每日文献(十四)——Part one
今天看的是《Understanding Negative Proposals in Generic Few-Shot Object Detection》
目录
零、摘要
0.1 原文
0.2 译文
一、介绍
二、相关工作
A. 通用目标检测
B. 通用目标检测中的采样策略
C. 少量样本学习目标检测
零、摘要
0.1 原文
Recently, Few-Shot Object Detection (FSOD) has received considerable research attention as a strategy for reducing reliance on extensively labeled bounding boxes. However, current approaches encounter significant challenges due to the intrinsic issue of incomplete annotation while building the instance-level training benchmark. In such cases, the instances with missing annotations are regarded as background, resulting in erroneous training gradients back-propagated through the detector, thereby compromising the detection performance. To mitigate this challenge, we introduce a simple and highly efficient method that can be plugged into both meta-learning-based and transfer-learning-based methods. Our method incorporates two innovative components: Confusing Proposals Separation (CPS) and Affinity-Driven Gradient Relaxation (ADGR). Specifically, CPS effectively isolates confusing negatives while ensuring the contribution of hard negatives during model fine-tuning; ADGR then adjusts their gradients based on the affinity to different category prototypes. As a result, false-negative samples are assigned lower weights than other negatives, alleviating their harmful impacts on the few-shot detector without the requirement of additional learnable parameters. Extensive experiments conducted on the PASCAL VOC and MS-COCO datasets consistently demonstrate that our method significantly outperforms both the baseline and recent FSOD methods. Furthermore, its versatility and efficiency suggest the potential to become a stronger new baseline in the field of FSOD. Code is available at https://github.com/Ybowei/UNP.
0.2 译文
最近,少量样本学习目标检测(FSOD)作为一种减少对广泛标记边界盒依赖的策略受到了相当多的研究关注。然而,由于在构建实例级训练基准时存在不完整注释的固有问题,目前的方法遇到了重大挑战。在这种情况下,缺少注释的实例被视为背景,导致错误的训练梯度通过检测器反向传播,从而影响检测性能。为了缓解这一挑战,我们引入了一种简单而高效的方法,可以插入到基于元学习和基于迁移学习的方法中。我们的方法包含两个创新组件:混淆建议分离(CPS)和亲和力驱动梯度松弛(ADGR)。具体而言,CPS有效地隔离了令人困惑的底片,同时确保了模型微调期间硬底片的贡献;然后,ADGR根据对不同类别原型的亲和力来调整它们的梯度。因此,假阴性样本被赋予比其他阴性样本更低的权重,减轻了它们对少量样本学习检测器的有害影响,而不需要额外的可学习参数。在PASCAL VOC和MS-COCO数据集上进行的大量实验一致表明,我们的方法明显优于基线和最近的FSOD方法。此外,它的通用性和效率表明它有可能成为FSOD领域更强大的新基线。代码可从https://github.com/Ybowei/UNP获得。
一、介绍
近年来,基于深度卷积神经网络的目标检测方法[1]、[2]、[3]在计算机视觉领域取得了重大进展。然而,卓越的性能在很大程度上依赖于丰富的注释图像的可用性。通常,获得足够的标记数据是劳动密集型的,并且可用训练样本的数量有限严重限制了当前视觉系统[4],[5],[6]的应用。为了克服这一障碍,研究人员开创了少量样本学习[7],[8],[9]的进步,它显示了用有限的标记数据泛化到新类别的能力。少量样本学习目标检测(Few-Shot Object Detection, FSOD)作为研究的一个分支,比少量样本学习分类[7]、[10]、[11]、[12]和目标检测[13]、[14]、[15]更具挑战性。随着学术界的兴趣日益浓厚,人们提出了一系列方法来应对FSOD中的挑战,如Meta YOLO[16]、Meta R-CNN[13]、TFA[17]、SVD[18]等。
根据之前的少量样本学习图像分类原理[19],FSOD方法大致分为两大类:基于元学习的方法[13]、[16]、[20]、[21]、[22]、[23]和基于迁移学习的方法[17]、[18]、[24]、[25]。具体来说,基于元学习的方法设计了元检测器,通过基于情节的数据集子采样模拟少量样本学习场景来获取任务级知识。基于迁移学习的方法通常是在数据丰富的基类上对模型进行预训练,然后在数据稀缺的新类上对模型进行微调。在这种情况下,微调阶段可以理解为从基类到新类的领域适应过程。尽管FSOD方法取得了重大进展,但它们仍然难以在有限的样本量下快速推广并达到所需的检测精度。
与在大量注释数据上训练的传统检测器相比,少量样本学习检测器容易将新类的实例错误地分类为背景,造成前景和背景的混淆。几个FSOD作品[13],[17],[26]将这种现象归因于分类器对有限训练样本的过拟合。然而,他们忽略了模型训练过程中注释不完整的另一个关键因素。与完全监督的设置(几乎所有感兴趣的实例都被标记为训练)不同,少量样本学习场景通常有大量缺少注释的实例,如图1所示。原因是FSOD方法通常将一个实例视为一次测试,以便在创建实例级基准测试时控制标记实例的数量。此外,考虑到实际应用,由于构建训练基准的简单性和便利性,仅标记部分实例是常见的和不可避免的。不完全标注问题加剧了少量样本学习检测方法的挑战,在这种情况下,标注的样本已经很稀缺,特别是在低镜头任务中。[22][27]。它加剧了少量样本学习检测器中前景和背景的混淆,导致新类别泛化能力差,降低了检测精度。
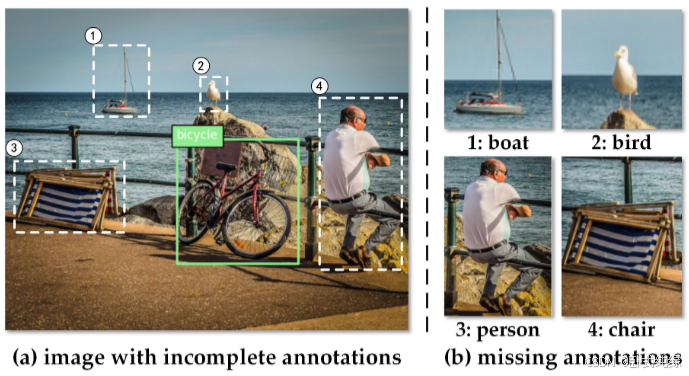
针对一般目标检测中存在的标注不完全问题,提出了一些现成的方法,如软采样[28]和部分感知采样[29]。然而,这些方法由于泛化到新类别的能力和检测精度的有限提高而不适合少量样本学习检测器。另一种替代策略是伪标记[30],[31],[32],它试图挖掘缺乏注释的实例,以增加新类的可用样本数量。不幸的是,这些方法面临着一个困境:它需要一个可靠的少量样本学习检测器来生成准确的伪标签,但是这种少量样本学习检测器的有效训练也依赖于高质量注释的可用性。此外,这些方法往往需要大量的未标记样本,并需要一个复杂的训练过程。
在本文中,我们确定了不完整注释导致前景和背景混淆的关键因素是基于交集的样本分配策略。为了解决这一问题,提出了一种简单有效的FSOD两阶段检测器UNP算法,该算法主要由两个新组件组成:混淆建议分离(CPS)和亲和驱动梯度松弛(ADGR)。CPS通过评估建议和可用注释之间的IoU,有效地隔离了令人困惑的负面建议。这一过程背后的动机是减少不正确的负建议的梯度,同时确保在模型微调期间硬负样本的贡献。在识别出令人困惑的建议后,ADGR实现了一种重新加权策略,该策略评估这些建议与类原型之间的亲和力,为每个样本的梯度动态分配不同的优化系数。随着提案相似度得分的增加,其属于前景类别的可能性增加,而相似度得分较低的建议更有可能是真实背景。
综上所述,我们的方法主要针对FSOD场景下的不完全标注问题,贡献总结如下:
•我们从不完整注释的角度仔细研究了现有的FSOD方法,并提出了一个可以集成到基于元学习和基于迁移学习的检测器中的框架。
•为了缓解由于标注不完整导致的前景和背景的混淆,我们设计了CPS和ADGR两个新颖的模块,减少了两阶段FSOD方法中错误阴性样本的影响,显著提高了检测性能。
•在PASCAL VOC和MS-COCO基准测试中,我们的方法始终优于最近的FSOD方法。
二、相关工作
A. 通用目标检测
目标检测是计算机视觉领域的一项基本任务,旨在识别和精确定位图像[14],[33],[34]中的目标。同时,它还可以应用于语义分割[35]、[36]、[37]和视觉语言理解[38]、[39]、[40]等各种下游任务。随着深度卷积神经网络的兴起,出现了一系列优秀的目标检测算法,大致可分为两大类:基于提议的方法[1]、[33]、[34]和无提议的方法[41]、[42]、[43]。基于提议的方法将目标检测分解为两个连续的阶段。最初,他们生成一组可能包含对象的区域建议,然后对每个建议进行分类和边界框回归。相反,无提议方法直接预测边界框,并利用CNN特征预测类标签,绕过了显式区域建议的必要性。尽管最近基于变压器的目标检测模型[44],[45],[46]取得了令人鼓舞的结果,但它们在模型训练过程中经常遇到缓慢收敛的问题。此外,所有这些框架都有一个共同的假设:来自可视领域的大量注释数据的可用性。在以有限数据为特征的情景中,这一假设提出了重大挑战。
B. 通用目标检测中的采样策略
采样策略在目标检测中起着至关重要的作用,直接影响训练过程和模型的整体性能。最普遍的抽样方案是随机抽样,即从所有候选人中随机选择训练样本。另一种流行的方法是HEM,它侧重于对损失较大的硬训练样本进行采样。HEM的概念在早期检测作品[47]中被引入,并在深度学习时代被进一步应用于当代研究[48]。作为HEM的替代方案,Libra R-CNN[49]建议采用IoU-balanced sampling,目的是实现平衡学习以增强分类结果。为了解决缺少注释的问题,[29]提出了一种基于周围上下文选择信息样本的上下文感知采样策略。与我们密切相关的一项工作是软抽样[28],它试图将丢失的实例视为硬负样本并调整其损失。然而,这些方法只针对一般的目标检测,不能直接应用于少量样本学习场景。与上下文感知采样和软采样中的注释缺失不同,我们的工作重点是在少量样本学习场景下,只有有限数量的注释训练样本可用的情况下,不完整的注释问题。
C. 少量样本学习目标检测
少量样本学习目标检测(FSOD)近年来受到越来越多的关注。根据训练范式,现有研究大致可分为两类:基于元学习的方法[13]、[20]、[21]、[22]、[50]、[51]、[52]、[53]和基于迁移学习的方法[17]、[18]、[25]、[54]、[55]、[56]、[57]。
元学习方法采用情景训练的方式,获取在基类上预训练的任务级知识,从而增强其在遇到新类时的泛化能力。RepMet[50]是一种典型的元学习方法,利用嵌入空间向量与类代表之间的距离计算进行目标分类。在单阶段和两阶段检测框架中,MetaYOLO[51]和Meta R-CNN[13]都采用了重加权特征而不是图像特征来检测新的类别实例。此外,CME[20]利用元学习来解决通过类边际均衡方法平衡新类分类和表示的挑战。[21]介绍了“婴儿检测器”的概念,它是通过元学习算法优化的初始检测器。
尽管基于元学习的技术可以部分解决FSOD的挑战,但它们通常涉及更复杂的数据组织和训练程序。最新的基于迁移学习的方法不仅超越了以前的元学习方法,而且提供了一种更简单、更有效的解决方案。TFA[17]介绍了一种简单的两阶段微调方法,首先使用充足的样本在所有基类上对检测器进行训练,然后专门对新类的有限样本进行微调。MPSR[57]提出了一个多尺度正样本细化分支来聚合各种尺度特征映射,用于最终检测。SRR-FSD[58]采用词嵌入网络和关系推理模块来增强已有的先验知识。此外,DMNet[59]提出了解耦表示转换模块,该模块预测目标和锚点形状,以减轻人工设计锚点的不利影响。
而上述方法存在标注不完整的问题,导致检测精度较低。FSCN[22]是一种缓解这一问题的伪标记方法,它通过标记缺失的注释来从基类数据集中增加新类的训练样本。然而,利用FSCN从基类的训练数据集中挖掘新类实例的前提并不一定总是适用。几种少量样本学习目标检测方法[16]、[26]经常有意地排除含有新类的训练数据。与FSCN相比,我们的方法只关注微调阶段的不完整注释问题,并且在不需要额外的基类和参数数据集的情况下,在少量样本学习检测基准上取得了更好的性能。