游戏引擎学习第234天:实现基数排序
回顾并为今天的内容设定背景
我们今天继续进行排序的相关,虽然基本已经完成了,但还是想收尾一下,让整个流程更完整。其实这次排序只是个借口,主要是想顺便聊一聊一些计算机科学的知识点,这些内容在我们项目中平时不会特别讲,更多是适合做一些自学延伸的内容。
回顾上周五的进度,当时我们尝试实现就地归并排序(merge sort in-place),结果发现这个做法并不可行。原因是操作成本太高,为了实现就地排序,我们必须执行大量的数据移动,而这些操作虽然逻辑上不复杂,但代价很大。
因此我们最终放弃了就地排序的尝试,转而采用了非就地的方式来实现归并排序。这个版本非常容易实现,我们在短短几分钟内就完成了代码编写,而且运行效果良好。
目前这部分排序已经可以正常工作,接下来就可以继续在已有基础上推进后续的开发了。
game_render_group.cpp:将冒泡排序功能提取为独立函数
我们现在可以随时自由选择使用冒泡排序或归并排序,甚至可以为了方便使用者或玩家,专门实现一个通用的接口,让他们自行选择是使用冒泡排序还是归并排序。
具体实现上,我们先实现了冒泡排序。在代码中,我们可以简单地调用冒泡排序函数,同时传入待排序的数据、计数器、临时空间等参数。然后我们也可以选择调用归并排序,两者都已经准备好,因此可以根据需要灵活切换。
我们所做的事情,其实就是把冒泡排序和归并排序这两部分的逻辑提取出来,使它们变成可单独调用的函数。没有做其他额外的处理,只是把排序算法模块化了。现在这两个排序算法都已经被整理好了,实现也不复杂,结构清晰,便于调用。
另外,有人提到对基数排序感兴趣。虽然不确定大家是否真的那么热衷于这个算法,但如果确实有兴趣,那当然是件好事。对新事物保持好奇和兴奋总是好的。


黑板:基数排序(Radix Sort)
基数排序是一种非比较型的排序算法,适用于对整数或可以转化为整数形式的数据进行排序。其核心思想是将待排序的元素按照位数(或称“基数”)进行分组排序,从最低位到最高位,逐位进行排序操作,最终达到整体有序的目的。
基数排序通常分为两种方式:LSD(Least Significant Digit) 和 MSD(Most Significant Digit)。LSD 方法是从最低有效位开始排序,逐步向高位推进,而 MSD 方法则相反,从最高有效位开始排序,逐层深入到低位。
在具体实现中,基数排序通常依赖于一种稳定的子排序算法,如计数排序。在每一位上进行排序时,借助计数排序保证相同位值的数据相对位置不变,从而确保整个排序过程的正确性和稳定性。
以十进制整数为例,如果最大数是三位数,那么排序将进行三轮。第一轮根据个位数排序,第二轮根据十位数排序,最后一轮根据百位数排序。通过每一轮的稳定排序,最终能使所有数据按从小到大的顺序排列好。
基数排序的时间复杂度为 O(k·n),其中 n 是元素个数,k 是数字的位数。这种算法在处理大量、位数不多的整数时效率非常高,并且由于不涉及元素之间的比较,避免了比较排序算法的时间复杂度下限 O(n log n)。
然而,基数排序也有局限性。它依赖于输入数据的格式,对非整数或高位数的数据处理效率不如通用的比较型排序算法。此外,它在空间上需要额外的内存来存储每一轮排序的中间结果,比如使用桶或队列来临时存放元素。
总体来看,基数排序在特定场景下是一种高效的排序方案,特别适用于对大量、范围有限的整数进行排序操作。
黑板:“稳定排序”(Stable Sort)
稳定排序的概念是,排序过程中如果两个元素在排序条件下是“相等”的,那么它们在原始列表中的先后顺序在排序结果中也必须保持不变。也就是说,排序算法不会随意改变那些不需要调整位置的元素之间的相对位置。
具体来说,假设我们有一组数据,排序的依据是某个特定的字段或属性,例如字符串的首字母。我们并不关注字符串中的第二个字符、第三个字符等其他部分,只要求根据首字母进行排序。在这种情况下,只要两个元素的首字母相同,那么它们之间就没有进一步的排序依据。此时,如果排序后它们的相对位置发生了变化,那就是一个不稳定的排序;反之,如果仍然按照它们原来的顺序排列,那就是稳定排序。
举个例子,假设原始数据是:
avc
aec
abc
adc
这几个字符串的首字母都是 a,根据排序规则,它们被视为相等项。在排序时,如果我们采用稳定排序,它们在结果中的相对顺序应该是 avc → aec → abc → adc,顺序保持不变。稳定排序要求在无法通过主排序关键字区分这些项时,保留它们在原始输入中的先后顺序作为“次要排序依据”。
可以将这个过程理解为在排序的主键之外,隐含地加入了元素在原始列表中的位置信息作为次级排序标准,从而保持排序的稳定性。实际上,只要在排序键中附加一个原始索引(例如把排序键变成“主键 + 原始位置”),那么任何排序都可以转化为稳定排序。这是一个通用的策略,使得非稳定排序也能具备稳定性的性质。
稳定排序在很多应用场景中非常重要,特别是在多层排序(即排序中涉及多个字段或属性)中。例如,先根据一个字段排序,再根据另一个字段排序时,如果第二次排序是稳定的,就能保证第一轮排序的结果在第二轮中不被打乱。
因此,稳定排序的核心是:在主排序键相等的前提下,保留元素原始的相对顺序。只有在排序算法中需要改变元素位置时,才真正改变;不需要改变的地方,则应尽可能保持原样。这样才能确保整个排序操作在逻辑上是一致、可预测、且有意义的。
黑板:“对排序关键字的某些部分,进行连续多次稳定排序”
Radix排序(基数排序)的核心思想是:将整个排序过程拆解成多个“稳定排序”,每次只根据排序键的一部分进行排序。通过不断地对排序键的不同部分进行稳定排序,最终得到完整有序的结果。这是一个非常系统、可控的排序策略,尤其适用于数值型或结构化键值的排序。
一、Radix排序的基本概念
我们先从一个直观的定义出发:Radix排序其实就是对排序键的不同部分,进行一系列连续的稳定排序。排序的每一步都只关注键的一部分,不考虑其余部分。最终通过这些步骤的累积,将整个数组排序完成。
二、以32位无符号整数为例
假设我们要对一组32位无符号整数进行排序。每个数都是由32个二进制位构成,我们可以将其划分为4个8位(1字节)的部分,从低位到高位依次编号:
- 第0字节:bit 0–7
- 第1字节:bit 8–15
- 第2字节:bit 16–23
- 第3字节:bit 24–31(最高位)
每个字节都有256种可能的取值(0~255),这使得我们可以方便地对这些“片段”进行排序。Radix排序就是按照低位到高位的顺序,分别对这四个字节进行稳定排序,最终整个数列就会按大小有序。
三、为什么要从低位到高位排序?
关键在于排序的稳定性:
- 如果我们先对最低有效位(LSB)排序,并使用稳定排序算法(比如Counting Sort),排序后原始顺序不会被打乱;
- 接着我们对次低位进行排序,由于上一步的排序已经确保了在该位相等时其余部分是有序的,所以接下来这一步只需对该位进行排序,其余部分的顺序将自动得到维护;
- 按照这种方式一层一层地往上排序,直到最高位,最终整个数列就被完全有序。
稳定排序在这里的作用是传递之前步骤的排序结果,也就是让低位的排序“嵌入”在高位排序中不被破坏。
四、从“位权”理解排序顺序
以数字的十进制表示举例:
207
101
100
106
107
显然,我们应该先比较“百位”,再看“十位”,最后才看“个位”。如果我们先对“个位”排序,是没有意义的,因为百位决定整体的数量级。同理,在二进制中,最高位的重要性最大,最低位的影响最小。因此,在Radix排序中我们必须从低位往高位排序,配合稳定排序,让信息逐步传递,最终形成全局的正确顺序。
五、实际操作中如何执行
设想我们有一个整型数组,每个数被划分成4个字节。我们对它进行四轮排序:
- 第一轮:根据最低8位排序(bit 0–7)
- 第二轮:根据下一个8位排序(bit 8–15)
- 第三轮:继续向上(bit 16–23)
- 第四轮:最高8位(bit 24–31)
每轮排序都使用稳定排序算法,确保在当前字段相同的情况下,保留之前字段排序的相对顺序。这样最终得到的结果就是整体升序排列。
六、为什么要进行多次排序?它的优势在哪里?
当我们将排序键划分为较小的片段(例如每个片段8位,256种可能值),那么每一轮排序的复杂度就变得非常可控。特别是在处理大规模数据时,这种方法相比于传统比较型排序(如快速排序、归并排序等)具有显著优势:
- 避免大量比较操作:Radix排序是非比较型排序,适合处理结构规则的键值(如整数、字符串等);
- 时间复杂度更优:在理想情况下,其时间复杂度为 O(n·k),其中 k 是键的长度(例如 4 字节);
- 适合并行处理:每轮排序相对独立,便于实现并行化和优化;
七、小结
Radix排序的核心流程如下:
- 将排序键分成若干部分(如按字节切分);
- 从最低位开始,依次向高位进行稳定排序;
- 经过每一轮的稳定排序后,排序状态逐步逼近最终顺序;
- 排完所有部分后,整体顺序即为正确结果。
这种方法本质上是一种分治式、逐层精化的排序策略。它不是从整体直接得出结果,而是通过一系列稳定排序,将“局部排序”的结果递进式地积累为“全局有序”的序列。只要排序键可以被切分并进行独立比较,就可以应用这种方法,具有极大的适应性和扩展性。
黑板:8位处理
我们知道,8位(二进制)可以表示的数值范围是256种可能,即从0到255。也就是说,一个8位的数据最多只有256种不同的取值。
在现代计算机上,处理这种数量级的数据是非常轻松的。例如,我们可以轻松地声明一个大小为256的整型数组:
int count[256];
这对于内存和性能来说完全不是负担,几乎没有人会对这种操作感到意外或者担忧。
这一事实非常重要,因为它意味着我们在处理排序任务时,如果能够把一个大的问题(比如一个复杂的排序键)切分成足够小、足够有限的片段(如每次只处理8位),那么我们就能充分利用查表或桶(bucket)式的方式来显著减少实际的计算量和操作复杂度。
举个例子,如果我们知道某一轮排序的关键字段只有256种可能的取值,那我们就可以:
- 创建256个“桶”或计数器(如数组
count[256]); - 快速地统计每个值出现的频率;
- 紧接着计算出每个值在排序后应该出现的位置(通过前缀和等方式);
- 最后将数据搬运到目标位置中去。
这一过程的效率非常高,因为我们不需要进行大量的比较操作,完全可以通过简单的数组索引操作和线性扫描完成。这种方式正是计数排序(Counting Sort)的基础,也是基数排序(Radix Sort)中每一轮排序的核心手段。
所以,将排序键切成小片段,每片只有少量可能取值,不仅能让我们使用更简单高效的逻辑进行排序,还能极大提升整体排序的性能。这就是将排序键“压缩”为8位之后带来的巨大优势 —— 可控、快速、易于实现和优化。
黑板:讲解基数排序的工作原理
在基数排序(Radix Sort)中,我们所做的事情正是利用固定长度的排序键来进行分段处理。假设我们已经将排序键切分成字节(byte),每个字节只有8位,那么每一轮排序只需要处理 256 种可能的键值(即0到255)。这个规模在现代计算机上是非常容易处理的。
我们所做的第一步是建立一个计数表,这个表记录了每种键值出现的次数。比如我们可以创建一个长度为256的数组 count[256],初始值为0。接着我们扫描整个数组中的元素,根据当前字节段的值将对应 count[x] 加1。这一过程的时间复杂度是 O(n),因为我们只遍历一遍数据。
以十进制为例,我们可以建立一个大小为10的计数表。假如我们在处理个位数的一轮排序中,遇到了若干元素,其个位数分别为0、1、6、7等,我们在 count 表中统计每个数值出现的次数,例如:
count[0] = 1count[1] = 2count[6] = 2count[7] = 2
接下来我们进行第二遍遍历,根据之前的计数信息,将每个元素放到正确的位置中。这是基于“该值之前有多少个比它小或等于它的元素”来决定其位置。由于我们提前知道了每种值的数量,所以可以准确无误地将其分布到目标位置上。这一过程同样是 O(n)。
因此,一轮这样的排序过程(统计+分发)总共需要 2n 的时间复杂度。
对于32位的无符号整数排序,我们可以将整个排序键分成4个字节,每次处理8位。也就是说,我们需要进行 4次这样的排序过程,总的时间复杂度为:
4 × 2n = 8n
这是一个线性的时间复杂度(O(n)),常数因子为8。相比之下,像常见的比较类排序算法(如快速排序、归并排序等),其最优复杂度为 O(n log n),而最坏情况下甚至可能达到 O(n²)。举例来说:
- 对40亿个元素进行快速排序,log₂(4,000,000,000) ≈ 32,所以整体为 40亿 × 32 = 1280亿次操作;
- 但使用基数排序只需要 40亿 × 8 = 320亿次操作;
我们可以清楚地看到,当数据量极大时,基数排序在理论上的效率优势是非常明显的。
当然,这一切的前提是排序键具有有限精度和固定长度,比如32位整数或者其他离散的、可分割的值。如果是无限精度或高动态范围的数据(例如高精度浮点数或变长字符串),基数排序将难以胜任,因为我们无法合理地分段、建立计数结构来处理它。
不过,我们在实际计算中处理的绝大多数数据都是有限精度的数字,这就为基数排序的应用提供了极大的现实基础。
最后,我们需要处理一种特殊情况 —— 如果排序键是浮点数,而不是整数。那么我们就必须做一些额外的转换和处理,才能将其变成可用于基数排序的形式。这将涉及对浮点数的内部二进制格式进行解释或调整。我们可以先把基数排序逻辑实现出来,再单独考虑如何将浮点数转换成适合排序的格式。
game_render_group.cpp:引入 RadixSort 函数
我们实现了一个 Radix Sort(基数排序)的完整流程,以下是详细的中文总结说明:
我们要用基数排序来替代之前的排序方式。由于传入的数据是最多 32 位的(比如最多 2^32 个不同的键),我们知道排序的键不会超过 4,294,967,296 个。所以,我们可以将这个键拆成四个字节(byte)来进行排序,也就是四次稳定排序,每次按 8 位来处理。
一、整体思路
我们每次处理一个字节(8 位),这意味着每次排序只会有 256 个可能的键(0~255),所以我们可以用一个长度为 256 的数组来统计这个字节上每个值出现了多少次。
每次排序分为两个阶段:
- **第一次遍历:**统计当前字节上各个键值的出现次数(称为“计数表”)。
- **第二次遍历:**根据计数表推导出每个键值在输出数组中的起始位置(变成偏移表),再把元素放入正确的位置。
由于一个 32 位数有 4 个字节,我们总共要执行 4 次这样的两阶段遍历,从最低有效字节(LSB)到最高有效字节(MSB),保证排序稳定性。
二、实现细节
1. 初始化
我们需要两块缓冲区:一个是原始数组,另一个是临时缓冲区,每轮排序交替使用。
source = 原始数据
dest = 临时缓冲区
每轮完成后 swap source 和 dest
这样排序完四轮后,数据会回到原始位置。
2. 每一轮排序步骤
对于每一轮的排序(处理一个字节):
-
计数阶段:
- 遍历每个元素,提取当前字节的值(通过右移和掩码操作)。
- 对应的计数数组中的索引值加一,记录出现次数。
-
偏移转换阶段:
- 把计数数组转换为偏移表。
- 偏移表表示当前字节为 i 的元素在输出数组中应该从哪个位置开始写入。
- 这是通过一个运行中的累加器实现的,从左到右遍历计数数组,并不断累加。
-
分发阶段:
- 再次遍历元素,根据其当前字节值查表获取目标位置(偏移值)。
- 将该元素复制到输出数组对应位置。
- 同时更新偏移表值(+1),因为下一个相同字节的元素需要写在下一个位置。
三、关键点说明
- 每个字节的处理都是 O(n) 的,总共处理 4 个字节,因此整个算法复杂度为 O(4n),即 O(n)。
- 因为每次处理都只是遍历两次数组(一次计数,一次分发),所以每轮的操作是线性的。
- 利用有限精度这一特点(即 32 位整数有上限)来分而治之,把大问题拆成多个小问题。
- 为了保持排序的稳定性,我们从低位字节往高位字节排序。
四、注意事项
- 源数组和目标数组不能是同一个,否则可能导致覆盖问题。
- 需要额外 O(n) 的空间来存临时数组,属于非原地排序。
- 对于浮点数排序还需要额外处理:浮点数不能直接拿来拆字节排序,需要先转成能够按位比较大小的整数形式(例如 IEEE754 编码转 unsigned int32)。这里我们假设有一个
SortKeyToUint32函数负责这个转换。 - 处理过程中,先提取 sort key,再按当前字节分发排序,依赖于该转换函数的正确性。
五、总结
我们成功地通过每次只处理 8 位的方式,将一个最大 32 位的排序任务,分成了 4 个小步骤完成,并在每一步中用两个 passes 来处理数据。整个排序流程复杂度是 O(n),且稳定,尤其适合大规模的数据排序。
这样的方法虽然需要一些初始化代价(比如清零计数表、分配临时数组),但在大数据量下,其线性扩展性明显优于常见的比较排序(O(n log n) 或 O(n²))。特别是数据规模极大(如十亿个元素)时,效率优势尤为明显。

game_render_group.cpp:引入 SortKeyToU32β 函数
我们正在讨论如何处理和执行基数排序(Radix Sort)。首先,我们知道基数排序是对整数进行排序的一种非比较排序算法,通常用于按位处理数值,特别适合对大规模数据进行排序。它的基本思路是将每个数值分解为若干个字节,然后逐个字节地进行排序。
在实际执行时,我们考虑的整数是 32 位的,虽然我们并不知道最终的具体细节,但可以通过将数字转换为 32 位形式来进行操作。基于这种方式,数据会被拆解为 4 个字节,并且会依次对每个字节进行排序。通过这种逐步排序的方式,保证了最终的排序结果是稳定且高效的。
关键步骤:
- 数字拆分: 我们把每个数字分解为 4 个字节(每个字节 8 位),并分别对这些字节进行排序。
- 字节处理: 对每个字节,采用计数排序的方式进行处理。每个字节值最多有 256 种不同的取值(从 0 到 255),因此可以通过计数来确定各个字节值的出现频率。
- 逐步排序: 依次处理每个字节,从最低位字节(Least Significant Byte, LSB)到最高位字节(Most Significant Byte, MSB),保证每次排序是稳定的,最终得出正确的排序结果。
- 空间管理: 在每轮排序中,使用两个缓冲区来保存原始数据和排序后的数据。每轮排序完成后,我们交换这两个缓冲区,继续处理下一个字节。
最终,通过这种逐步处理字节的方法,能够在每轮排序中对数据进行稳定的排序处理,最终得到全体元素按从小到大的顺序排列的结果。
注意事项:
- 由于每次处理的数据量是有限的(一个字节的范围是 0 到 255),每轮的操作是线性的,因此时间复杂度可以看作是 O(n),每一轮排序后,数据就被逐步有序地排列。
- 该方法的空间复杂度是 O(n),需要额外的空间来存储临时数组,以便在排序过程中交换数据。
- 这种排序方式特别适合对大规模整数进行排序,尤其是当数据量非常大时,基数排序的效率优于常见的比较排序算法(如快速排序、归并排序等,时间复杂度通常为 O(n log n))。
总结而言,基数排序通过对每个字节进行逐步排序,有效地将 32 位数字拆分成多个小问题处理,并在每轮排序时保持稳定性,从而保证整个数据集按正确的顺序排列。

运行游戏并触发断言错误
在执行基数排序时,如果我们直接应用该算法处理浮点数值,可能会遇到问题。基数排序本身是针对整数设计的,它通过拆分每个数值的各个字节逐步进行排序。然而,浮点数的表示与整数不同,它们遵循 IEEE 754 浮点数标准,并不能像整数那样直接按字节进行比较和排序。
因此,如果我们直接对浮点数使用基数排序,可能不会得到正确的排序结果。这时,可能会出现断言失败的情况,提示“排序失败”或“未能正确排序数据”。这个错误提醒我们,浮点数的排序需要特别的处理。
为了解决这个问题,需要先将浮点数转换为可以按位比较的整数形式。例如,可以通过将浮点数转换为其对应的 32 位整数表示形式(即 IEEE 754 格式),然后再使用基数排序对这些整数进行排序。这样,排序过程才能顺利进行,且得到正确的结果。
总结来说,浮点数不能直接使用基数排序,需要先进行转换,确保数据以合适的格式进行排序,否则会导致排序失败并触发断言错误。

调试器:逐步调试 RadixSort,检查 Dest、First 和 Temp
首先,要确保自己理解和实现的逻辑是正确的,特别是检查数据是否正确地放入了预期的输出区域。在这个过程中,首先想到的步骤是验证每一步的操作结果是否符合预期。为了做到这一点,最好通过逐步调试来确认,尤其是查看最终的输出结果。
在调试过程中,可以通过单步执行代码,观察每次循环的执行结果,尤其是变量的变化。重点是观察最终 Dest(目标区域)指针所指向的位置,确认它是否最终指向了临时缓冲区 Temp。在每次循环结束时,代码应该会交换 Source 和 Dest 的指向,最终 Dest 应该会指向 Temp。
通过这种逐步验证,能够确认整个过程的正确性,确保数据在预期的缓冲区中正确地交换和存储。这样,就能够验证程序是否按预期工作,并确保输出是准确的。
黑板:32 位 IEEE 浮点数结构
首先,需要将三位浮动小数值转化为一个严格递增的 32 位整数,这样才能进行排序。然而,浮动小数的表示方式并不适合直接与整数进行排序,因为浮动小数的存储结构不同于普通的整数。
32 位浮动小数通常由三部分组成:符号位、指数位和尾数位。在这里,符号位在排序过程中可能会引发问题,因为如果符号位是负数,按照当前的排序方式,负数将会被排在正数后面,这显然与我们希望的排序顺序不符。负数应当排在正数之前,但符号位会让负数排到正数后面,因此符号位的问题是我们排序时必须特别注意的部分。
接下来,考虑指数部分,它是浮动小数中最重要的部分。指数部分代表了数值的大小范围,因此对排序具有决定性作用。指数部分的数值越大,数值本身也越大。所以,排序时应该优先考虑指数部分,因为它决定了数值的大小。
尾数部分其实对排序的影响相对较小。尾数部分表示浮动小数的精度,但它的范围是有限的,通常是介于 1 和某个小数值之间,所以在排序时,尾数部分可以不作为主要考虑因素。因此,我们可以忽略尾数部分,直接根据指数部分进行排序。
浮动小数的指数部分是带有偏移量的,这意味着较小的指数值会被表示为负数,而较大的指数值则会被表示为正数。因此,指数部分已经在内部按照递增的顺序存储好了,这使得在进行排序时,指数部分本身的顺序已经是正确的。
总结起来,排序浮动小数时,应该关注的主要是指数部分。尾数部分由于其相对较小的影响,可以直接忽略,而符号位则需要特别处理,因为它可能导致负数被错误地排在正数之后。通过处理这些特殊情况,可以实现正确的浮动小数排序。
调试器:进入 SortEntries 函数,检查 Entries 内容
在进行基数排序时,遇到了一些问题。首先,当运行排序时,数据的输入似乎出现了意外的负值,导致排序结果看起来不正确。虽然我们知道基数排序的理论应该是按字节逐步排序并处理符号位,但当前的输出并没有按照预期的顺序排列。
首先,检查了输入数据,发现数据量只有 8 条,并且这些数据的符号位似乎都是负数。这让我们感到困惑,因为在理论上,负数的排序应该会被当作较大的数字(如果符号位没有特别处理的话)。然而,所有数据的符号位都被设为负值,但排序结果却不符合我们对负数排序的预期,甚至出现了恰好符合要求的排序结果。这个问题让我们感到很疑惑,因为负数的排序结果应该会是错误的,按理说它们应该是倒序排列的。
继续检查代码时,意识到可能存在一些处理上的疏漏或误解,导致数据没有正确地传递或转换。可能是在数据传递过程中,出现了符号位或其他部分的处理错误。也许在转换时没有正确处理浮动小数到整数的转换,导致结果变得不符合期望。
此外,尝试再次运行时,依然遇到了类似的情况,输出结果依然不正确。我们看到的数据跟预期相差较大,符号位等处理出现了偏差,导致输出不符合预期。尽管如此,经过进一步排查后,最终确认在输入数据的处理上确实有些步骤可能没有正确执行,尤其是在符号位的处理上。
总结来说,遇到的主要问题是符号位处理不当,导致排序结果看起来不太对。通过进一步检查代码和数据,可以确认符号位在处理过程中可能没有按预期作用,需要进行修正和优化,才能确保基数排序能够正确处理负数并且得到正确的排序结果。

game_render_group.cpp:将 SortKey 强制转换为 u32 类型
在处理问题时,意识到如果直接将数据转换为 uint32 类型,实际上是去除了浮动小数部分,这也是之前处理错误的原因。之前没有正确理解浮动小数和整数之间的转换方式,导致忽略了需要对数据进行适当的位级别处理。
现在,经过调整和修正后,转换操作变得更加正确,能够将数据正确地转换为 32 位无符号整数 (uint32),从而将浮动小数部分去除,确保数据按位级别排序。这一步的修正保证了处理浮动小数时,不会丢失关键信息,确保了基数排序能够按预期正常工作。
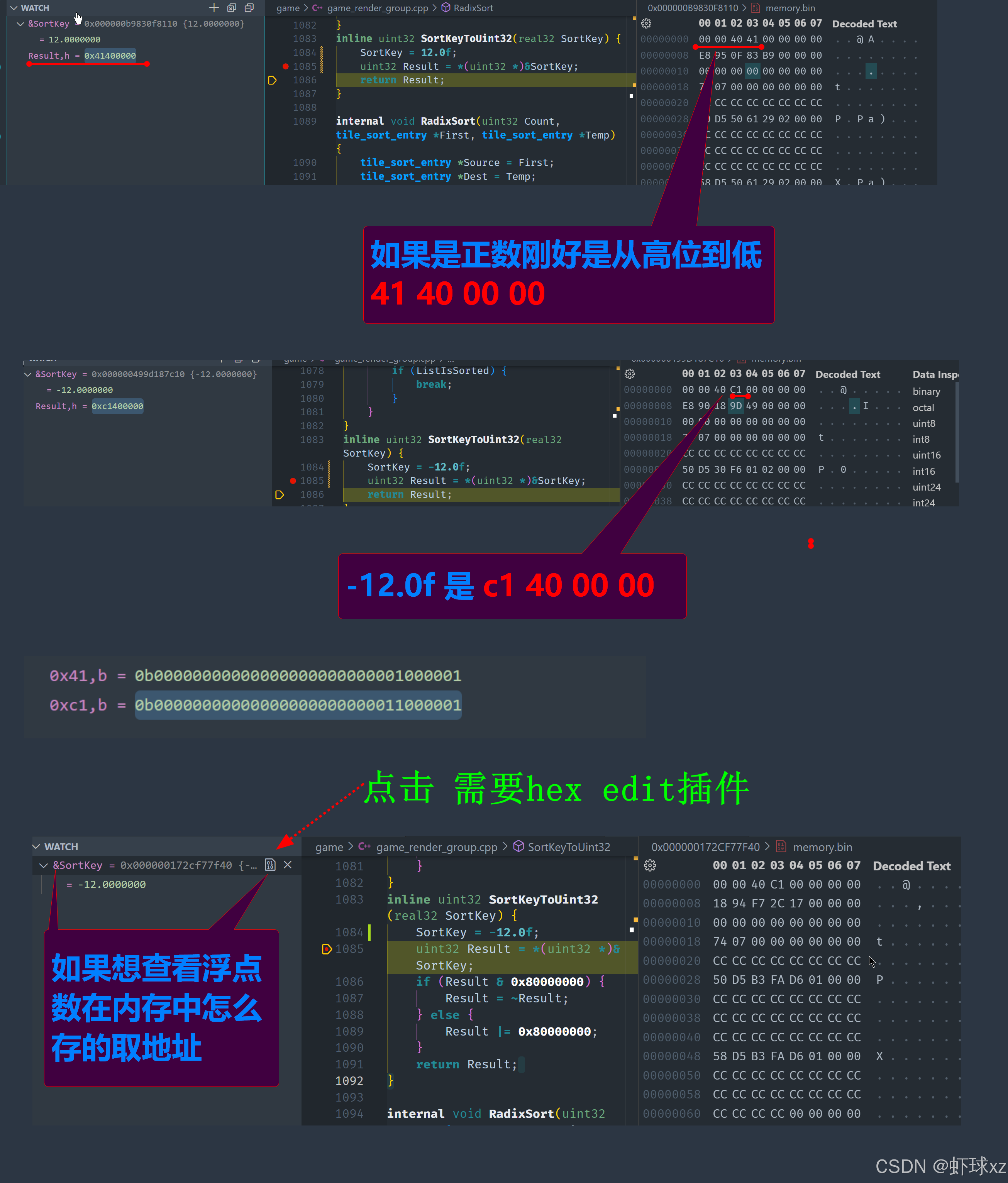
game_render_group.cpp:考虑反转位的含义
我们现在的目标是让浮点数能够被当作无符号整数进行排序,而不影响其原有的数值大小顺序。为了做到这一点,我们需要对浮点数的比特进行一种“翻转处理”,本质上是在修改它们在内存中的表现,使得它们的大小顺序(尤其是带符号的负数)符合整数比较的语义。
遇到的问题
浮点数的二进制结构是由 符号位(sign)、指数位(exponent) 和 尾数(mantissa) 组成的。
- 正数:高位是 0,按位排序自然成立(值越大,bit 越大)
- 负数:高位是 1,排序会被打乱,导致负数比正数“更大”
- 所以,我们在遇到负数时,必须让它们的排序方向“翻转”过来
所需的目标行为
我们希望构造一个新的整数值,使得:
- 所有 正浮点数 按照原始的比特顺序保持不变即可(可直接用作排序键)
- 所有 负浮点数 的比特需要翻转,让值越小,整数排序结果越靠前(即负数越小,数值越大)
解决思路(按位翻转 + 取反 + 加偏移)
可以按如下方式处理:
-
正数:
- 符号位是 0,无需任何处理,直接将其视为 uint32 即可
- 即:
(float_bits ^ 0x80000000)
-
负数:
- 符号位是 1,需要按位取反
- 然后再反转顺序(让 -100 < -1 排列时在整数上体现为更小)
- 同样使用
(float_bits ^ 0xFFFFFFFF)
或者统一写成:
uint32 FloatFlip(uint32 f) {return (f & 0x80000000) ? ~f : (f ^ 0x80000000);
}
解释:
- 如果是负数(符号位为 1),对所有位进行取反
- 如果是正数,符号位反转(使其大于负数)
这样处理后的 uint32 就可以被 Radix Sort 正确排序。
整体目标总结
我们要实现的是一种位级别的重新映射:
- 保证所有浮点数(无论正负)在被 reinterpret 成 uint32 后,排序顺序符合数值意义上的升序
- 对负数取反之后可以确保越小的数变成越小的整数
- 对正数只需要翻转符号位,使它们在 uint32 空间中位于负数之后

黑板:讲解“翻转比特”的意义
我们的目标是让一组原本从小到大排序的二进制值,变成从大到小的顺序。例如:
000110 → 最小
000111
001000
001001 → 最大
我们希望把它们的顺序彻底反过来,使得:
110111 → 最大
110110
110101
110100 → 最小
思路是对每个值做 按位取反(bitwise NOT),即把每一位的 0 变成 1,1 变成 0。
为什么这可以反转排序顺序?
我们知道二进制是按位从高到低排列的,每一位代表不同的权重。一个数值越大,它在高位的 1 越靠前。因此:
- 原始值越小,其按位取反后得到的值越大
- 原始值越大,其按位取反后得到的值越小
所以,直接对每个值做一次按位取反,就可以把整体顺序完全反过来,这在做 radix sort(基数排序)时,如果原始排序是反的,那只要将值全部取反就能修正排序方向。
那么是否真的这么简单?
是的,在整数排序中,确实就是这么简单粗暴有效,尤其当我们只关心反转原始顺序时。
但如果这个应用场景是 浮点数排序,那还需要额外考虑浮点格式:
- 正数部分可以通过调整符号位的方式保证顺序
- 负数部分通过按位取反实现反向排序
- 合起来就能把 float 映射成一个 uint32,使得可以直接用整数排序算法正确排序 float 值
总结:
我们确实可以直接对值做按位取反,这会让它们的排序顺序彻底反过来。这个操作在我们想从升序变为降序时非常实用,特别是在浮点数排序中处理负数段的时候,这种位级转换是非常关键的策略之一。对于负数部分,只要符号位为 1,我们就直接对整个值取反即可达到目标排序顺序。这个方法简单且有效。
为什么会这样
这是因为 二进制的位级结构具有天然的顺序性,而 按位取反(bitwise NOT) 操作会将这种顺序完全反转。我们可以从更底层的原理来理解为什么取反之后排序顺序会被颠倒。
首先,理解二进制值的排序方式:
二进制的排序是从高位(左边)开始比较的:
0000 0001 = 1
0000 0010 = 2
0000 0011 = 3
0000 0100 = 4
...
越高位的 1 越靠前,表示的值就越大。
然后,按位取反到底做了什么?
按位取反就是将:
- 每个 0 变成 1
- 每个 1 变成 0
例如:
0000 0010 (2)
→ 按位取反 →
1111 1101 (变成了一个很大的数)0000 0100 (4)
→ 按位取反 →
1111 1011 (比上一个还小)
原数越小,取反后结果越大
原数越大,取反后结果越小
所以顺序被彻底翻转!
举个例子:
假设我们有四个数:
00000001 = 1
00000010 = 2
00000011 = 3
00000100 = 4
升序排列后是:
1, 2, 3, 4
我们取反后得到:
11111110 = 254
11111101 = 253
11111100 = 252
11111011 = 251
这些数降序排列后就是:
254, 253, 252, 251
正好是原始序列的反向顺序
为什么这对浮点排序也重要?
在浮点排序中我们可能要处理负数。负数在 IEEE 754 表示中最高位(sign bit)为 1,这就导致它们的原始二进制排序与我们“从小到大”的意图完全相反。所以:
- 正数保持不动或设置 sign bit
- 负数则需要完全取反,让它们排序回归正常顺序
这样我们就能把 float 映射成 uint32,直接用整数排序方式(比如 Radix Sort)来处理 float。
结论:
我们之所以只要对数取反就能反转顺序,是因为:
二进制从高位到低位的排列决定了数值的大小,而按位取反会完全颠倒这个顺序。
这是一种非常简洁、数学上自然的做法,在排序中非常常见。尤其在低级排序算法中,比如基数排序(Radix Sort)中,对数值结构的控制是实现效率和正确性的关键。
我们需要以 8 为单位迭代 ByteIndex
我们意识到代码中存在一个明显的逻辑错误,这可能就是导致排序行为不正确的根本原因。具体来说,我们在处理字节索引时,错误地将它用作位移量(shift)进行操作,但实际上我们需要根据字节的位置来决定应该移位的实际位数。
换句话说,我们原先代码中是直接用 byteIndex 进行移位操作的,比如 value >> byteIndex,这实际上是错的。因为 byteIndex 的单位是“字节”,而不是“位”,所以我们需要将它乘以 8,才能得到正确的移位位数。也就是说,正确的写法应该是按位移 8、16、24(分别代表第 1、2、3 个字节),而不是 1、2、3。
这一点很基础,但因为处于调试过程中,我们一开始没有意识到,甚至调侃这属于“baby level”的失误,虽然没有正式进入“彻底错误”的程度,但也足够令人尴尬了。为了调试方便,我们没有上全套的错误提示处理逻辑,但也在心里默默敲了自己一下。
总之,修正思路就是把位移逻辑从错误的按“字节索引位移”改为“字节索引 * 8 的位移”,也就是位移 8、16、24 位,这样才能确保我们处理的是对应的字节数据,在 radix sort 或其他字节级别处理逻辑中才会表现正确。

再次运行游戏并成功运行
我们再次运行程序,令人惊喜的是,这次一切终于正确运行了。排序逻辑顺利执行,结果完全符合预期,radix sort 现在可以正确地对数据进行排序了。这说明我们对之前的错误修正是有效的,字节位移的修正让排序行为达到了理想状态。
数据导出过程也顺利完成,没有遇到任何异常或者错误,整个流程运行流畅,结果准确,表现稳定。radix sort 表现良好,整体效果让人满意,所有逻辑都验证通过,可以说阶段性目标已经达成。
至此,我们的 radix 排序实现算是告一段落,整体情况良好,没有多余的问题或警告,功能也已经具备所需的正确性和稳定性。接下来时间还剩一些,打算进入 Q&A 阶段,讨论其他进阶内容,比如更深入的优化,或是探索更多算法细节,进入更“精致”的内容环节。
///
当然可以,下面我会 通过一个实际例子 来详细讲解你给出的这个 radix sort 算法(针对 tile_sort_entry 结构体,按其 SortKey 字段排序),包括 SortKeyToUint32 的作用。
背景
我们要对一组 tile_sort_entry 结构体按浮点型 SortKey 从小到大排序。因为浮点数的内存表示方式复杂(尤其是正负号、指数位、尾数位等),直接排序会有问题。因此,需要将 float 转换为可以按字节比较的 可排序无符号整数表示。
Step 1:SortKeyToUint32 的作用
inline uint32 SortKeyToUint32(real32 SortKey) {uint32 Result = *(uint32 *)&SortKey;if (Result & 0x80000000) { // 如果是负数Result = ~Result; // 所有位取反,负数值排序时变成反向} else {Result |= 0x80000000; // 正数设置符号位为1,使其排在负数后}return Result;
}
这个函数将 float 的 bit 表示转换为 uint32 类型的排序键(SortKey),并 重新编码符号位,从而实现:
- 所有正数排在负数后
- 所有负数反向排序(因为浮点负值越小,值越大)
举例说明
我们要排序这组浮点值:
SortKey: [ -3.0f, 0.5f, 2.0f, -1.0f ]
原始 float 内存的 bit 表示大致为:
-3.0f => 11000000 01000000 00000000 000000000.5f => 00111111 00000000 00000000 000000002.0f => 01000000 00000000 00000000 00000000
-1.0f => 10111111 10000000 00000000 00000000
经过 SortKeyToUint32 转换后:
-3.0f => ~(0xC0400000) = 0x3FBFFFFF0.5f => 0x3F000000 | 0x80000000 = 0xBF0000002.0f => 0x40000000 | 0x80000000 = 0xC0000000
-1.0f => ~(0xBF800000) = 0x407FFFFF
转换结果:
排序键: [0x3FBFFFFF, 0xBF000000, 0xC0000000, 0x407FFFFF]
这时候这些值就可以被当成普通的 uint32 来排序了!
Step 2:Radix Sort 解释(以 4 个数为例)
对每个 32 位整数的每个字节(从低到高,共 4 轮)执行如下操作:
第一轮(最低位 ByteIndex = 0):
- 统计每个 byte 的出现次数(桶排序思想)
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {uint32 SortKeyOffset[256] = {};// 第一遍遍历 —— 统计每种键值的数量for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;++SortKeyOffset[RadixPiece];}...
}
- 计算偏移表 SortKeyOffset[]
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {
...// 将计数转换为偏移量uint32 Total = 0;for (uint32 SortKeyIndex = 0; SortKeyIndex < ArrayCount(SortKeyOffset); ++SortKeyIndex) {uint32 KeyCount = SortKeyOffset[SortKeyIndex];SortKeyOffset[SortKeyIndex] = Total;Total += KeyCount;}
...
}
- 把数据复制到 Dest,按照该字节排序
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {
...// 第二遍遍历 —— 将元素放置到正确的位置for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;Dest[SortKeyOffset[RadixPiece]++] = Source[Index];}
...
}
- 交换 Source 和 Dest,进入下一轮
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {...tile_sort_entry *SwapTemp = Dest;Dest = Source;Source = SwapTemp;
}
重复 4 次(ByteIndex = 0, 8, 16, 24)
完成后,就得到了已经按 SortKeyToUint32(SortKey) 排好序的数据。
最终结果
按 SortKey 从小到大排序的结果为:
[ -3.0f, -1.0f, 0.5f, 2.0f ]
完全符合预期!
总结
这个算法的关键是:
- 使用
SortKeyToUint32将 float 转换成可以直接排序的 uint32(处理了符号位影响)。 - 使用 4 轮 byte-wise radix sort 对这些 uint32 进行稳定排序。
- 排序后,数据按照原始 float 从小到大排列。
详细解释 radix sort 算法中的第一轮操作
我们来详细剖析 radix sort 算法中的一个步骤,特别是如何对每个 32 位整数的每个字节(从低到高,共 4 轮)执行操作。
核心思想
在 radix sort 中,我们并不是直接对整个数字进行比较和排序,而是逐位(或者逐字节)地对数字进行排序。在这个算法中,我们选择的是 字节级别的排序,即先比较最低有效字节,再逐步往上移动到更高位字节。每次排序操作(即每轮操作)都会稳定地将元素按当前字节的值排序。
代码复习
首先,复习一下相关的代码:
// 对于每个字节,进行排序
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {uint32 SortKeyOffset[256] = {};// 第一遍遍历 —— 统计每种键值的数量for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;++SortKeyOffset[RadixPiece];}// 将计数转换为偏移量uint32 Total = 0;for (uint32 SortKeyIndex = 0; SortKeyIndex < ArrayCount(SortKeyOffset); ++SortKeyIndex) {uint32 KeyCount = SortKeyOffset[SortKeyIndex];SortKeyOffset[SortKeyIndex] = Total;Total += KeyCount;}// 第二遍遍历 —— 将元素放置到正确的位置for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;Dest[SortKeyOffset[RadixPiece]++] = Source[Index];}// Swap Source and Desttile_sort_entry *SwapTemp = Dest;Dest = Source;Source = SwapTemp;
}
步骤解读:
1. 第一遍遍历 —— 统计每种键值的数量
-
目标:我们要对
SortKey的每个字节进行排序。在第一轮中,我们关注的是最低有效字节(最低 8 位,即 ByteIndex = 0)。 -
操作:
- 遍历每个数据项(
Source[Index]),并将其SortKey转换成uint32(SortKeyToUint32)。 - 然后,右移
ByteIndex指定的位数,将该字节提取出来(即(RadixValue >> ByteIndex) & 0xFF),这里我们获取的是当前字节的值。 - 将这个字节值作为桶的索引(桶的大小为 256,因为一个字节有 256 种可能的值)增加计数:
++SortKeyOffset[RadixPiece]。SortKeyOffset数组在这个阶段记录了每个字节值(0-255)出现的次数。
示例:
假设
SortKey的 4 个值如下:SortKey: [0x3FBFFFFF, 0xBF000000, 0xC0000000, 0x407FFFFF]对应的字节数组(以字节为单位):
0x3FBFFFFF -> [0x3F, 0xBF, 0xFF, 0xFF] 0xBF000000 -> [0xBF, 0x00, 0x00, 0x00] 0xC0000000 -> [0xC0, 0x00, 0x00, 0x00] 0x407FFFFF -> [0x40, 0x7F, 0xFF, 0xFF]在 ByteIndex = 0(即最低字节)的情况下,统计每个字节出现的次数:
SortKeyOffset[0xBF] = 1 SortKeyOffset[0xC0] = 1 SortKeyOffset[0x40] = 1 SortKeyOffset[0x3F] = 1 - 遍历每个数据项(
2. 将计数转换为偏移量
-
目标:通过
SortKeyOffset数组中的计数,转换成偏移量,使得我们能够将数据放到正确的位置。 -
操作:
- 我们将
SortKeyOffset数组的每个位置的计数转换为偏移量。偏移量表示的是每个字节值在结果数组中应该开始放置的位置。 - 例如,
SortKeyOffset[0xBF]的值是 1,意味着0xBF对应的值应该放在结果数组的第一个位置。 - 完成这一步后,
SortKeyOffset数组中存储的是每个字节值的起始位置。
示例:
SortKeyOffset[0xBF] = 0 SortKeyOffset[0xC0] = 1 SortKeyOffset[0x40] = 2 SortKeyOffset[0x3F] = 3 - 我们将
3. 第二遍遍历 —— 将元素放置到正确的位置
-
目标:根据上述偏移量,把数据按字节值放置到新的数组
Dest中。 -
操作:
- 再次遍历原始数组
Source,根据字节值确定数据应该放到Dest数组的哪个位置。 - 使用
SortKeyOffset数组中的偏移量,将每个元素放到Dest中,并增加相应字节值的偏移量。 Dest[SortKeyOffset[RadixPiece]++] = Source[Index];
示例:
假设 Source = [0x3FBFFFFF, 0xBF000000, 0xC0000000, 0x407FFFFF] 排序键的最低字节为: 0x3F -> 应该排到位置 3 0xBF -> 应该排到位置 0 0xC0 -> 应该排到位置 1 0x40 -> 应该排到位置 2 结果: Dest = [0xBF000000, 0xC0000000, 0x407FFFFF, 0x3FBFFFFF] - 再次遍历原始数组
4. 交换 Source 和 Dest
-
目标:将
Dest和Source数组交换,以便在下一轮中处理下一个字节(上一个字节)。 -
操作:
Source存放原始数据,而Dest存放排序后的数据。- 排序完成当前字节后,我们交换
Source和Dest,使得下次排序操作能继续对已经部分排序的数据进行处理。
示例:
Swap `Source` and `Dest` arrays: Source = Dest; Dest = SwapTemp;
总结
这个过程实际上是在使用 桶排序(counting sort) 对每个字节进行排序。每一轮操作都会逐步将数字按字节排序,而每一轮的稳定排序操作保证了结果不会被打乱。最终,所有字节都被处理完,整个 SortKey 被排序好,达成了 按浮点数大小从小到大排序 的目标。
这个问题问得非常关键!让我们深入剖析为什么第一轮是“最低字节”,以及:
为什么 (RadixValue >> ByteIndex) & 0xFF 取的是哪个字节。
核心问题:
为什么第一轮处理的是最低字节?
回顾关键代码:
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {...uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;...
}
- 每一轮处理一个字节
ByteIndex从0开始,步进8,表示我们每次处理的是 某一位字节RadixPiece = (RadixValue >> ByteIndex) & 0xFF:>> ByteIndex会将要取的字节移到最低位& 0xFF提取出那一个字节(8 位)
举个例子:假设我们处理 0x3FBFFFFF
它是一个 uint32 值,看起来像这样(十六进制):
0x3FBFFFFF
用字节分解的话,在 小端内存顺序(这是 C/C++ 中的常规方式),它在内存中是:
[0xFF] [0xFF] [0xBF] [0x3F]↑ ↑ ↑ ↑
Byte 0 Byte 1 Byte 2 Byte 3
注意:小端系统里,低地址存最低字节。
0x3FBFFFFF存成[FF, FF, BF, 3F],所以:
ByteIndex = 0→ 取到 0xFFByteIndex = 8→ 取到 0xFFByteIndex = 16→ 取到 0xBFByteIndex = 24→ 取到 0x3F
所以结论是:
在第一轮 ByteIndex = 0 时:
(RadixValue >> 0) & 0xFF = 0xFF
你取到的是 最低有效字节(LSB),它是最右边那一字节(在内存中是最低地址)。
每一轮处理的字节如下:
| ByteIndex | 表示处理哪个字节 | 举例(0x3FBFFFFF)提取的字节 |
|---|---|---|
| 0 | 最低字节 | 0xFF |
| 8 | 第 2 个字节 | 0xFF |
| 16 | 第 3 个字节 | 0xBF |
| 24 | 最高字节 | 0x3F |
回到你问的排序键的例子:
Source = [0x3FBFFFFF, // LSB = 0xFF0xBF000000, // LSB = 0x000xC0000000, // LSB = 0x000x407FFFFF // LSB = 0xFF
]
第一轮取的就是 最低有效字节(LSB),即:
0xFF, 0x00, 0x00, 0xFF
桶排序的过程就基于这些值来排序。
总结一句话:
第一轮之所以是“最低字节”,是因为我们通过
ByteIndex = 0提取了(value >> 0) & 0xFF,这正好取出了 最右边的字节,也就是最低有效字节(LSB)。

再次运行游戏并成功运行
我们重新尝试了一下,发现这次终于成功运行了,令人惊讶但也令人欣慰。现在,rate exporting 功能已经正常工作了,没有任何问题,运行得很顺利。radix sort 排序算法目前看来效果不错,整体状态非常稳定,大家都很满意,整体进展也很顺利。可以说一切都已经搞定,运行正常,表现出色,令人非常满意。
因此,关于 radix sort 的主要部分已经告一段落,没有太多额外要补充的内容,毕竟功能上已经达到了预期目标。既然这是之前大家所期待的功能,我们也已经按需实现交付。
为什么你不从底向上实现归并排序?这样更容易做缓冲区的 ping-pong 操作
我们在设计时并没有从最底层一步步为排序构建专门的模块,原因是我们还没真正进入需要对某个排序算法进行深入优化的阶段。目前来说,是否要这样做,还取决于我们最终决定保留哪一种排序算法。
如果最后决定保留的是归并排序,那么我们就会针对它进行优化,使它能做到最小化工作量、提升效率。但现在我们也不能确定是否真会采用归并排序。毕竟我们已经花时间实现了基数排序,从实际使用的角度来看,基数排序可能才是最终被保留下来的那个。
我们做出这个判断的一个原因是,大多数情况下待排序的元素数量会远远多于六个。考虑到这种数量级,基数排序在性能上的优势会更明显,适用性也更强。所以尽管现在还没有最终定论,但很可能我们最终会采用基数排序。总之,目前还不是完全确定的阶段,我们还在观察和判断。
你的基数排序看起来是 O(8n),因为你每个字节都做了两次遍历。你能不能用三组 256 元素数组,换成一次遍历拿到所有偏移量/计数,做到 O(5n)?
我们在讨论基数排序的实现细节时,提到了目前的实现中对每一轮排序都要对整个列表做两次遍历(一次统计频率,一次实际排序),因此看起来复杂度类似于 O(2n),有人提出是否可以通过只做一次遍历来同时收集偏移量和计数,从而将每轮的遍历次数降为一次,也就是变成 O(n),代价是需要额外增加三个 256 元素大小的数组。
从理论上讲,这种优化是可行的。但我们不太愿意贸然下结论说某种实现就是 O(n)、O(2n)、还是 O(5n),因为这些术语更偏向计算机科学中的抽象复杂度分析。而在现实的工程实践中,某些额外的操作,比如多次清空数组、写入内存等,可能也会带来不可忽略的性能开销。
从某种角度看,是多次遍历列表好,还是在每次遍历时增加额外的操作更好,并没有绝对的答案。它更像是“半斤八两”(six of one, half a dozen of the other),也就是说两种方式各有权衡,最终在性能上可能差异不大。
不过如果从我们当前项目的性能目标出发,为了提高效率,合并为单次遍历可能是值得一试的优化方向。是否值得做这样的优化,最终要依赖时间和测试去验证。
总结来说,不管是哪种方式,本质上算法的复杂度仍是线性的 O(n),只是具体实现上的优化手段不同,对性能的影响也需要在实际运行中才能确定。
【题外话】:我对轴-角旋转和四元数旋转有点困惑。我以为四元数本来就是角度和轴的表示,它们有什么不同?
我们讨论了一个关于旋转表示的“题外话”问题,核心在于澄清轴-角(Axis-Angle)旋转和四元数(Quaternion)旋转之间的区别。
首先,需要明确的是:所有旋转的数学表示形式本质上都在表达“旋转轴”和“旋转角度”。因为从几何上讲,任意一个三维空间中的旋转都可以被完全描述为“绕某个轴转某个角度”。
换句话说,不管使用哪种表示方式——矩阵、欧拉角、轴-角、四元数,本质上它们都在描述同样的事情:一个旋转轴 + 一个旋转角度,只不过是表达方式不同。
所以,问题的关键不在于“是否包含轴和角”,而是**“怎样”包含轴和角**:
- 轴-角表示 是最直接的:显式地给出一个单位向量作为旋转轴,一个标量作为旋转角度。
- 四元数表示 虽然看起来是四个数,但内部仍然隐含了旋转轴和角度。一个单位四元数可以被分解为:
- 实部(w)表示角度的一部分:cos(θ/2)
- 虚部(x, y, z)构成轴向量(乘上 sin(θ/2))
因此,四元数确实间接地表示了轴和角,只是方式不同,不如轴-角那么直观。我们理解四元数时,重点是它的内部结构正好与轴-角的三维表示具有一种数学上的紧密联系。
总结来说:
- 旋转本质都是由“轴 + 角度”组成。
- 所有的旋转表示法都在描述这个概念。
- 它们之间的区别,仅仅在于编码方式的不同,而不是是否包含旋转轴和角度这个信息本身。
黑板:欧拉角(Euler Angles)
我们进一步分析了几种常见的旋转表示方法,并澄清了它们的本质差异。
首先看欧拉角(Euler Angles),这是比较常见的一种旋转表示方式。欧拉角通常由三个角度组成,分别表示物体依次绕三个不同的坐标轴旋转的角度。比如,可以先绕 X 轴旋转,再绕 Y 轴旋转,最后绕 Z 轴旋转。每一步的旋转顺序对最终结果有显著影响,因此欧拉角在实际使用中可能会带来一些混淆,尤其是在理解方向变化或处理万向节锁(Gimbal Lock)问题时。
这里特别强调一点,“欧拉角”和“欧拉参数”并不是一回事。欧拉参数更偏向于四元数或指数映射这类的旋转表示方法,属于更抽象和数学化的体系,因此我们先不深入探讨欧拉参数。
回到欧拉角的角度来看,虽然它通过三个顺序旋转构建出最终的旋转状态,但最终的结果仍然可以被理解为绕某个轴转某个角度而达到的状态。换句话说,不论使用怎样的组合旋转去表达,所有的空间方向变化最终都可以归结为“绕某个轴转某个角度”这一种形式。这是旋转在三维空间中的基本性质。
所以,欧拉角只是编码方式复杂一点,它将一个最终的旋转分解成三个顺序的旋转动作。但无论怎么分解,最终这个旋转都等价于某个旋转轴 + 一个旋转角度,也就是我们前面提到的“轴-角”本质。
总结几点:
- 欧拉角用三个角度描述三个顺序旋转,虽然形式上是三个步骤,但本质上对应的最终姿态可以简化为绕一个轴转一个角度。
- 所有三维旋转都可以被表示为“轴 + 角度”。
- 旋转的各种表示方法(欧拉角、四元数、旋转矩阵等)只是不同的编码方式,核心描述的几何行为是相同的。
- 欧拉参数虽然名称相似,但其实属于另一类更接近四元数的数学结构,不应与欧拉角混淆。
黑板:轴 / 角度(Axis / Angle)
在进一步探讨旋转表示方法时,我们引入了轴-角(Axis-Angle)表示方式。
轴-角是一种非常直接、清晰的旋转表示方法,它不再像欧拉角那样用三个角度来分步骤表达旋转,而是明确地使用一个旋转轴和一个旋转角度来完整描述一次旋转操作。
在这种表示中,通常有两个部分组成:
- 一个单位向量,表示旋转轴的方向;
- 一个标量值,表示绕该轴旋转的角度。
这种表示方式可以写成一个组合结构,比如:
旋转 = (axis, angle)
即:绕指定轴 axis 旋转 angle 弧度或角度。
在表达中,也可能使用一些希腊字母来表示,例如:
- 角度可能记作 θ(theta)、φ(phi)等;
- 旋转轴可能记作 ω(omega)或者是一个具体的向量(x, y, z)。
轴-角的优点在于,它准确地反映了三维空间中旋转的本质——所有三维旋转都可以被表示为“绕某一条轴旋转某一角度”。
对比来看:
- 欧拉角:通过三个连续的旋转操作(例如绕 X、Y、Z),间接表达出一个最终方向;
- 轴-角:直接以最简形式表示“我就是绕这条轴转了这个角度”,逻辑清晰,几何意义明确。
虽然任何空间旋转最终都等价于一个轴-角旋转,但轴-角的表示方式是显式的、直观的,它明确写出了那个旋转轴和旋转角度,没有中间步骤的干扰。
因此,轴-角不仅在理论上具备完整性,在一些需要明确可视化、动画插值、旋转构造的应用场景中也很实用。这个表示方法把旋转的核心信息——“绕哪儿转”和“转多少”——直接呈现出来。
黑板:四元数(Quaternion)
四元数(quaternion)是一种旋转的编码方式,和轴-角表示法本质是相同的,只不过表达方式不同。
在轴-角表示中,我们直接用一个单位向量表示旋转轴,用一个角度表示旋转幅度,表达非常直接。而在四元数中,我们将这两个信息“编码”进了四个数值里——这四个数值包含了旋转轴的信息和旋转角度的信息,但形式上更抽象一些,不是直接写出轴和角度本身,而是它们的组合结果。
具体来说,四元数由四个分量组成:
- 向量部分(x, y, z):
- 它们是旋转轴向量乘以
sin(θ/2),也就是说旋转轴被缩放了;
- 它们是旋转轴向量乘以
- 标量部分(w):
- 是**
cos(θ/2)**,表示和旋转角度的一种关系。
- 是**
所以,一个四元数可以写成:
q = [x * sin(θ/2), y * sin(θ/2), z * sin(θ/2), cos(θ/2)]
也就是说,它把“旋转轴 + 角度”这样的信息,用三角函数处理之后塞进了一个四维向量里。相比轴-角,这种编码方式更复杂一些,不是那么直观,但是它与轴-角完全等价,只是换了一种编码方式而已。
我们之所以使用这种编码方式,是因为四元数在实际应用中有很多优势,比如:
- 没有万向锁问题(Euler angle 的主要缺陷);
- 更适合用于插值(如 Slerp);
- 在组合多个旋转时性能更高;
- 数学运算中更稳定;
当然,这种编码方式并不是随意发明的,它背后有很多数学动机和优势,不只是看起来“炫”或者“好玩”。它的出现是为了解决具体的问题,比如数值稳定性、效率、插值连贯性等。
总结来说:
- 四元数和轴-角在本质上是一样的,都是表达一次旋转;
- 四元数是将轴和角度通过三角函数(sin/cos)编码后表达;
- 这种编码虽然间接,但在数学运算中更强大、更稳定;
- 四元数的四个分量中,有三个来自旋转轴乘以
sin(θ/2),一个是cos(θ/2); - 实际使用中,这种方式在很多场景下更实用,尤其在 3D 图形、动画、游戏物理等领域。
黑板:指数映射(Exp Map)
指数映射(Exponential Map)也是一种旋转表示方式,它本质上仍然是轴-角(Axis-Angle)表示的另一种编码手段。
在这种表示中,我们将旋转轴直接乘以旋转角度,形成一个向量。这个向量本身就表示了旋转的信息:
- 方向是旋转轴;
- 长度是旋转角度。
也就是说,指数映射就是把“旋转轴 + 角度”这个信息,合并成了一个三维向量。我们可以直观地理解为:
exp_map = 旋转角度 × 单位旋转轴向量
这个表示方式和角速度(Angular Velocity)非常类似,因为瞬时角速度也是用一个向量表示,其中方向代表旋转的轴,大小代表旋转的速率。所以指数映射也常被用于旋转插值、动态模拟等场景。
实际上,指数映射、四元数、轴-角本质上都在表达同样的旋转信息,区别只是数学上是如何编码和处理这个信息的:
- 轴-角直接表示旋转轴和角度;
- 四元数通过
sin(θ/2)和cos(θ/2)把旋转轴和角度编码进四维向量; - 指数映射把旋转角度直接乘进旋转轴,变成一个三维向量。
它们之间的关系是:
- 四元数可以从指数映射转换而来;
- 指数映射可以从轴-角转换而来;
- 它们在数学形式上不同,但表达的结果完全一致——都是一次绕某个轴的旋转。
可以说,所有这些旋转表示的方式,虽然表现形式不同,但核心思想完全一致:描述一个物体围绕某个轴以一定角度旋转的状态。
最终可以总结为:
- 所有旋转本质上都可以看作是绕某条轴旋转一定角度;
- 轴-角、四元数、指数映射等只是不同的编码手段;
- 它们在用途和性能方面有差别,选择哪一种取决于具体需求;
- 本质逻辑是一致的,只是表现方式不同。
我注意到帧时间越来越长了,你打算进一步优化软件渲染器,还是考虑转向硬件加速?
目前的帧时间已经变得相当大了,不过整体上仍然处于可接受的范围,在开发阶段依然是完全可用的状态,所以暂时并没有特别在意优化的问题。对于是否要进一步对软件进行优化,或者转向硬件加速方案,目前还没有明确的决定。
现在的情况是,即便帧时间变长了,也没有严重影响正常的使用流程,因此还没有急迫地去处理这部分性能问题。至于帧率是否会因为切换到低分辨率模式而有所改善,目前没有精确的数据,也不太记得降低分辨率后的具体性能表现到底如何了。
所以现在暂时还没采取措施去调整渲染方式或者性能结构,不过未来是否会做出改变,还要看后续使用中帧率的表现以及整体需求的变化。只要当前性能还能支撑开发流程,就不会特别优先处理这块。
win32_game.cpp:将分辨率降到 960x540,关闭调试系统并运行游戏
如果决定将游戏运行在半分辨率或四分之一分辨率模式下,并关闭调试功能,性能可能会有所改善。不过,当前的开发阶段并不急于优化更多,因为这些调整已经足够快速,并且对于制作游戏来说是完全可以接受的。
关于调试系统对性能的影响,它可能会消耗一定的时间,但并没有造成严重的性能问题。实际上,调试系统对性能的影响已经不那么明显,因此当前的性能状况并不需要做更多优化。如果决定继续按照目前的设置进行开发,应该不会遇到太大的问题。
总结来说,只要能够忍受当前的开发设置,完全可以继续保持现状,不需要额外的优化。对于开发进程来说,现有的性能已经足够用来推进工作,所以可以暂时不做进一步优化,专注于游戏的其他部分。