YuE本地部署完整教程,可用于ai生成音乐,歌曲
YuE 本地部署教程
注意:需要挂梯子
这里用到的python版本是 3.12.7
1.安装Anaconda
官网地址

下载直接安装,这里选择第一个
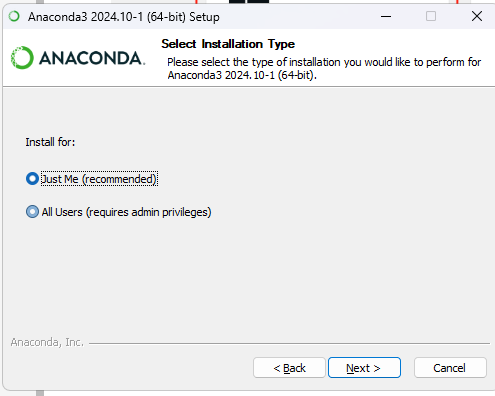
这里打勾1,2,3即可
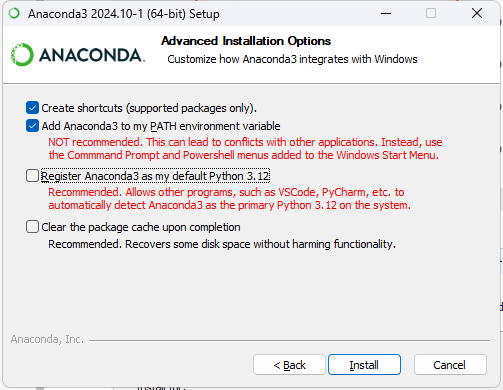
安装完成,执行
conda --version

安装完成
2.YuE-exllamav2本地部署
(1)拉取项目代码
git clone https://github.com/sgsdxzy/YuE-exllamav2
创建虚拟环境
python -m venv myevnv
进入虚拟环境
myevnv\Scripts\activate
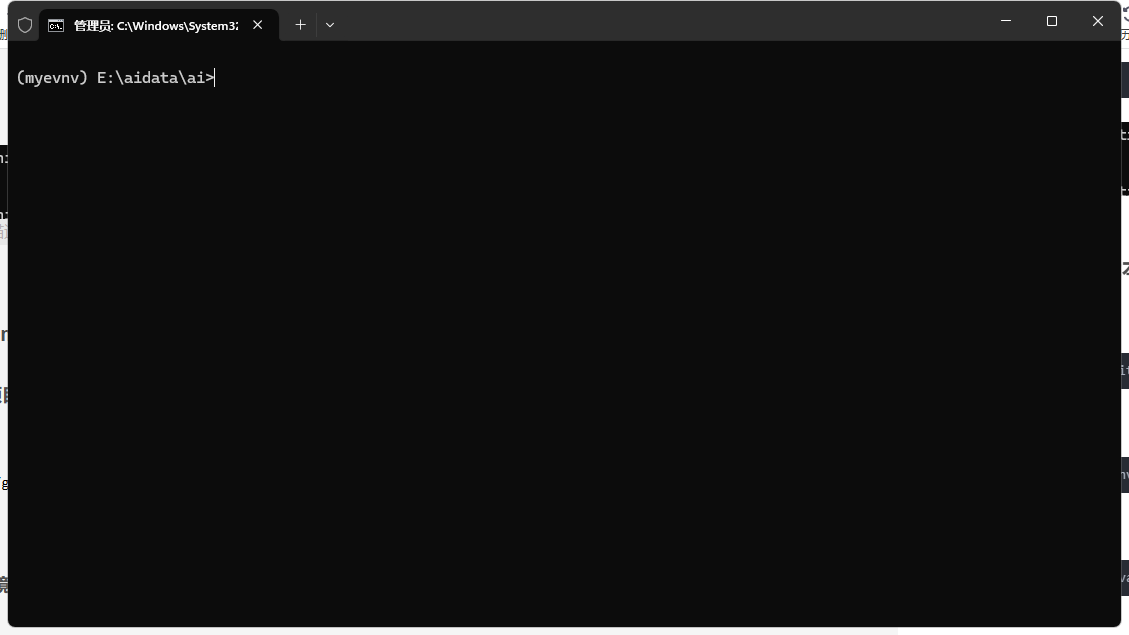
这样说明已经进去了
安装exllamav2,flash-attn依赖
pip install exllamav2
pip install flash-attn
flash-attn 坑解决
安装flash-attn大概率会报错,这边建议手动去安装,如果没报错当我没说
看清楚对应的python版本和torch版本cuda版本
python
import torch # 如果pytorch安装成功即可导入
print(torch.__version__)
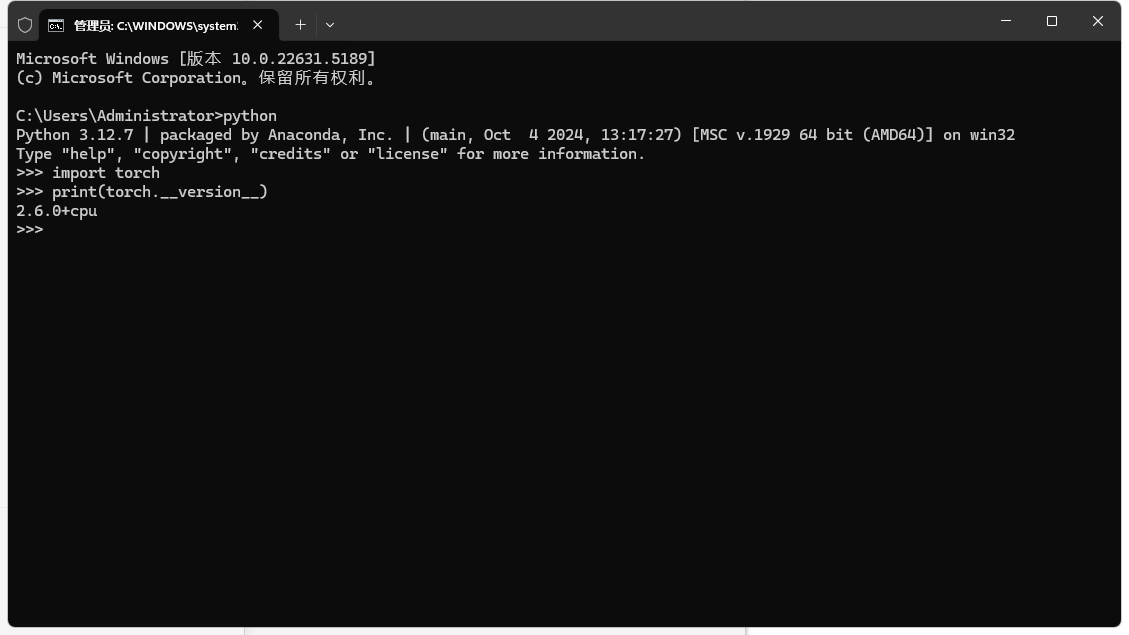
这我这个torch是2.6.0的,
然后查看cuda版本
点击桌面,右键鼠标 选择 NVIDIA 控制面板 打开
点帮助->系统信息->组件
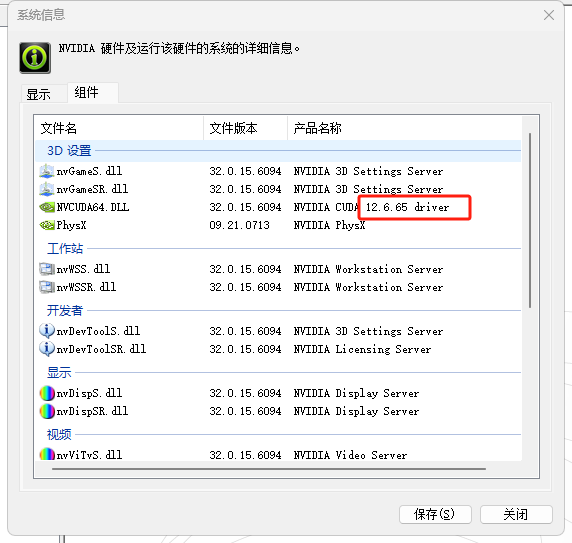
我这里的cuda版本是12.6,但没有12.6,我就选择124
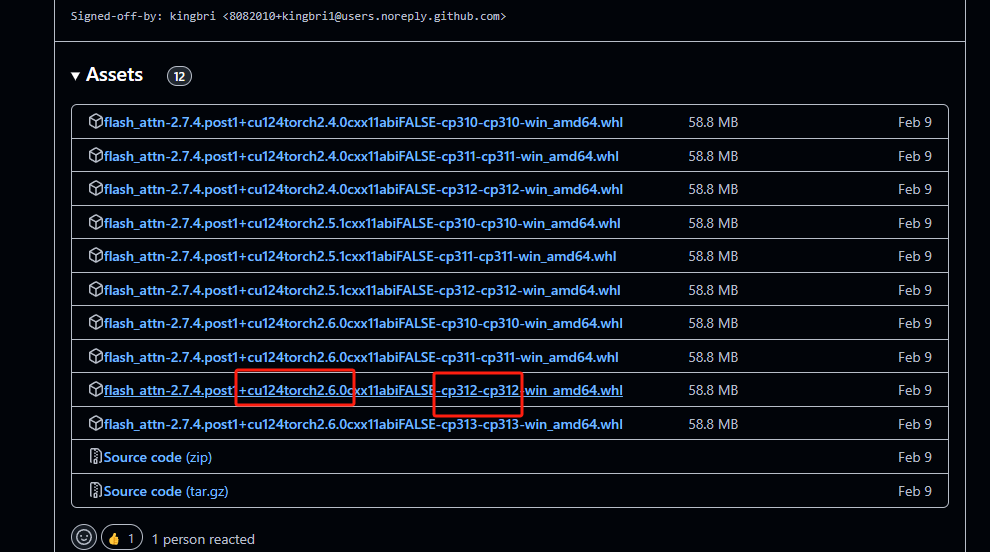
然后复制到当前的目录,然后安装
pip install flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
安装即可
exllamav2 坑解决
安装flash-attn大概率会报错,这边建议手动去安装,如果没报错当我没说
看清楚对应的python版本和torch版本cuda版本
elxllamav2下载地址
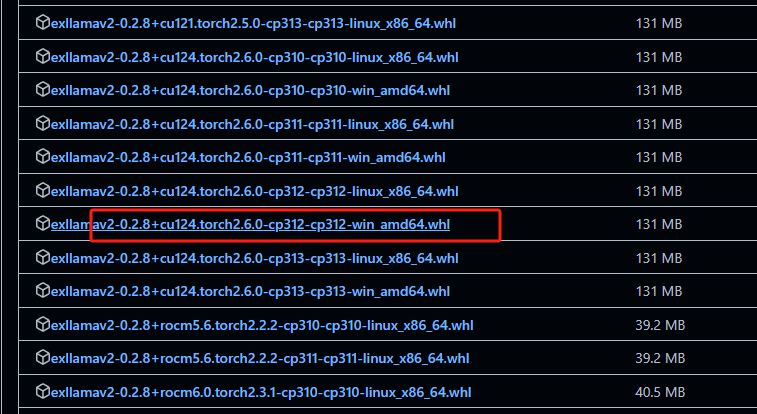
看清楚自己版本,进行下载
然后复制到当前的目录,然后安装
pip install exllamav2-0.2.8+cu124.torch2.6.0-cp312-cp312-win_amd64.whl
安装即可
进入主目录
cd YuE-exllamav2
先打开YuE-exllamav2里面的requirements.txt文件,修改scipy,scipy==1.10.1 改成 scipy>=1.10.1
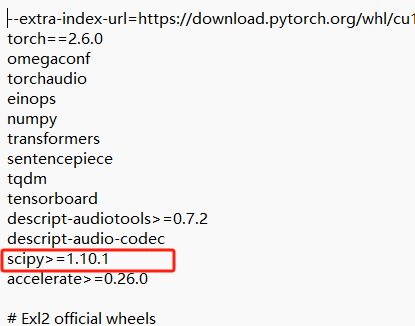
然后保存,安装依赖
pip install -r requirements.txt
安装xcodec_mini_infer
git lfs install
git clone https://huggingface.co/m-a-p/xcodec_mini_infer
这里网络非常容易导致下载不下来,多下几次或者切节点,在或者手动下载
模型下载
然后下载两个模型,如果下载不下来去手动下载
git clone https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2/tree/4.25bpw-h6
或者
git clone -b 4.25bpw-h6 https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2 #我是这样装上的
git clone https://huggingface.co/Doctor-Shotgun/YuE-s2-1B-general-exl2/tree/8.0bpw-h8
或者
git clone -b 8.0bpw-h8 https://huggingface.co/Doctor-Shotgun/YuE-s2-1B-general-exl2 #我是这样装上的
然后就可以跑程序的
这里先确认一下,2个模型和xcodec_mini_infer都是放在YuE-exllamav2主目录上面
这样的话,就可以启动命令了

启动命令,启动命令记得空格不要多敲,记得检查下
python src/yue/infer.py --stage1_model "你当前目录\YuE-s1-7B-anneal-en-cot-exl2" --stage2_model "你当前目录\YuE-s2-1B-general-exl2" --stage1_use_exl2 --stage2_use_exl2 --stage2_cache_size 32768 --genre_txt prompt_egs\genre.txt --lyrics_txt prompt_egs\lyrics.txt
下面是的我的例子
python src/yue/infer.py --stage1_model "E:\aidata\ai\YuE-exllamav2\model\YuE-s1-7B-anneal-en-cot-exl2" --stage2_model "E:\aidata\ai\YuE-exllamav2\model\YuE-s2-1B-general-exl2" --stage1_use_exl2 --stage2_use_exl2 --stage2_cache_size 32768 --genre_txt prompt_egs\genre.txt --lyrics_txt prompt_egs\lyrics.txt
然后就等待就可以生成音乐了,音乐文件放在根目录的output文件夹里面,点进去能看见有一个mp3 文件
注意:模型的文件名字要确保正常,不然找不到模型就直接报错误了我这边就漏写-exl2,反正得确定模型名称,上面两个git命令,拉下来的模型名称有可能不一致,注意路径和名字即可
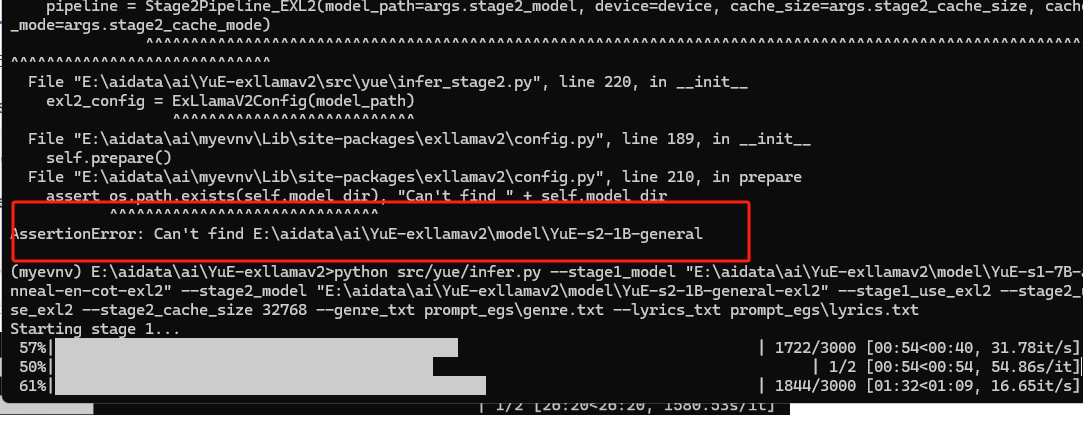
生成完成的图片
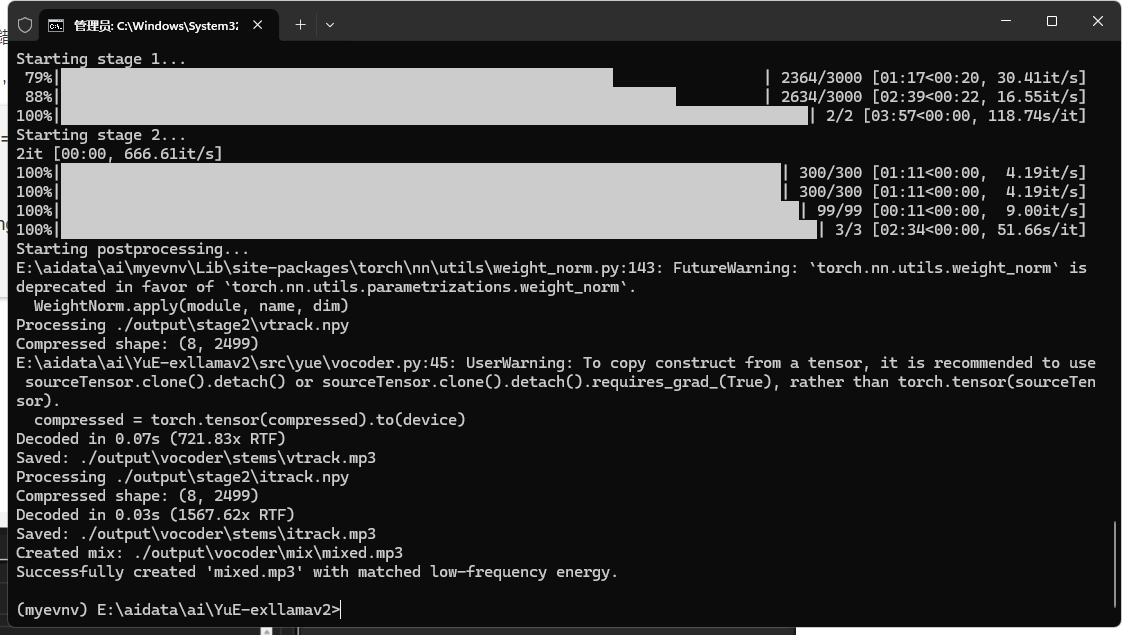
然后这里还有坑,triton报错
出现 No module named ‘triton‘
原因是现Triton不支持Windows,所以找已编译的Windows二进制文件进行安装
triton下载地址
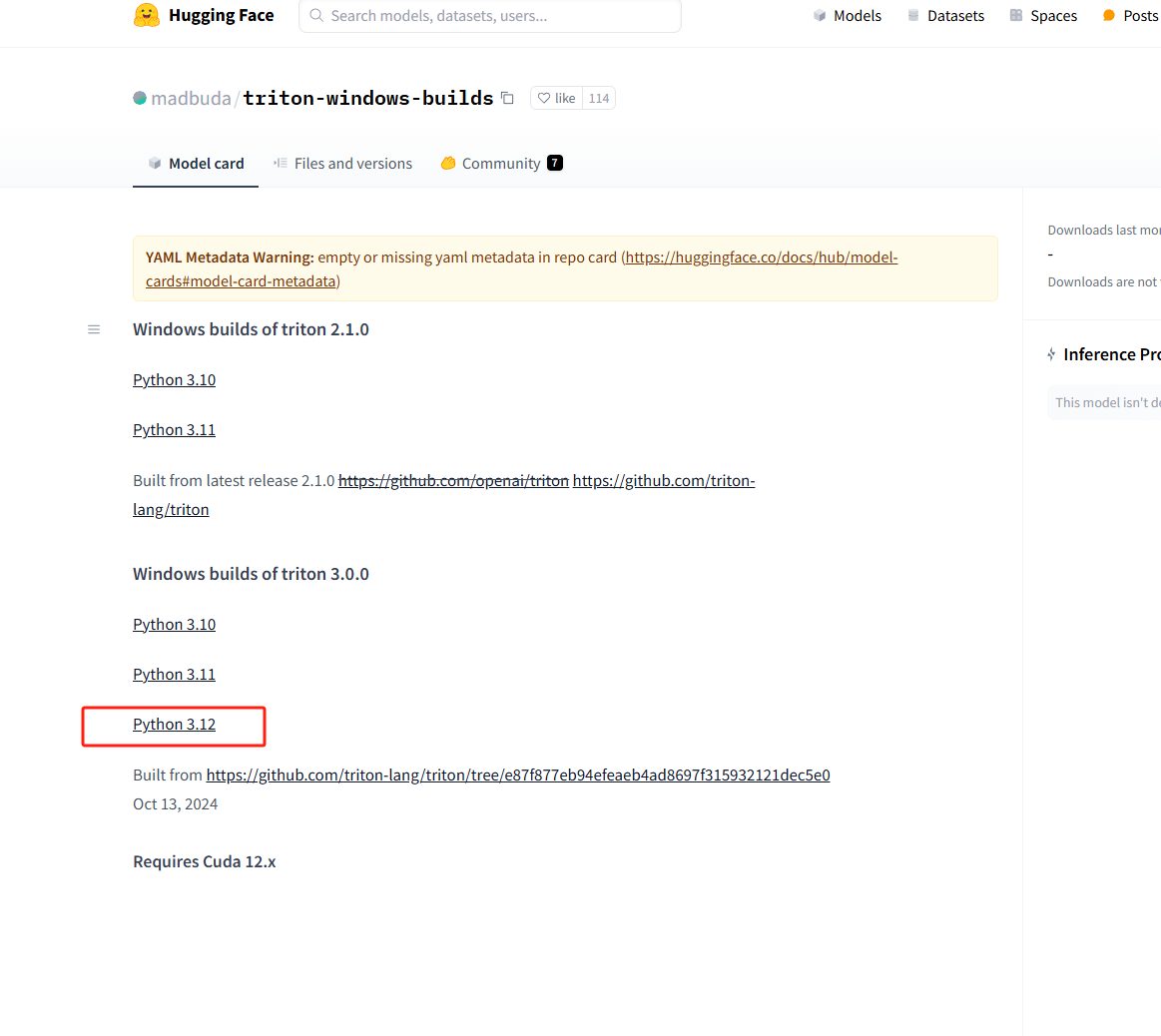
这里自己选一个合适自己的,
等待下载完成
放在根目录上
执行命令
pip install triton-3.0.0-cp312-cp312-win_amd64.whl
安装完成即可
然后重新启动命令,程序即可跑起来
python src/yue/infer.py --stage1_model "你当前目录\YuE-s1-7B-anneal-en-cot-exl2" --stage2_model "你当前目录\YuE-s2-1B-general-exl2" --stage1_use_exl2 --stage2_use_exl2 --stage2_cache_size 32768 --genre_txt prompt_egs\genre.txt --lyrics_txt prompt_egs\lyrics.txt
文件描述
路径 prompt_egs\genre.txt,这个是用于正面描述词,比如轻音乐,摇滚等描述词的输入
路径 prompt_egs\lyrics.txt,这个是用于正输入歌词
路径 output\mixed.mp3,生成出来的mp3文件
中文歌词生成
这里需要更改文件src\yue\infer_stage1.py
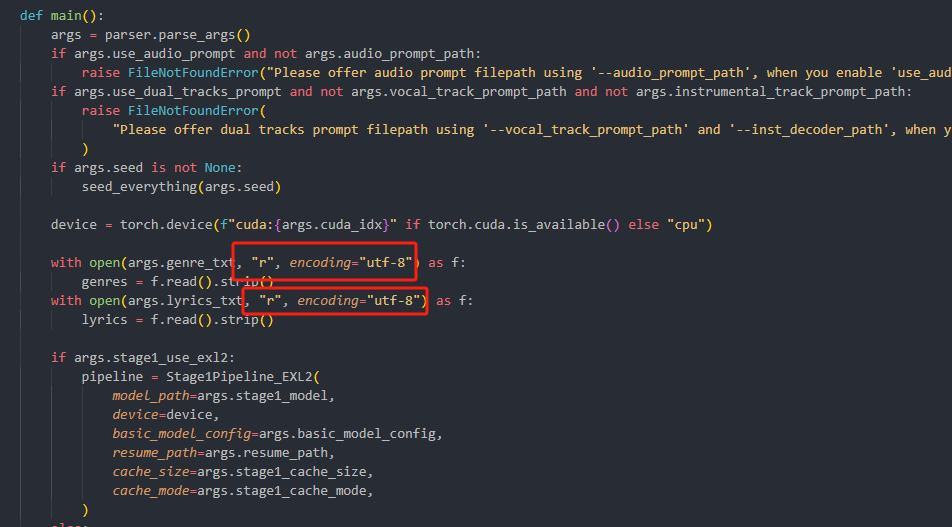
加入[ ,“r”, encoding=“utf-8” ] 即可
with open(args.genre_txt, "r", encoding="utf-8") as f:genres = f.read().strip()
with open(args.lyrics_txt, "r", encoding="utf-8") as f:lyrics = f.read().strip()
总结
使用下来的总结,英文风格感觉还是很可以的,中文的生成效果就一般般了,可能是因为我没有调整中文描述词,总之这个项目也终于跑起来了,刚刚开始跑这个项目的时候,各种依赖版本冲突,各种各样的报错,真给我整麻了,即使使用虚拟环境都感觉行不通,后面一气之下直接把全部的pip的全局依赖全部删除,重新安装,静下心来,分析一个又一个的报错,扔到deepseek,百度去找解决方法,说起来也搞笑关于YuE的文章,全部网加起来都不够四页的文章,跟着他们的教程走,一步一步来,但是最后都是发现跑不起来,哎,特别还有就是这xcodec_mini_infer下载真的吐了,根本就拉不下来,但过了段时间,切了个节点莫名其妙又可以拉了,后续这个功能大概率我也会集成到ollama-chat-ui-vue 这个纯前端vue3的开源项目上面去,下一步的方向应该是往数字人或者定制模型(炼丹)在或者知识库那边研究了,天哪头发又要秃了
相关教程
Stable Diffusion vue本地api接口对接,模型切换, ai功能集成开源项目 ollama-chat-ui-vue
ollama-chat-ui-vue,一个可以用vue对接ollama的开源项目,可接入deepSeek
deepSeek本地部署,详细教程,Ollama安装