内积(Inner Product)
内积(Inner Product)是线性代数中的核心概念,广泛应用于数学、物理和机器学习中。在 PyTorch 等深度学习框架中,内积是张量运算的基础操作之一。以下从定义、计算、几何意义及 PyTorch 实现进行详细解析:
1. 内积的定义
对于两个向量 a 和 b,内积是一个标量值,定义为对应分量乘积之和:
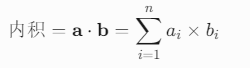
- 维度要求:两个向量必须维度相同。
- 几何意义:反映向量的相似性,与夹角相关
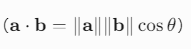
2. PyTorch 中的内积计算
在 PyTorch 中,内积可通过多种方式实现,适用场景不同:
(1) 一维向量内积(点积)
import torcha = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
dot_product = torch.dot(a, b) # 输出: 1 * 4 + 2 * 5 + 3 * 6 = 32(2) 二维矩阵乘法(广义内积)
矩阵乘法可视为行向量与列向量内积的扩展:
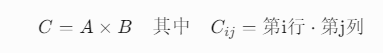
A = torch.tensor([[1, 2], [3, 4]]) # 2x2
B = torch.tensor([[5, 6], [7, 8]]) # 2x2
matmul_result = torch.matmul(A, B) # 或使用 A @ B
# 输出: [[1 * 5+2 * 7, 1 * 6+2 * 8], [3 * 5+4 * 7, 3 * 6+4 * 8]] = [[19, 22], [43, 50]](3) 高维张量内积
对更高维张量,使用 torch.tensordot 指定收缩的维度:
x = torch.randn(3, 4)
y = torch.randn(4, 5)
result = torch.tensordot(x, y, dims=([1], [0])) # 收缩第1维和第0维,输出形状 (3,5)3. 内积的几何意义
- 投影:内积 a⋅b 表示 a 在 b 方向上的投影长度乘以 ∥b∥。
- 相似性度量:内积越大,向量方向越接近(夹角越小);内积为0时,向量正交。
4. 内积在机器学习中的应用
(1) 线性回归
线性模型的预测值可表示为权重向量 w 与输入特征 x 的内积:
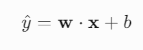
(2) 支持向量机 (SVM)
核函数(如多项式核、RBF核)通过隐式计算高维空间中的内积,实现非线性分类:
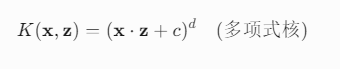
(3) 注意力机制
Transformer 中的自注意力通过查询(Query)和键(Key)的内积计算注意力权重:
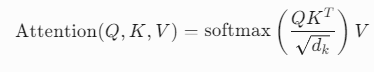
5. 常见误区与注意事项
-
维度不匹配:
torch.dot仅支持一维向量,对二维张量会报错。- 矩阵乘法要求第一个矩阵的列数等于第二个矩阵的行数。
-
广播规则:
PyTorch 的@或torch.matmul支持广播(Broadcasting),但需确保非收缩维度兼容:a = torch.randn(3, 4, 5) b = torch.randn(5, 6) result = a @ b # 输出形状: (3, 4, 6) -
性能优化:
- 使用 GPU 加速大规模矩阵乘法(
tensor.to('cuda'))。 - 避免在循环中逐元素计算,尽量向量化操作。
- 使用 GPU 加速大规模矩阵乘法(
代码示例:内积与梯度计算
# 内积的自动微分示例
x = torch.tensor([2.0, 3.0], requires_grad=True)
y = torch.tensor([4.0, 5.0])
loss = torch.dot(x, y) # 计算内积 2 * 4 + 3 * 5 = 23
loss.backward() # 反向传播计算梯度
print(x.grad) # 梯度为 y 的值: tensor([4., 5.])总结
内积是连接线性代数与机器学习的桥梁,在 PyTorch 中通过 torch.dot、torch.matmul 等函数高效实现。理解其数学本质和框架中的操作规则,有助于设计更高效的模型(如注意力机制)和避免维度错误。实际应用中需注意:
- 明确需求:区分向量点积、矩阵乘法和张量收缩。
- 利用硬件加速:通过 GPU 并行化大规模运算。
- 结合自动微分:内积作为计算图的一部分支持梯度传播。