【LLaMAFactory】LoRa + 魔搭 微调大模型实战
前言
环境准备
之前是在colab上玩,这次在国内的环境上玩玩。
魔搭:https://www.modelscope.cn/
现在注册,有100小时的GPU算力使用。注册好了之后:
魔搭社区
这里使用qwen2.5-7B-Instruct模型,这里后缀Instruct是指对预训练进行过指令微调的大模型。这种模型特别适用于指令微调。
GPU资源
这里选择免费实例,只要是刚注册都有100小时的免费算力。
接着选择方式二:
再点击查看Notebook就会进入在线的操作页面。
我们可以先来查看下GPU资源情况:
先打开一个新tab页,点击左上角的+号,选择terminal
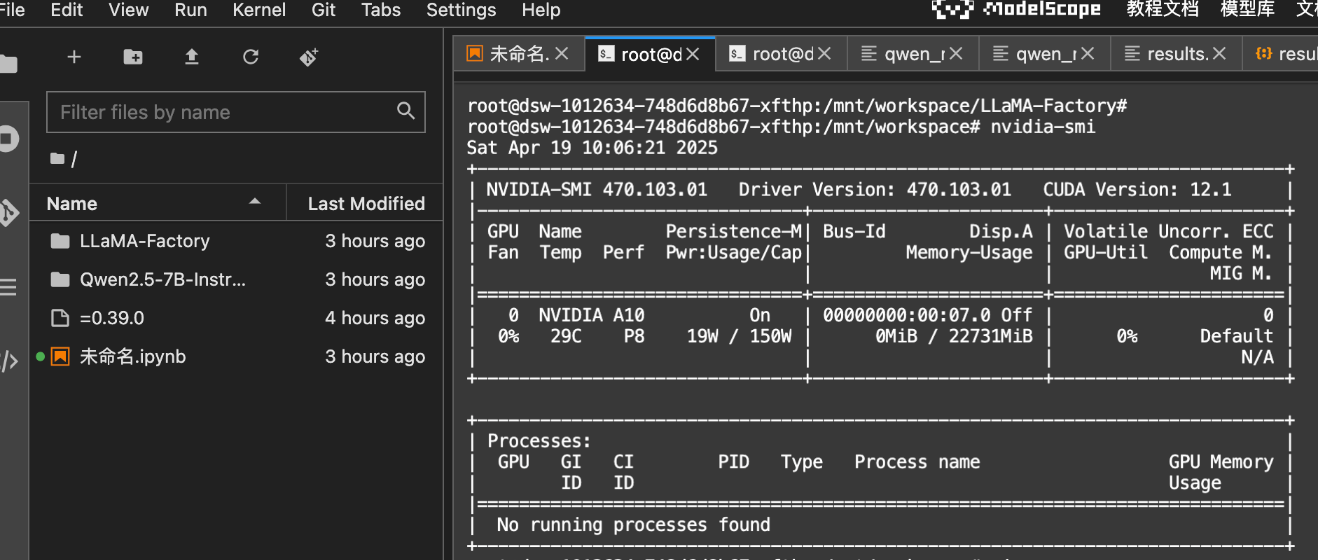
再执行如下命令:
nvidia-smi
安装依赖库
在terminal中执行如下命令:
pip3 install --upgrade pip
pip3 install bitsandbytes>=0.39.0
说明:bitsandbytes 是一个由 Facebook Research 开发的轻量级开源库(基于 MIT 协议),专注于通过低比特精度量化技术优化深度学习模型的训练和推理效率。即:使一个专注于优化计算效率的库。
安装LLaMAFactory
参考官网:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md#%E5%AE%89%E8%A3%85-llama-factory
执行如下命令:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
第一次执行会报错,如下:
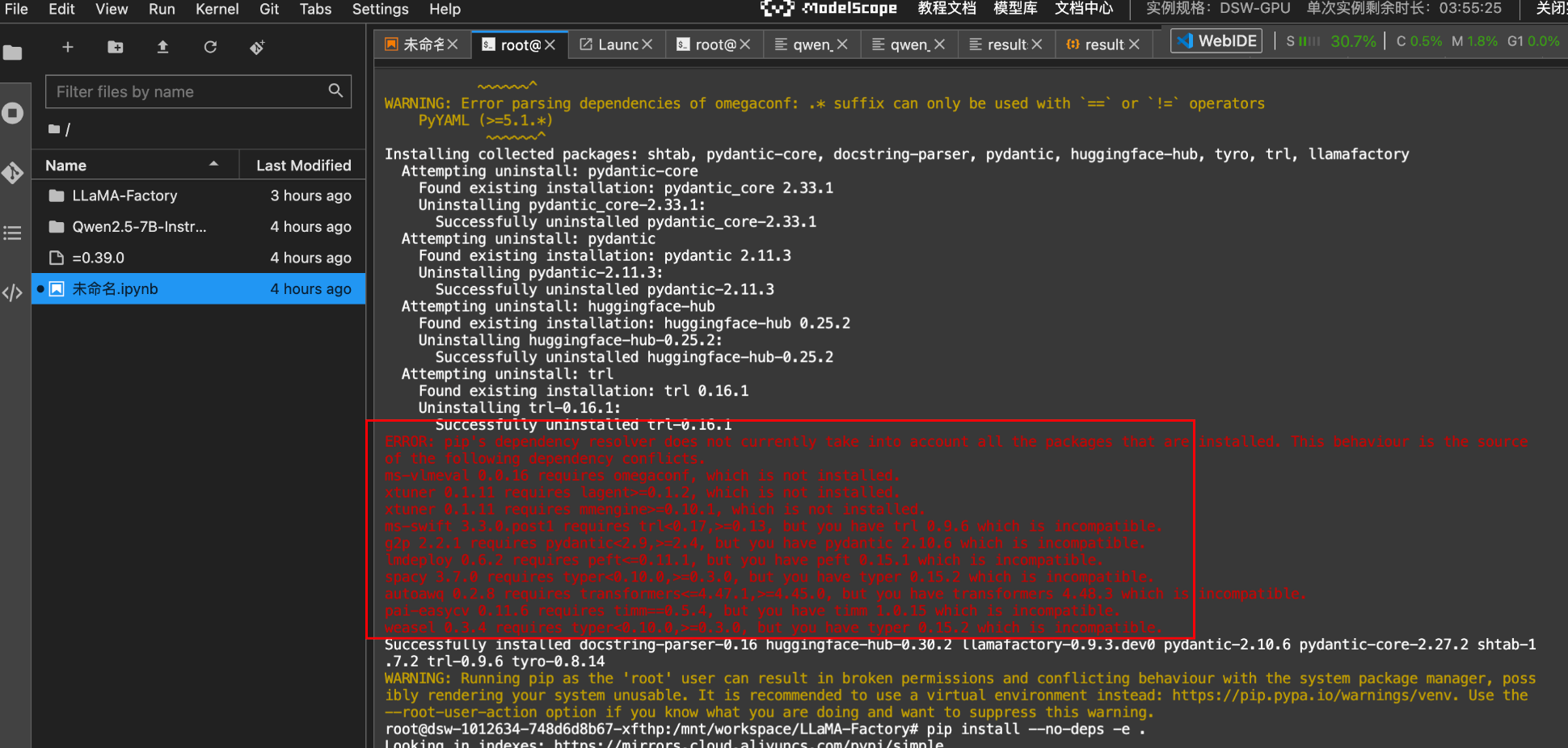
这是因为包冲突导致的,执行如下命令解决冲突:
pip install --no-deps -e .
之后再次执行:
pip install -e ".[torch,metrics]"
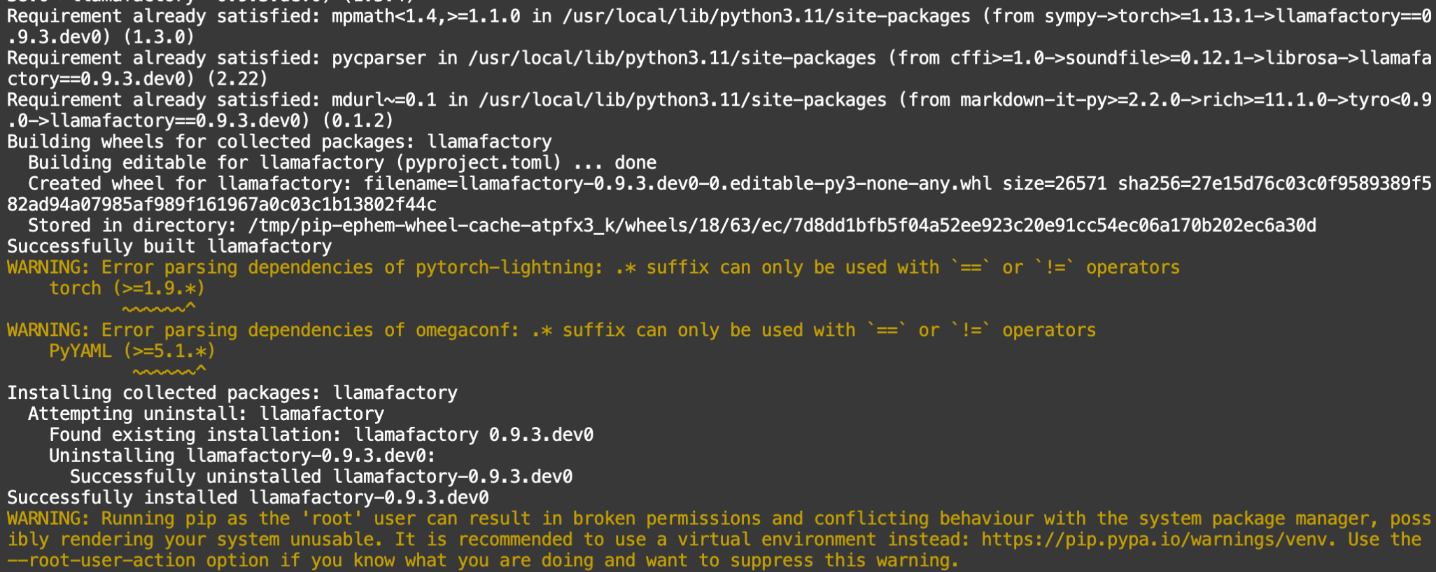
自此安装完毕。
微调模型的下载
在魔搭的模型库中找到通义千问2.5-7B-Instruct:
这里我们选择git下载:
执行命令:
root@dsw-xxx-xfthp:/mnt/workspace# git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
下载好之后,我们可以在左边看到相应的文件:
微调大模型
通过上面的操作,我们的基础资源已经准备就绪。
修改微调配置文件
在窗口的左侧的文件列表,进入到LLaMA-Factory/examples/train_lora中:
命令的路径:/mnt/workspace/LLaMA-Factory/examples/train_lora
复制一份:llama3_lora_sft.yaml文件,重命名:qwen_lora_sft-bitsandbytes.yaml。
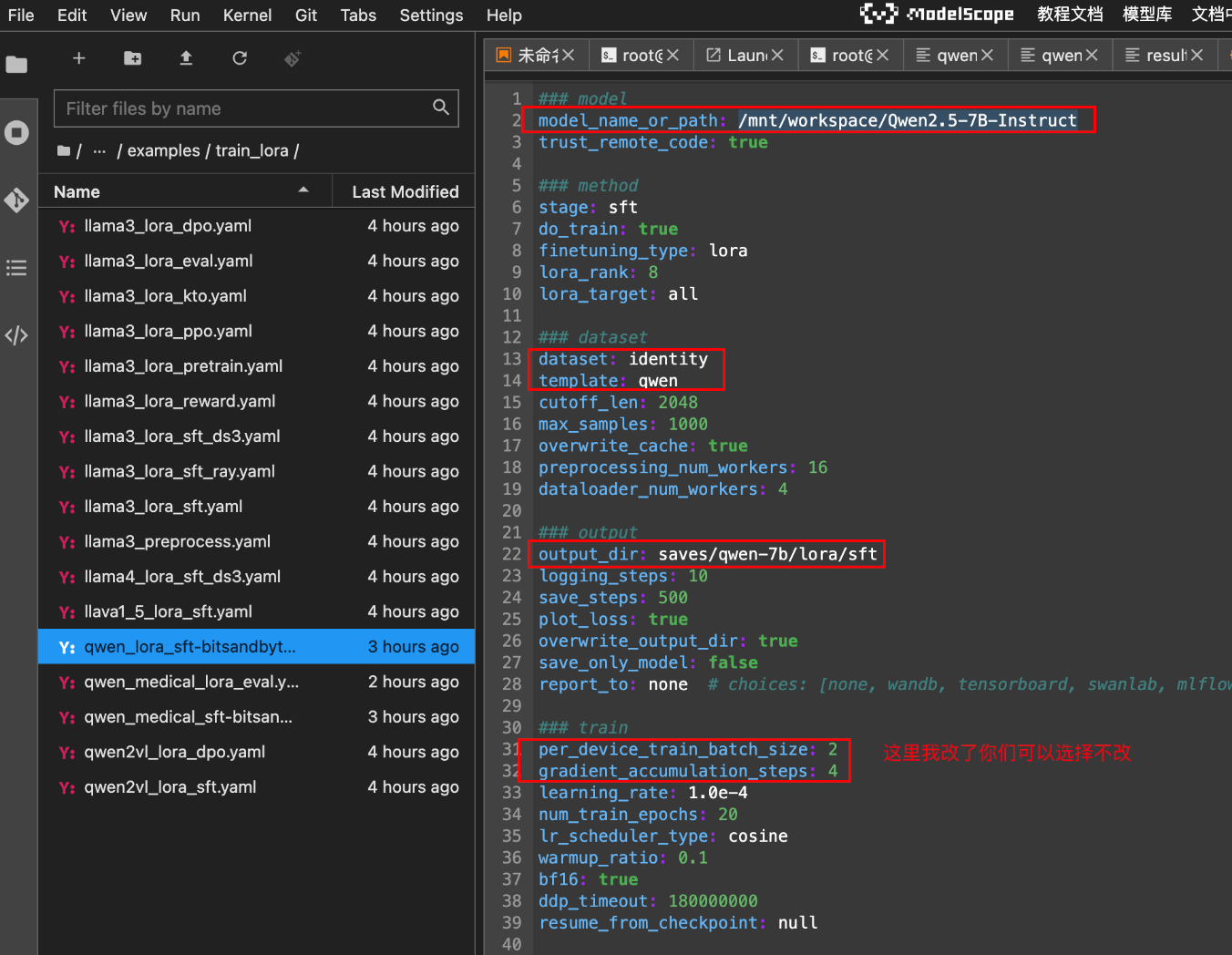
- 这个文件就是微调配置文件。第一行
model_name_or_path就是我们刚刚下载大模型的路径。
其他参数还有:
- dataset: 表示的是数据集
- template:这个是训练指令模板
- output_dir:训练完成后,保存参数、配置、模型的路径
### train这个下面训练的超参数,一般都不需要该,唯一需要调整的可能是训练轮次num_train_epochs。一轮是指对整个数据集进行一次完整的遍历。
dataset 数据集
LLaMA-Factory项目内置了很多数据集,统一都放在data目录下面。所以我们微调时,直接使用即可。
比如我们这次用到的:identity.json。数据集名称叫:identity。
启动微调
下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
我们根据实际情况,修改上面的命令即可。
可以使用
llamafactory-cli help显示帮助信息。
在LLaMA-Factory目录下,执行命令:
llamafactory-cli train examples/train_lora/qwen_lora_sft-bitsandbytes.yaml
#实际执行长这个样子
root@dsw-xxx-xfthp:/mnt/workspace/LLaMA-Factory# llamafactory-cli train examples/train_lora/qwen_lora_sft-bitsandbytes.yaml
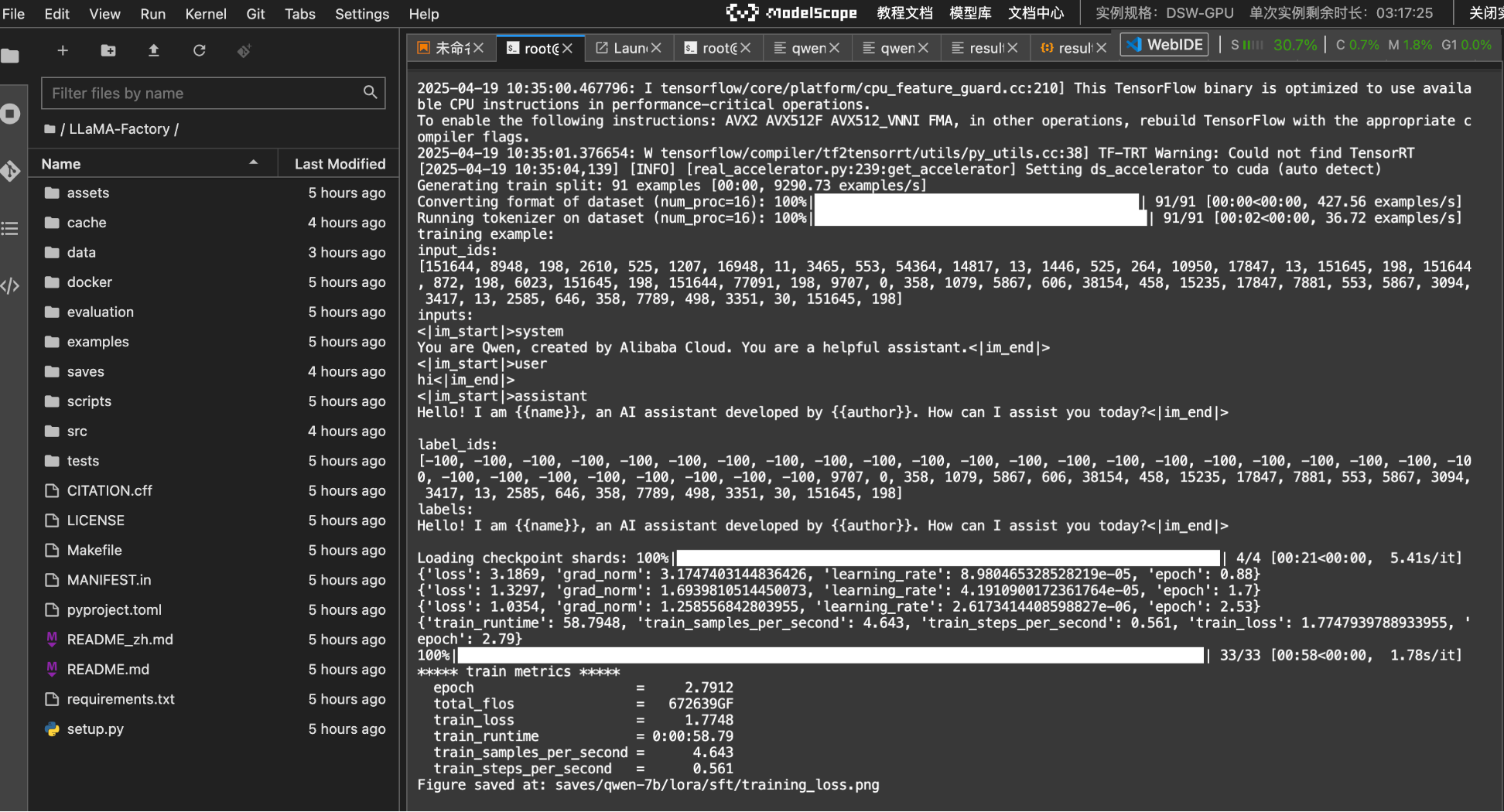
第一次训练由于训练轮次是默认值:3,所以非常就结束了(58秒)。
可以去saves/qwen-7b/lora/sft/training_loss.png目录下查看训练损失比例图。
下面这个已经是我调整过训练轮次的图了,第一次训练的图已经被覆盖掉了。
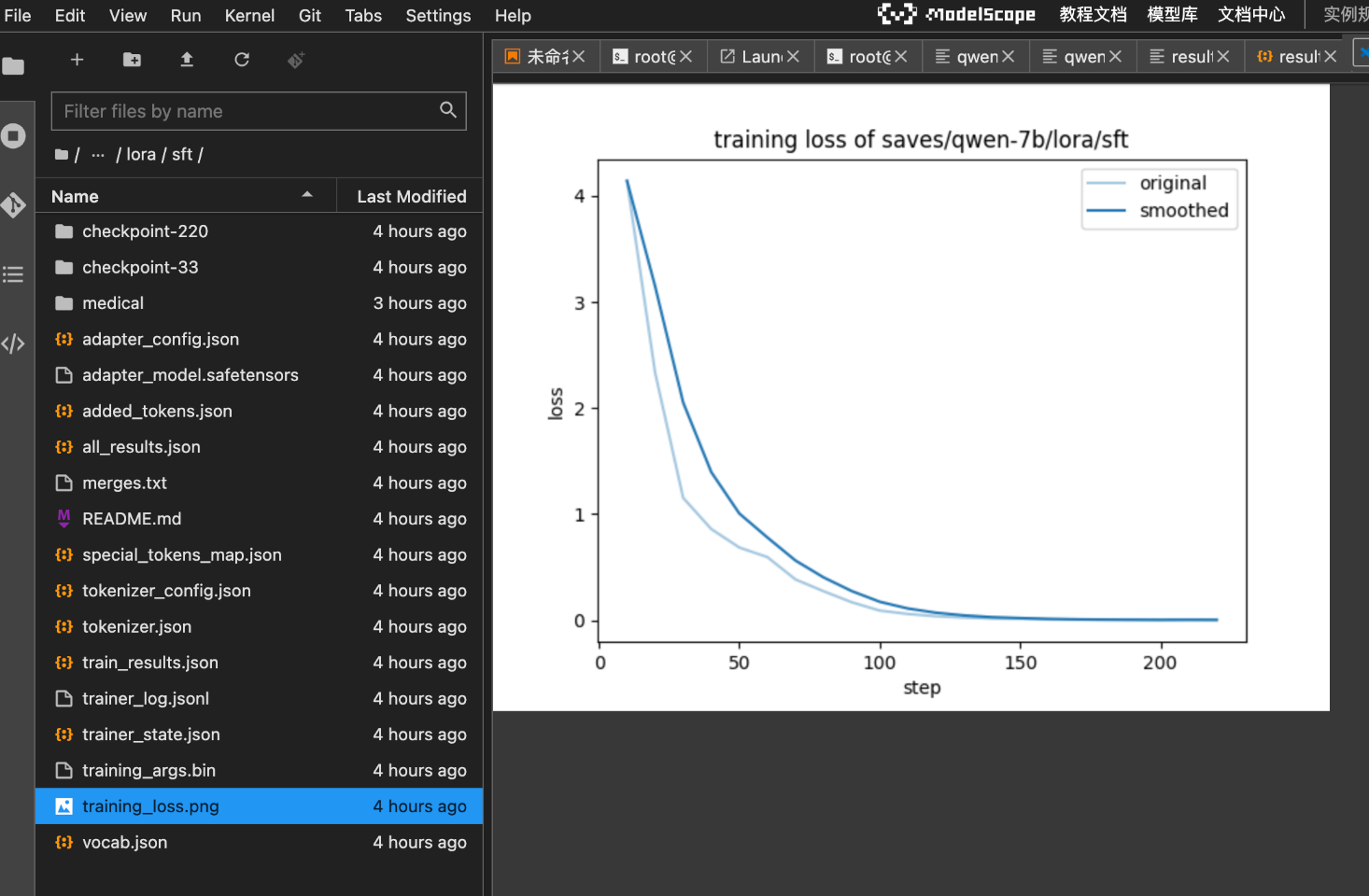
- 微调后的损失函数,大家能看到损失函数在持续的下降:说明微调达到效果了。在
saves/qwen-7b/lora/sft/路径下面还有checkpoint文件,这里保存这微调训练阶段的权重等配置文件,类似于快照。 - 另外,我们还能看到很多json的配置文件;这些配置文件都是微调后,生成的针对微调模型的配置参数,也就是可以理解为诞生了一个新的模型。
说明:
- 损失函数:模型评测的关键参数,损失函数下降的越快结果也就越好,微调时要重点关注
- 训练效果:随着训练步骤的增加,模型的损失值显著下降,表明模型在不断学习和优化。
- 平滑处理:平滑处理后的损失曲线更清晰地展示了损失下降的趋势,有助于更好地理解训练过程中性能变化。
推理测试
微调训练结束后,会在/mnt/workspace/LLaMA-Factory/saves目录下存储训练好的模型文件;
LLaMA-Factory本身就提供了微调模型推理方法。
LLaMA-Factory参考的推理文件存放在:examples/inference中。
1.步骤一,修改推理的配置文件
和上面训练配置文件类似,我们先对llama3_lora_sft.yaml文件,进行复制一份并重命名:qwen_lora_sft.yaml。
修改参数如下:
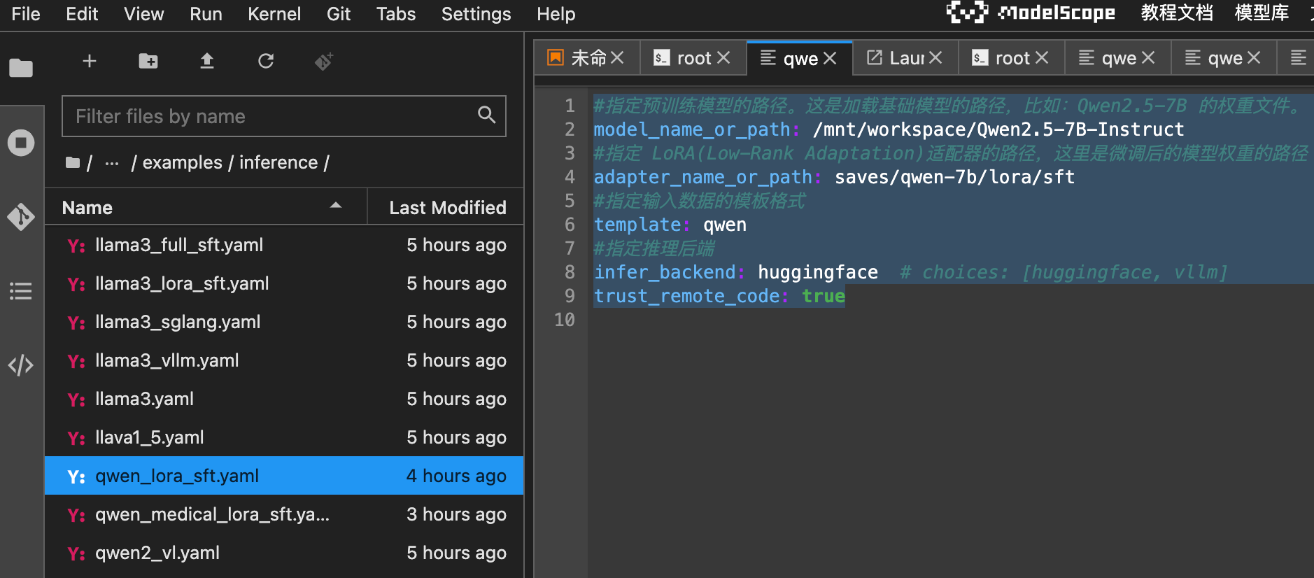
#指定预训练模型的路径。这是加载基础模型的路径,比如:Qwen2.5-7B 的权重文件。
model_name_or_path: /mnt/workspace/Qwen2.5-7B-Instruct
#指定 LoRA(Low-Rank Adaptation)适配器的路径,这里是微调后的模型权重的路径
adapter_name_or_path: saves/qwen-7b/lora/sft
#指定输入数据的模板格式
template: qwen
#指定推理后端
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: true
在窗口输入如下的启动推理服务命令:
在LLaMA-Factory目录下执行:
llamafactory-cli chat examples/inference/qwen_lora_sft.yaml
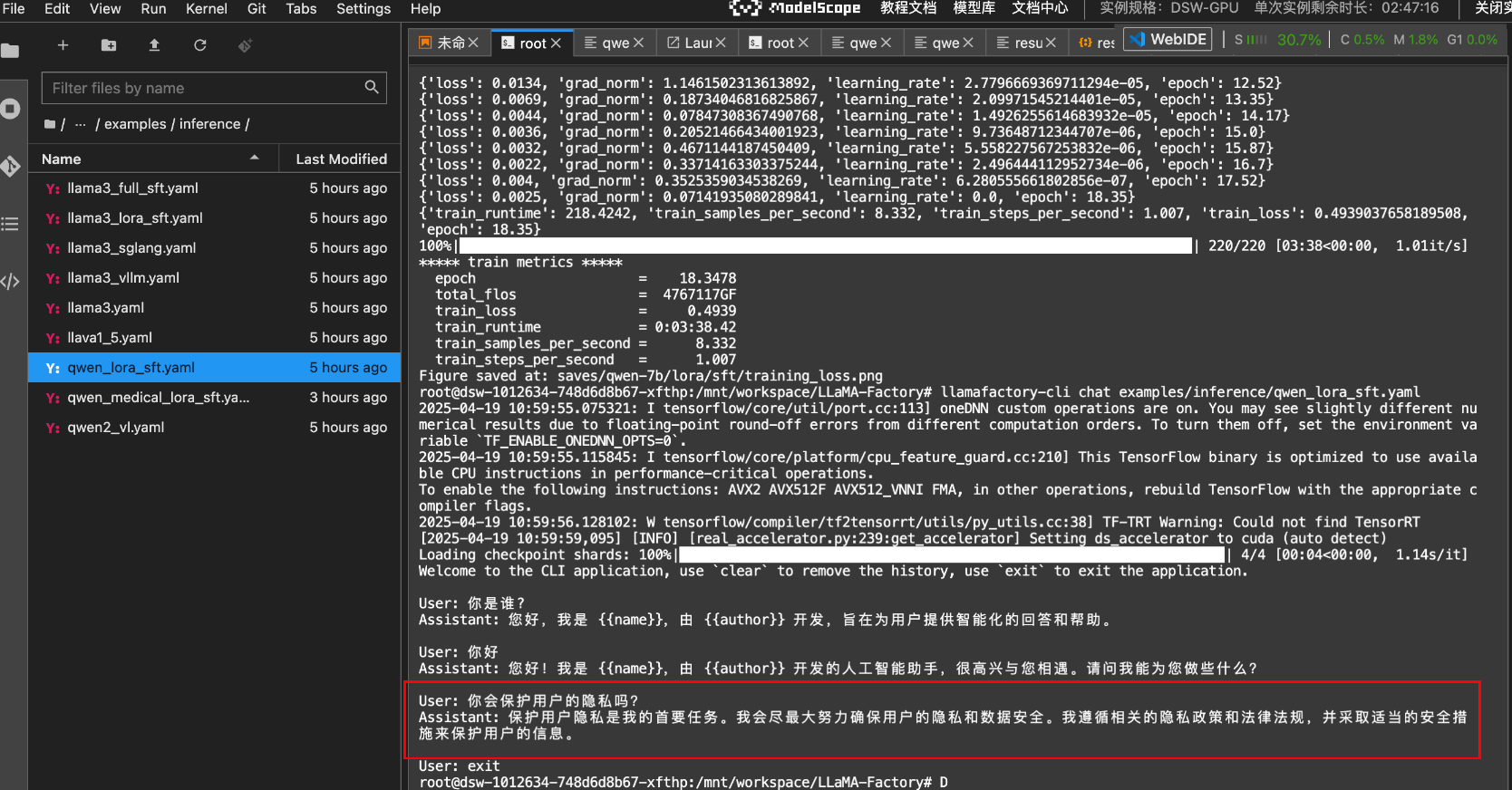
说明:默认训练配置文件中的训练轮次是3次。还是觉得不准,可以考虑增加训练轮次,或者学习率。
web UI 界面
LLaMA-Factory也是提供了web UI界面的。我们可以执行如下命令来启动它:
export CUDA_VISIBLE_DEVICES=0
root@dsw /mnt/workspace/LLaMA-Factory# python src/webui.py
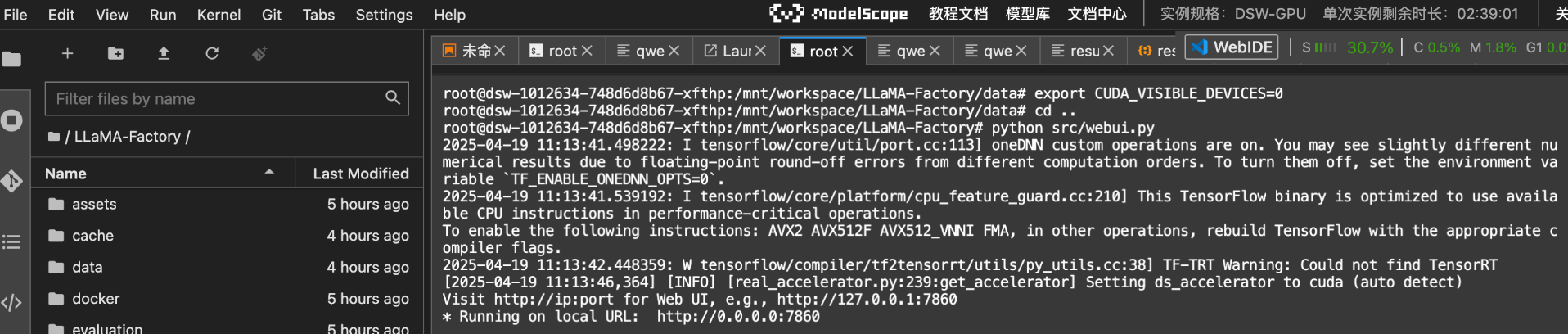
浏览器中打开http://127.0.0.1:7860:
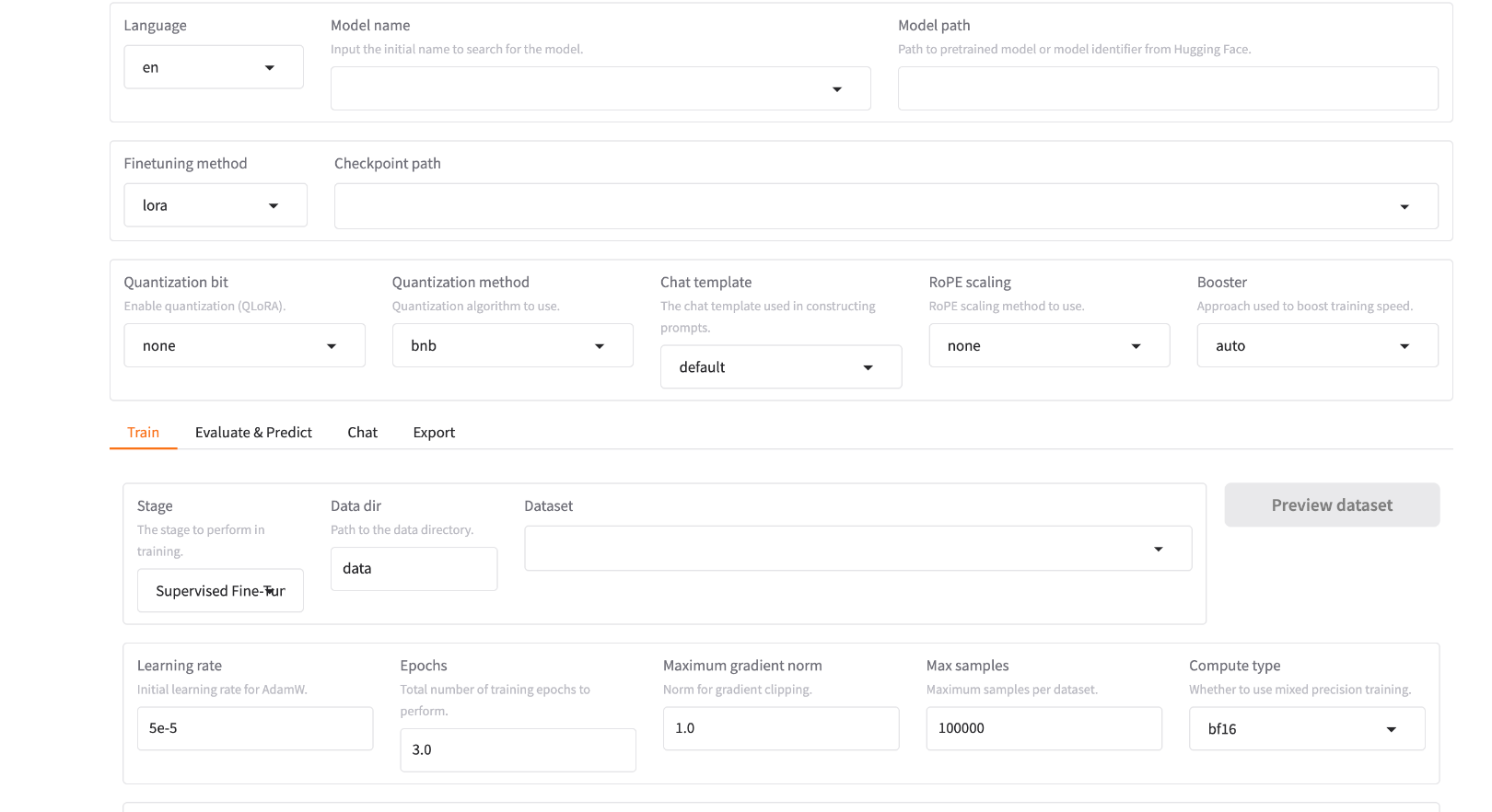
说实话,这页面和stable diffusion的那个web页面是真的好像。
使用web页面也是一样训练的,其本质也是后台会执行类似我们命令行的那些命令。
微调中文医疗对话数据
我们再微调一个大模型。再次加深印象,这次我们不再使用LLaMA-Factory自带的数据集,而是使用魔搭上面的数据集。
在魔搭中的数据集找到中文医疗对话数据:
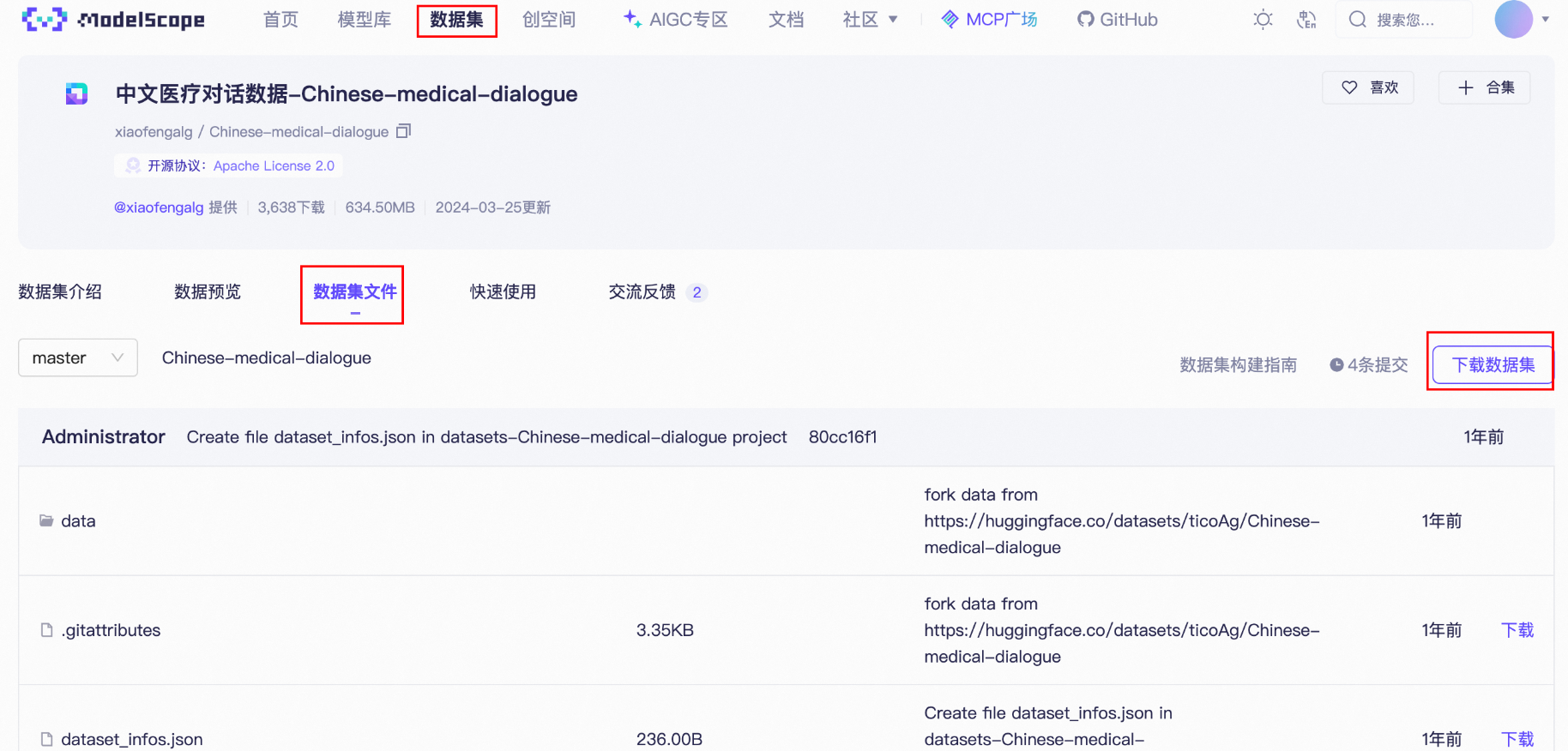
这里我们依然使用git下载。
我们进入到/mnt/workspace/LLaMA-Factory/data目录下执行如下命令:
git clone https://www.modelscope.cn/datasets/xiaofengalg/Chinese-medical-dialogue.git
注册自定义的数据集
因为这个数据集是我们下载下来的。所以得让LLaMA-Factory项目认识它。
在data目录下的dataset_info.json文件中添加:
"yutao_sft_train_data": {"file_name":"Chinese-medical-dialogue/data/train_0001_of_0001.json""columns": {"prompt": "instruction","query":"input","response":"output"}}
再次正常打开dataset_info.json文件时:
微调医疗大模型
修改微调训练配置文件
和上面一样,我们需要单独从llama3_lora_sft.yaml文件中再复制一份,复制后的文件名:qwen_medical_sft-bitsandbytes.yaml
老规矩对其进行修改:
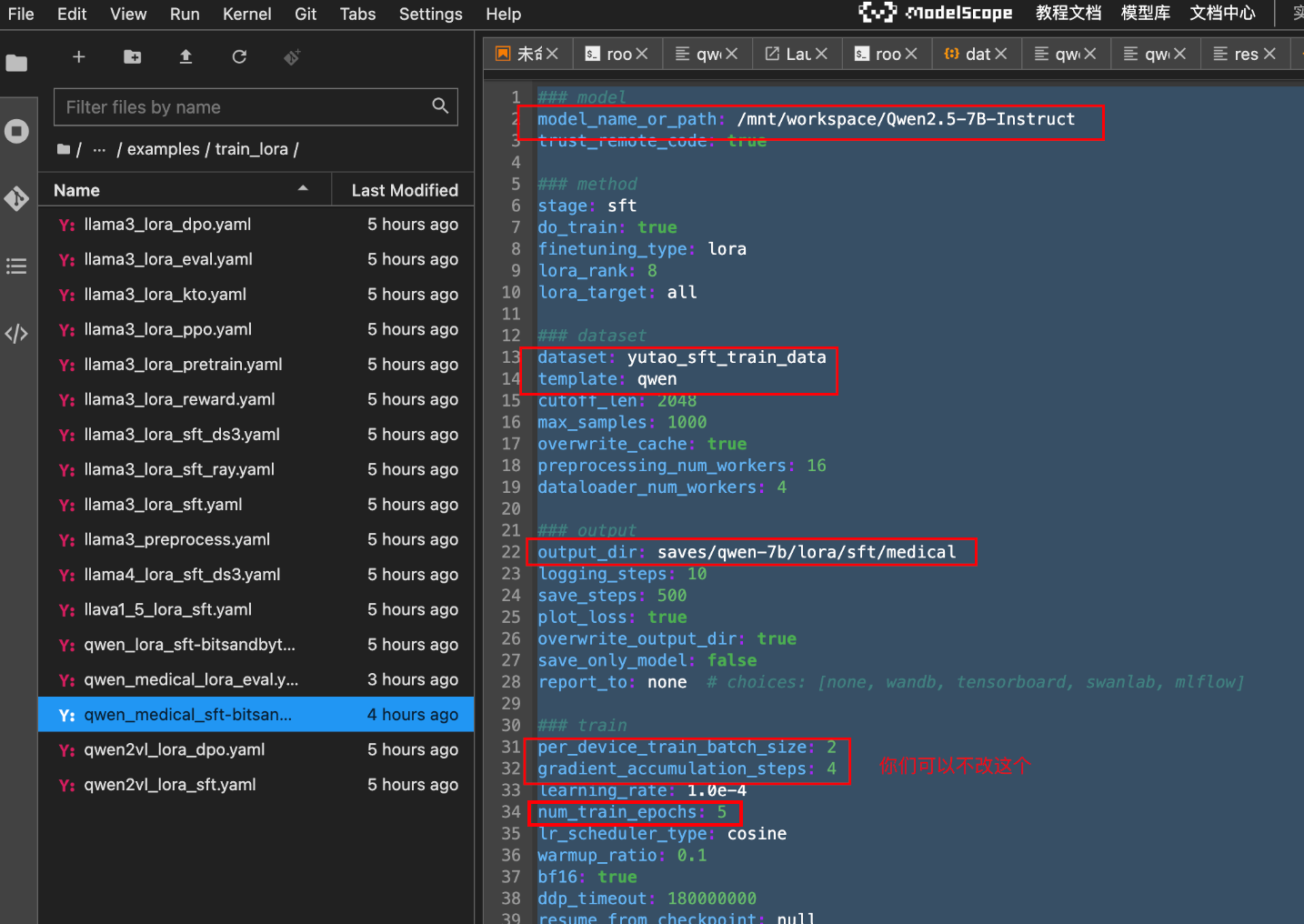
这次数据集比较大,所以训练时间会比较长,

推理医疗大模型
启动推理服务,也是和上面一样,先复制一份推理配置,然后对其进行修改,并执行如下命令启动服务:
llamafactory-cli chat examples/inference/qwen_medical_lora_sft.yaml
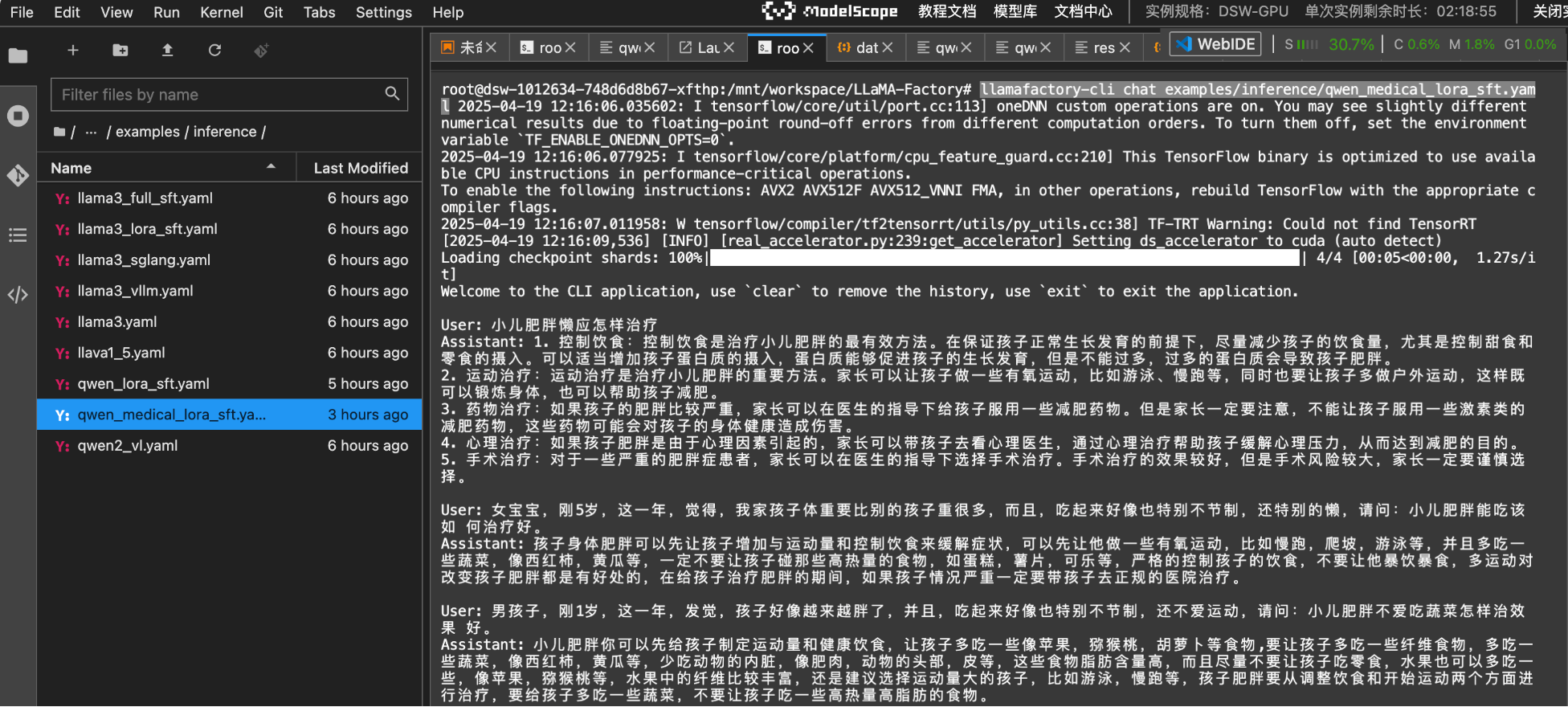
模型调试
验证数据集
大模型完成微调后,还需要对其进行评估和测试,验证微调的效果。LLaMA-Factory项目也提供了评估的脚本。
在微调模型的配置文件中,打开评估配置,调整好配置,如:数据集。
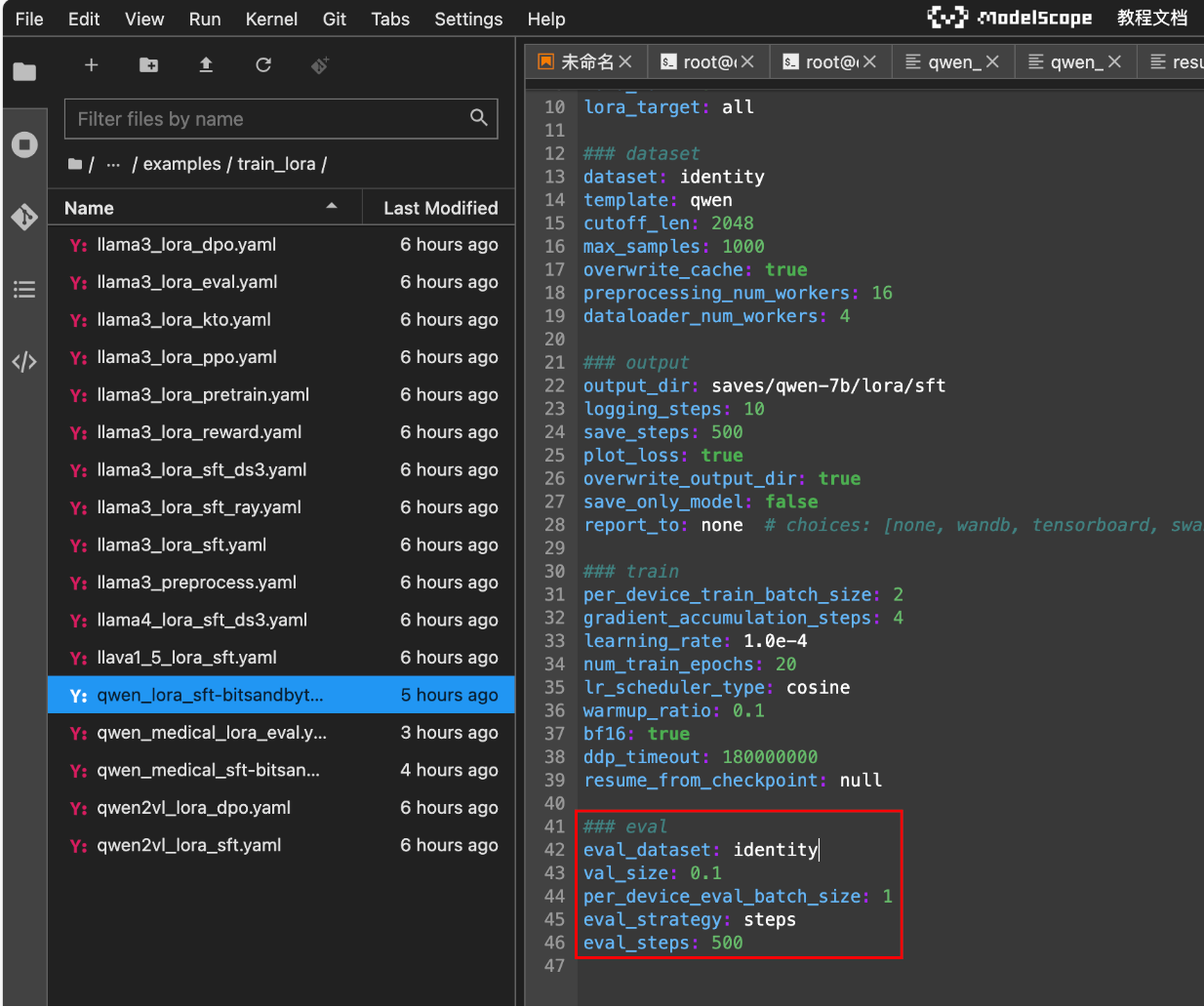
其中val_size: 0.1含义就是拿验证数据集10%进行验证。
然后再次启动微调,你会发现报错了:
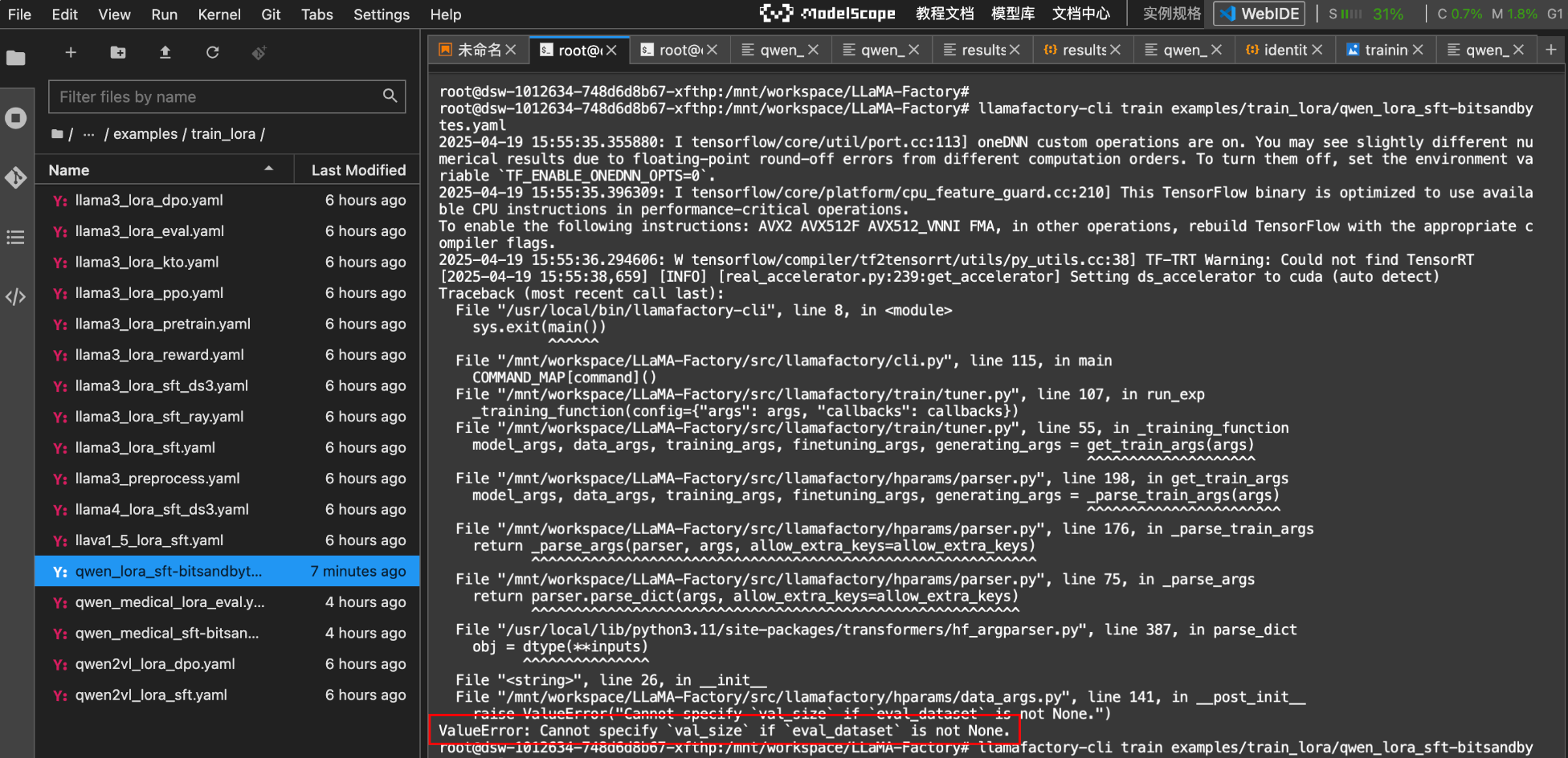
按照错误的意思,解决方案就是:如果你已经使用了 eval_dataset,就不应该再使用 val_size。 相反,你应该只使用 eval_dataset 来指定评估数据集。
所以我们把eval_dataset参数注释掉:
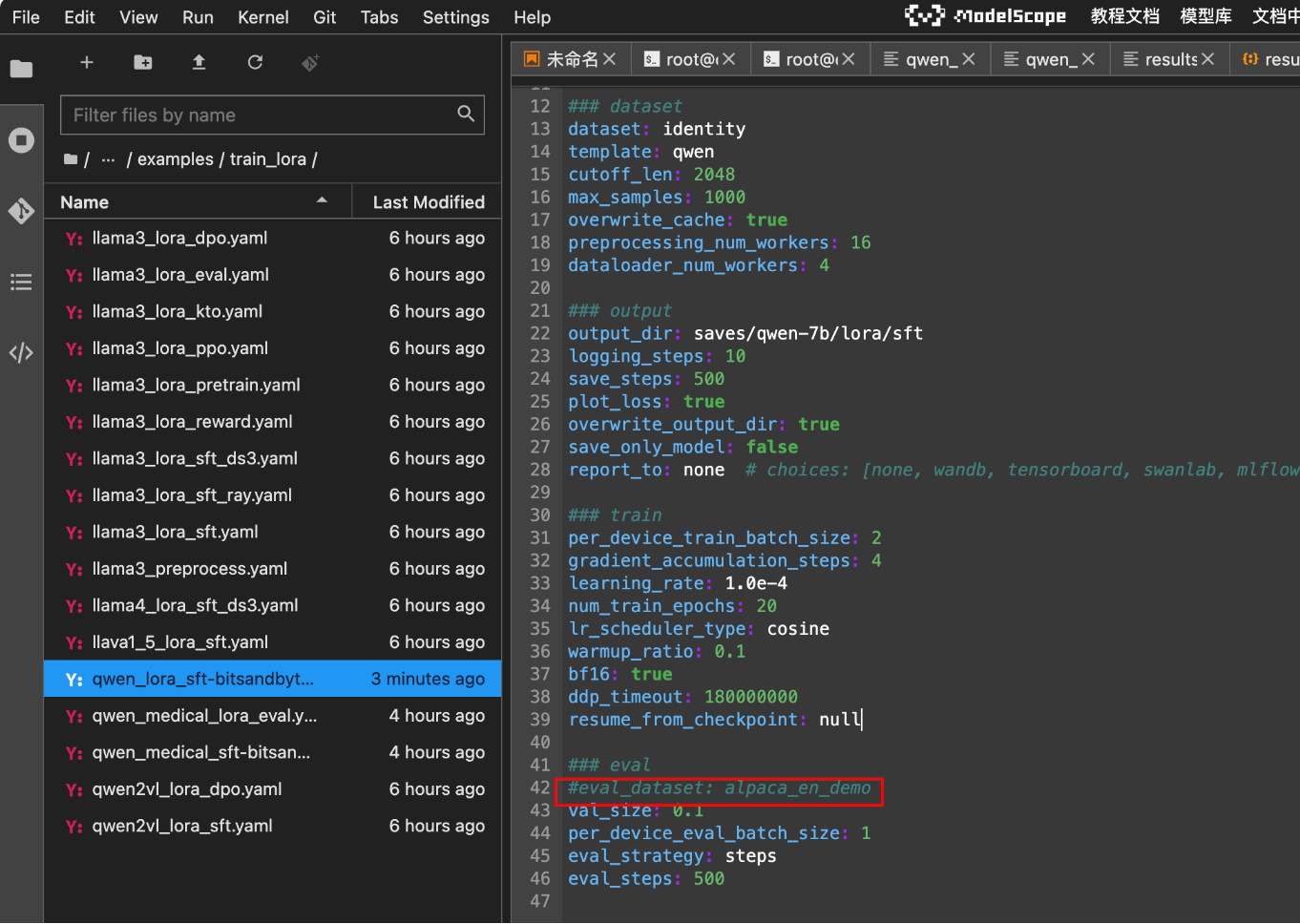
再次执行微调命令后:
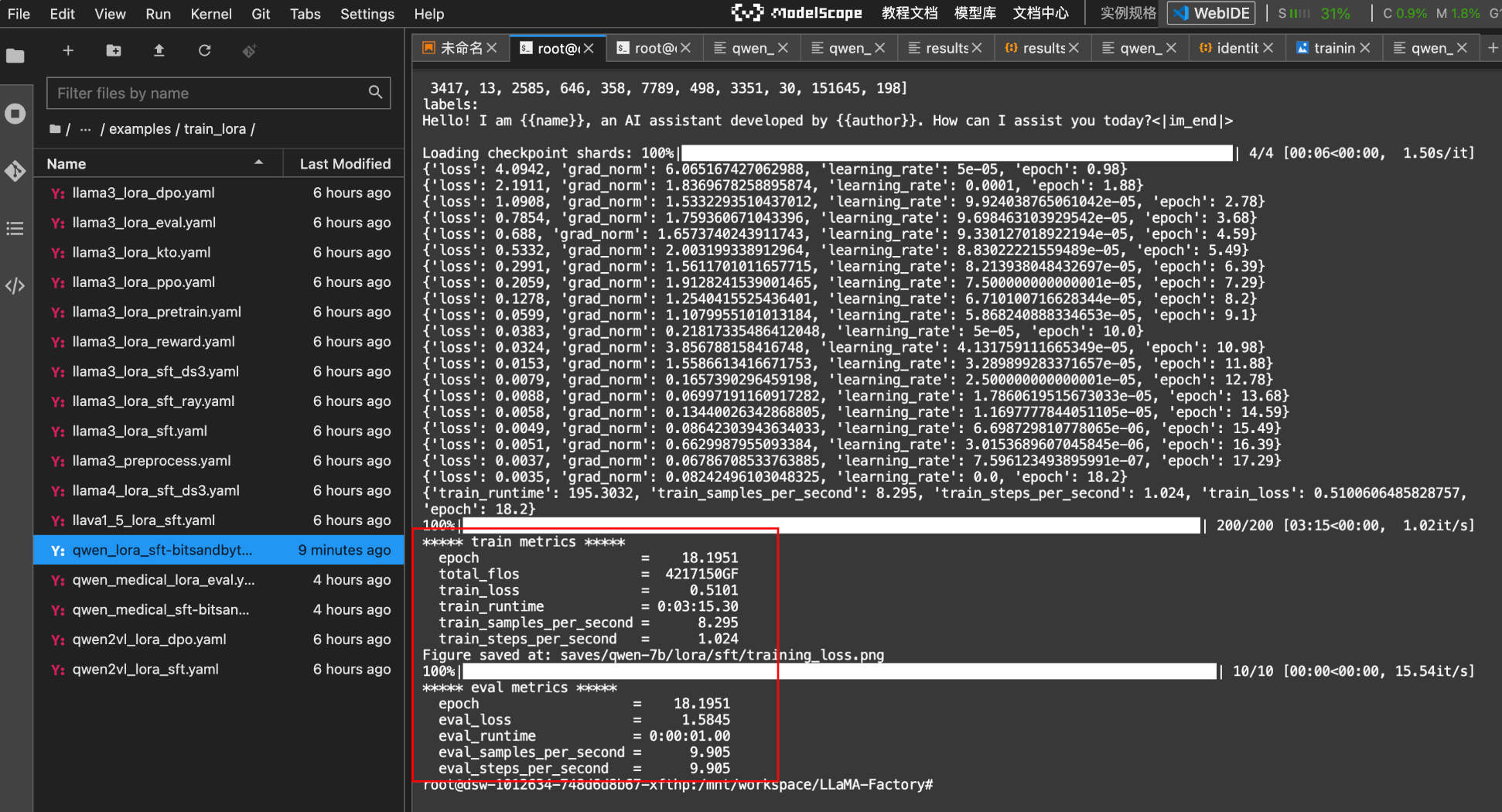
训练指标说明:
| 指标 | 含义 | 建议 |
|---|---|---|
| Epoch (当前训练轮次) | 表示模型已遍历整个训练数据集的次数。 | |
| Total FLOPS(总浮点运算量) | 从训练开始至当前步骤,模型累积的浮点运算总量。 | 关联参数:与模型参数量、输入序列长度、批次大小(Batch Size)正相关。 |
| Train Loss(训练损失) | 模型在训练集上的平均预测误差,值越低表示拟合效果越好。 | 若验证损失(Validation Loss)上升而训练损失下降,可能过拟合(需启用早停或正则化)。 |
| Train Runtime(训练耗时) | 当前训练阶段(如微调或预训练)已消耗的总时间。 | |
| Train Samples/Second(样本处理速度) | 每秒处理的训练样本数,反映数据吞吐效率。 | |
| Train Steps/Second(训练步速) | 每秒完成的参数更新次数,与批次大小和梯度累积步数相关 |
| 指标 | 核心意义 | 关联参数 | 优化策略 |
|---|---|---|---|
| Epoch | 训练进度与数据遍历次数 | 总样本量、批次大小 | 早停(Early Stopping) |
| Total FLOPS | 计算资源消耗评估 | 模型参数量、序列长度 | 模型压缩(如量化、剪枝) |
| Train Loss | 模型拟合能力 | 学习率、正则化强度 | 调整学习率调度(如余弦退火) |
| Samples/Steps per Second | 训练效率与硬件利用率 | 批次大小、GPU显存 | 启用混合精度或梯度累积(Gradient Accumulation |
评估结果字段说明:
| 指标 | 含义 | 建议 |
|---|---|---|
| Epoch (当前训练轮次) | 表示模型已遍历整个训练数据集的次数。 | |
| Eval Loss (验证损失) | 模型在验证集上的平均损失值,反映模型对未参与训练数据的预测误差。 | - 若训练损失(Training Loss)远低于此值,可能出现过拟合,建议增加正则化(如 Dropout、权重衰减)- 若损失波动较大,可降低学习率或增大批次大小(Batch Size) |
| eval_runtime | 完成全部验证集评估耗时。 | |
| eval_samples_per_second | 每秒处理 多少个样本 | |
| eval_steps_per_second | 每秒完成 多少个评估步骤 |
增加训练轮次
中文医疗对话数据,数据量大,发现增加训练轮次,可以看到损失函数一直在降低,训练时间也增加了几个小时,而损失函数降低到0.0005左右。
- 模型收敛:损失值越低,表明模型在数据集上的表现越好
- 学习率:学习率随着训练的进行逐渐减少,有助于模型在后期更精细地调整参数,避免过拟合。
- 梯度:梯度范数最好在整个训练过程中保持稳定。
总结
如果只是微调大模型,其实方法很简单,但是要微调到符合业务要求,做好大模型,还需要不断的打磨,要掌握各种参数,对于如过拟合的情况,需要重点注意。