【HDFS入门】HDFS性能调优实战:小文件问题优化方案
目录
前言
1 HDFS小文件问题的影响
2 HAR归档方案详解
2.1 HAR工作原理
2.2 实战操作示例
3 SequenceFile合并方案
3.1 SequenceFile结构原理
3.2 合并实现流程
4 方案对比与选型指南
5 进阶优化技巧
5.1 组合使用方案
5.2 自动化管理脚本
5.3 监控指标建议
6 总结
前言
在Hadoop生态系统中,小文件问题(指大量KB/MB级文件)是影响HDFS性能的主要瓶颈之一。本文将深入探讨两种经典的小文件优化方案:HAR归档和SequenceFile合并。
1 HDFS小文件问题的影响
HDFS(Hadoop Distributed File System)小文件问题是指HDFS中存储了大量的小文件(通常指小于HDFS块大小的文件,默认块大小为128MB或256MB),这些小文件会给HDFS集群带来多方面的影响:
存储层面(空间效率):
- 内存黑洞:每文件消耗约150B元数据,1亿文件≈15GB内存
- 空间浪费:1KB文件实际占用128MB块,利用率仅0.0008%
- 示例现象:NameNode内存溢出告警,存储使用量虚高
性能层面(I/O效率):
- 读写放大:
- 读操作:1000文件触发1000次网络I/O
- 写操作:每个文件需单独元数据操作
- 扩展瓶颈:DataNode扩容无法缓解NameNode内存压力
- 典型场景:MapReduce任务因过多小文件导致启动缓慢
管理层面(运维成本):
- 操作原子化:备份/迁移等操作耗时与文件数量正比
- 分析效率差:Spark任务90%时间消耗在文件打开阶段
问题本质:HDFS小文件指远小于块大小(128MB/256MB)的文件,其核心矛盾在于:
- 存储逻辑矛盾:HDFS设计面向大文件,但小文件强制占用完整块空间
- 管理规模矛盾:NameNode内存存储元数据的机制与海量小文件不匹配
2 HAR归档方案详解
2.1 HAR工作原理

- 关键步骤
创建阶段:将多个小文件打包成更大的归档单元存储结构:
- part-*文件:实际数据内容
- index文件:记录内部文件元数据
- masterindex:顶层索引
访问方式:通过har://协议前缀保持原始路径访问
2.2 实战操作示例
<!-- core-site.xml -->
<property><name>har.block.size</name><value>134217728</value> <!-- 128MB块大小 -->
</property>- 参数调优建议
<!-- core-site.xml --> <property> <name>har.block.size</name> <value>134217728</value> <!-- 128MB块大小 --> </property>
- 优缺点对比
| 优点 | 缺点 |
| 减少NameNode内存占用 | 需要额外索引查找 |
| 保持文件目录结构 | 读取性能略有下降 |
| 支持透明访问 | 不可修改已归档文件 |
3 SequenceFile合并方案
3.1 SequenceFile结构原理

特点说明:
- 二进制格式存储键值对
- 支持三种存储格式:
- 未压缩(直接存储)
- 记录级压缩
- 块级压缩(最优)
3.2 合并实现流程

- 代码示例
// 创建SequenceFile.Writer
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, new Path("merged.seq"),Text.class, BytesWritable.class,CompressionType.BLOCK,new DefaultCodec());// 添加小文件
for (FileStatus file : smallFiles) {FSDataInputStream in = fs.open(file.getPath());byte[] content = IOUtils.toByteArray(in);writer.append(new Text(file.getPath().getName()), new BytesWritable(content));
}
writer.close();- 压缩方式选择建议
| 类型 | 压缩比 | 随机访问 | CPU开销 |
| 无压缩 | 1x | 支持 | 低 |
| 记录压缩 | 中等 | 支持 | 中 |
| 块压缩 | 高 | 不支持 | 高 |
4 方案对比与选型指南
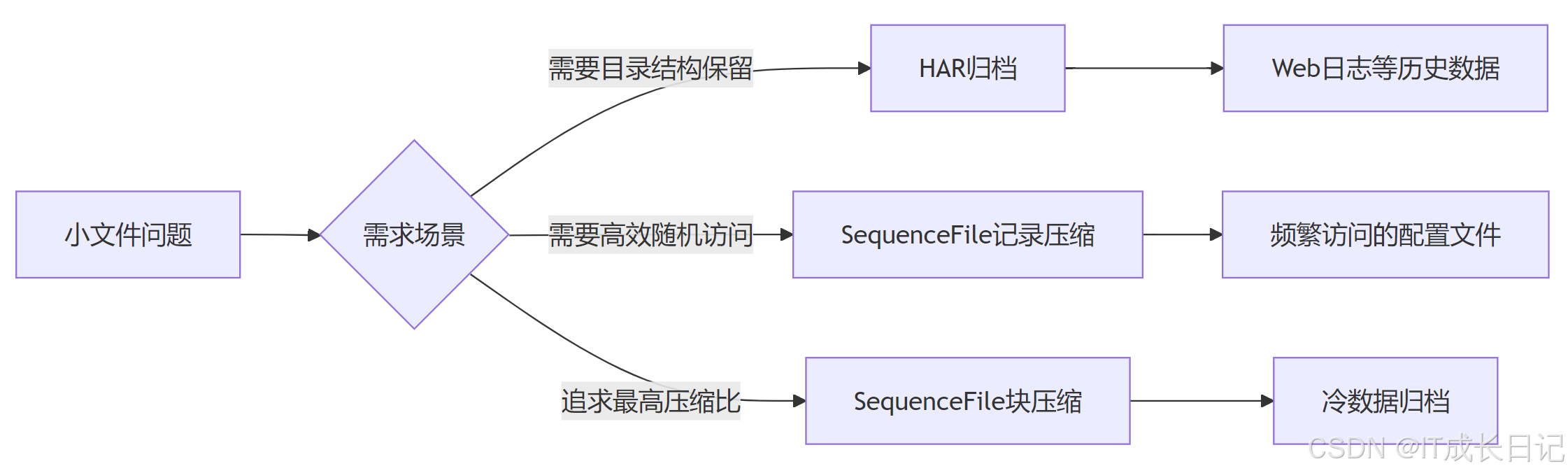
- 性能对比数据
| 方案 | NameNode内存节省 | 读取延迟 | 写入成本 | 适用场景 |
| HAR | 90%+ | 增加20% | 中等 | 历史数据归档 |
| SeqFile(无压缩) | 95%+ | 基本不变 | 低 | 活跃小文件 |
| SeqFile(块压缩) | 95%+ | 增加50% | 高 | 冷数据存储 |
5 进阶优化技巧
5.1 组合使用方案

5.2 自动化管理脚本
#!/bin/bash
# 自动归档7天前的文件脚本# 配置参数
LOG_FILE="/var/log/hdfs_archiver.log"
SOURCE_DIR="/data"
ARCHIVE_DIR="/archive"
RETENTION_DAYS=7
DATE_TAG=$(date +%Y%m%d)
ARCHIVE_NAME="${DATE_TAG}.har"# 创建日志目录(如果不存在)
mkdir -p $(dirname "$LOG_FILE")# 日志记录函数
log() {local level=$1local message=$2echo "[$(date '+%Y-%m-%d %H:%M:%S')] [${level}] ${message}" | tee -a "$LOG_FILE"
}# 检查Hadoop命令可用性
check_hadoop() {if ! command -v hadoop &> /dev/null; thenlog "ERROR" "Hadoop命令未找到,请检查环境变量"exit 1fi
}# 检查目录是否存在
check_directory() {local dir=$1local desc=$2if [ ! -d "$dir" ]; thenlog "ERROR" "${desc}目录不存在: ${dir}"exit 1fi
}# 主执行函数
main() {log "INFO" "===== 开始归档任务 ====="log "INFO" "源目录: ${SOURCE_DIR}"log "INFO" "归档目录: ${ARCHIVE_DIR}"log "INFO" "保留天数: ${RETENTION_DAYS}"# 前置检查check_hadoopcheck_directory "$SOURCE_DIR" "源"check_directory "$ARCHIVE_DIR" "归档"# 查找需要归档的文件log "INFO" "正在查找${RETENTION_DAYS}天前的文件..."file_list=$(find "$SOURCE_DIR" -type f -mtime +${RETENTION_DAYS})file_count=$(echo "$file_list" | wc -l)if [ "$file_count" -eq 0 ]; thenlog "WARNING" "未找到需要归档的文件"exit 0filog "INFO" "找到${file_count}个需要归档的文件"log "DEBUG" "文件列表:\n${file_list}"# 执行归档操作log "INFO" "开始创建归档: ${ARCHIVE_NAME}"if echo "$file_list" | hadoop archive -archiveName "$ARCHIVE_NAME" -p "$SOURCE_DIR" "$ARCHIVE_DIR" 2>&1 | tee -a "$LOG_FILE"; thenlog "INFO" "归档创建成功: ${ARCHIVE_DIR}/${ARCHIVE_NAME}"# 验证归档文件if hadoop fs -test -e "${ARCHIVE_DIR}/${ARCHIVE_NAME}/_SUCCESS"; thenlog "INFO" "归档验证成功"# 可选:删除已归档的源文件# log "INFO" "正在清理源文件..."# echo "$file_list" | xargs rm -f# log "INFO" "已清理${file_count}个源文件"elselog "ERROR" "归档验证失败,_SUCCESS文件不存在"exit 1fielselog "ERROR" "归档创建失败"exit 1filog "INFO" "===== 归档任务完成 ====="
}# 执行主函数
main5.3 监控指标建议
- NameNode堆内存使用率
- 平均文件大小分布
- 归档文件访问命中率
6 总结
两种小文件优化方案各有千秋,实际生产环境中建议:
- 短期方案:对现有系统影响最小的SequenceFile合并
- 长期方案:建立HAR归档的定期工作机制
- 治本方案:在数据采集层避免产生小文件
"选择比努力更重要,在HDFS小文件优化中,选择适合业务特性的方案才能事半功倍。"