基于medusa范式的大模型并行解码推理加速初探
一、基于Medusa的投机解码加速
1.1 Blockwise Parallel Decoding
Medusa受到了Noam Shazeer在2018年的工作“Blockwise Parallel Decoding”的启发。Blockwise Parallel Decoding是一种解码方法,旨在加速大型语言模型(LLMs)的推理过程。它通过并行生成多个token来提高解码速度,而不是像传统的自回归解码那样逐个生成token。这种方法可以显著减少生成文本所需的时间,同时保持生成质量。
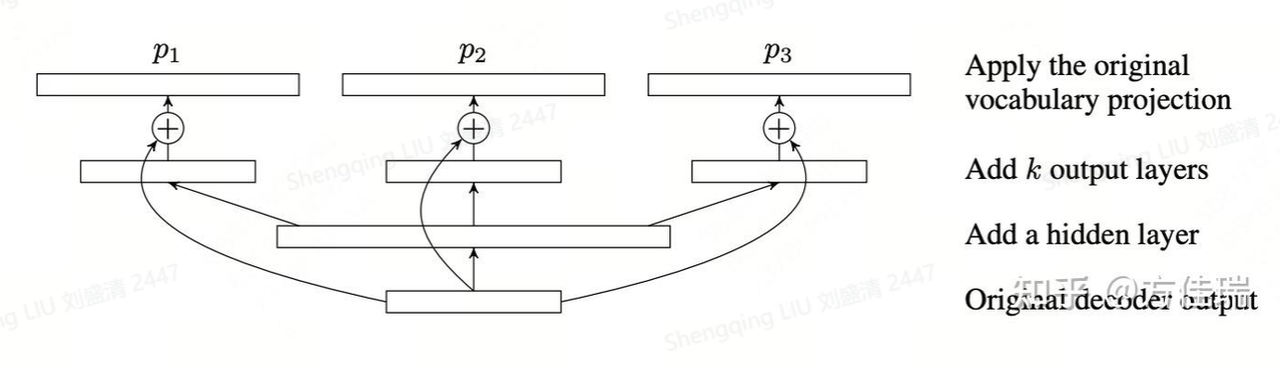
Blockwise Decoding通过在decoder之后加入三个简单的输出层来生成不同token位置对应的logits。在具体实现中,输入会正常通过模型的各个隐藏层,在最后一层后将最终的hidden states传给不同的输出层,用以生成不同位置的token。作者认为,在某些任务中,大模型具备同时预测多个位置的token的能力。
Blockwise Decoding的局限性: 该框架作为多头解码范式的开山之作,存在一些局限:
- 这里只使用了一个简单的映射层作为解码头。
- 这里的采样只能选择top-1的greedy sampling(贪婪采样)。
1.2 Medusa模型
- Medusa基于多头解码范式进行了进一步的继承和发展
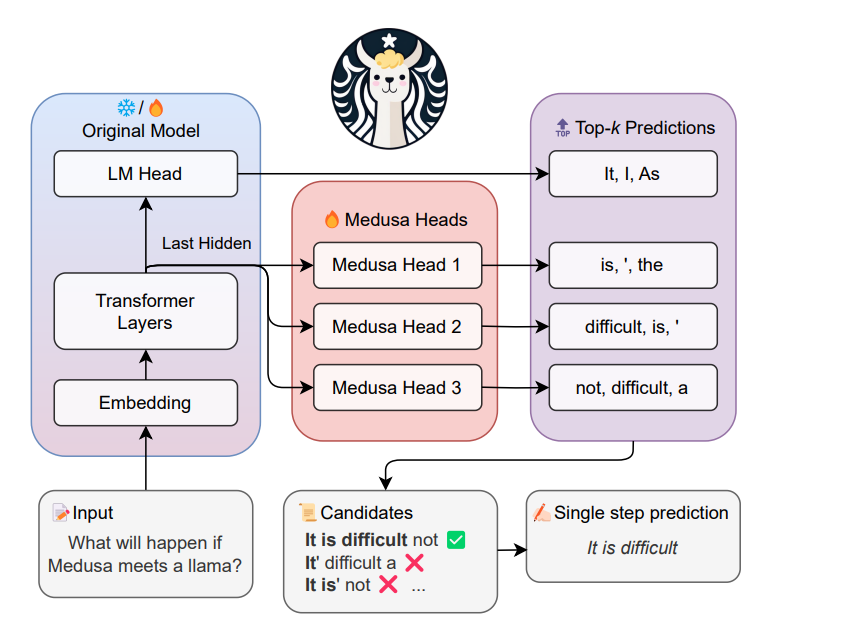
medusa核心要点:
-
受到bockwise parallel decoding的启发,在LLM模型基础上增加几个 medusa head,每一个head预测下一个token。
-
解除bockwise parallel decoding中使用top-1采样的限制,medusa 每个head使用top-k的结果,不同head的候选集合组成一个树状的笛卡尔集。原始模型验证这个笛卡尔集使用改进Mask的Tree Attention方法,从而增大并行解码被验证接受的概率。
-
和之前的验证方式不一样,medusa选择了使用一个阈值来判断是不是被接受!具体可以参看medusa代码中的evaluate_posterior函数
主要思想是在正常的LLM的基础上,增加几个解码头,并且每个头预测的偏移量是不同的,比如原始的头预测第i个token,而新增的medusa heads分别为预测第i+1,i+2...个token。如上图,并且每个头可以指定topk个结果,这样可以将所有的topk组装成一个一个的候选结果,最后选择最优的结果。
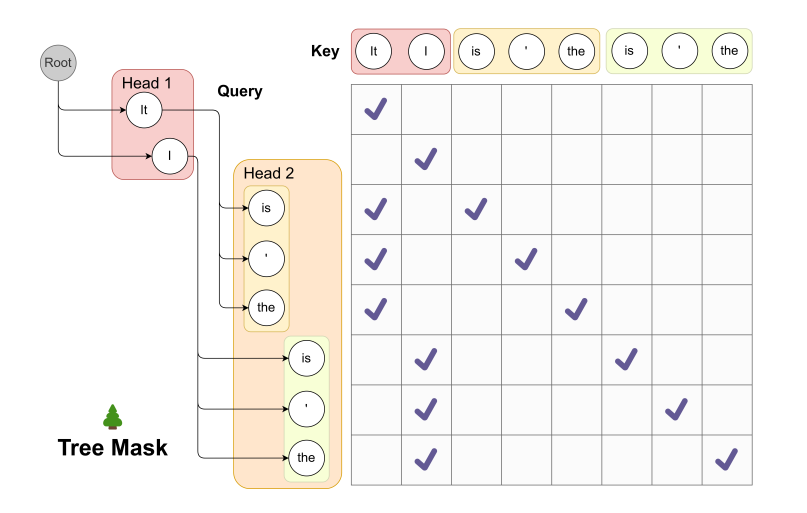
计算每个头组装之后的候选的最优解,其实这时候完全可以每个候选都走一次模型,算出概率,但是很显然不可能这样做,因为本来方案是为了加速,作者设计了一种tree attention的机制,可以做到只走一次模型来达到目的,如示例所示,第一个medusa heads的 top-2 预测和第二个medusa heads的 top-3 预测产生 2*3=6 个候选。假设原始的LLM输出是[0],第一个头是[1,2],第二个头是[3,4,5]。期望直接能把[0,1,2,3,4,5],输入模型就能得到一些概率的信息,但是不同的头对应的token的父节点是不同的,所以对应不同头的token, 他们的深度信息是不一样的。这样子就构建了一个tree attention mask 矩阵。
下图展示了Tree Attention的例子。其中我们使用来自第一个Head的前2个预测,和来自第二个的前3个预测,如下所示。在这种情况下,第一个头部的任何预测都可以与第二个头部的任何预测配对,最终形成一个多层树结构。这棵树的每一层都对应于一个Medusa Head的预测。在这棵树内,Attention Mask需要新的设计,该Mask只限制对一个token的前面token的注意力, 也就是该token 只能获取到改token之前和本身的attention信息,之后的和不是一条组合的信息是不能获取到的。如下例子中,Attention Mask大小是(2+2*3)*(2+2*3) =8*8。”is , the“这三个token分别attention to It和I两个token。 同时,要为相应地为position embedding设置正确的位置索引。
第一次用美杜莎头解码的时候,是看不到前面i个token的,而再次输入模型可以看到完整的上文,得到完整的概率之后,可以通过头计算得到树的路径信息,比如示例对应的路径index是[0,1,3] , [0,1,4], [0,1,5], [0,2,6],然后基于后验概率得到最优的候选片, 每个token的概率分布, 通常是和一个预设阈值进行比较。从 head-1 开始依次判断,如果 head-n 的评分分数满足阈值条件,就接受其预测 token。如果没有任何 head 满足要求,就默认只生成一个 token,也就是LM 头生成的token。
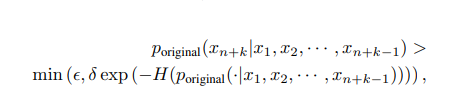
空白表示是不能获取的。
1.3 Medusa 多头并行解码总结
-
树注意力机制:
-
树注意力机制通过树状结构来组织所有候选的token。
-
每个token只能看到自己当前路径上的prefix(前缀),确保每条路径互不干扰。
-
-
掩码(Masking):
-
通过掩码技术实现每个token只能看到自己当前路径上的prefix,从而确保每条路径互不干扰。
-
-
Medusa模型:
-
Medusa模型引入了树注意力机制,通过这种方式,Medusa只需要对这些候选进行一次forward pass(前向传播)就能对所有路径并行地实现验证(verify)。
-
Medusa不保证和原始top-p相同Sampling分布,而是设计一个朴素地基于阈值的方法。因为这种方法并不和创新解码等价,大家对它的接受程度还有待验证。
-