基于用户的协同过滤推荐系统实战项目
文章目录
- 基于用户的协同过滤推荐系统实战项目
- 1. 推荐系统基础理论
- 1.1 协同过滤概述
- 1.2 基于用户的协同过滤原理
- 1.3 相似度计算方法
- 1.3.1 余弦相似度(Cosine Similarity)
- 1.3.2 皮尔逊相关系数(Pearson Correlation)
- 1.3.3 欧几里得距离(Euclidean Distance)
- 1.3.4 调整余弦相似度(Adjusted Cosine Similarity)
- 1.4 评分预测方法
- 1.4.1 简单加权平均
- 1.4.2 考虑用户评分偏置的加权平均
- 1.5 评估指标
- 1.5.1 均方根误差(RMSE)
- 1.5.2 平均绝对误差(MAE)
- 1.6 TopN推荐
- 1.6.1 精确率(Precision)和召回率(Recall)
- 1.6.2 F1分数
- 2. 项目介绍
- 2.1 数据集介绍
- 2.2 项目架构设计
- 2.2.1 模块化架构
- 3. 项目实施步骤
- 3.1 数据获取与探索
- 3.2 数据加载模块实现
- 3.3 构建评分矩阵和数据集拆分
- 3.4 日志系统设计
- 3.5 相似度计算模块
- 3.6 评分预测模块
- 3.7 推荐生成模块
- 3.8 评估模块
- 3.9 完整推荐系统模型
- 3.10 命令行接口设计
- 3.11 模型序列化与反序列化
- 3.12 Web应用开发
- 3.13 性能优化与错误处理
- 5. 模块化设计的优势
- 6. 结论与未来工作
- 7. 参考资料
基于用户的协同过滤推荐系统实战项目
1. 推荐系统基础理论
1.1 协同过滤概述
协同过滤(Collaborative Filtering, CF)是推荐系统中最经典、应用最广泛的技术之一。其核心思想是利用群体的智慧来进行推荐,基于"相似的用户喜欢相似的物品"或"喜欢某物品的用户也喜欢其他相似物品"的假设。
协同过滤主要分为两大类:
- 基于记忆的协同过滤(Memory-based CF):直接使用用户-物品交互数据进行推荐,包括基于用户的协同过滤(User-based CF)和基于物品的协同过滤(Item-based CF)。
- 基于模型的协同过滤(Model-based CF):通过机器学习算法从数据中学习模型,如矩阵分解(Matrix Factorization)、奇异值分解(SVD)等。
本项目主要聚焦于基于用户的协同过滤。
1.2 基于用户的协同过滤原理
基于用户的协同过滤的工作流程如下:
- 构建用户-物品评分矩阵:每行代表一个用户,每列代表一个物品,矩阵中的元素表示用户对物品的评分。
- 计算用户相似度:寻找与目标用户具有相似品味的用户群体。
- 预测评分:基于相似用户的评分,预测目标用户对未评分物品的可能评分。
- 生成推荐:为用户推荐评分最高的未接触物品。
1.3 相似度计算方法
在协同过滤中,常用的相似度计算方法包括:
1.3.1 余弦相似度(Cosine Similarity)
余弦相似度计算两个向量之间夹角的余弦值,范围从-1到1,值越大表示越相似。
对于用户 u u u和用户 v v v,其余弦相似度计算公式为:
s i m c o s ( u , v ) = ∑ i ∈ I u v r u i ⋅ r v i ∑ i ∈ I u r u i 2 ⋅ ∑ i ∈ I v r v i 2 sim_{cos}(u, v) = \frac{\sum_{i \in I_{uv}} r_{ui} \cdot r_{vi}}{\sqrt{\sum_{i \in I_{u}} r_{ui}^2} \cdot \sqrt{\sum_{i \in I_{v}} r_{vi}^2}} simcos(u,v)=∑i∈Iurui2⋅∑i∈Ivrvi2∑i∈Iuvrui⋅rvi
其中:
- I u v I_{uv} Iuv是用户 u u u和用户 v v v共同评分的物品集合
- r u i r_{ui} rui是用户 u u u对物品 i i i的评分
- r v i r_{vi} rvi是用户 v v v对物品 i i i的评分
- I u I_u Iu是用户 u u u评分的所有物品集合
- I v I_v Iv是用户 v v v评分的所有物品集合
在Python中,可以使用sklearn.metrics.pairwise中的cosine_similarity或1 - pairwise_distances(X, metric='cosine')计算余弦相似度。
1.3.2 皮尔逊相关系数(Pearson Correlation)
皮尔逊相关系数衡量两个变量之间的线性相关性,范围从-1到1,也称为"皮尔逊积矩相关系数"。
计算公式为:
s i m p e a r s o n ( u , v ) = ∑ i ∈ I u v ( r u i − r ˉ u ) ⋅ ( r v i − r ˉ v ) ∑ i ∈ I u v ( r u i − r ˉ u ) 2 ⋅ ∑ i ∈ I u v ( r v i − r ˉ v ) 2 sim_{pearson}(u, v) = \frac{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u) \cdot (r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv}} (r_{vi} - \bar{r}_v)^2}} simpearson(u,v)=∑i∈Iuv(rui−rˉu)2⋅∑i∈Iuv(rvi−rˉv)2∑i∈Iuv(rui−rˉu)⋅(rvi−rˉv)
其中:
- r ˉ u \bar{r}_u rˉu是用户 u u u的平均评分
- r ˉ v \bar{r}_v rˉv是用户 v v v的平均评分
皮尔逊相关系数考虑了用户评分的偏置(bias),能更好地处理用户评分标准不同的情况(有些用户倾向于给高分,有些用户倾向于给低分)。
在Python中,可以使用numpy.corrcoef()计算皮尔逊相关系数。
1.3.3 欧几里得距离(Euclidean Distance)
欧几里得距离直接计算两个向量在空间中的距离,距离越小表示越相似。
计算公式为:
d i s t a n c e e u c l i d e a n ( u , v ) = ∑ i ∈ I u v ( r u i − r v i ) 2 distance_{euclidean}(u, v) = \sqrt{\sum_{i \in I_{uv}} (r_{ui} - r_{vi})^2} distanceeuclidean(u,v)=∑i∈Iuv(rui−rvi)2
为了将距离转换为相似度,通常使用以下变换:
s i m e u c l i d e a n ( u , v ) = 1 1 + d i s t a n c e e u c l i d e a n ( u , v ) sim_{euclidean}(u, v) = \frac{1}{1 + distance_{euclidean}(u, v)} simeuclidean(u,v)=1+distanceeuclidean(u,v)1
在Python中,可以使用sklearn.metrics.pairwise中的euclidean_distances计算欧几里得距离。
1.3.4 调整余弦相似度(Adjusted Cosine Similarity)
调整余弦相似度在计算前先减去用户的平均评分,解决了用户评分标准不一致的问题:
s i m a d j _ c o s ( u , v ) = ∑ i ∈ I u v ( r u i − r ˉ u ) ⋅ ( r v i − r ˉ v ) ∑ i ∈ I u v ( r u i − r ˉ u ) 2 ⋅ ∑ i ∈ I u v ( r v i − r ˉ v ) 2 sim_{adj\_cos}(u, v) = \frac{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u) \cdot (r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv}} (r_{vi} - \bar{r}_v)^2}} simadj_cos(u,v)=∑i∈Iuv(rui−rˉu)2⋅∑i∈Iuv(rvi−rˉv)2∑i∈Iuv(rui−rˉu)⋅(rvi−rˉv)
1.4 评分预测方法
在确定用户相似度后,需要预测目标用户对未评分物品的可能评分。传统的基于用户的协同过滤通常采用加权平均的方式进行预测。
1.4.1 简单加权平均
r ^ u i = ∑ v ∈ N u ( i ) s i m ( u , v ) ⋅ r v i ∑ v ∈ N u ( i ) ∣ s i m ( u , v ) ∣ \hat{r}_{ui} = \frac{\sum_{v \in N_u(i)} sim(u, v) \cdot r_{vi}}{\sum_{v \in N_u(i)} |sim(u, v)|} r^ui=∑v∈Nu(i)∣sim(u,v)∣∑v∈Nu(i)sim(u,v)⋅rvi
其中:
- r ^ u i \hat{r}_{ui} r^ui是预测的用户 u u u对物品 i i i的评分
- N u ( i ) N_u(i) Nu(i)是与用户 u u u相似且评价过物品 i i i的用户集合
- s i m ( u , v ) sim(u, v) sim(u,v)是用户 u u u与用户 v v v的相似度
- r v i r_{vi} rvi是用户 v v v对物品 i i i的实际评分
1.4.2 考虑用户评分偏置的加权平均
为了解决不同用户评分标准不同的问题,可以使用考虑评分偏置的改进公式:
r ^ u i = r ˉ u + ∑ v ∈ N u ( i ) s i m ( u , v ) ⋅ ( r v i − r ˉ v ) ∑ v ∈ N u ( i ) ∣ s i m ( u , v ) ∣ \hat{r}_{ui} = \bar{r}_u + \frac{\sum_{v \in N_u(i)} sim(u, v) \cdot (r_{vi} - \bar{r}_v)}{\sum_{v \in N_u(i)} |sim(u, v)|} r^ui=rˉu+∑v∈Nu(i)∣sim(u,v)∣∑v∈Nu(i)sim(u,v)⋅(rvi−rˉv)
其中:
- r ˉ u \bar{r}_u rˉu是用户 u u u的平均评分
- r ˉ v \bar{r}_v rˉv是用户 v v v的平均评分
这种方法不直接使用原始评分,而是使用评分与用户平均评分的偏差,能够更好地处理用户评分偏好不同的情况。
1.5 评估指标
推荐系统的性能评估通常使用以下指标:
1.5.1 均方根误差(RMSE)
RMSE是预测评分与实际评分之间差异的平方平均的平方根,值越小表示预测越准确。
R M S E = 1 ∣ T ∣ ∑ ( u , i ) ∈ T ( r ^ u i − r u i ) 2 RMSE = \sqrt{\frac{1}{|T|} \sum_{(u,i) \in T} (\hat{r}_{ui} - r_{ui})^2} RMSE=∣T∣1∑(u,i)∈T(r^ui−rui)2
其中:
- T T T是测试集中的用户-物品对集合
- r ^ u i \hat{r}_{ui} r^ui是预测的评分
- r u i r_{ui} rui是实际评分
1.5.2 平均绝对误差(MAE)
MAE是预测评分与实际评分之间绝对差值的平均,同样值越小表示预测越准确。
M A E = 1 ∣ T ∣ ∑ ( u , i ) ∈ T ∣ r ^ u i − r u i ∣ MAE = \frac{1}{|T|} \sum_{(u,i) \in T} |\hat{r}_{ui} - r_{ui}| MAE=∣T∣1∑(u,i)∈T∣r^ui−rui∣
与RMSE相比,MAE对异常值的敏感度较低,因此两个指标通常一起使用,以全面评估推荐系统的性能。
1.6 TopN推荐
在实际应用中,我们通常不仅关注评分预测的准确度,还关注能否为用户推荐最适合的N个物品,称为TopN推荐。为此,可以使用额外的评估指标:
1.6.1 精确率(Precision)和召回率(Recall)
-
精确率:推荐的物品中实际相关的比例
P r e c i s i o n @ k = ∣ 推荐列表 ∩ 相关物品 ∣ ∣ 推荐列表 ∣ Precision@k = \frac{|推荐列表 \cap 相关物品|}{|推荐列表|} Precision@k=∣推荐列表∣∣推荐列表∩相关物品∣
-
召回率:实际相关物品中被成功推荐的比例
R e c a l l @ k = ∣ 推荐列表 ∩ 相关物品 ∣ ∣ 相关物品 ∣ Recall@k = \frac{|推荐列表 \cap 相关物品|}{|相关物品|} Recall@k=∣相关物品∣∣推荐列表∩相关物品∣
1.6.2 F1分数
F1分数是精确率和召回率的调和平均数,综合考虑两个指标。
F 1 = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \cdot \frac{Precision \cdot Recall}{Precision + Recall} F1=2⋅Precision+RecallPrecision⋅Recall
2. 项目介绍
协同过滤是推荐系统的核心算法之一,它基于用户行为数据来推荐物品。基于用户的协同过滤(User-Based Collaborative Filtering)算法通过寻找与目标用户相似的用户群体,然后推荐这些相似用户喜欢但目标用户尚未接触的物品。gitcode
本项目基于以下经典论文:
- Resnick P, Iacovou N, Suchak M, et al. Grouplens: An open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM conference on Computer supported cooperative work. 1994: 175-186. https://doi.org/10.1145/192844.192905
- Breese J S, Heckerman D, Kadie C. Empirical analysis of predictive algorithms for collaborative filtering[J]. arXiv preprint arXiv:1301.7363, 2013. https://doi.org/10.48550/arXiv.1301.7363
2.1 数据集介绍
本项目使用经典的MovieLens 100K数据集,该数据集包含:
- 943个用户
- 1682部电影
- 10万条评分数据(1-5分)
- 用户的人口统计学特征
- 电影的类型信息
2.2 项目架构设计
为了构建一个可维护、可扩展的推荐系统,本项目采用模块化设计,将核心功能按照职责分散到不同模块中。
2.2.1 模块化架构
项目由以下核心模块组成:
- 数据加载模块(data_loader.py):负责数据读取、预处理和矩阵构建
- 相似度计算模块(similarity.py):实现多种相似度计算方法
- 评分预测模块(prediction.py):实现评分预测算法
- 推荐生成模块(recommendation.py):生成个性化推荐列表
- 评估模块(evaluation.py):实现多种评估指标计算
- 日志模块(logger.py):管理系统日志记录
- 主模型模块(model.py):集成各个组件,提供统一接口
- 命令行接口(main.py):提供命令行交互功能
- Web应用(app.py):提供Web界面
3. 项目实施步骤
3.1 数据获取与探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_error
from sklearn.metrics.pairwise import pairwise_distances
from scipy.spatial.distance import cosine
import warnings
warnings.filterwarnings('ignore')# 设置随机种子保证结果可重复
np.random.seed(42)# 加载数据集
# 从 https://grouplens.org/datasets/movielens/100k/ 下载
# 或使用以下代码自动下载
!wget -nc http://files.grouplens.org/datasets/movielens/ml-100k.zip
!unzip -n ml-100k.zip# 加载用户评分数据
column_names = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv('ml-100k/u.data', sep='\t', names=column_names)# 加载电影信息
movies_column_names = ['movie_id', 'movie_title', 'release_date', 'video_release_date','IMDb_URL', 'unknown', 'Action', 'Adventure', 'Animation','Children', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy','Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi','Thriller', 'War', 'Western']
movies_df = pd.read_csv('ml-100k/u.item', sep='|', names=movies_column_names, encoding='latin-1')# 查看数据集基本信息
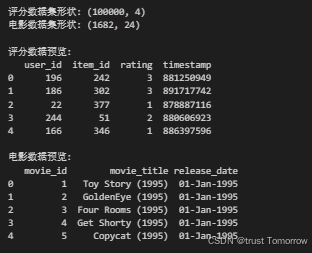
print(f"评分数据集形状: {df.shape}")
print(f"电影数据集形状: {movies_df.shape}")
print("\n评分数据预览:")
print(df.head())
print("\n电影数据预览:")
print(movies_df[['movie_id', 'movie_title', 'release_date']].head())
3.2 数据加载模块实现
我们将数据加载和处理功能封装在DataLoader类中,提供以下功能:
- 从文件加载数据
- 构建用户-物品评分矩阵
- 划分训练集和测试集
- 计算数据集统计信息
class DataLoader:"""负责加载和预处理MovieLens数据集的类"""def __init__(self, data_path="data/ml-100k"):"""初始化DataLoader并设置数据路径"""self.data_path = data_pathself.ratings_df = Noneself.movies_df = Noneself.n_users = Noneself.n_items = Noneself.ratings_matrix = Noneself.train_data = Noneself.test_data = Nonedef load_data(self):"""加载评分数据和电影数据"""# 检查数据路径if not os.path.exists(self.data_path):raise FileNotFoundError(f"数据目录 {self.data_path} 不存在")# 加载评分数据ratings_file = os.path.join(self.data_path, "u.data")if not os.path.exists(ratings_file):raise FileNotFoundError(f"评分文件 {ratings_file} 不存在")column_names = ["user_id", "item_id", "rating", "timestamp"]self.ratings_df = pd.read_csv(ratings_file, sep="\t", names=column_names)# 加载电影数据movies_file = os.path.join(self.data_path, "u.item")if not os.path.exists(movies_file):raise FileNotFoundError(f"电影文件 {movies_file} 不存在")movies_column_names = ["movie_id", "movie_title", "release_date", "video_release_date","IMDb_URL", "unknown", "Action", "Adventure", "Animation","Children", "Comedy", "Crime", "Documentary", "Drama", "Fantasy","Film-Noir", "Horror", "Musical", "Mystery", "Romance", "Sci-Fi","Thriller", "War", "Western"]self.movies_df = pd.read_csv(movies_file, sep="|", names=movies_column_names, encoding="latin-1")# 获取用户和电影数量self.n_users = self.ratings_df["user_id"].max()self.n_items = self.ratings_df["item_id"].max()return self.ratings_df, self.movies_df
3.3 构建评分矩阵和数据集拆分
def create_matrix(self):"""创建用户-物品评分矩阵"""if self.ratings_df is None:self.load_data()# 创建矩阵self.ratings_matrix = np.zeros((self.n_users, self.n_items))# 填充评分for row in self.ratings_df.itertuples():# 调整为0-based索引self.ratings_matrix[row.user_id-1, row.item_id-1] = row.ratingreturn self.ratings_matrixdef split_data(self, test_size=0.2, random_state=42):"""将数据划分为训练集和测试集"""if self.ratings_df is None:self.load_data()from sklearn.model_selection import train_test_split# 划分数据self.train_data, self.test_data = train_test_split(self.ratings_df, test_size=test_size, random_state=random_state)# 创建训练集矩阵self.train_matrix = np.zeros((self.n_users, self.n_items))for row in self.train_data.itertuples():self.train_matrix[row.user_id-1, row.item_id-1] = row.rating# 创建测试集矩阵self.test_matrix = np.zeros((self.n_users, self.n_items))for row in self.test_data.itertuples():self.test_matrix[row.user_id-1, row.item_id-1] = row.ratingreturn self.train_data, self.test_data, self.train_matrix, self.test_matrix
3.4 日志系统设计
为了跟踪系统运行状态、性能和错误,我们实现了一个灵活的日志模块:
import os
import logging
from logging.handlers import RotatingFileHandler
import timedef setup_logger(log_dir="results/logs", log_level=logging.INFO, silent=False):"""配置并返回推荐系统的日志记录器参数:log_dir: 日志文件存储目录log_level: 日志级别silent: 是否静默模式(不记录日志)返回:logger: 配置好的日志记录器"""# 创建日志记录器logger = logging.getLogger("recommendation_system")logger.setLevel(log_level)# 清除已有的处理器(避免重复日志)if logger.handlers:logger.handlers = []if silent:# 添加NullHandler以防止"找不到处理器"警告logger.addHandler(logging.NullHandler())else:# 创建日志目录os.makedirs(log_dir, exist_ok=True)# 使用时间戳创建唯一的日志文件名timestamp = time.strftime("%Y%m%d-%H%M%S")log_file = os.path.join(log_dir, f"recommender_{timestamp}.log")# 创建文件处理器(每文件最大10MB,保留5个备份)file_handler = RotatingFileHandler(log_file, maxBytes=10*1024*1024, backupCount=5, encoding="utf-8")file_handler.setLevel(log_level)# 创建控制台处理器console_handler = logging.StreamHandler()console_handler.setLevel(log_level)# 创建格式化器并添加到处理器formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")file_handler.setFormatter(formatter)console_handler.setFormatter(formatter)# 将处理器添加到记录器logger.addHandler(file_handler)logger.addHandler(console_handler)return loggerdef get_logger():"""获取推荐系统日志记录器"""logger = logging.getLogger("recommendation_system")# 如果记录器没有处理器,设置一个默认的静默记录器if not logger.handlers:return setup_logger(silent=True)return logger
3.5 相似度计算模块
def calculate_similarity(ratings_matrix, method="cosine"):"""计算用户相似度矩阵参数:ratings_matrix: 用户-物品评分矩阵method: 相似度计算方法('cosine', 'pearson', 'euclidean', 'adjusted_cosine')返回:similarity: 用户相似度矩阵"""if method == "cosine":return cosine_similarity(ratings_matrix)elif method == "pearson":return pearson_similarity(ratings_matrix)elif method == "euclidean":return euclidean_similarity(ratings_matrix)elif method == "adjusted_cosine":return adjusted_cosine_similarity(ratings_matrix)else:raise ValueError(f"未知的相似度计算方法: {method}")
每种相似度计算方法的具体实现:
def cosine_similarity(ratings_matrix):"""计算余弦相似度"""similarity = 1 - pairwise_distances(ratings_matrix, metric="cosine", n_jobs=-1)similarity = np.nan_to_num(similarity) # 处理NaN值return similaritydef pearson_similarity(ratings_matrix):"""计算皮尔逊相关系数"""similarity = np.corrcoef(ratings_matrix)similarity = np.nan_to_num(similarity) # 处理NaN值return similaritydef euclidean_similarity(ratings_matrix):"""计算基于欧几里得距离的相似度"""distances = pairwise_distances(ratings_matrix, metric="euclidean", n_jobs=-1)similarity = 1 / (1 + distances) # 转换距离为相似度return similaritydef adjusted_cosine_similarity(ratings_matrix):"""计算调整后的余弦相似度"""# 获取非零元素以计算平均值rated_mask = ratings_matrix != 0# 计算用户平均评分(仅考虑已评分项目)user_means = np.sum(ratings_matrix, axis=1) / np.sum(rated_mask, axis=1)# 通过减去用户平均值归一化评分(仅对已评分项目)normalized_matrix = np.zeros_like(ratings_matrix)for i, (user_ratings, mask, mean) in enumerate(zip(ratings_matrix, rated_mask, user_means)):normalized_matrix[i, mask] = user_ratings[mask] - mean# 计算余弦相似度similarity = 1 - pairwise_distances(normalized_matrix, metric="cosine", n_jobs=-1)# 处理NaN值similarity = np.nan_to_num(similarity)return similarity
3.6 评分预测模块
def predict_ratings(ratings_matrix, similarity_matrix, method="bias_weighted", k=10):"""预测用户对物品的评分参数:ratings_matrix: 用户-物品评分矩阵similarity_matrix: 用户相似度矩阵method: 预测方法('simple_weighted', 'bias_weighted')k: 考虑的近邻数量返回:predicted_ratings: 预测评分矩阵"""if method == "simple_weighted":return simple_weighted_average(ratings_matrix, similarity_matrix, k)elif method == "bias_weighted":return bias_weighted_average(ratings_matrix, similarity_matrix, k)else:raise ValueError(f"未知的预测方法: {method}")def bias_weighted_average(ratings_matrix, similarity_matrix, k=10):"""使用考虑用户偏置的加权平均预测评分"""n_users, n_items = ratings_matrix.shapepredicted_ratings = np.zeros((n_users, n_items))# 计算用户平均评分user_rated_mask = ratings_matrix > 0user_ratings_count = np.sum(user_rated_mask, axis=1)user_ratings_sum = np.sum(ratings_matrix, axis=1)# 处理除零问题user_mean_ratings = np.where(user_ratings_count > 0, user_ratings_sum / user_ratings_count, 0)# 为每个用户预测评分for u in range(n_users):# 找到k个最相似用户(不包括自己)user_similarities = similarity_matrix[u]user_similarities[u] = -1 # 排除自己similar_users = np.argsort(user_similarities)[::-1][:k]# 用户的平均评分u_mean = user_mean_ratings[u]# 为每个物品预测评分for i in range(n_items):# 如果用户已经评分,保留原评分if ratings_matrix[u, i] > 0:predicted_ratings[u, i] = ratings_matrix[u, i]continue# 获取评价过该物品的相似用户sim_users_rated = [v for v in similar_users if ratings_matrix[v, i] > 0]# 如果没有相似用户评价过,使用用户平均评分if len(sim_users_rated) == 0:predicted_ratings[u, i] = u_mean if u_mean > 0 else np.mean(ratings_matrix[ratings_matrix > 0])continue# 计算考虑偏置的加权平均sim_sum = sum(abs(similarity_matrix[u, v]) for v in sim_users_rated)if sim_sum == 0:predicted_ratings[u, i] = u_meancontinueweighted_sum = sum(similarity_matrix[u, v] * (ratings_matrix[v, i] - user_mean_ratings[v])for v in sim_users_rated)predicted_rating = u_mean + weighted_sum / sim_sum# 将预测评分限制在有效范围[1,5]predicted_ratings[u, i] = max(1, min(5, predicted_rating))return predicted_ratings
3.7 推荐生成模块
def recommend_items(user_id, ratings_matrix, predicted_ratings, movies_df, top_n=10):"""为特定用户生成电影推荐参数:user_id: 用户ID(从1开始)ratings_matrix: 用户-物品评分矩阵predicted_ratings: 预测评分矩阵movies_df: 电影信息DataFrametop_n: 推荐数量返回:recommendations: 包含推荐电影的DataFrame"""# 调整为0-based索引user_idx = user_id - 1# 获取用户评分user_ratings = ratings_matrix[user_idx]user_predictions = predicted_ratings[user_idx]# 找出用户未评分的物品unrated_items = np.where(user_ratings == 0)[0]# 如果用户已评分所有物品,返回空DataFrameif len(unrated_items) == 0:return pd.DataFrame(columns=["movie_id", "movie_title", "predicted_rating"])# 获取未评分物品的预测评分unrated_predictions = user_predictions[unrated_items]# 按预测评分降序排序sorted_indices = np.argsort(-unrated_predictions)# 获取top_n推荐top_item_indices = sorted_indices[:top_n]top_items = unrated_items[top_item_indices]top_ratings = unrated_predictions[top_item_indices]# 转换为1-based电影IDmovie_ids = top_items + 1# 创建推荐DataFramerecommendations = pd.DataFrame({"movie_id": movie_ids,"predicted_rating": top_ratings})# 合并电影信息recommendations = recommendations.merge(movies_df[["movie_id", "movie_title"]], on="movie_id")# 按预测评分降序排序recommendations = recommendations.sort_values("predicted_rating", ascending=False)return recommendations

3.8 评估模块
def evaluate_recommendations(test_data, predicted_ratings, ratings_matrix=None, k_values=[5, 10], threshold=3.5):"""对推荐系统性能进行全面评估参数:test_data: 测试集DataFramepredicted_ratings: 预测评分矩阵ratings_matrix: 原始评分矩阵k_values: 评估的k值列表threshold: 判定物品相关性的评分阈值返回:results: 包含各项评估指标的字典"""# 评估评分预测rating_metrics = evaluate_rating_predictions(test_data, predicted_ratings)# 初始化结果字典results = rating_metrics.copy()# 评估top-k推荐for k in k_values:pr_metrics = calculate_precision_recall_at_k(test_data, predicted_ratings, ratings_matrix=ratings_matrix, k=k, threshold=threshold)precision_key = f"precision@{k}"recall_key = f"recall@{k}"results[precision_key] = pr_metrics[precision_key]results[recall_key] = pr_metrics[recall_key]# 计算F1分数precision = pr_metrics[precision_key]recall = pr_metrics[recall_key]f1 = calculate_f1_score(precision, recall)results[f"f1@{k}"] = f1return results
3.9 完整推荐系统模型
class UserBasedCF:"""基于用户的协同过滤推荐系统这个类实现了一个完整的推荐系统,使用基于用户的协同过滤算法。它通过识别具有相似评分模式的用户,并推荐这些相似用户喜欢但目标用户尚未体验的物品。"""def __init__(self, similarity_method="cosine", prediction_method="bias_weighted", k=30):"""初始化推荐系统模型参数:similarity_method: 计算用户相似度的方法prediction_method: 预测评分的方法k: 考虑的相似用户数量"""self.logger = get_logger()self.logger.info(f"初始化UserBasedCF模型,相似度方法={similarity_method},"f"预测方法={prediction_method},k={k}")self.similarity_method = similarity_methodself.prediction_method = prediction_methodself.k = k# 初始化数据属性self.ratings_df = Noneself.movies_df = Noneself.train_data = Noneself.test_data = Noneself.ratings_matrix = Noneself.user_similarity = Noneself.predicted_ratings = Noneself.n_users = Noneself.n_items = None# 跟踪模型是否已训练self.is_trained = Falsedef fit(self, ratings_df, movies_df=None, test_size=0.2, random_state=42):"""训练推荐模型参数:ratings_df: 包含评分数据的DataFramemovies_df: 包含电影信息的DataFrametest_size: 用于测试的数据比例random_state: 随机数种子返回:self: 训练后的模型实例"""from sklearn.model_selection import train_test_splitself.logger.info("开始模型训练")train_start = time.time()# 存储数据self.ratings_df = ratings_dfself.movies_df = movies_df# 获取维度self.n_users = ratings_df["user_id"].max()self.n_items = ratings_df["item_id"].max()self.logger.info(f"使用{self.n_users}个用户和{self.n_items}个物品训练模型")# 如果test_size>0,划分数据if test_size > 0:self.logger.info(f"划分数据,test_size={test_size},random_state={random_state}")split_start = time.time()self.train_data, self.test_data = train_test_split(ratings_df, test_size=test_size, random_state=random_state)split_time = time.time() - split_startself.logger.info(f"数据划分耗时{split_time:.2f}秒: {len(self.train_data)}训练样本,{len(self.test_data)}测试样本")else:self.train_data = ratings_dfself.test_data = Noneself.logger.info("使用所有数据进行训练(无测试集)")# 创建评分矩阵self.logger.info("从训练数据创建评分矩阵")matrix_start = time.time()self.ratings_matrix = np.zeros((self.n_users, self.n_items))for row in self.train_data.itertuples():# 调整为0-based索引user_idx = row.user_id - 1item_idx = row.item_id - 1self.ratings_matrix[user_idx, item_idx] = row.ratingmatrix_time = time.time() - matrix_startself.logger.info(f"评分矩阵创建耗时{matrix_time:.2f}秒")# 计算矩阵密度n_ratings = np.sum(self.ratings_matrix > 0)density = n_ratings / (self.n_users * self.n_items)self.logger.info(f"评分矩阵密度: {density:.6f} ({n_ratings}条评分)")# 计算用户相似度self.logger.info(f"使用{self.similarity_method}方法计算用户相似度")sim_start = time.time()self.user_similarity = calculate_similarity(self.ratings_matrix, method=self.similarity_method)sim_time = time.time() - sim_startself.logger.info(f"用户相似度计算耗时{sim_time:.2f}秒")# 预测评分self.logger.info(f"使用{self.prediction_method}方法预测评分,k={self.k}")pred_start = time.time()self.predicted_ratings = predict_ratings(self.ratings_matrix,self.user_similarity,method=self.prediction_method,k=self.k)pred_time = time.time() - pred_startself.logger.info(f"评分预测耗时{pred_time:.2f}秒")# 标记模型为已训练self.is_trained = Truetotal_time = time.time() - train_startself.logger.info(f"模型训练完成,总耗时{total_time:.2f}秒")return self
3.10 命令行接口设计
为了方便用户使用推荐系统,我们设计了一个功能丰富的命令行接口:
def parse_args():"""解析命令行参数"""parser = argparse.ArgumentParser(description="基于用户的协同过滤推荐系统")# 数据参数parser.add_argument("--data_path",type=str,default="data/ml-100k",help="MovieLens数据集目录路径")# 模型参数parser.add_argument("--similarity",type=str,default="cosine",choices=["cosine", "pearson", "euclidean", "adjusted_cosine"],help="使用的相似度度量")parser.add_argument("--prediction",type=str,default="bias_weighted",choices=["simple_weighted", "bias_weighted"],help="使用的预测方法")parser.add_argument("--k",type=int,default=30,help="考虑的相似用户数量")# 输出目录参数parser.add_argument("--output_dir",type=str,default="results",help="保存可视化输出的目录")parser.add_argument("--log_dir",type=str,default="results/logs",help="保存日志文件的目录")parser.add_argument("--log_level",type=str,default="INFO",choices=["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"],help="日志级别")# 推荐参数parser.add_argument("--user_id",type=int,required=False,help="为其生成推荐的用户ID")parser.add_argument("--num_recommendations",type=int,default=10,help="生成的推荐数量")# 评估参数parser.add_argument("--test_size",type=float,default=0.2,help="用于测试的数据比例")parser.add_argument("--evaluate",action="store_true",help="评估模型")# 可视化参数parser.add_argument("--visualize",action="store_true",help="可视化用户相似度和推荐")# 模型保存/加载parser.add_argument("--save_model",type=str,default=None,help="保存训练模型的路径")parser.add_argument("--load_model",type=str,default=None,help="加载预训练模型的路径")# 参数调优parser.add_argument("--tune",action="store_true",help="执行参数调优")return parser.parse_args()
使用示例:
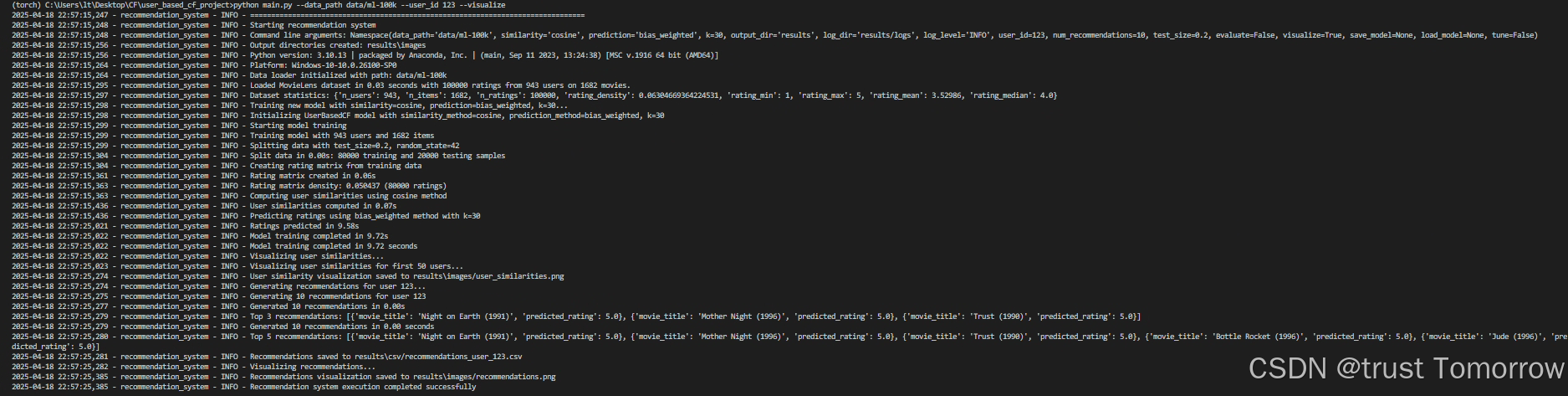
# 生成推荐
python main.py --user_id 123 --num_recommendations 10 --similarity cosine --k 30# 评估模型
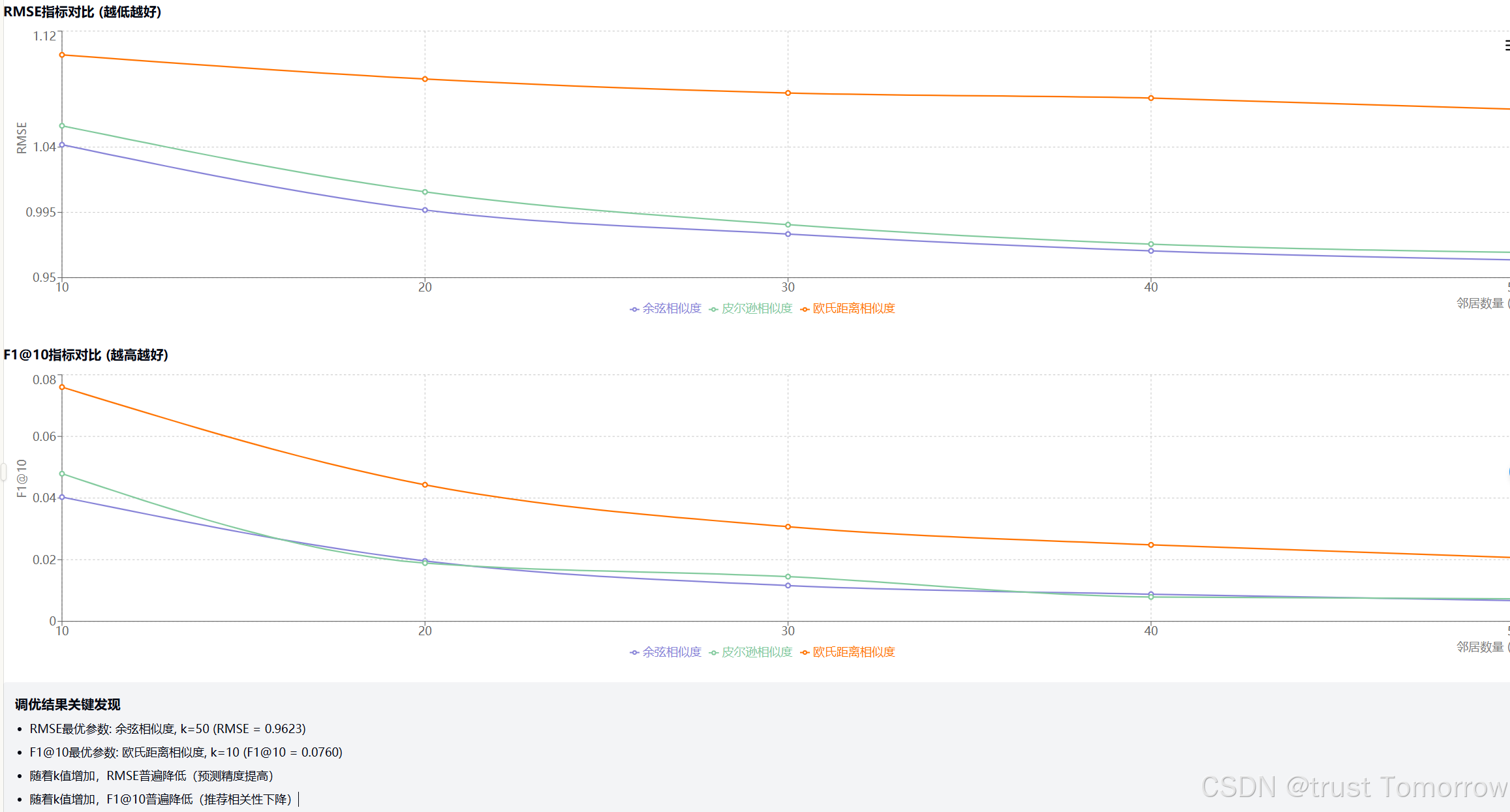
python main.py --evaluate --test_size 0.2# 参数调优
python main.py --tune --output_dir results# 保存和加载模型
python main.py --similarity pearson --k 40 --save_model models/my_model.pkl
python main.py --load_model models/my_model.pkl --user_id 123
3.11 模型序列化与反序列化
对于训练好的模型,我们提供了保存和加载功能,以便在不同环境中复用:
def save_model(self, filepath):"""将训练好的模型保存到文件参数:filepath: 保存模型的路径"""if not self.is_trained:error_msg = "模型未训练。保存前请先调用fit()"self.logger.error(error_msg)raise ValueError(error_msg)self.logger.info(f"保存模型到{filepath}")# 如果目录不存在则创建os.makedirs(os.path.dirname(filepath), exist_ok=True)import picklemodel_data = {"similarity_method": self.similarity_method,"prediction_method": self.prediction_method,"k": self.k,"ratings_matrix": self.ratings_matrix,"user_similarity": self.user_similarity,"predicted_ratings": self.predicted_ratings,"n_users": self.n_users,"n_items": self.n_items,"is_trained": self.is_trained}save_start = time.time()with open(filepath, "wb") as f:pickle.dump(model_data, f)save_time = time.time() - save_start# 计算文件大小file_size = os.path.getsize(filepath) / (1024 * 1024) # MBself.logger.info(f"模型已保存到{filepath} ({file_size:.2f} MB),耗时{save_time:.2f}秒")@classmethod
def load_model(cls, filepath, movies_df=None):"""从文件加载训练好的模型参数:filepath: 模型文件路径movies_df: 电影信息DataFrame返回:model: 加载的模型实例"""logger = get_logger()logger.info(f"从{filepath}加载模型")if not os.path.exists(filepath):error_msg = f"模型文件{filepath}不存在"logger.error(error_msg)raise FileNotFoundError(error_msg)import pickleload_start = time.time()with open(filepath, "rb") as f:model_data = pickle.load(f)load_time = time.time() - load_start# 创建新实例model = cls(similarity_method=model_data["similarity_method"],prediction_method=model_data["prediction_method"],k=model_data["k"])# 恢复模型属性model.ratings_matrix = model_data["ratings_matrix"]model.user_similarity = model_data["user_similarity"]model.predicted_ratings = model_data["predicted_ratings"]model.n_users = model_data["n_users"]model.n_items = model_data["n_items"]model.is_trained = model_data["is_trained"]model.movies_df = movies_df# 计算文件大小file_size = os.path.getsize(filepath) / (1024 * 1024) # MBlogger.info(f"从{filepath}加载模型 ({file_size:.2f} MB),耗时{load_time:.2f}秒")logger.info(f"模型维度: {model.n_users}用户, {model.n_items}物品")return model
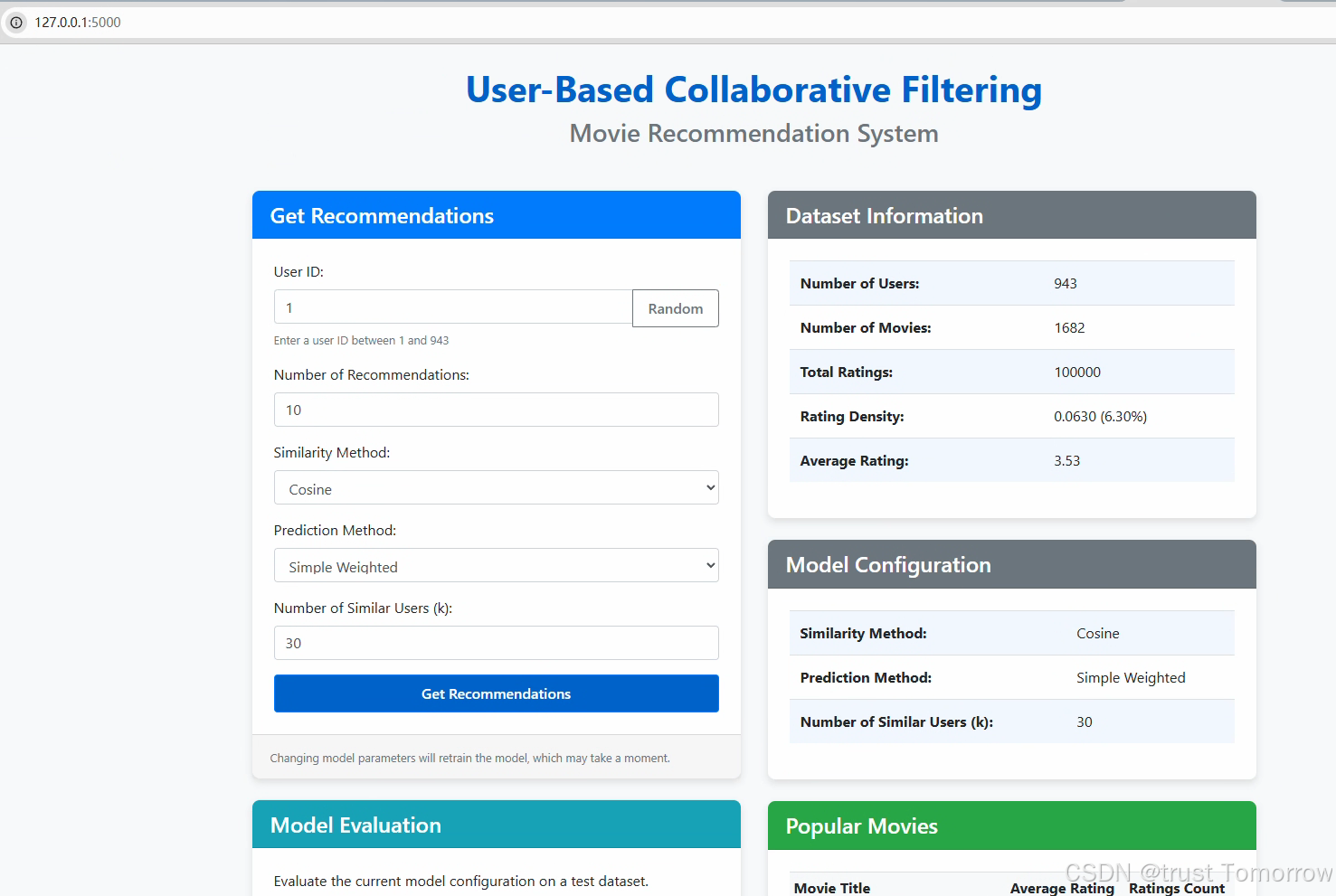
3.12 Web应用开发
为了提供友好的用户界面,我们使用Flask开发了一个Web应用:
from flask import Flask, render_template, request, redirect, url_for, flash, jsonify, send_fileapp = Flask(__name__)
app.secret_key = os.urandom(24)# 全局变量
data_loader = None
model = None
MODEL_PATH = "../models/user_based_cf.pkl"
DATA_PATH = "../data/ml-100k"
OUTPUT_DIR = "../results"# 创建目录
os.makedirs(os.path.dirname(MODEL_PATH), exist_ok=True)
os.makedirs(os.path.join(OUTPUT_DIR, "images"), exist_ok=True)def initialize_data_and_model():"""初始化数据加载器和模型"""global data_loader, modellogger.info("初始化数据和模型...")# 初始化数据加载器并加载数据if data_loader is None:try:data_loader = DataLoader(data_path=DATA_PATH)ratings_df, movies_df = data_loader.load_data()logger.info(f"数据加载完成: {len(ratings_df)}条评分, {len(movies_df)}部电影")except Exception as e:logger.error(f"加载数据出错: {str(e)}")logger.error(traceback.format_exc())return False# 初始化模型(如果未加载)if model is None:try:# 检查是否存在预训练模型if os.path.exists(MODEL_PATH):logger.info(f"从{MODEL_PATH}加载预训练模型")model = UserBasedCF.load_model(MODEL_PATH, movies_df=data_loader.movies_df)else:logger.info("使用默认参数训练新模型")model = UserBasedCF(similarity_method="cosine", prediction_method="bias_weighted", k=30)model.fit(data_loader.ratings_df, data_loader.movies_df, test_size=0)# 保存模型以供将来使用model.save_model(MODEL_PATH)logger.info(f"模型训练完成并保存到{MODEL_PATH}")except Exception as e:logger.error(f"初始化模型出错: {str(e)}")logger.error(traceback.format_exc())return Falsereturn True@app.route("/")
def index():"""渲染首页"""# 初始化数据和模型if not initialize_data_and_model():flash("初始化数据和模型出错,请检查日志", "danger")# 如果模型已初始化,获取模型参数model_params = {}if model and model.is_trained:model_params = {"similarity_method": model.similarity_method,"prediction_method": model.prediction_method,"k": model.k,"n_users": model.n_users,"n_items": model.n_items}# 获取可用的相似度和预测方法similarity_methods = ["cosine", "pearson", "euclidean", "adjusted_cosine"]prediction_methods = ["simple_weighted", "bias_weighted"]# 获取数据集统计信息dataset_stats = {}if data_loader:dataset_stats = data_loader.get_dataset_stats()return render_template("index.html",model_params=model_params,similarity_methods=similarity_methods,prediction_methods=prediction_methods,dataset_stats=dataset_stats)@app.route("/recommend", methods=["GET", "POST"])
def recommend():"""基于表单输入或URL参数生成推荐"""# 初始化数据和模型if not initialize_data_and_model():flash("初始化数据和模型出错,请检查日志", "danger")return redirect(url_for("index"))# 提取当前模型参数作为默认值current_similarity = model.similarity_method or "cosine"current_prediction = model.prediction_method or "bias_weighted"current_k = model.k or 30# 根据请求方法提取参数if request.method == "POST":# 获取表单数据user_id = int(request.form.get("user_id", 1))num_recommendations = int(request.form.get("num_recommendations", 10))similarity_method = request.form.get("similarity_method", current_similarity)prediction_method = request.form.get("prediction_method", current_prediction)k = int(request.form.get("k", current_k))else: # GET请求# 获取URL参数user_id = int(float(request.args.get("user_id", "1")))# 验证user_id在有效范围内if user_id < 1 or user_id > model.n_users:flash(f"无效的用户ID: {user_id}。必须在1到{model.n_users}之间", "danger")return redirect(url_for("index"))num_recommendations = int(request.args.get("num_recommendations", 10))similarity_method = request.args.get("similarity_method", current_similarity)prediction_method = request.args.get("prediction_method", current_prediction)k = int(request.args.get("k", current_k))# 确保参数不为Nonesimilarity_method = similarity_method or "cosine"prediction_method = prediction_method or "bias_weighted"k = k or 30logger.info(f"推荐参数: user_id={user_id}, similarity={similarity_method}, prediction={prediction_method}, k={k}")# 检查是否需要重新训练模型retrain = model.similarity_method != similarity_method or model.prediction_method != prediction_method or model.k != k# 如需要,重新训练if retrain:try:logger.info(f"使用参数重新训练模型: similarity={similarity_method}, prediction={prediction_method}, k={k}")model = UserBasedCF(similarity_method=similarity_method,prediction_method=prediction_method,k=k)model.fit(data_loader.ratings_df, data_loader.movies_df, test_size=0)# 保存重新训练的模型model.save_model(MODEL_PATH)logger.info("模型重新训练完成并保存")except Exception as e:logger.error(f"重新训练模型出错: {str(e)}")logger.error(traceback.format_exc())flash(f"重新训练模型出错: {str(e)}", "danger")return redirect(url_for("index"))# 生成推荐try:start_time = time.time()recommendations = model.recommend(user_id, top_n=num_recommendations)generation_time = time.time() - start_time# 可视化推荐img_path = Noneif not recommendations.empty:img_path = visualize_recommendations(user_id, recommendations)# 获取用户当前评分(如果有)user_ratings = Noneif data_loader:try:user_ratings = data_loader.get_user_ratings(user_id)# 按评分降序排序user_ratings = user_ratings.sort_values("rating", ascending=False)except:pass# 获取相似用户similar_users = Nonetry:similar_users = model.get_similar_users(user_id, top_n=5)except:passreturn render_template("recommendations.html",user_id=user_id,recommendations=recommendations,generation_time=generation_time,img_path=img_path,user_ratings=user_ratings,similar_users=similar_users,model_params={"similarity_method": model.similarity_method,"prediction_method": model.prediction_method,"k": model.k})except Exception as e:logger.error(f"生成推荐出错: {str(e)}")logger.error(traceback.format_exc())flash(f"生成推荐出错: {str(e)}", "danger")return redirect(url_for("index"))
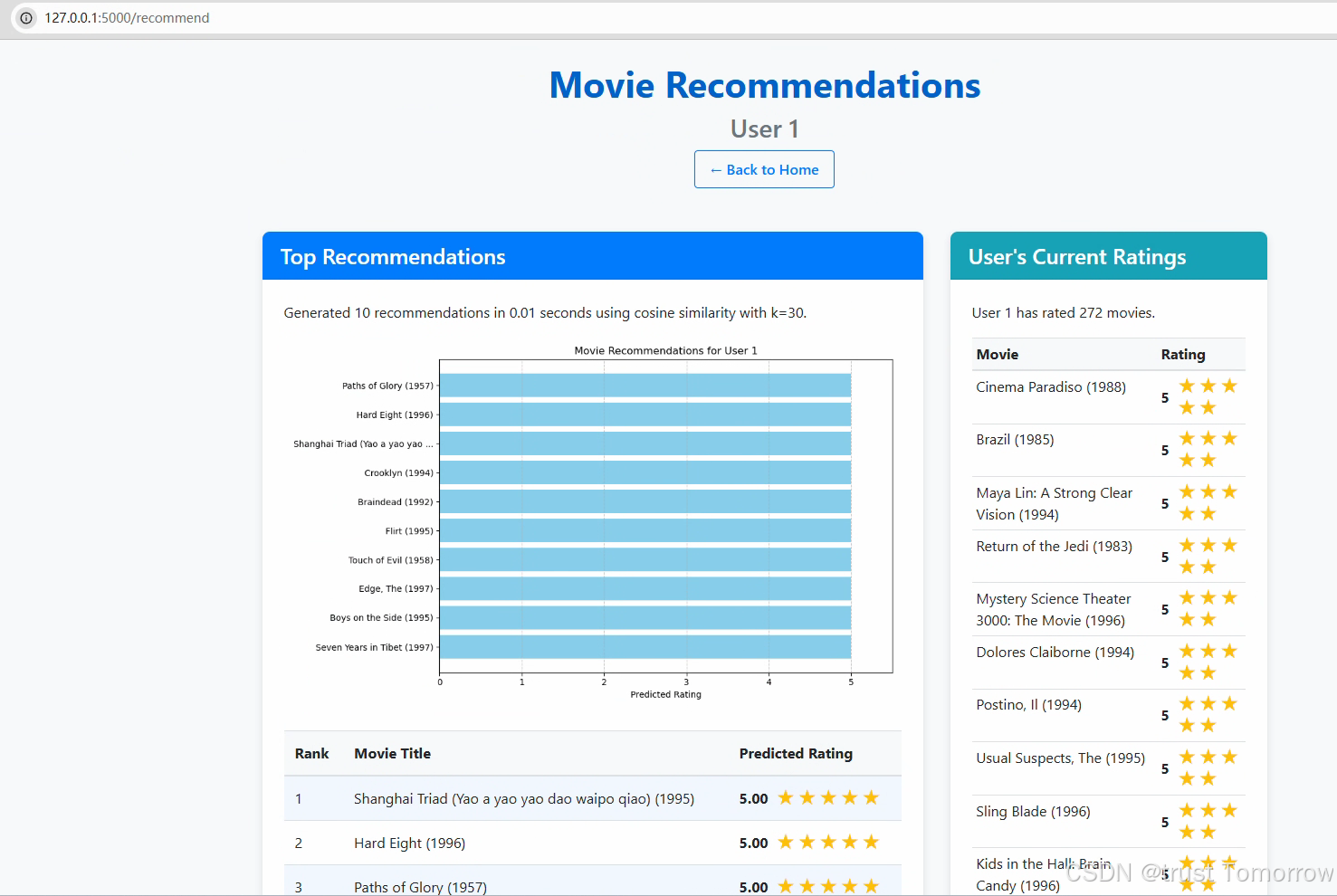
3.13 性能优化与错误处理
为了提高系统性能并增强鲁棒性,我们实现了以下优化与错误处理机制:
# 矩阵运算优化
# 使用向量化操作代替循环
def calculate_similarity_optimized(ratings_matrix, method="cosine"):"""优化的相似度计算函数"""# 利用多核加速计算return 1 - pairwise_distances(ratings_matrix, metric=method, n_jobs=-1)# 大规模数据处理:使用稀疏矩阵表示
def create_sparse_matrix(self):"""创建稀疏评分矩阵以节省内存"""from scipy.sparse import csr_matrixrows, cols, data = [], [], []for row in self.ratings_df.itertuples():rows.append(row.user_id - 1)cols.append(row.item_id - 1)data.append(row.rating)self.sparse_ratings_matrix = csr_matrix((data, (rows, cols)), shape=(self.n_users, self.n_items))return self.sparse_ratings_matrix# 异常处理与数据验证
def recommend(self, user_id, top_n=10):"""带异常处理的推荐函数"""# 验证模型状态if not self.is_trained:raise ValueError("模型未训练,请先调用fit()")# 验证用户IDif user_id < 1 or user_id > self.n_users:raise ValueError(f"无效的用户ID: {user_id}。必须在1到{self.n_users}之间")# 验证参数if top_n < 1:raise ValueError(f"无效的推荐数量: {top_n}。必须大于0")# 验证必要的数据是否可用if self.movies_df is None:raise ValueError("缺少电影信息。请在fit()中提供movies_df")# 生成推荐try:return recommend_items(user_id, self.ratings_matrix, self.predicted_ratings, self.movies_df, top_n)except Exception as e:self.logger.error(f"为用户{user_id}生成推荐时出错: {str(e)}")# 重新抛出异常,附加上下文信息raise RuntimeError(f"推荐生成失败: {str(e)}")
5. 模块化设计的优势
采用模块化设计使得我们的推荐系统具有以下优势:
- 代码可维护性:每个模块专注于单一功能,便于理解和修改
- 可扩展性:可以轻松添加新的相似度计算方法或评分预测算法
- 可重用性:各个组件可以在其他项目中重用
- 测试便利性:可以独立测试每个模块的功能
- 团队协作:不同团队成员可以同时开发不同模块
6. 结论与未来工作
本项目成功实现了一个基于用户的协同过滤推荐系统,并在MovieLens 100K数据集上进行了评估。系统具有以下特点:
- 模块化设计:清晰的代码结构,便于维护和扩展
- 多种算法支持:实现了多种相似度计算和评分预测方法
- 完整的评估体系:使用RMSE、MAE、精确率、召回率等指标全面评估性能
- 用户友好界面:提供命令行和Web两种交互方式
- 日志和错误处理:完善的日志系统和健壮的错误处理机制
7. 参考资料
- Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., & Riedl, J. (1994). GroupLens: An Open Architecture for Collaborative Filtering of Netnews. Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work.
- Breese, J. S., Heckerman, D., & Kadie, C. (1998). Empirical Analysis of Predictive Algorithms for Collaborative Filtering. Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence.
- Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (2001). Item-based collaborative filtering recommendation algorithms. Proceedings of the 10th International Conference on World Wide Web.
- Harper, F. M., & Konstan, J. A. (2015). The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS).
- Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37.
- Ning, X., Desrosiers, C., & Karypis, G. (2015). A comprehensive survey of neighborhood-based recommendation methods. Recommender systems handbook, 37-76.