论文速报《CAL: 激光雷达中的零样本对象形状补全》
论文链接:https://arxiv.org/abs/2504.12264
代码链接:https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
0. 简介
在自动驾驶和机器人视觉领域,激光雷达是获取环境3D信息的重要传感器。然而,激光雷达数据通常存在稀疏性和不完整性问题,尤其是对于远距离或被遮挡的物体。现有的激光雷达场景补全方法大多依赖于预定义的类别标签和大量标注数据,难以应对开放世界中的未知物体。
近日,NVIDIA、ETH Zurich和Carnegie Mellon University的研究团队提出了一种名为CAL (Complete Anything in Lidar) 的创新方法,旨在实现激光雷达数据中的零样本对象形状补全。该方法不依赖于固定的类别词汇表,而是利用多模态传感器序列的时间上下文来挖掘对象形状和语义特征,从而在单帧激光雷达扫描的基础上完成对象形状、进行本地化并识别任意类别的物体。
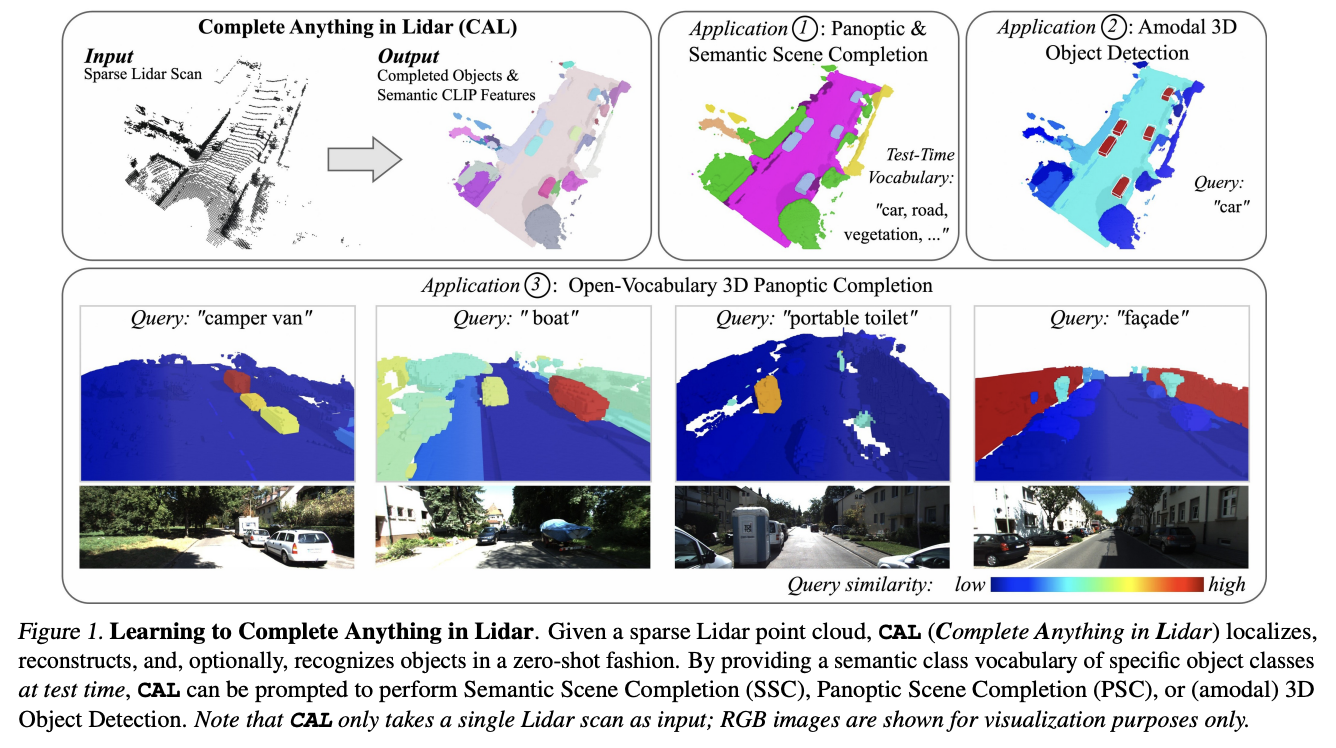
图1. 在激光雷达中学习完成任何任务。给定一个稀疏的激光雷达点云,CAL(在激光雷达中完成任何任务)能够以零样本的方式进行物体的定位、重建,并可选择性地识别物体。在测试时,通过提供特定物体类别的语义类别词汇,CAL可以被引导执行语义场景补全(SSC)、全景场景补全(PSC)或(非模式)三维物体检测。请注意,CAL仅以单个激光雷达扫描作为输入;RGB图像仅用于可视化目的。
1. 主要贡献
CAL作为第一个零样本激光雷达全景场景补全方法,主要贡献包括:
- 提出了一种伪标签引擎,能够从未标注的多模态数据中自动挖掘3D形状先验和语义特征
- 开发了一个零样本、类别无关的对象补全模型,可以直接从单帧激光雷达数据中推断完整的对象形状
- 实现了开放词汇表的物体识别,突破了传统方法受限于固定类别标签的局限
- 在标准基准上验证了该方法在语义场景补全、全景场景补全和3D物体检测等任务上的有效性
2. 相关工作
2.1 激光雷达分割方法
传统的激光雷达语义分割和全景分割方法主要关注对直接观察到的激光雷达点进行分类,并识别个体实例。大多数方法依赖手动标注的数据集(如Behley等人的工作),而一些研究(如Unal等人和Li等人)则探索了弱监督分割方法以减少标注工作量。
近期研究开始采用视觉基础模型进行开放词汇表的自动标注。Liu等人利用对比学习预训练来提取视觉基础模型特征;Osep等人将视觉基础模型知识蒸馏到零样本激光雷达全景分割模型中;而Peng等人和Xiao等人则将2D基础知识蒸馏到3D领域,但测试时仍依赖激光雷达和相机输入来分类点云。这些方法仅定位物体的可见部分,容易受到信号稀疏性和遮挡的影响。CAL则不同,它专注于激光雷达中的形状补全,解决了分割范围之外的独特挑战。
2.2 激光雷达物体检测
激光雷达物体检测方法将物体定位为定向的3D边界框,包括激光雷达传感器未直接观察到的区域。这类方法通常需要手动标注的3D框,近期研究(如Najibi等人、Zhang等人和Seidenschwarz等人)利用基础模型先验和时间上下文自动获取移动物体的非模态3D框。与此不同,CAL不局限于运动状态下观察到的物体类别,它可以分割和补全任意类别的物体。
2.3 物体级形状补全
从部分观察扫描(如单一视点)进行物体级形状补全通常使用基于数据的方法,依赖物体形状先验。现有研究利用生成对抗网络、自编码器、扩散模型和矢量量化自编码器等生成模型,这些模型通常在提供部分观察和对应3D网格的数据集上训练,或通过数据增强实现。相比之下,CAL通过自动标注解决物体和场景级补全问题。
2.3 场景级补全方法
场景级补全方法通常使用密集体素网格表示标记、预注册的静态环境扫描,这限制了其在大场景中的可扩展性。为解决这一问题,Dai等人使用稀疏编码器结合从粗到细的前馈生成,而Ren等人则在潜在空间中进行扩散。这与机器人感知流不同,后者中的测距传感器提供稀疏测量,方法需要在有动态物体的情况下推断密集场景几何。Li等人探索了稀疏激光雷达数据的隐式场景补全,而Nunes等人则探索基于扩散的激光雷达点云补全。现有的语义场景补全工作需要标记数据集,这需要昂贵的整理工作。
Cao等人使用生成编码器-解码器结合与占用体素交互的变换器解码器,共同解决SSC和实例分割问题。虽然我们的模型受Cao等人启发,但CAL超越了固定类别分类法,不需要手动标记的3D数据集。CAL通过从时间线索提取几何信息和从基础模型中提取开放词汇表语义来解决这些限制。值得注意的是,尽管有研究探索了基于多视图图像的开放词汇表SSC,但据我们所知,还没有先前的工作将开放词汇表、实例级别和基于激光雷达的场景补全结合在单一框架中。
3. 核心算法
CAL主要包含两个关键组件:
- 伪标签引擎:从未标注数据中挖掘形状先验
- 零样本对象补全模型:进行对象补全和识别
3.1 伪标签引擎
伪标签引擎的目标是从无标签数据中挖掘部分观察点云与完整3D形状和CLIP特征的配对。主要步骤包括:
-
视频物体定位:利用分割基础模型(如SAM和SAM 2)在RGB图像序列中分割和跟踪物体,生成时间上连贯的2D掩码序列。
-
语义特征聚合:计算每个实例的CLIP特征并在时间域中聚合,获取多视角的视觉-语言特征。
-
提升和优化:将2D掩码投影到激光雷达坐标系中,并进行精确定位优化。
-
时间聚合:使用已知的自身位姿将掩码投影到参考坐标系中,并随时间聚合以获得密集的3D掩码。体素化后获得每个实例的占用网格,并通过多数投票分配实例索引。此外,通过直接累积360°激光雷达点来补充二进制占用信号,提高标签覆盖率。
-
CRF细化:使用条件随机场(CRF)进一步优化实例掩码,提高标签覆盖率。
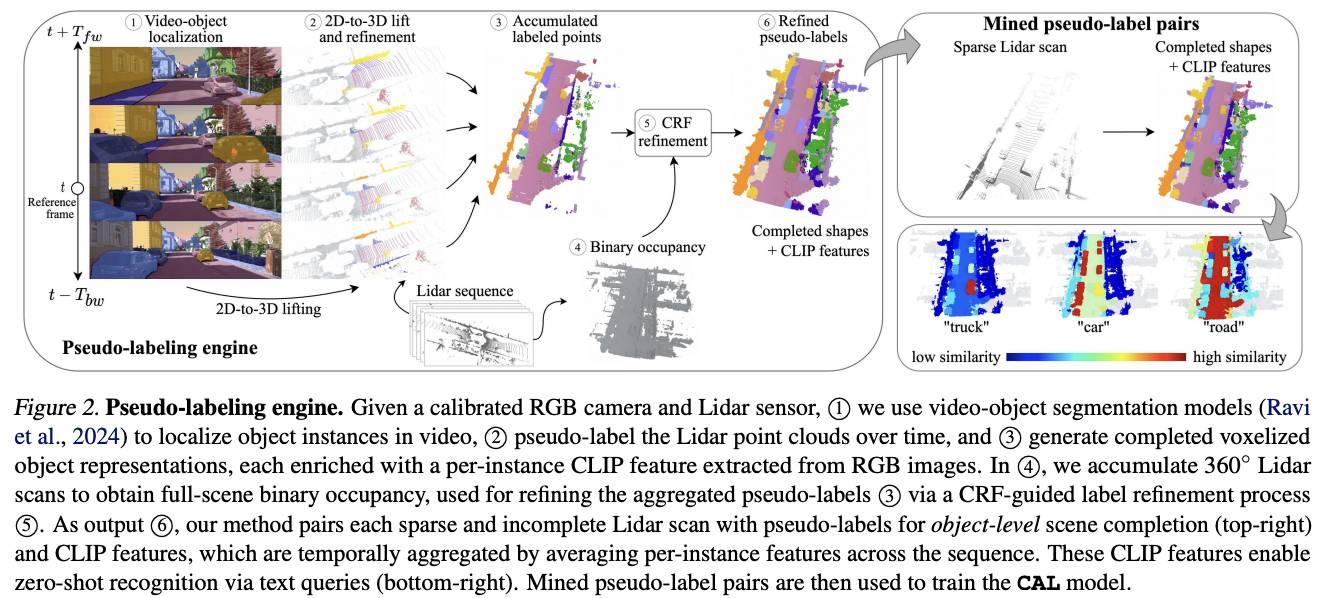
图2. 伪标签引擎。给定一个经过校准的RGB摄像头和激光雷达传感器1 我们利用视频目标分割模型(Ravi et al., 2024)在视频中定位物体实例2 随着时间的推移为激光雷达点云生成伪标签,并3 生成完整的体素化物体表示,每个表示都附带了从RGB图像中提取的每个实例的CLIP特征。4中,我们积累360°的激光雷达扫描,以获取完整场景的二进制占用信息,这些信息用于通过条件随机场引导的标签优化过程 5)来细化聚合的伪标签 3)。作为输出 6),我们的方法将每个稀疏且不完整的激光雷达扫描与物体级场景补全的伪标签(右上方)和CLIP特征配对,这些特征通过对序列中每个实例的特征进行平均以实现时间上的聚合。这些CLIP特征使得通过文本查询实现零样本识别成为可能(右下方)。挖掘出的伪标签对随后用于训练CAL模型。
3.2 零样本对象补全模型
模型架构包含以下主要部分:
-
稀疏-生成3D U-Net架构:由稀疏特征编码器、密集3D卷积块和多尺度生成解码器组成。
-
Transformer实例解码器:使用可学习的查询与生成解码器学习的多分辨率特征在体素空间中交互。预测物体置信度、分割掩码和CLIP特征。
-
生成解码器、补全头和CLIP特征原型:
- 生成解码器包含三个解码块,每个块提供不同尺度的特征,用于预测场景占用率
- 为克服伪标签部分完成的偏差,使用二进制占用指导训练
- 通过聚类将实例CLIP特征量化为伪原型,引入额外的语义头来预测每个占用体素的原型类
- 添加第二个占用头,学习将每类逻辑转换为二进制占用预测,进一步规范化训练
-
训练目标:模型联合训练以完成四个任务:二进制占用补全、类别无关的实例掩码预测、CLIP特征蒸馏和每体素原型分配。最终训练目标是这些损失的加权和。
-
推理过程:模型输出体素网格上的物体实例掩码和每个实例的CLIP特征,通过阈值过滤掉重叠和低置信度的掩码,然后使用预测的CLIP特征以零样本方式对每个查询进行分类。
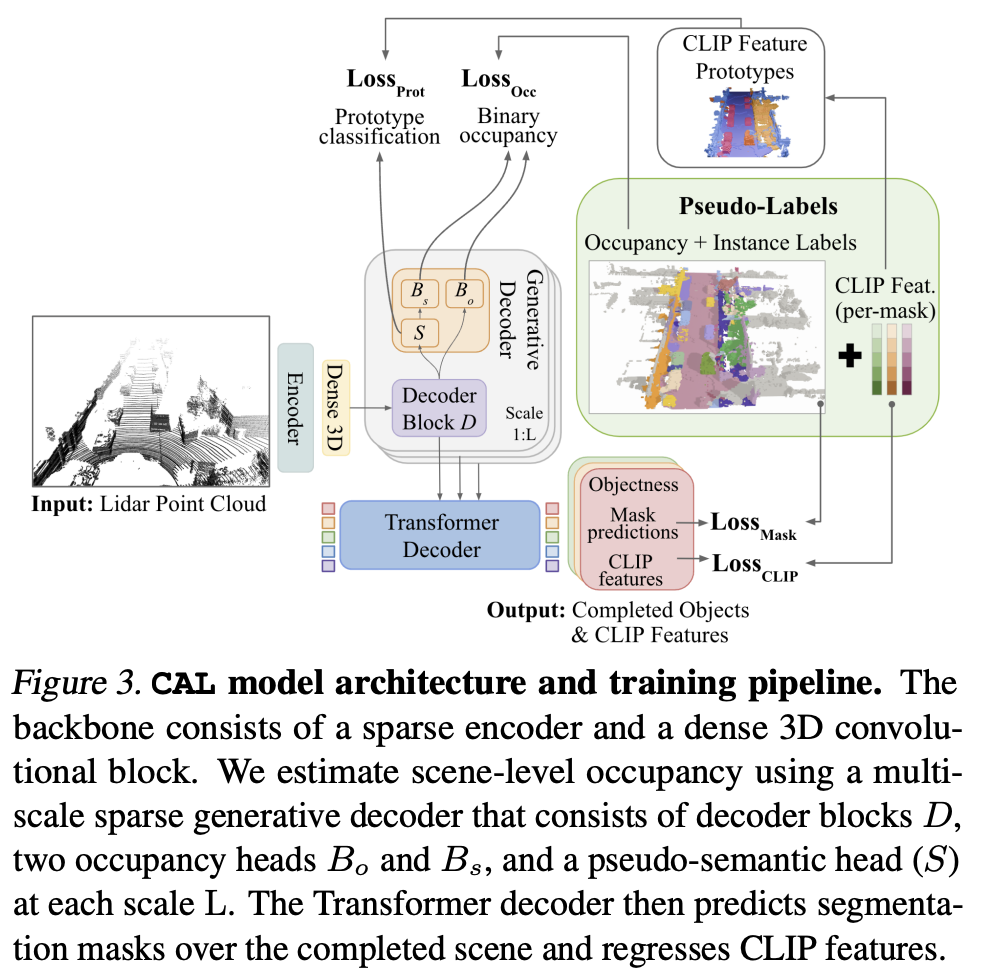
图3. CAL模型架构及训练流程。该模型的主干由稀疏编码器和稠密的3D卷积块组成。我们通过一个多尺度稀疏生成解码器来估计场景级的占用情况,该解码器包括解码块D、两个占用头Bo和Bs,以及在每个尺度L上的伪语义头S。随后,Transformer解码器预测完整场景的分割掩码,并回归CLIP特征。
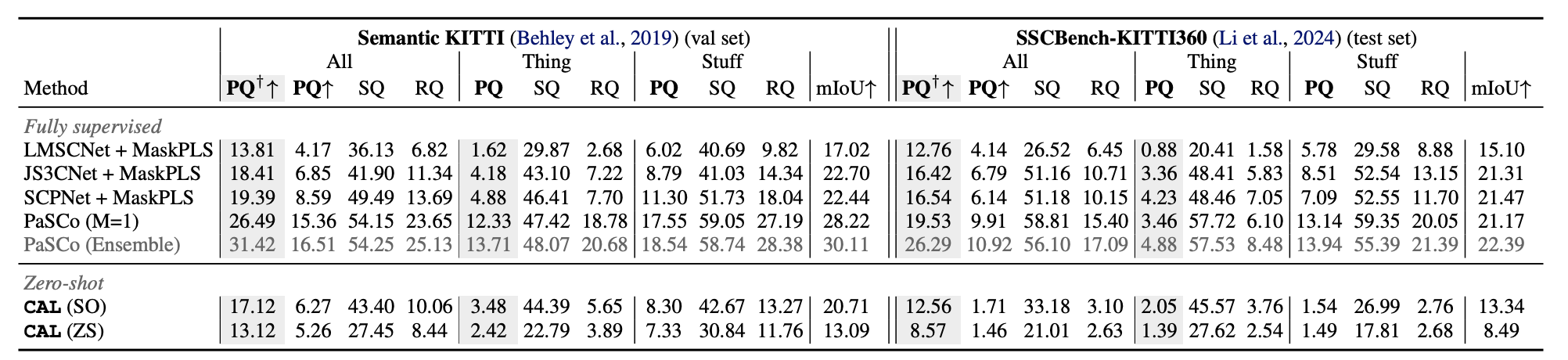
4. 实验结果
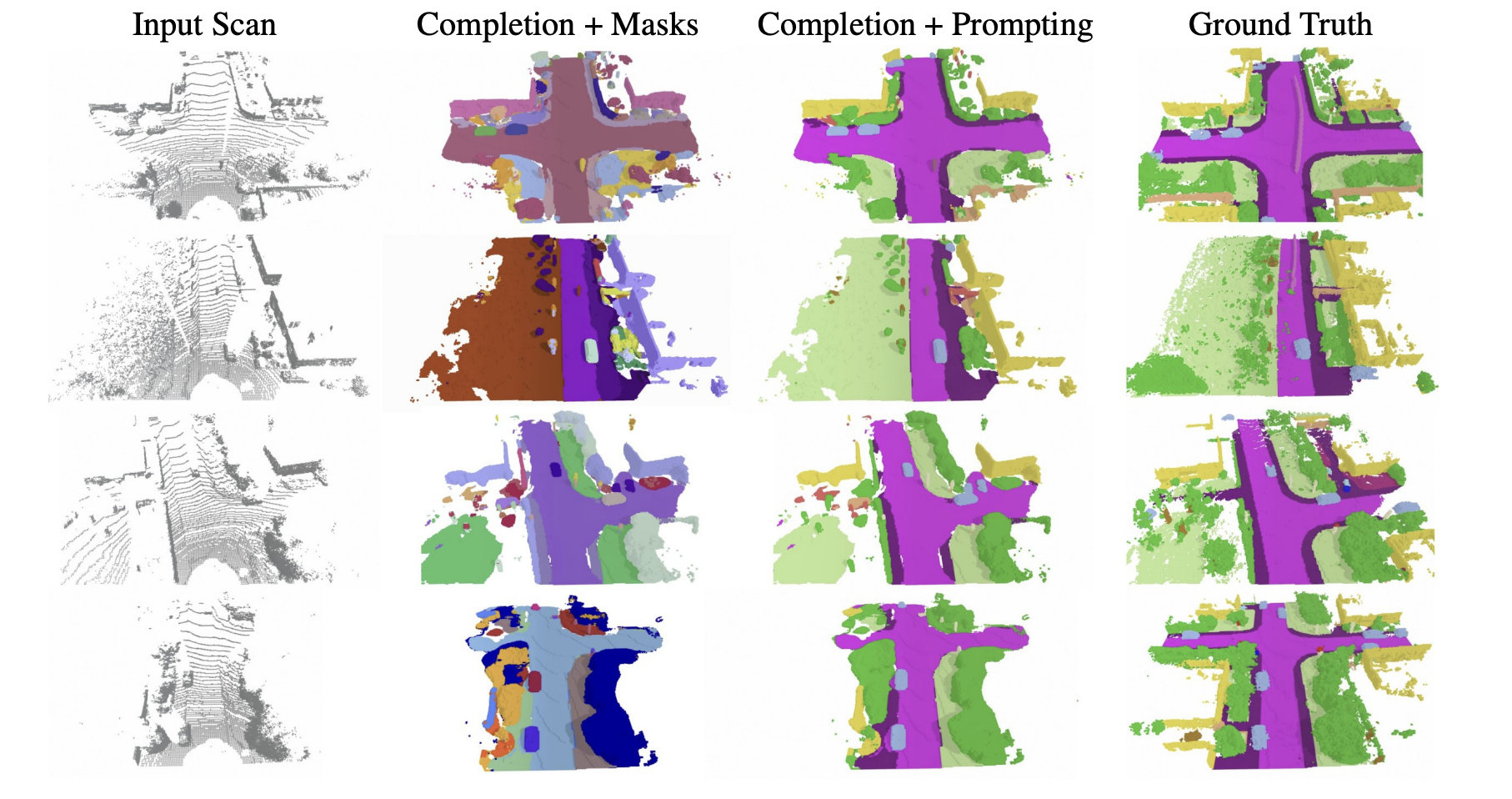
CAL在SemanticKITTI数据集上展示了卓越的性能。实验表明,该方法能够:
-
有效地补全稀疏激光雷达扫描中的物体,包括汽车、骑自行车的人、植被和道路等不同类别
-
准确预测物体形状先验,即使在直接证据有限的情况下也能正确预测交叉几何
-
通过在测试时提供特定对象类别的语义词汇表,CAL可以灵活地执行语义场景补全、全景场景补全或3D物体检测
-
对于开放词汇表的物体识别,CAL表现出色,能够识别训练集中未见过的类别
-
消融实验验证了伪标签引擎中CRF细化和时间聚合等各组件的有效性
5. 结论与展望
CAL作为第一个零样本激光雷达全景场景补全方法,能够完成稀疏和不完整激光雷达扫描中的物体。该工作朝着从时间上下文中学习形状先验迈出了重要一步,为多模态感知奠定了基础。
然而,伪标注引擎的计算成本仍然较高,尽管有CRF的改进,但标签覆盖范围有限。未来可以通过利用自监督的激光雷达预测来改善完全未观察区域的标签覆盖。研究团队相信这些是未来工作的有前途的方向。
作为实际应用,CAL有望提升自动驾驶感知和机器人导航的能力,特别是在处理稀疏传感器数据和识别未知物体方面具有广阔的应用前景。