02、Yarn的安装理念及如何破解依赖管理困境
Facebook、Google、Exponent和Tilde
构建的新的JavaScript包管理器
yarn.lock中子依赖的版本号不是固定版本
synp工具,将yarn.lock转换为package-lock.json
通过 yarn cache dir 命令查看缓存目录及内容
yarn所独有的命令:
yarn import
yarn licenses
yarn pack
yarn why
yarn autoclean
npm所独有的命令:
npm rebuild
yarn安装机制和背后思想

-
checking
检测项目中是否存在一些npm相关文件
检查系统OS、CPU等信息 -
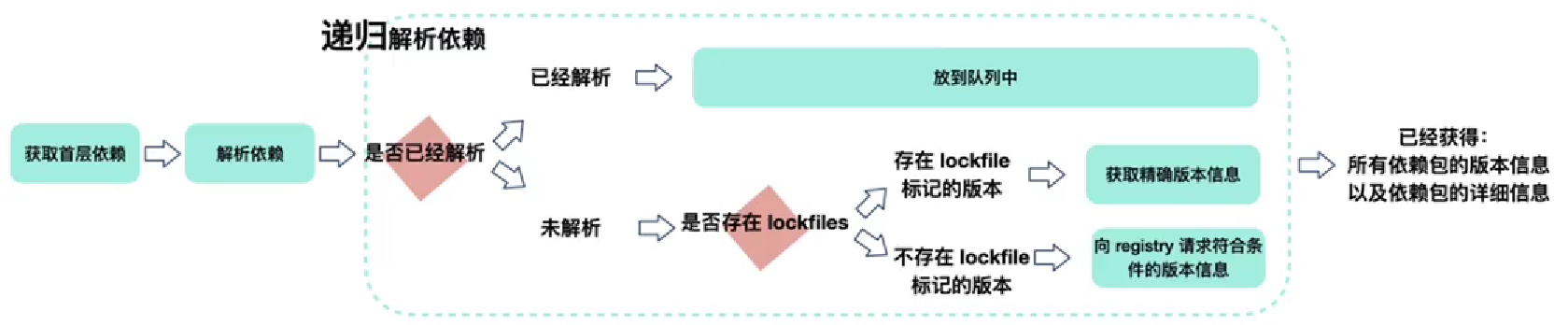
Resolving Packages
- 获取当前项目中package.json定义
- 采用遍历首层依赖的方式获取依赖包的版本信息
- 对于没有解析过的包A,首次尝试从yarn.lock中获取到版本信息,并标记为已解析
- 如果在yarn.lock中没有找到包A,则向Register发起请求获取满足版本范围的已知最高版本的包信息,获取后将当前包标记为已解析。
-
fetching Packages
- 检查缓存中是否存在当前依赖包,将缓存中不存在的依赖包下载到缓存目录
- 如何判断缓存中是否存在当前的依赖包?
- yarn根据cacheFolder+slug+node_modules+pkg.nam生成一个path,判断系统中是否存在该path,如果存在证明已经有缓存,不用重新下载

-
linking Packages
- 将项目中的依赖复制到项目node_modules下,遵循扁平化原则

- 将项目中的依赖复制到项目node_modules下,遵循扁平化原则
-
构建包(Building Packages)
- 依赖包中存在二进制包的进行编译
破解依赖管理困境
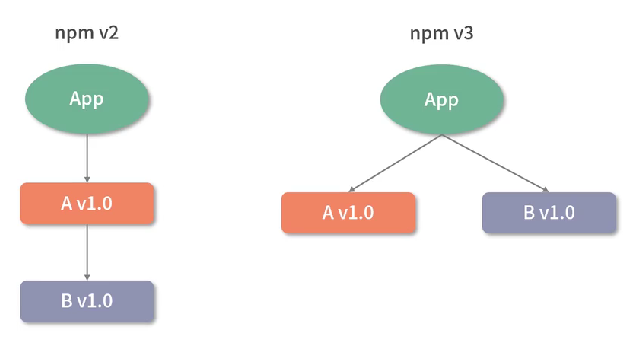
- 在安装依赖时将依赖放到项目的node_modules文件中
- 如果某个直接依赖A还依赖其他模块B,作为间接依赖模块B将会被下载到A的node_modules文件夹中,依此递归执行
那么如何理解“嵌套地狱”呢?
- 项目依赖树的层级非常深,不利于调试和排查问题
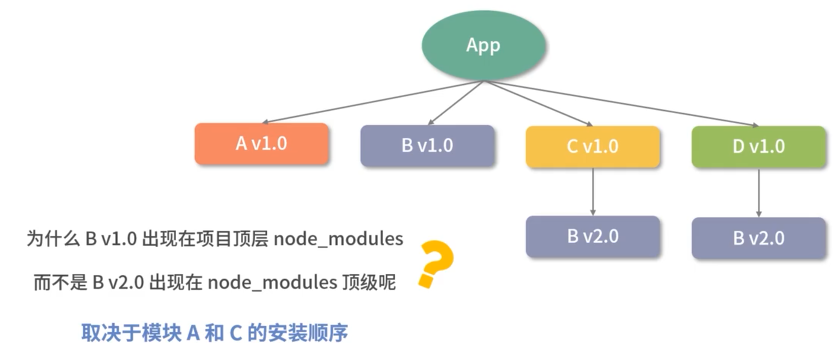
- 依赖树的不同分支里,可能存在同样版本的相同依赖
安装结果浪费了较大的空间资源,使得安装过程过慢
- 因为目录层级太深导致文件路径太长,导致删除node_modules文件夹出现失败情况