LLaMA Factory多模态微调实践:微调Qwen2-VL构建文旅大模型
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub 星标超过 4.7 万。本教程将基于通义千问团队开源的新一代多模态大模型 Qwen2-VL-2B-Instruct,介绍如何使用 矩池云 平台及 LLaMA Factory 训练框架完成文旅领域大模型的构建。
GitHub地址:https://github.com/hiyouga/LLaMA-Factory
一、直接使用 LLaMA-Factory镜像
注:最新版
LLaMa-Factory已经上线
租用实例时,请搜索关键词
LLaMaFactory选择镜像LLaMa-Factory20250418即可使用
实例运行后,可通过“我的实例”页面中的服务链接进行访问。
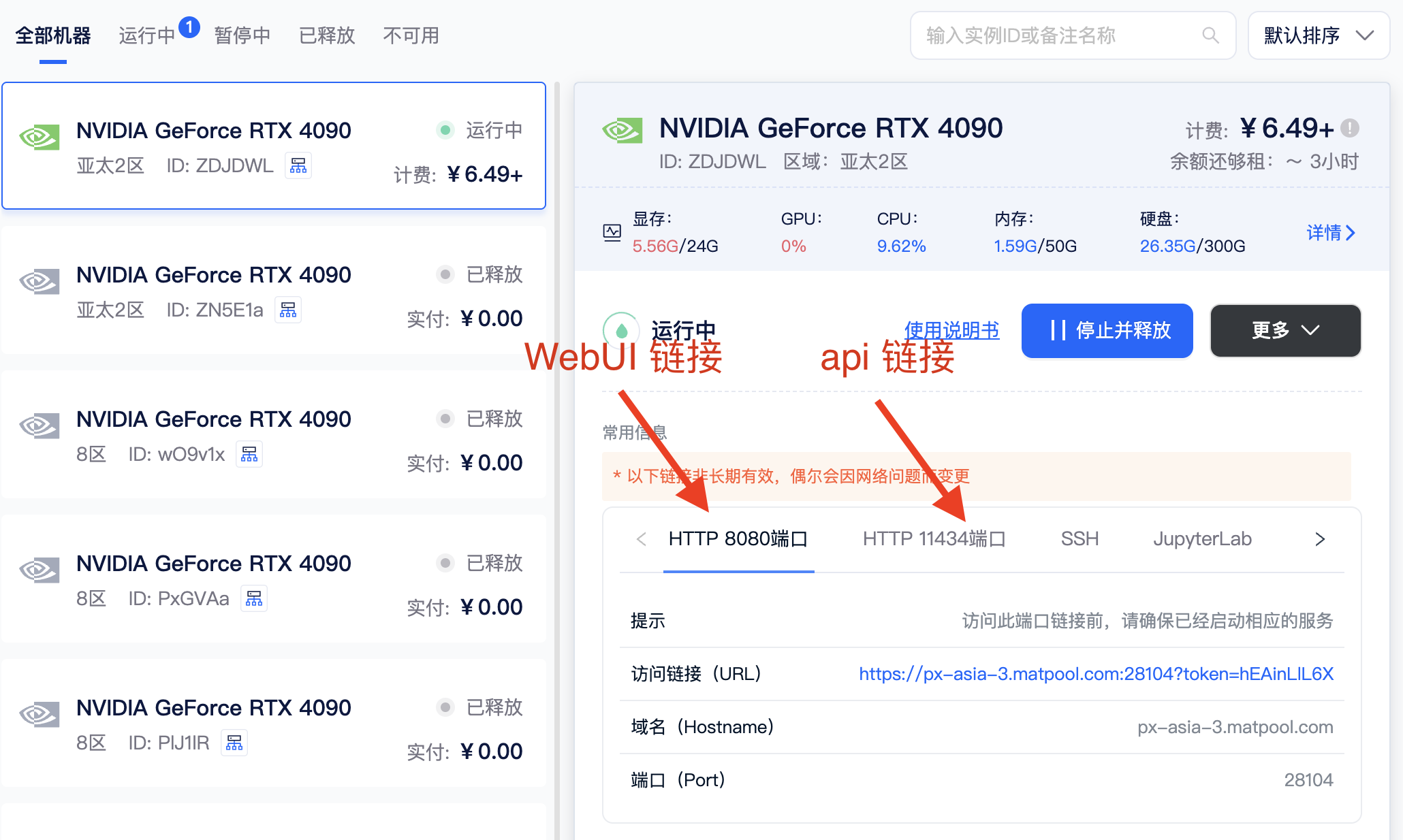
二、亲自部署 LLaMA-Factory
如果想亲自在实例上部署LLaMA-Factory,则步骤如下:
启动实例
显卡型号:4090 24G显存 (为保证下载速度,请选择亚太 2 区的机器)
镜像:Pytorch 2.5.1
配置端口号: 8080(WebUI 服务) 11434(API 服务)
设置环境变量:GRADIO_SERVER_PORT=8080 (定义 Gradio webUI 服务的端口号,注:环境变量只能在 terminal 中查看,notebook 无法查看)
去除国内镜像源
如果您使用的是亚太 2 区的机器,则在部署之前,先去除默认的国内 pip 源:
具体方法在matpool主站右下角点击“客服”寻问AI客服:“如何去除pip源”
安装LLaMA-Factory
实例中运行:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
启动服务
实例中运行:
llamafactory-cli webui
注:如果实例不在亚太2区,则配置modelhub下载模型
USE_MODELSCOPE_HUB=1 llamafactory-cli webui
# USE_MODELSCOPE_HUB 设为 1,表示模型从 ModelScope 魔搭社区下载。避免从 HuggingFace 下载模型导致网速不畅。
服务启动后,可通过“我的实例”页面中的服务链接进行访问。
三、使用LLaMA-Factory 微调模型
准备数据集
LLaMA-Factory 项目内置了丰富的数据集,放在了 data 目录下。您可以跳过本步骤,直接使用内置数据集。您也可以准备自定义数据集,将数据处理为框架特定的格式,放在 data 下,并且修改 dataset_info.json 文件。
如果直接使用了人LLama-Factory镜像,则用户可直接在
data目录下查看到images文件夹和train.json数据集,并且已经在`dataset_info.json `中加入train数据集。
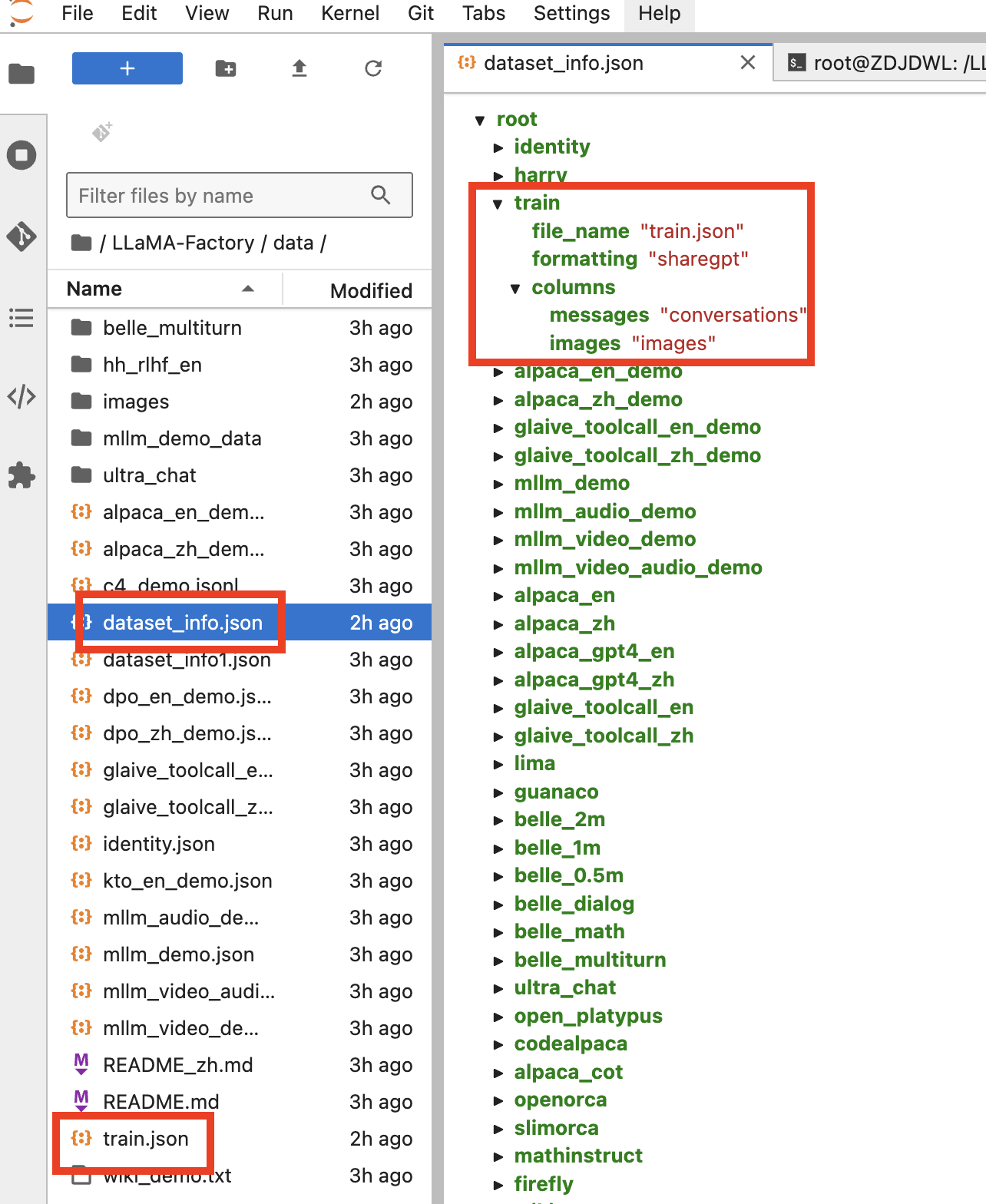
如果是按照步骤二自己部署的 LLaMA-Factory,则可自行下载数据集并存放到 data 目录:
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zip
mv data rawdata && unzip Qwen2-VL-History.zip -d data # 这一步会将原LLaMA-Facroty 目录下的 data 文件转移到rawdata中
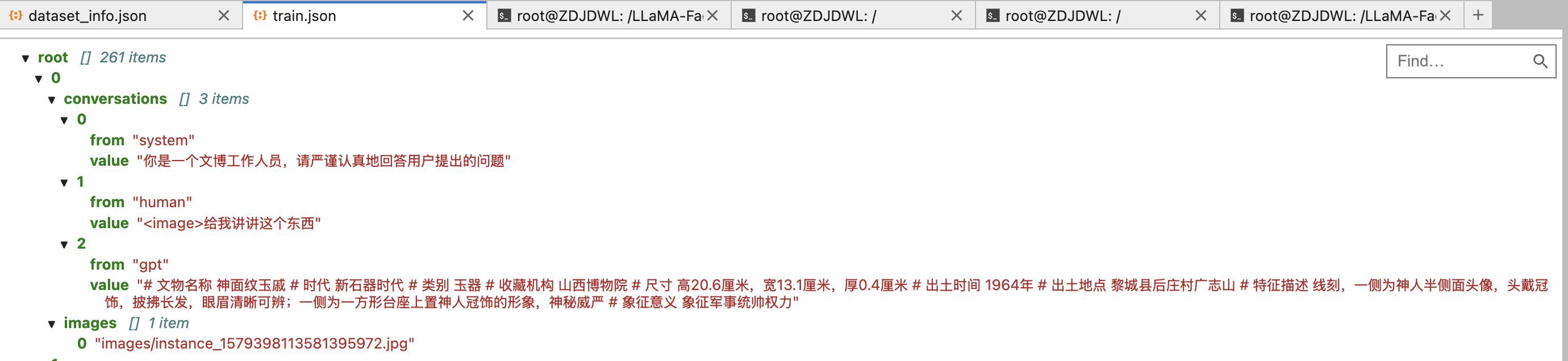
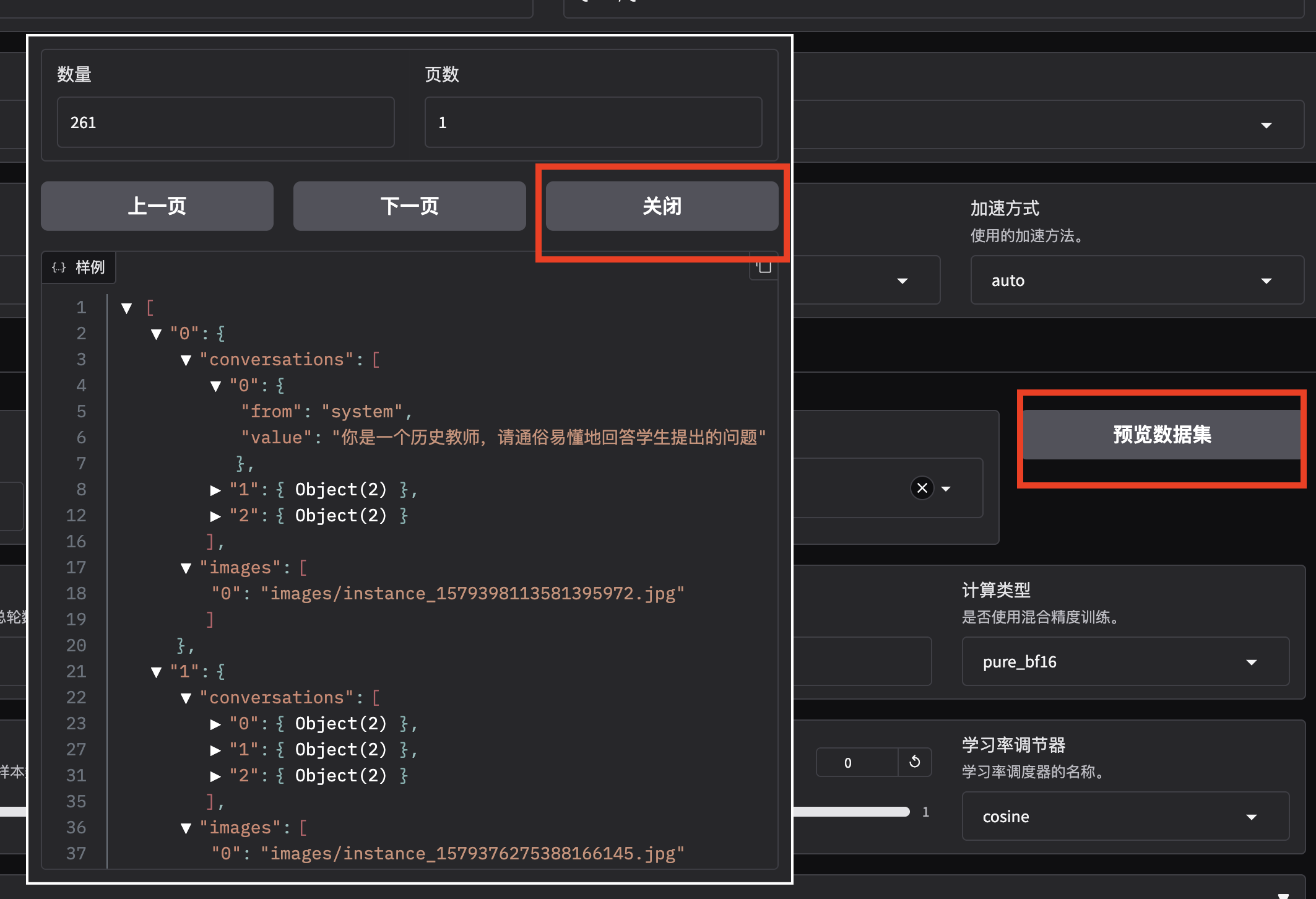
数据集中的样本为单轮对话形式,含有 261 条样本,每条样本都由一条系统提示、一条用户指令和一条模型回答组成,微调过程中模型不断学习样本中的回答风格,从而达到学习文旅知识的目的。数据样例如下所示:
模型微调
2.0 监控显存使用情况
在微调过程中,需要持续观测显存用量,及时发现显存用超的情况:
watch -n 1 nvidia-smi
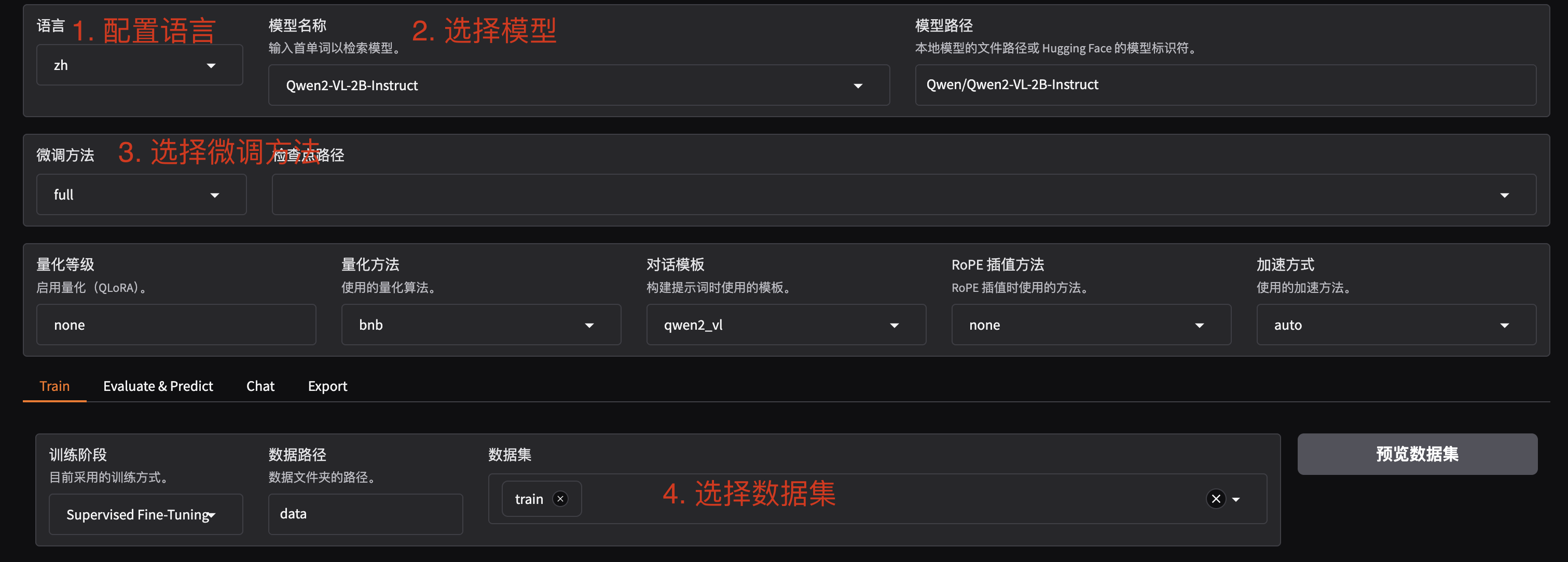
2.1 配置参数
进入 WebUI 后,可以切换语言到中文(zh)。首先配置模型,本教程选择 Qwen2VL-2B-Chat 模型,微调方法修改为 full,针对小模型使用全参微调方法能带来更好的效果。
可以点击「预览数据集」按钮查看训练数据;点击「关闭」按钮返回训练界面:
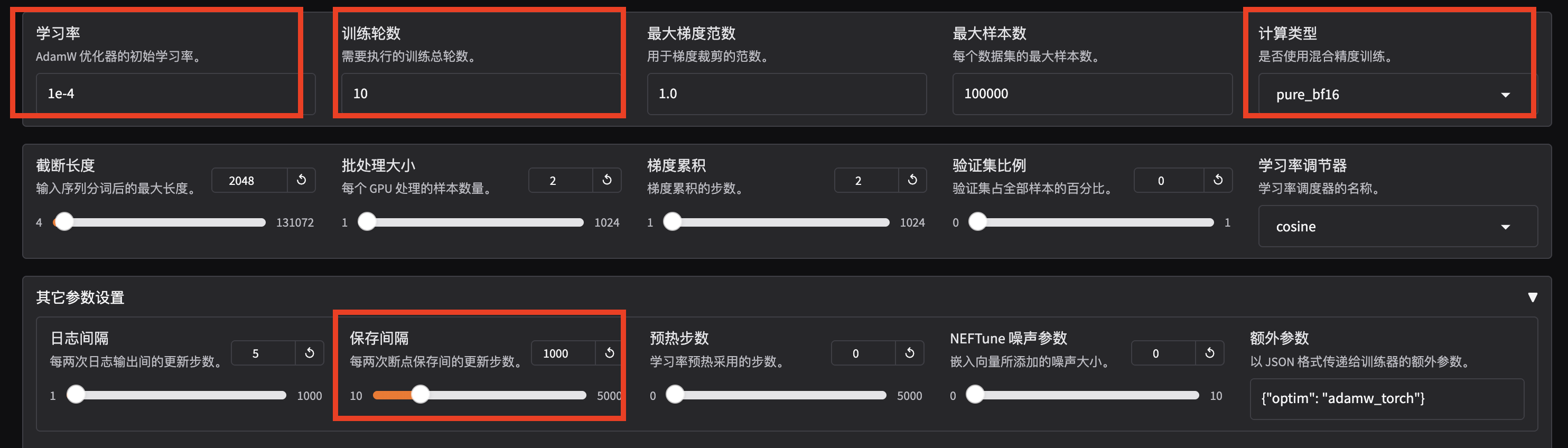
设置学习率为 1e-4,训练轮数为 10,更改计算类型为 pure_bf16,梯度累积为 2,有利于模型拟合。在其他参数设置区域修改保存间隔为 1000,节省硬盘空间。
2.2 启动微调
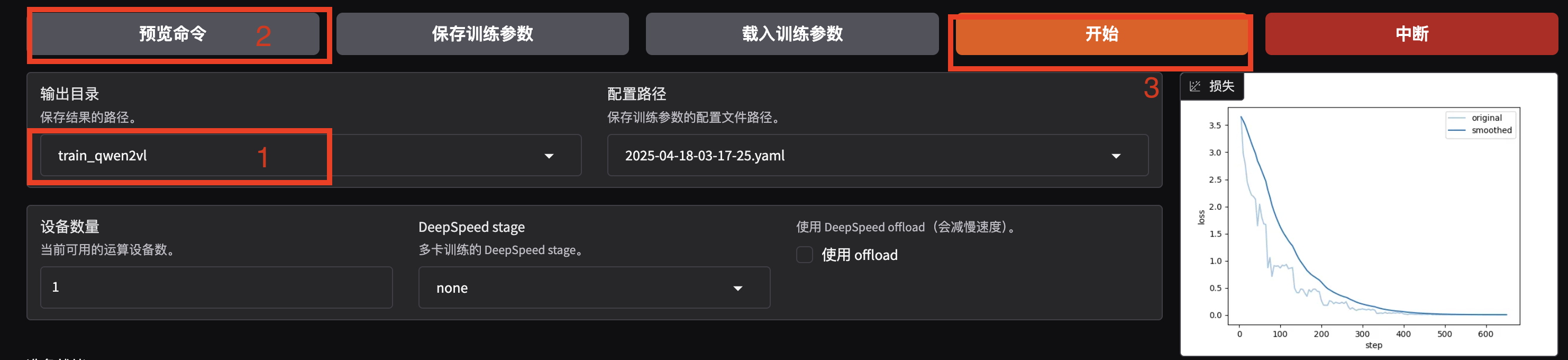
将输出目录修改为 train_qwen2vl,训练后的模型权重将会保存在此目录中。点击「预览命令」可展示所有已配置的参数,如果想通过代码运行微调,可以复制这段命令,在命令行运行。
点击「开始」启动模型微调。
启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约需要 14 分钟,显示“训练完毕”代表微调成功。
2.3 模型对话
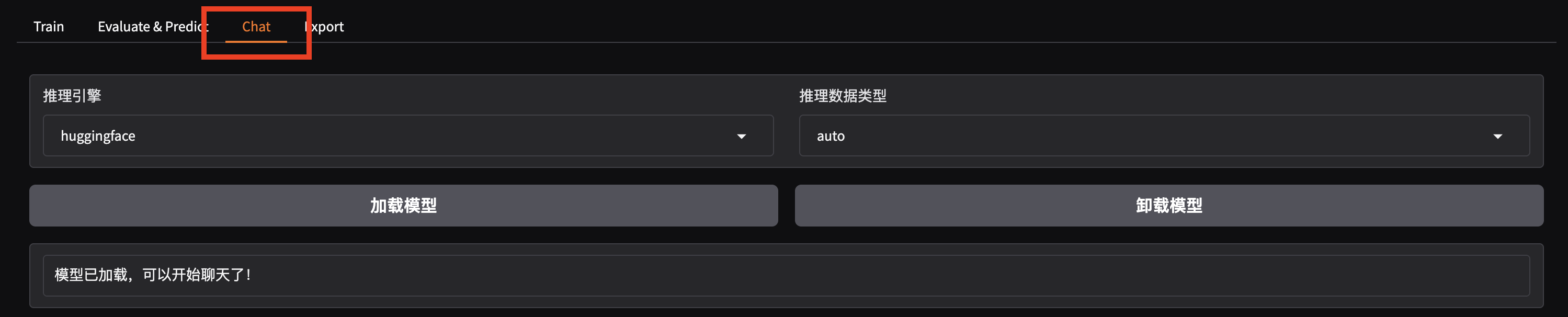
将检查点路径改为 train_qwen2vl

选择「Chat」栏,点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。
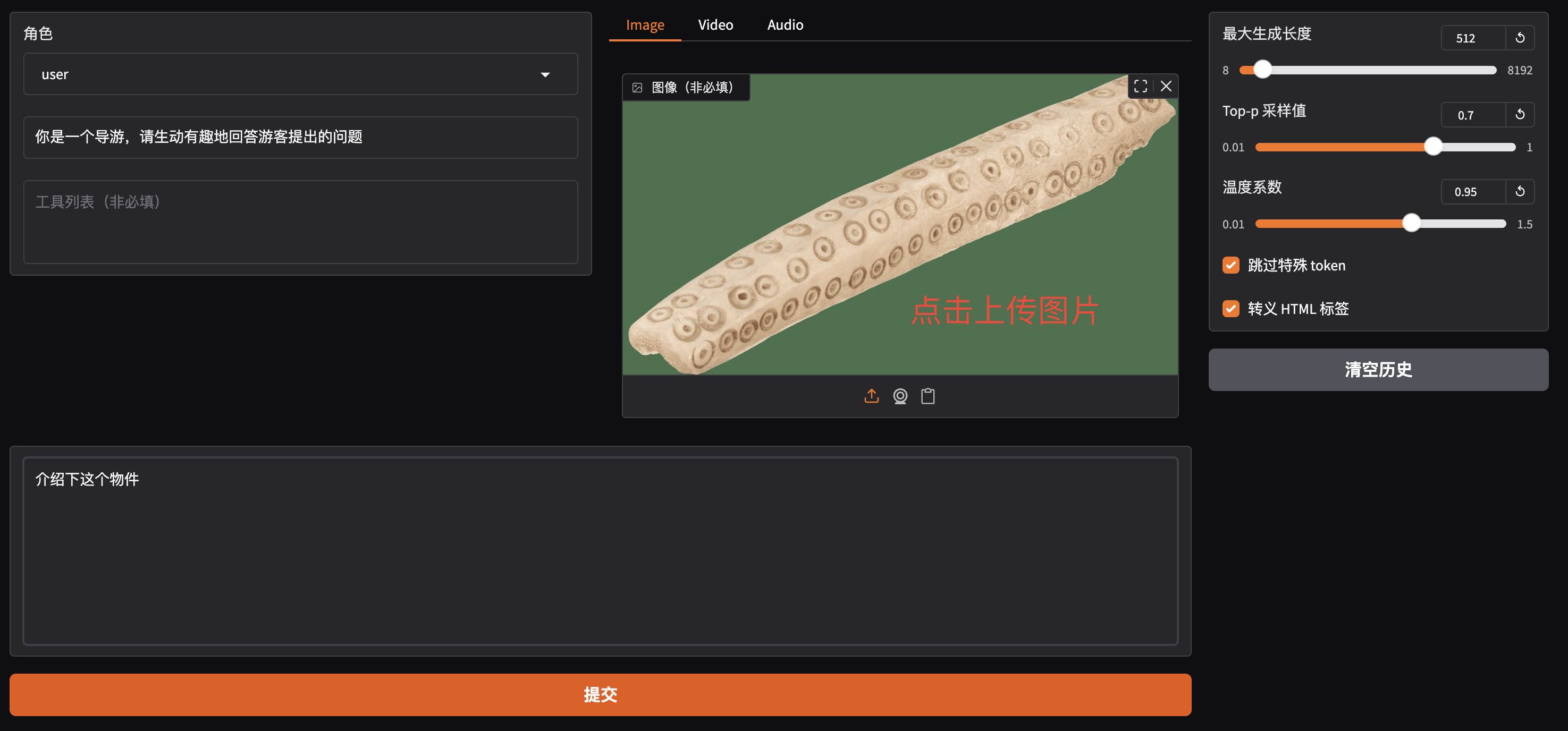
首先点击测试图片并上传至对话框的图像区域,接着在系统提示词区域填写“你是一个导游,请生动有趣地回答游客提出的问题”。在页面底部的对话框输入想要和模型对话的内容,点击提交即可发送消息。
测试图片 1:

测试图片 2:

参考
https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory_qwen2vl