BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
背景
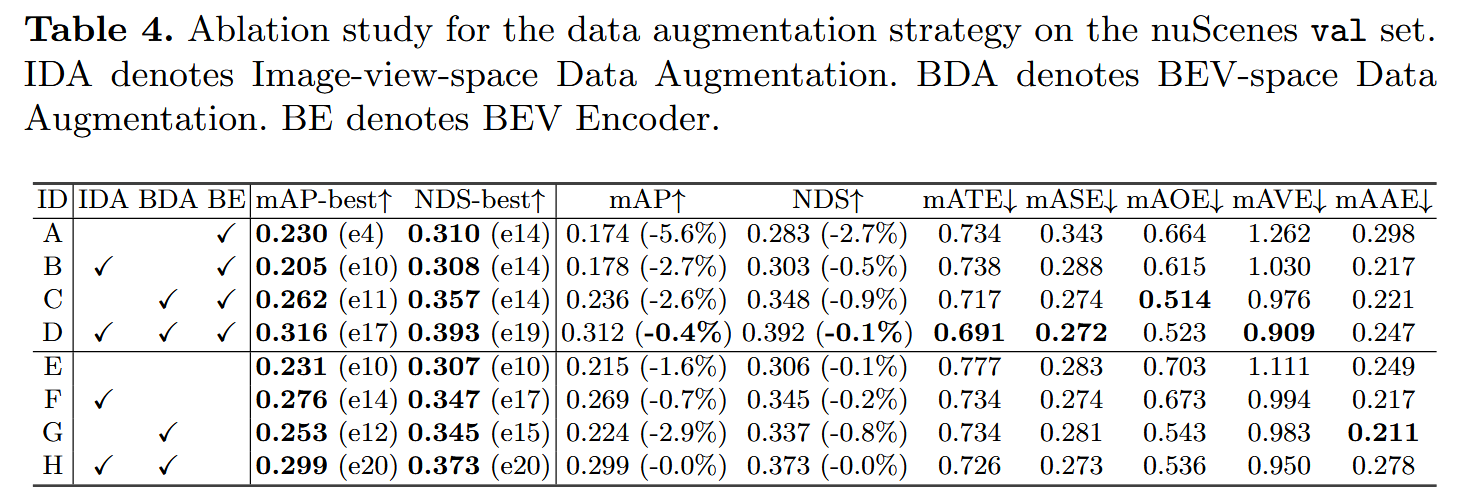
在自动驾驶场景下,以往工作是目标检测任务用图像视角做,语义分割用BEV视角做。本文提出了BEVDet,实现了一个统一的框架,它模块化设计分为图像编码器,视角转换器,BEV编码器以及BEV空间的3D检测头。然而框架定下来不代表性能好了,BEVDet在BEV空间上过拟合了,这需要在图像空间增加数据增强,但只有在没有BEV Encoder时才会有正效果。此外,由于图像空间到BEV空间是像素级联系的,图像空间的数据增强并不会对BEV编码器与检测头有正则化效果。所以这里我们在BEV空间进行数据增强来增加鲁棒性。
主要贡献
- BEV空间与图像空间都用了数据增强方法,并且解耦合
- 提出了BEV编码器,并且沿用LSS的深度估计方法,将图像转到BEV空间进行目标检测。
- 提出了NMS的改进版本,Scale-NMS对不同类别的物体不同放缩处理。
- 训练沿用了CBGS,方便训练样本均衡。
方法
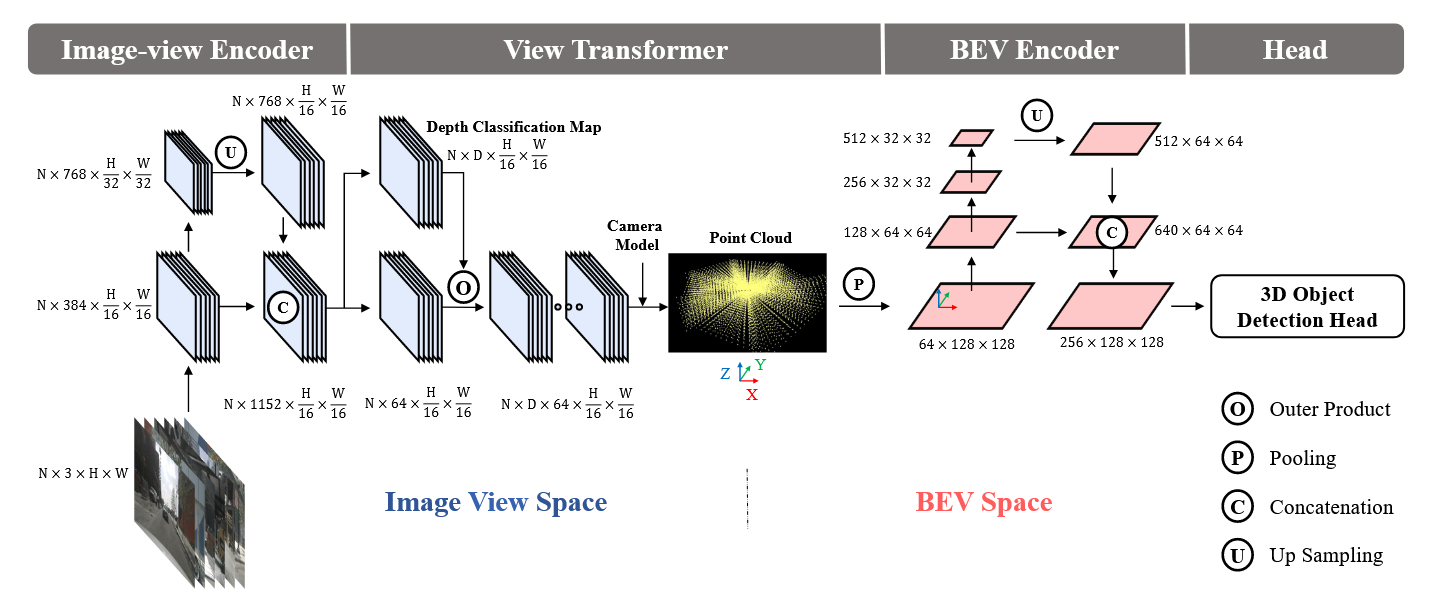
图像编码器
这部分BackBone使用ResNet或SwinTransformer处理,neck部分使用FPN或者FPN-LSS,FPN-LSS就是将1/32分辨率的上采样到1/16与原Backbone提取的特征拼接即可。
视角变换器
这里首先使用LSS的方法预测深度,使用softmax得到每个深度的概率值,得到深度分类图与特征图进行外积相乘得到每个深度下的特征图,形状为ND64H/16W/16,这也就类似于伪点云特征了,将他们转到BEV坐标系上,并在高度维度上使用最大池化或平均池化。
BEV编码器与检测头
与图像编码器类似,最后得到统一的BEV特征图输出即可,但这里的BEV特征图能学到更关键的信息如尺度、速度等等。3D检测头直接使用的CenterPoint的第一阶段检测头。
数据增强策略
由于我们对于图像使用数据增强,这会导致得到的BEV特征图描述信息与真实的3D检测框不一致。对于图像上的点 p i m a g e p_{image} pimage=[ x i , y i , 1 x_i,y_i,1 xi,yi,1],深度为d,它对应的3D空间坐标是
P camera = I − 1 ( P image × d ) P_{\text{camera}} = \mathbf{I}^{-1}(P_{\text{image}} \times d) Pcamera=I−1(Pimage×d)
I代表相机内参,若我们对于图像进行数据增强如旋转平移等等,即用一个变换矩阵A操作, p i m a g e , = A p i m a g e p_{image}^,=Ap_{image} pimage,=Apimage。而为了不影响后面的操作,只需要对上式修改为如下所示即可,这样就能对图像数据进行增强,从而解耦合。
P camera ′ = I − 1 ( A − 1 p image ′ × d ) = P camera P_{\text{camera}}' = \mathbf{I}^{-1} (\mathbf{A}^{-1} p_{\text{image}}' \times d) = P_{\text{camera}} Pcamera′=I−1(A−1pimage′×d)=Pcamera
对于BEV视图特征以及目标检测框做相同的数据增强,可以防止BEV特征学习过拟合,这是基于我们的视角变换能够解耦合图像编码器与后面模块的前提下的。
Scale NMS
传统的NMS在BEV中不适用,BEV空间下,不同类别物体占据的空间大小不同并且实例间的重叠应该接近0,对于小物体,由于其占用空间小,所以很可能生成多个假阳锚框,无法用NMS排除掉,这里使用Scale NMS,根据不同的类别,进行不同尺度的放缩,再使用传统NMS处理。
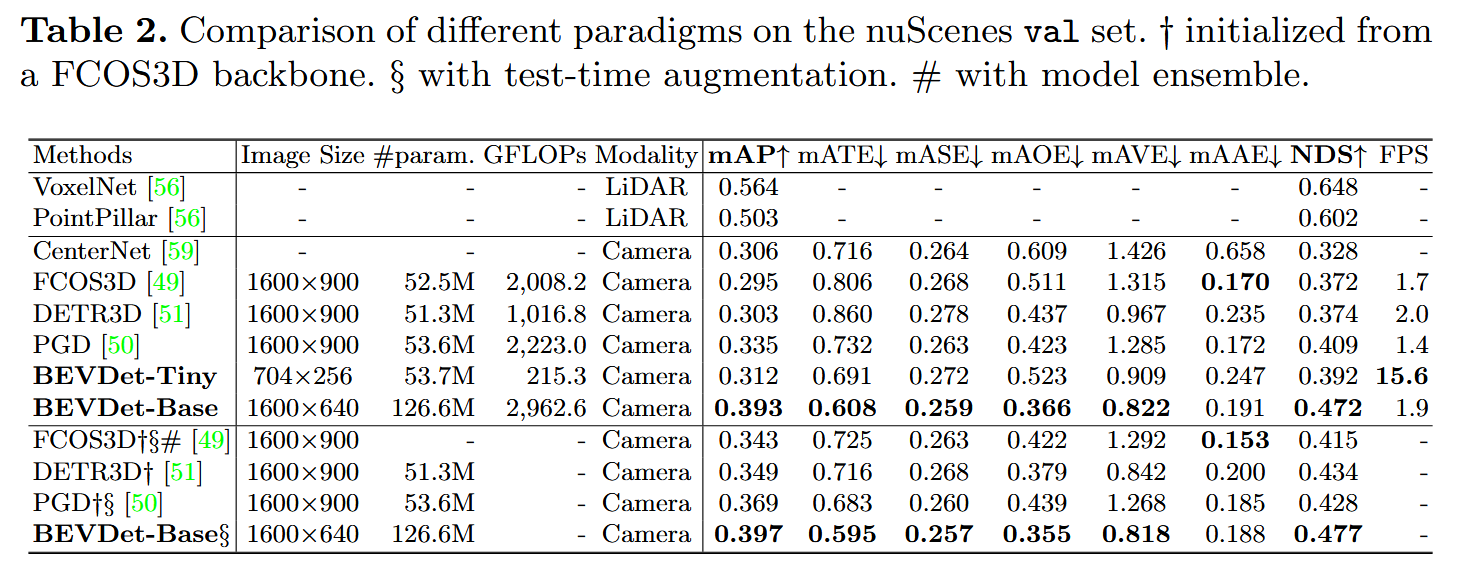
实验
在nuscenes数据集处理,nuscenes数据集有1000个场景,700个训练,验证与测试各150个。感兴趣的区域大小设置为51.2米,分辨率设置为0.8米。对于指标使用了mAP,Average Translation Error (ATE), Average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE), Average Attribute Error (AAE)与NDS等等。
训练时使用AdamW优化器,并使用了梯度裁剪,学习率设为2e-4,在8张3090上训练,batch设为64。对于图像编码器使用ResNet时,则使用步进学习策略,在17和20两个epoch将学习率*0.1。而对于SwinTransformer则是使用循环策略,在前40%调度让其学习率从2e-4线性增加到1e-3,在剩下来的调度线性降低到0即可。总调度为20epoch。
数据处理部分,对于输入的图像使用随机放缩、随机翻转与随机旋转,最后裁剪成[ W i n , H i n W_{in},H_{in} Win,Hin]大小的图片。BEV空间也是使用随机翻转旋转放缩。
模型使用CBGS训练,CBGS解决类别不均衡 的问题,比如在自动驾驶数据中,小车特别多,行人和骑行者很少,模型训练时容易偏向检测小车,导致少数类 recall 低。具体步骤是,每个训练样本中含有哪些类别,就归入对应类别的组;有 Car 就进 Car 组;有 Pedestrian 就进 Pedestrian 组(也可能同时属于多个组);每次训练时,先从每个类别组中分别采样一定数量的 sample;把这些 sample 混合起来,组成一个 batch;这样,每个 batch 中各类别样本数量就更均衡,避免模型学不到小众类。