理解Java一些基础(八股)
什么是Java
Java 是一门面向对象的编程语言,由 Sun 公司的詹姆斯·高斯林团队于 1995 年推出。吸收了 C++ 语言中大量的优点,但又抛弃了 C++ 中容易出错的地方,如垃圾回收、指针。
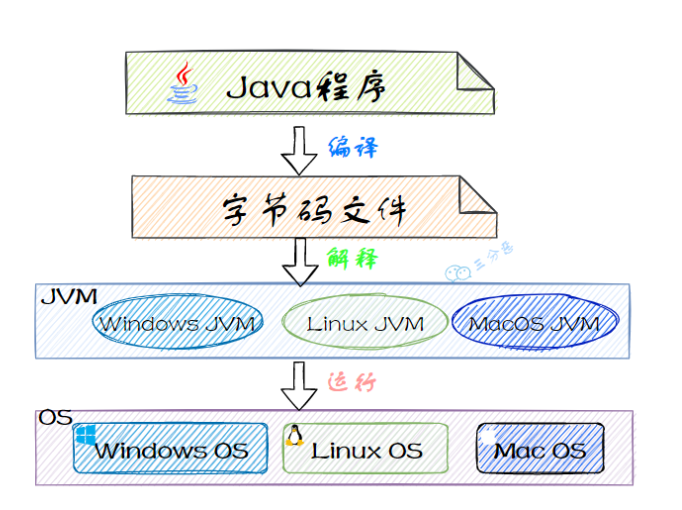
同时,Java 又是一门平台无关的编程语言,即一次编译,处处运行。
只需要在对应的平台上安装 JDK,就可以实现跨平台,在 Windows、macOS、Linux 操作系统上运行。
有什么特点
Java 语言的特点有:
①、面向对象,主要是封装,继承,多态,抽象。
②、平台无关性,“一次编写,到处运行”,因此采用 Java 语言编写的程序具有很好的可移植性。
③、支持多线程。C++ 语言没有内置的多线程机制,因此必须调用操作系统的 API 来完成多线程程序设计,而 Java 却提供了封装好 多线程支持;
④、支持 JIT 编译,也就是即时编译器,它可以在程序运行时将字节码转换为热点机器码来提高程序的运行速度。
JDK,JRE,JVM区别
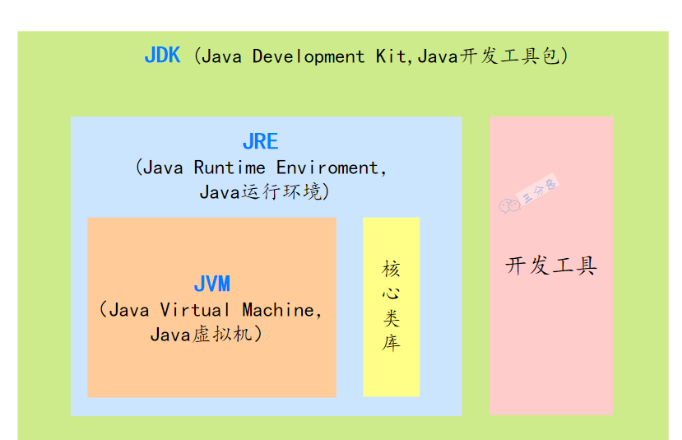
JVM:也就是 Java 虚拟机,是 Java 实现跨平台的关键所在,不同的操作系统有不同的 JVM 实现。JVM 负责将 Java 字节码转换为特定平台的机器码,并执行。(跨平台原理)
JRE:也就是 Java 运行时环境,包含了运行 Java 程序所必需的库,以及 JVM。
JDK:一套完整的 Java SDK,包括 JRE,编译器 javac、Java 文档生成工具 javadoc、Java 字节码工具 javap 等。为开发者提供了开发、编译、调试 Java 程序的一整套环境。
JVM 就像发动机,JRE 是带了发动机的汽车,JDK 是一整套能造汽车的工具厂。
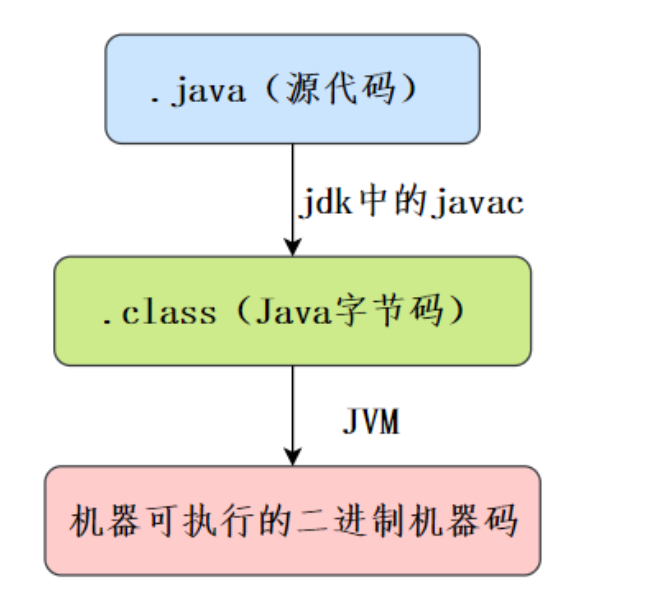
字节码是什么,有什么好处
所谓的字节码,就是 Java 程序经过编译后产生的 .class 文件。
Java 程序从源代码到运行需要经过三步:
- 编译:将源代码文件 .java 编译成 JVM 可以识别的字节码文件 .class
- 解释:JVM 执行字节码文件,将字节码翻译成操作系统能识别的机器码
- 执行:操作系统执行二进制的机器码
Java为什么被称为“编译与解释并存”的语言
编译型语言是指编译器针对特定的操作系统,将源代码一次性翻译成可被该平台执行的机器码。
解释型语言是指解释器对源代码进行逐行解释,解释成特定平台的机器码并执行。
举个例子,我想读一本国外的小说,我有两种选择:
- 找个翻译,等翻译将小说全部都翻译成汉语,一次性读完。
- 找个翻译,翻译一段我读一段,慢慢把书读完。
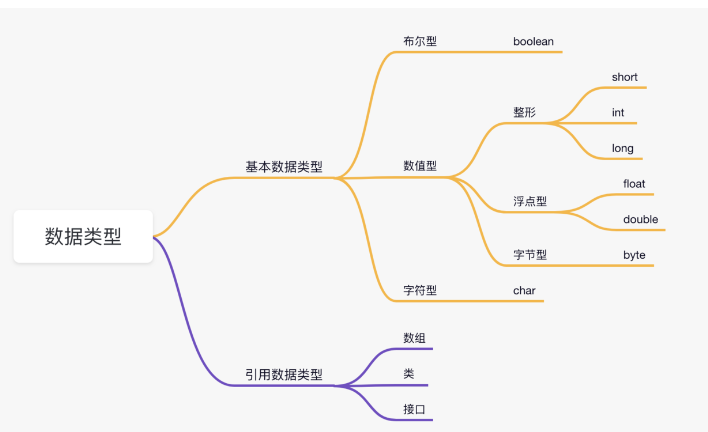
Java的数据类型
Java 的数据类型可以分为两种:基本数据类型和引用数据类型。
| 数据类型 | 默认值 | 大小 |
|---|---|---|
| boolean | false | 1 字节或 4 字节 |
| char | ‘\u0000’ | 2 字节 |
| byte | 0 | 1 字节 |
| short | 0 | 2 字节 |
| int | 0 | 4 字节 |
| long | 0L | 8 字节 |
| float | 0.0f | 4 字节 |
| double | 0.0 | 8 字节 |
boolean为什么1或者4字节
Java 虚拟机规范中,并没有明确规定 boolean 类型的大小,只规定了 boolean 类型的取值 true 或 false。
我本机的 64 位 JDK 中,通过 JOL 工具查看单独的 boolean 类型,以及 boolean 数组,所占用的空间都是 1 个字节。
给Integer.MAX_VALUE 加 1会发生什么
当给 Integer.MAX_VALUE 加 1 时,会发生溢出,变成 Integer.MIN_VALUE。
这是因为 Java 的整数类型采用的是二进制补码表示法,溢出时值会变成最小值。
- Integer.MAX_VALUE 的二进制表示是 01111111 11111111 11111111 11111111(32 位)。
- 加 1 后结果变成 10000000 00000000 00000000 00000000,即 -2147483648(Integer.MIN_VALUE)。
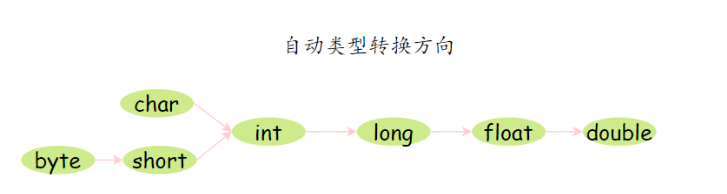
自动类型转换,强制类型转换
当把一个范围较小的数值或变量赋给另外一个范围较大的变量时,会进行自动类型转换;反之,需要强制转换。
①、float f=3.4,对吗?
不正确。Java 里面默认写的 带小数的 是 double 类型,也就是双精度浮点数。3.4 默认是双精度,将双精度赋值给浮点型属于下转型(down-casting,也称窄化)会造成精度丢失,因此需要强制类型转换float f =(float)3.4;或者写成float f =3.4F
一个是七位有效数字,一个是十六位,转换会被截断,会造成精度丢失
②、short s1 = 1; s1 = s1 + 1;对吗?short s1 = 1; s1 += 1;对吗?
short s1 = 1; s1 = s1 + 1; 会编译出错,由于 1 是 int 类型,因此 s1+1 运算结果也是 int 型,需要强制转换类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1); 其中有隐含的强制类型转换。
自动拆箱/装箱
- 装箱:将基本数据类型转换为包装类型,例如 int 转换为 Integer。
- 拆箱:将包装类型转换为基本数据类型。
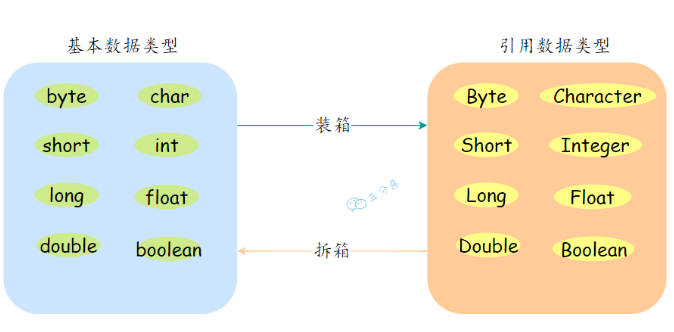
举例
Integer i = 10; //装箱
int n = i; //拆箱
&和&&,|和||
& 是 逻辑与。
&&是短路与运算。逻辑与跟短路与的差别是非常大的,虽然二者都要求运算符左右两端的布尔值都是 true,整个表达式的值才是 true。
&&之所以称为短路运算是因为,如果&&左边的表达式的值是 false,右边的表达式会直接短路掉,不会进行运算。
例如在验证用户登录时判定用户名不是 null 而且不是空字符串,应当写为username != null && !username.equals(""),二者的顺序不能交换,更不能用 & 运算符,因为第一个条件如果不成立,根本不能进行字符串的 equals 比较,会抛出 NullPointerException 异常。
注意:逻辑或运算符(|)和短路或运算符(||)的差别也是类似。
switch 语句能否用在byte/long/String
Java 5 以前 switch(expr) 中,expr 只能是 byte、short、char、int。
从 Java 5 开始,Java 中引入了枚举类型, expr 也可以是 enum 类型。
从 Java 7 开始,expr 还可以是字符串,但是长整型在目前所有的版本中都是不可以的。
| Java 版本 | 支持的类型 |
|---|---|
| Java 1.0+ | byte、short、char、int |
| Java 5+ | enum(枚举类型) |
| Java 7+ | String |
| Java 7+ | 以及上面基本类型的包装类(如 Integer、Character) |
| 🚫 不支持 | long、float、double、对象引用(除 String) |
| 类型 | 比较方式 |
|---|---|
int、byte、short、char、enum | 使用 ==(值比较) |
String(Java 7+) | 编译时转成 if ("xxx".equals(expr)) |
包装类(如 Integer) | 会自动拆箱,再用 == 比较数值 |
自增与自减
在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1,Java 提供了一种特殊的运算符,用于这种表达式,叫做自增运算符(++)和自减运算符(–)。
++和–运算符可以放在变量之前,也可以放在变量之后。
当运算符放在变量之前时(前缀),先自增/减,再赋值;当运算符放在变量之后时(后缀),先赋值,再自增/减。
例如,当 b = ++a 时,先自增(自己增加 1),再赋值(赋值给 b);当 b = a++ 时,先赋值(赋值给 b),再自增(自己增加 1)。也就是,++a 输出的是 a+1 的值,a++输出的是 a 值。
用一句口诀就是:“符号在前就先加/减,符号在后就后加/减”。
例子
int i = 1;
i = i++;
System.out.println(i); // 1
JVM是这样处理的
i = i++;
// 等价于下面这个“伪代码”:
int temp = i; // 把 i 当前的值存一份(temp = 1)
i = i + 1; // 自增操作:i = 2
i = temp; // 把最初的值(1)赋回给 i
类似的
int i = 1;
int j = i++; // j = 1, i = 2
看这个例子
int count = 0;
for(int i = 0;i < 100;i++)
{count = count++;
}
System.out.println("count = "+count); // 0
而++i
i = ++i;
// 等价于
i = i + 1; // 先加一,i 从 1 → 2
i = i; // 把新值赋给自己(其实没变)
float是怎么表示小数的
float类型的小数在计算机中是通过 IEEE 754 标准的单精度浮点数格式来表示的。
𝑉 = ( − 1 ) 𝑆 × 𝑀 × 2 𝐸 𝑉=(−1)𝑆×𝑀×2𝐸 V=(−1)S×M×2E
- S:符号位,0 代表正数,1 代表负数;
- M:尾数部分,用于表示数值的精度;比如说 1.25∗22;1.25 就是尾数;
- R:基数,十进制中的基数是 10,二进制中的基数是 2;
- E:指数部分,例如 10−1 中的 -1 就是指数。

这种表示方法可以将非常大或非常小的数值用有限的位数表示出来,但这也意味着可能会有精度上的损失。
按照这个规则,将十进制数 25.125 转换为浮点数,转换过程是这样的:
- 整数部分:25 转换为二进制是 11001;
- 小数部分:0.125 转换为二进制是 0.001;
- 用二进制科学计数法表示:25.125 = 1.001001×2^4
符号位 S 是 0,表示正数;指数部分 E 是 4,转换为二进制是 100;尾数部分 M 是 1.001001。
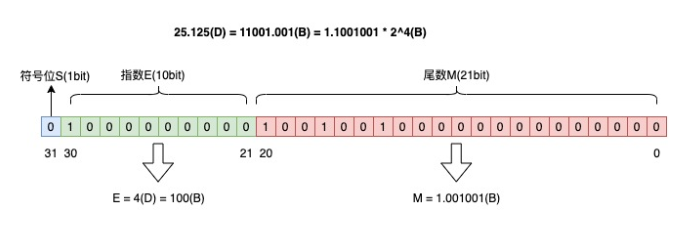
单精度浮点数占用 4 字节(32 位),这 32 位被分为三个部分:符号位、指数部分和尾数部分。
像我们熟悉的 0.1、0.2 在十进制很好表示
但在 二进制 中,它们是无限循环小数,就像十进制的 1/3 = 0.333…
计算机只能截断或近似存储,就产生了误差
对于需要高精度计算的场景(如金融计算),可能需要考虑使用BigDecimal类来避免这种误差。
数据准确性保证
在金融计算中,保证数据准确性有两种方案,一种使用 BigDecimal,一种将浮点数转换为整数 int 进行计算。
肯定不能使用 float 和 double 类型,它们无法避免浮点数运算中常见的精度问题,因为这些数据类型采用二进制浮点数来表示,无法准确地表示,例如 0.1。
BigDecimal num1 = new BigDecimal("0.1");
BigDecimal num2 = new BigDecimal("0.2");
BigDecimal sum = num1.add(num2);
System.out.println("Sum of 0.1 and 0.2 using BigDecimal: " + sum); // 输出 0.3,精确计算
在处理小额支付或计算时,通过转换为较小的货币单位(如分),这样不仅提高了运算速度,还保证了计算的准确性。
int priceInCents = 199; // 商品价格199分
int quantity = 3;
int totalInCents = priceInCents * quantity; // 计算总价
System.out.println("Total price in cents: " + totalInCents); // 输出597分