【WTYOLO】使用GPU训练YOLO模型教程记录
本文主要记录笔者亲自测试的使用GPU进行YOLO模型训练的过程,包括安装CUDA,cuDNN,pytorch的笔记记录。
一、检查硬件要求
1.1 确认电脑中有Nvidia显卡
因为使用GPU进行Yolo模型训练需要英伟达的GPU支持。
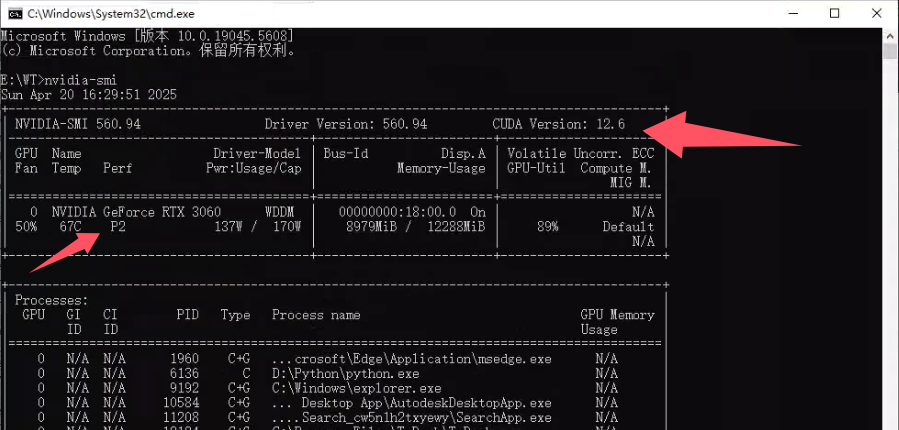
方法一:打开终端,输入命令行回车:
nvidia-smi如果电脑中有Nvidia显卡,会打印出相关信息,显示支持的CUDA版本和显卡型号,如果不是,则一般无法识读该命令,打印信息如下:
方法二:通过系统设置查看
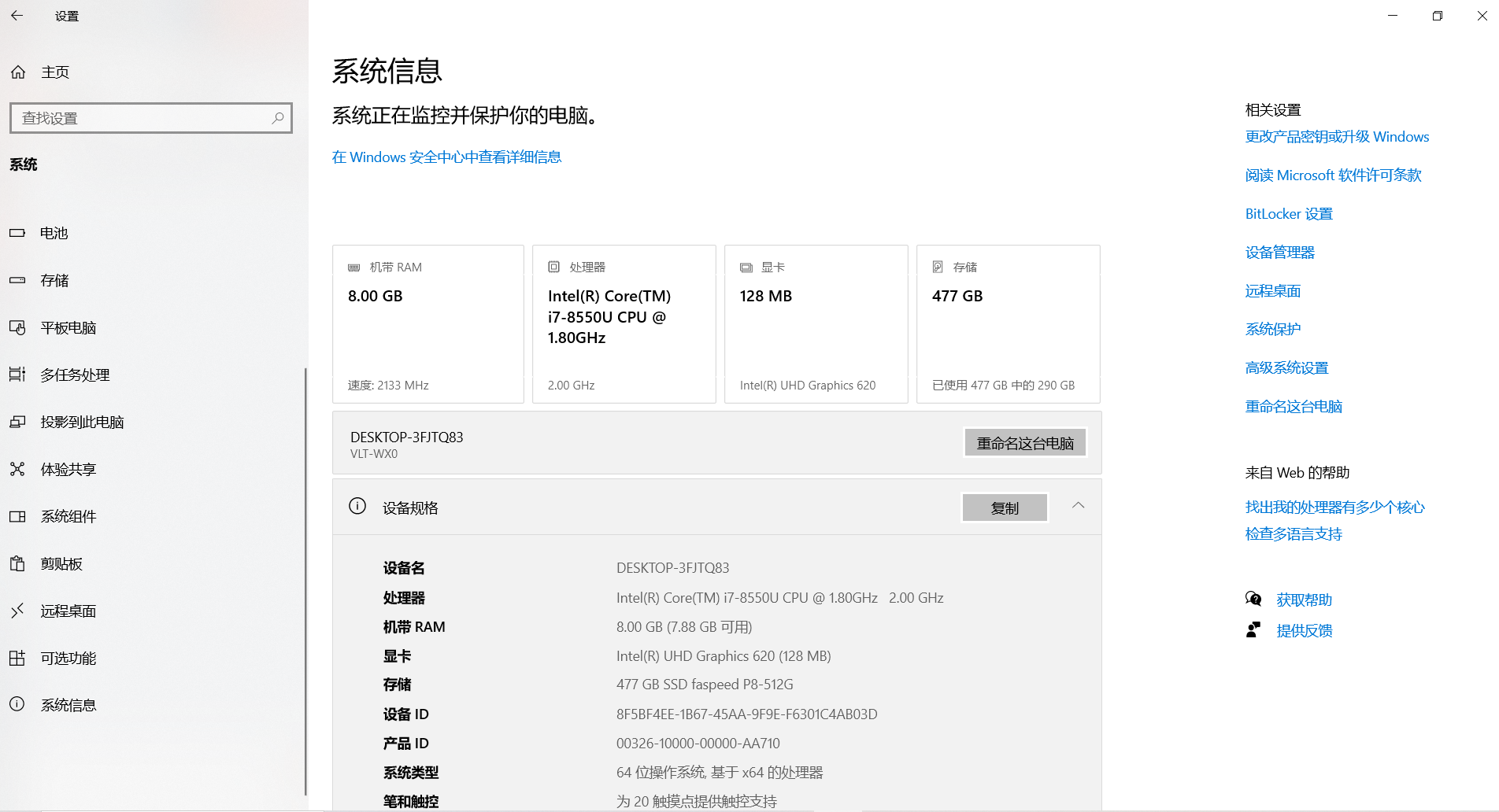
以笔者个人用Win10家庭版为例,具体为点击【设置】-【系统】-【系统信息】 ,便可以查看电脑的CPU,显卡等信息,如下:
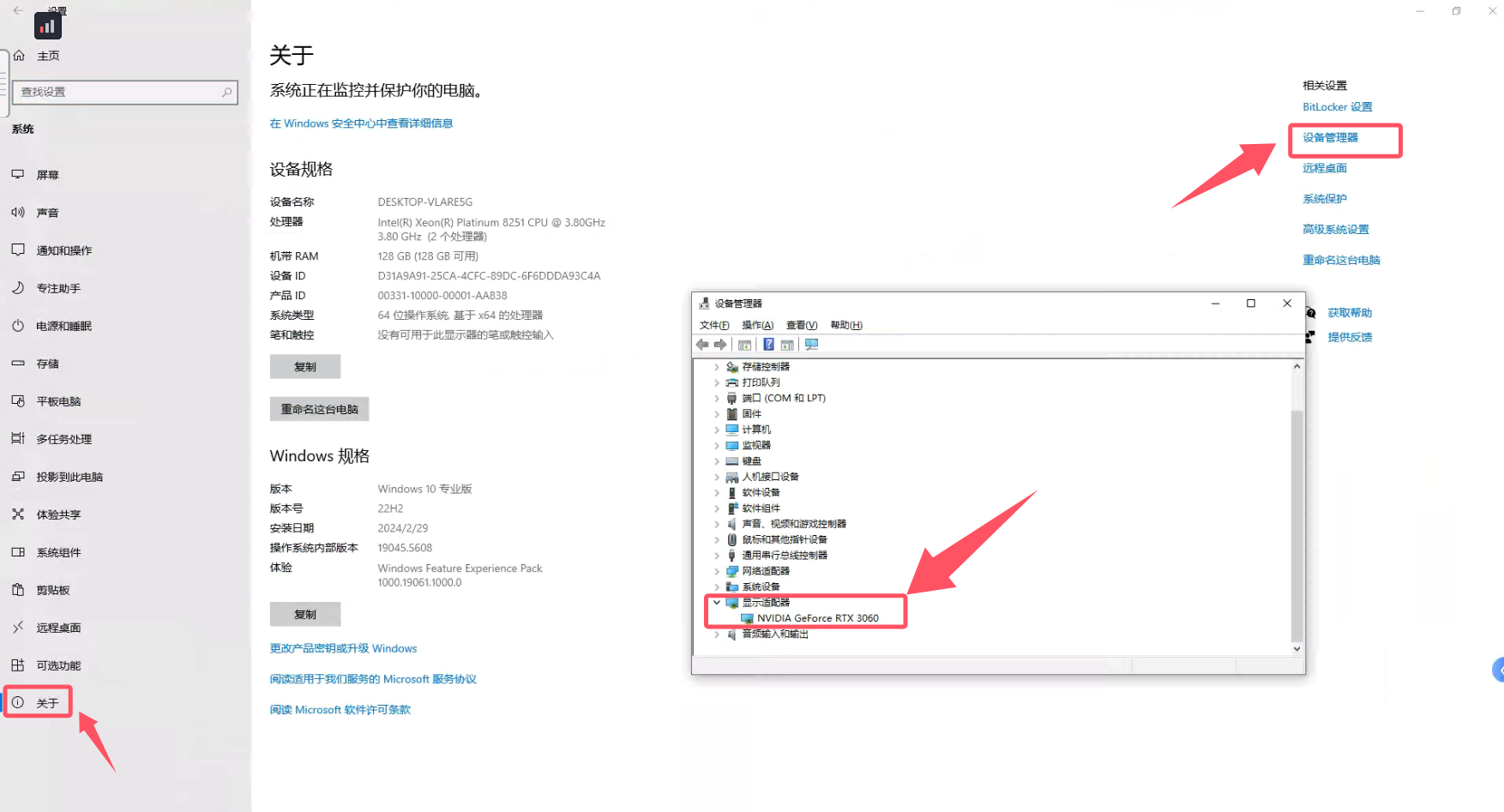
方法三:通用方法或专业版
对于一些电脑 安装了Win10专业版的,可以点击【设置】-【系统】-【关于(查看CPU信息)】-【设备管理器】-【显示适配器】查看,该方法也是Windows通用。
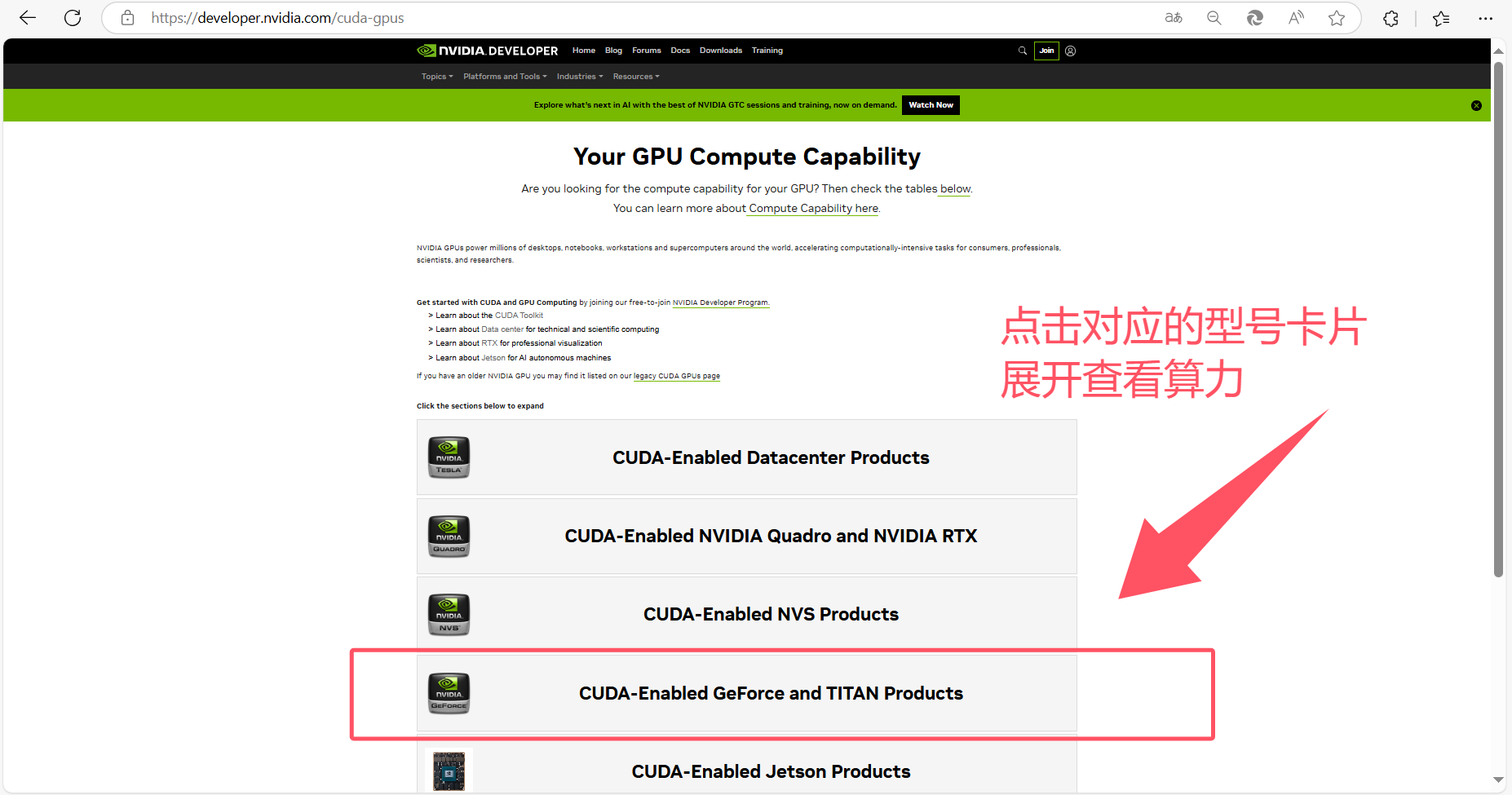
1.2 查询显卡算力情况,以确保其满足PyTorch的最低算力要求
访问NVIDIA官网【计算能力】栏目或直接点击:CUDA GPUs - Compute Capability | NVIDIA Developer,下拉找到对应的GPU型号卡片,点击展开后可以看到该型号下各种GPU的算力情况。根据GPU算力看能不能跑起来Pytorch,Pytorch的最低算力要求表如下:
| PyTorch版本 | 最低算力要求 |
|---|---|
| 1.3及以下 | 3.0 |
| 1.4到1.6 | 3.5 |
| 1.7到1.8 | 3.7 |
| 1.9到1.10 | 5.2 |
| 1.11及以上 | 6.0 |

如果到了这一步都满足,那恭喜你,可以使用GPU来训练你的YOLO模型啦!
二、软件配置
如果第一步检查硬件要求通过,那么接下来就进行具体的软件配置了。
2.1 安装CUDA
检查显卡支持的CUDA版本并进行安装,安装后可通过命令验证。
2.1.1 更新显卡驱动
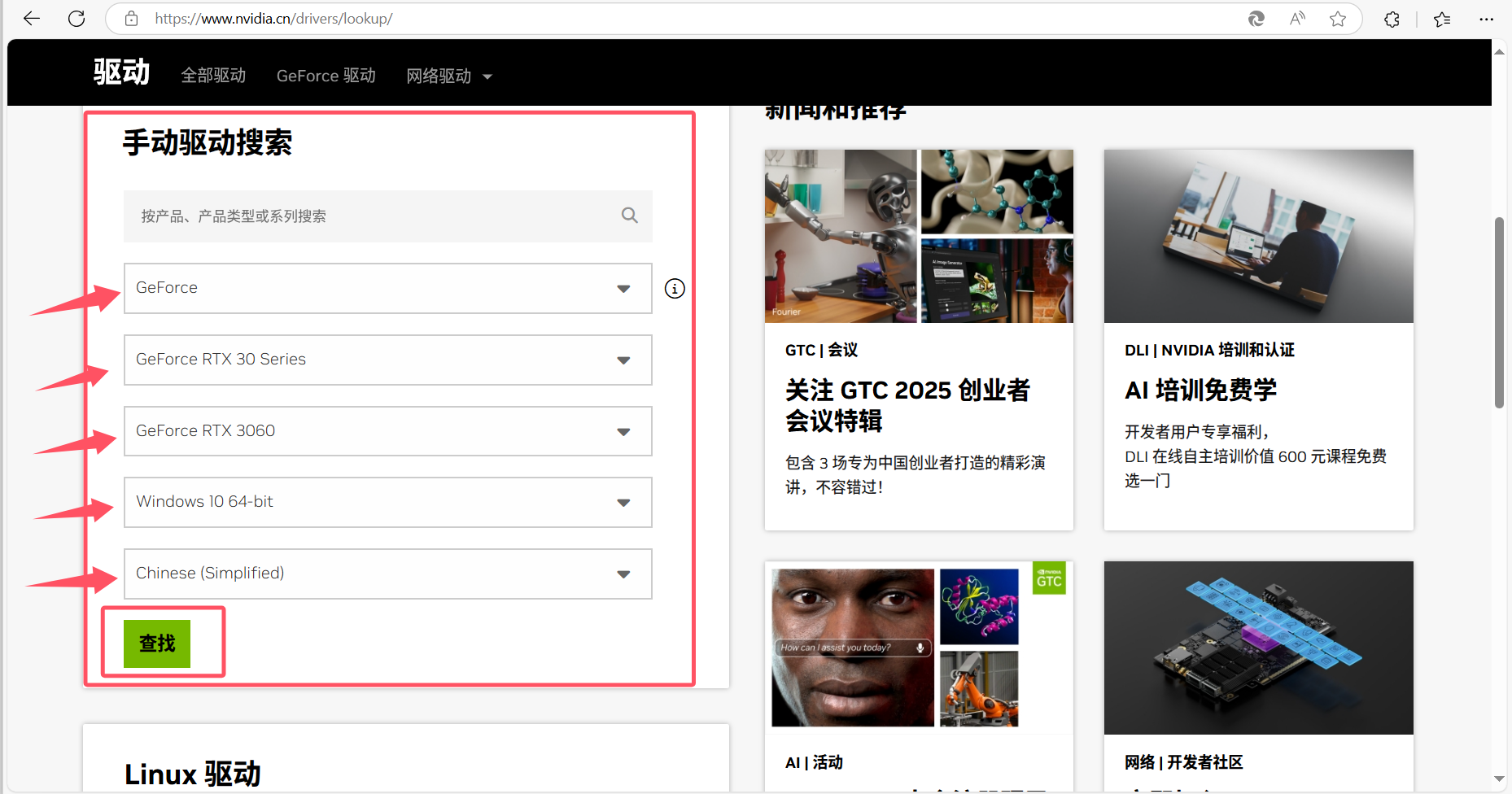
访问:下载 NVIDIA 官方驱动 | NVIDIA ,下载对应显卡驱动程序进行更新,如果已经是最新版驱动,请忽略该步骤。
2.1.2安装CUDA
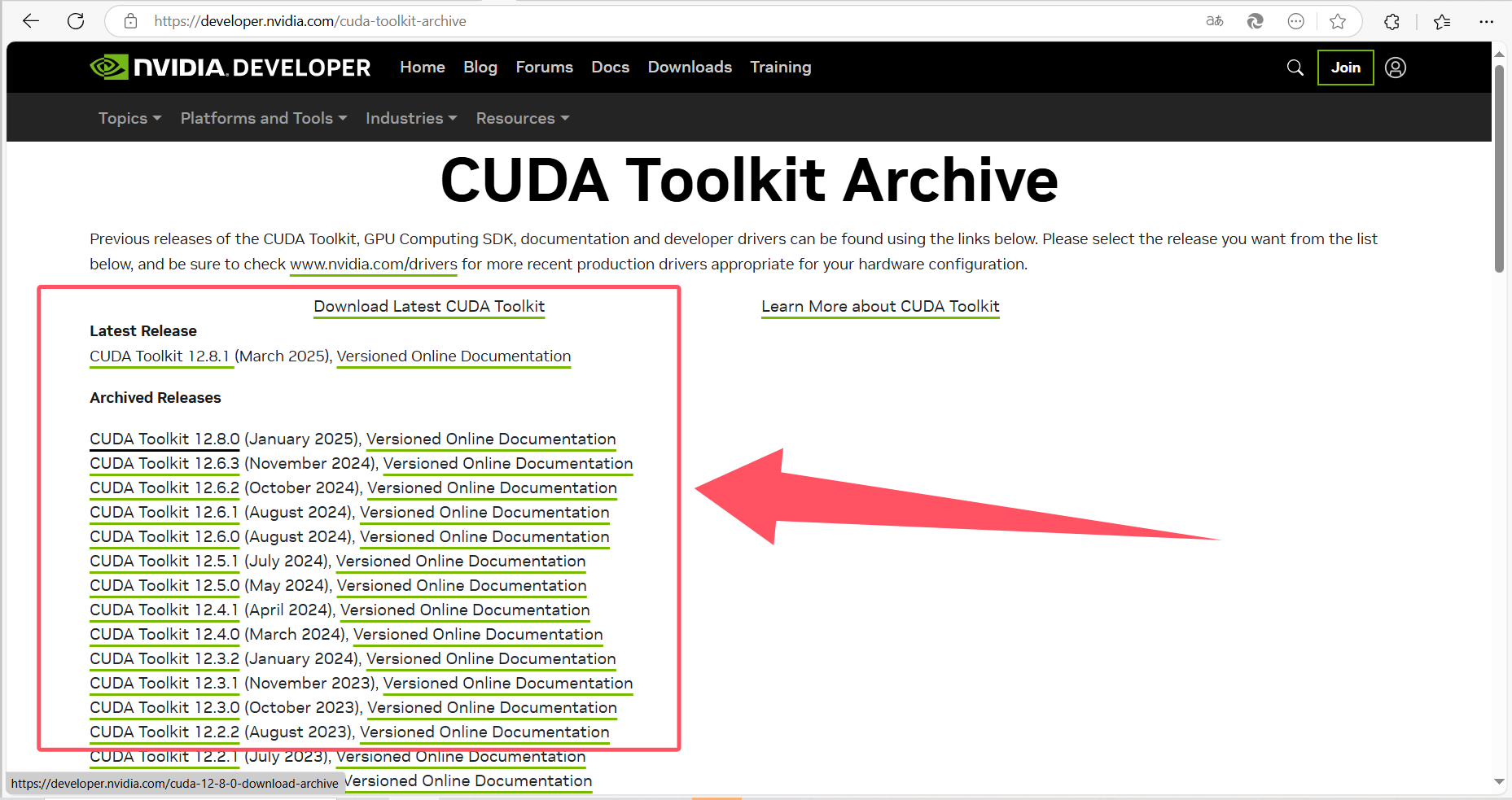
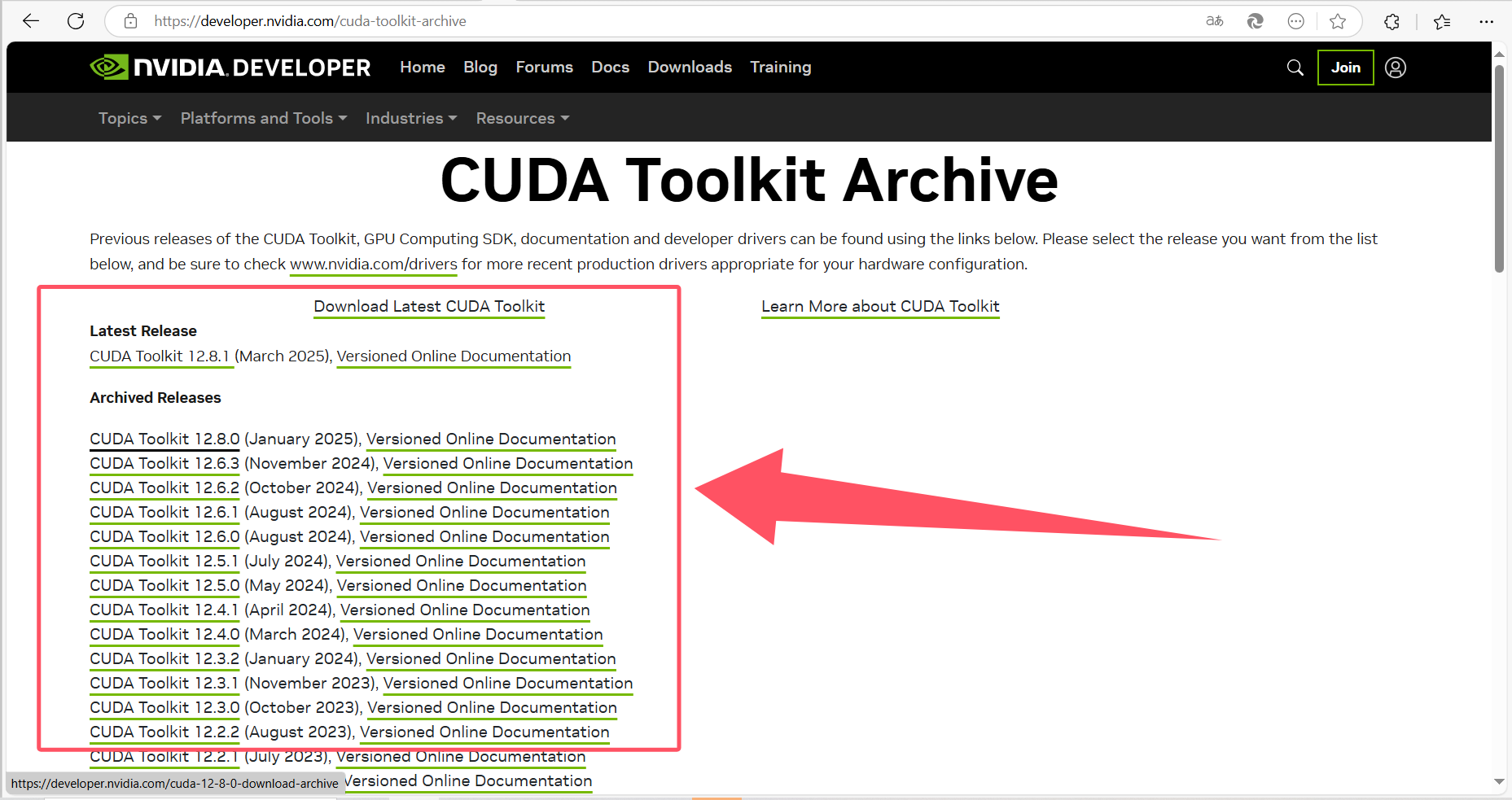
访问CUDA下载官网:CUDA Toolkit Archive | NVIDIA Developer,根据第一步查看到的自己的显卡支持的CUDA版本,下载并安装。
选择好对应CUDA 版本后,点击进入,配置一下参数,点击下载按钮即可下载: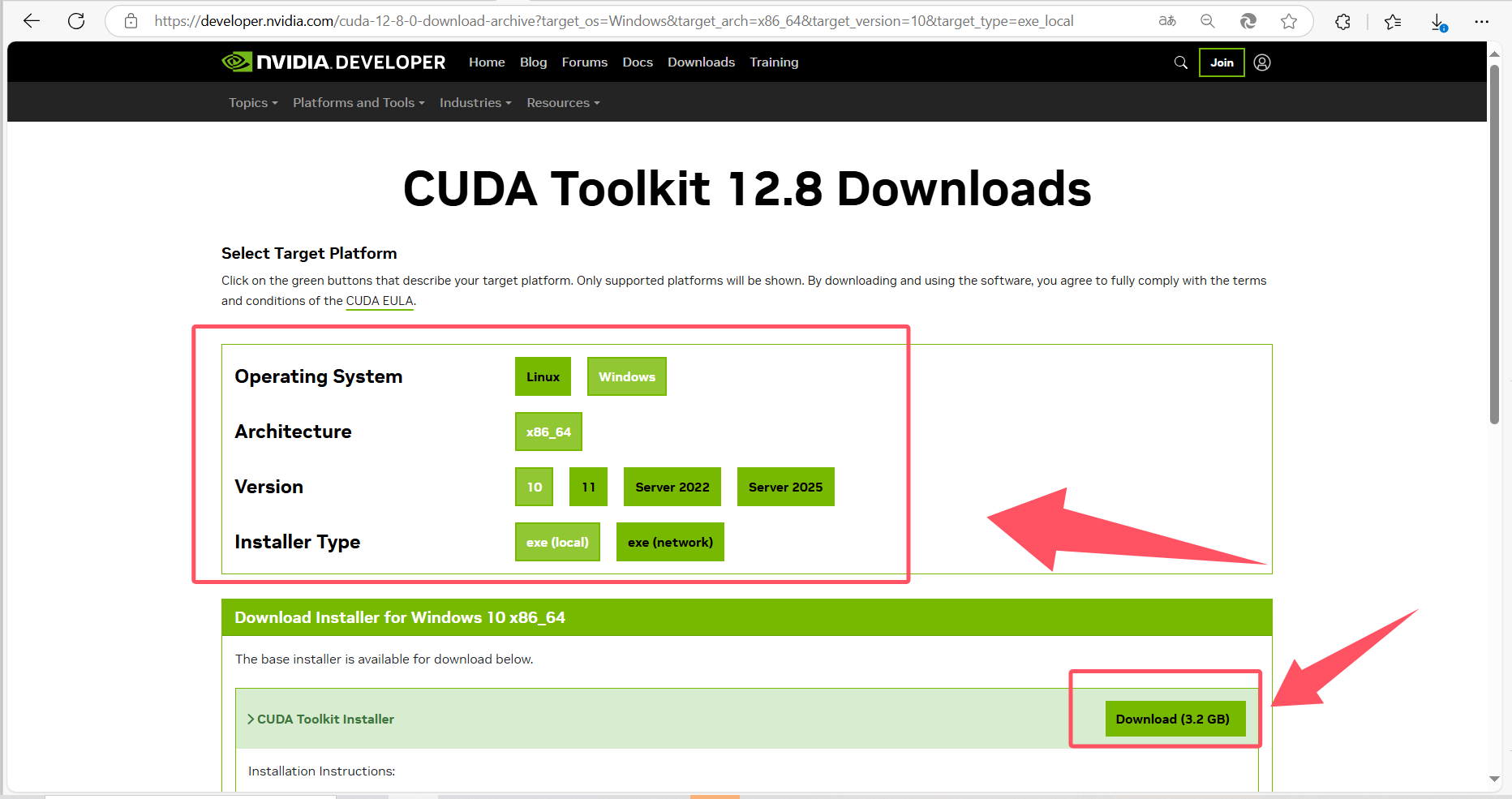
下载完成后按部就班安装完成即可,安装过程选择自定义,建议尽可能全部勾选,防止缺失内容导致后续出现麻烦。安装结束后会要求重启电脑,重启即可。
安装完成后打开电脑终端,
附一下:打开电脑终端的方法[1]
1. 从开始菜单的应用列表打开
操作路径:按Win键或者点击开始菜单 > Windows 系统 > 命令提示符如果最近从菜单打开过命令提示符,它会出现在菜单的常用列表
2. 从搜索打开
操作路径:Win + S 打开搜索栏 > 输入cmd > 在搜索结果里点击命令提示符如果最近有使用过命令提示符,它会出现在搜索窗口的最近列表里
3. 从运行打开
操作路径:Win + R 打开运行 > 输入cmd 回车
4. 从文件资源管理器打开
操作路径:打开文件资源管理器 > 在地址栏输入cmd,回车(这种方式打开dos窗口,有个特别方便之处就是,dos窗口的工作路径就是文件资源管理器当前的路径)
(注意:CUDA安装好后环境变量不需要配置,因为在安装之后就默认添加好了,9.0 版本之前(包括 9.0)还是需要配置环境变量的[2])
输入以下命令查看CUDA信息或者直接运行打开已安装的CUDA,点击【关于】查看:
nvcc -V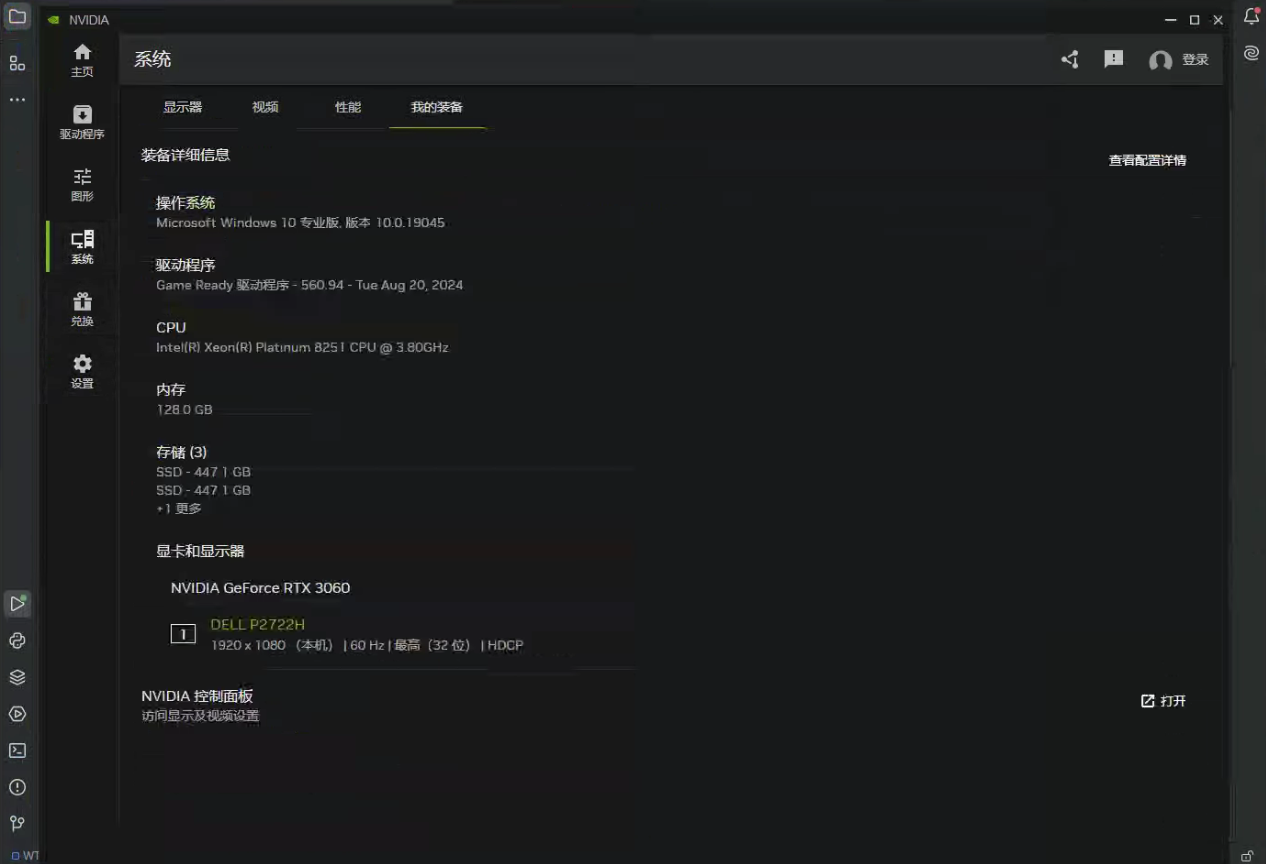
2.2 安装cuDNN
安装与CUDA对应版本的cuDNN,以加速深度学习计算。
访问cuDNN官网:cuDNN Archive | NVIDIA Developer,找到对应的cuDNN版本(根据你的CUDA版本来进行选择)
下载cuDNN需要注册一个NVIDIA官网账号,使用邮箱注册,按照提示完成注册即可跳转下载cuDNN,下载完成后得到一个压缩文件,里面有三个文件夹:
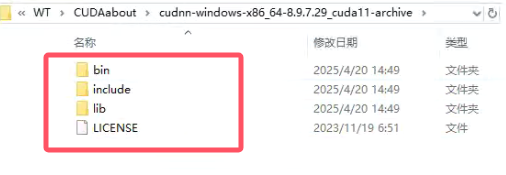
将这三个文件夹拷贝到你的CUDA安装目录下,默然安装的CUDA一般路径为:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vxx.x\# vxx.x 为CUDA版本号,如v11.8,v12.1等自定义安装的根据实际情况选择。
实际就是替换这三个文件夹中的内容:
把 bin 目录的内容拷贝到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin把 include 目录的内容拷贝到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include把 lib\x64 目录的内容拷贝到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64粘贴文件时如果提示同名文件选择覆盖。
2.3 配置CUDA相关环境变量
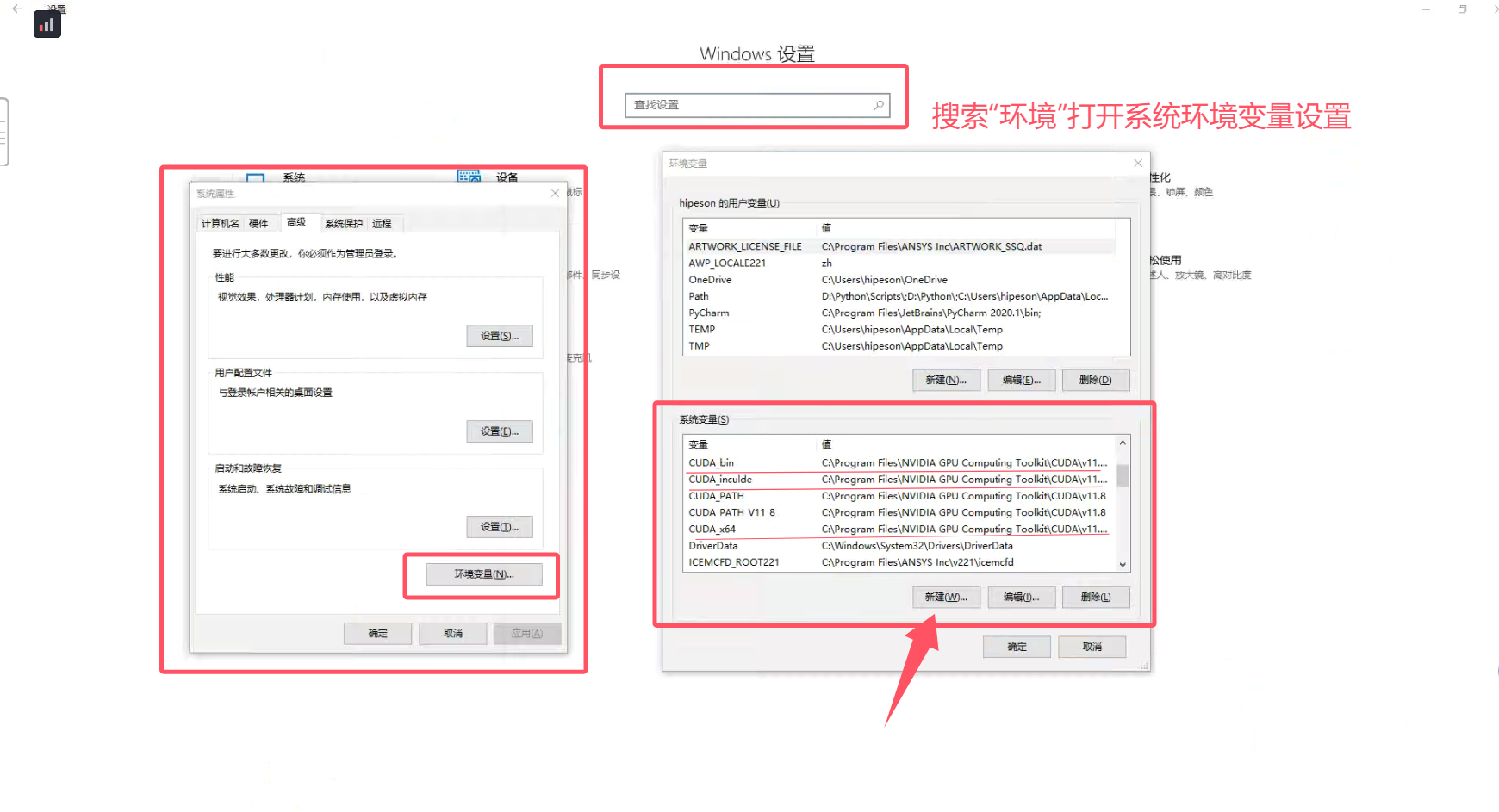
将这三个路径添加到环境变量(即cuDNN的三个文件路径):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\binC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\includeC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64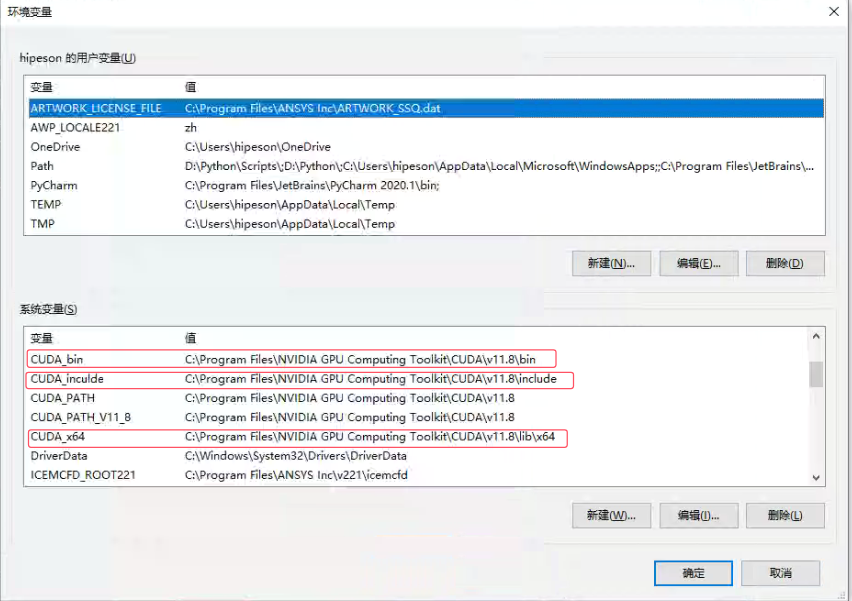
2.4 检查CUDA和cuDNN是否可用
打开终端,键入 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite目录下,输入以下命令行运行检测:
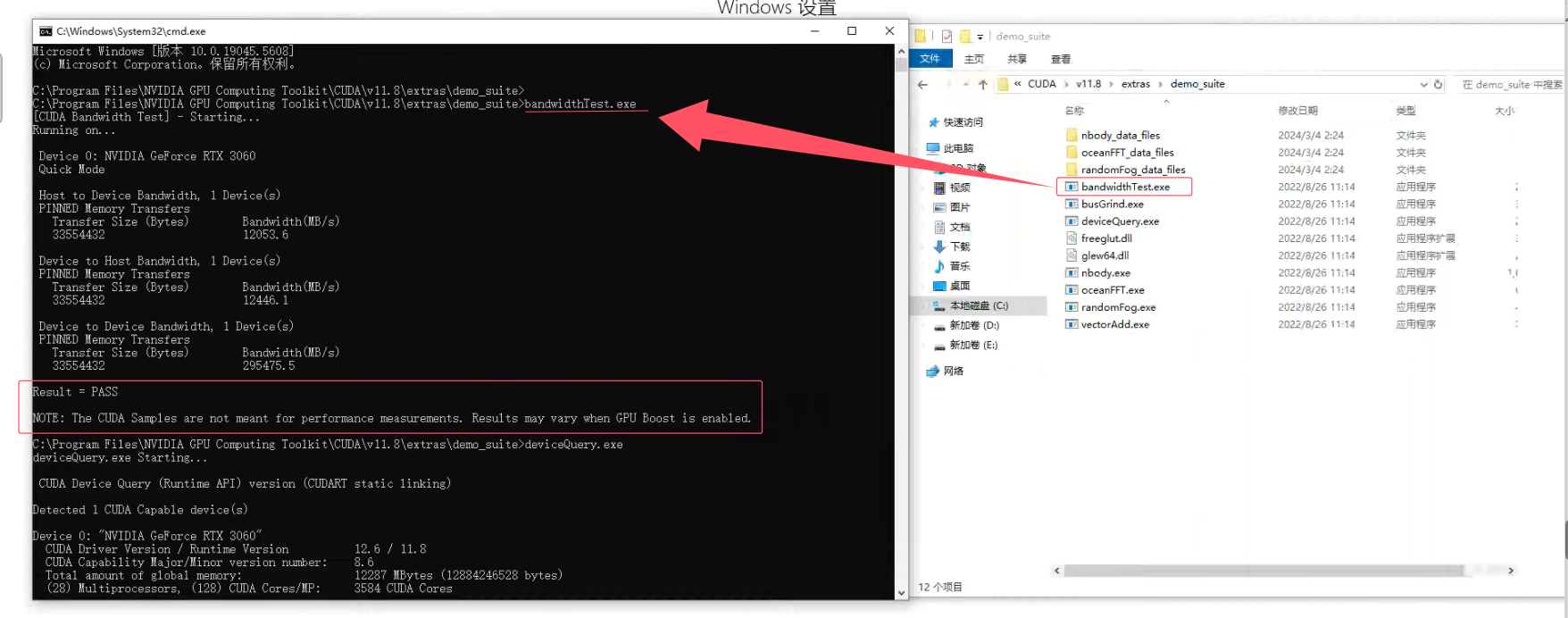
(1)运行 bandwidthTest.exe
路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite\bandwidthTest.exe
根目录终端命令行键入回车:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite\bandwidthTest.exe
或直接进入C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite\目录下终端键入回车:
bandwidthTest.exe 输出以下信息表示成功:
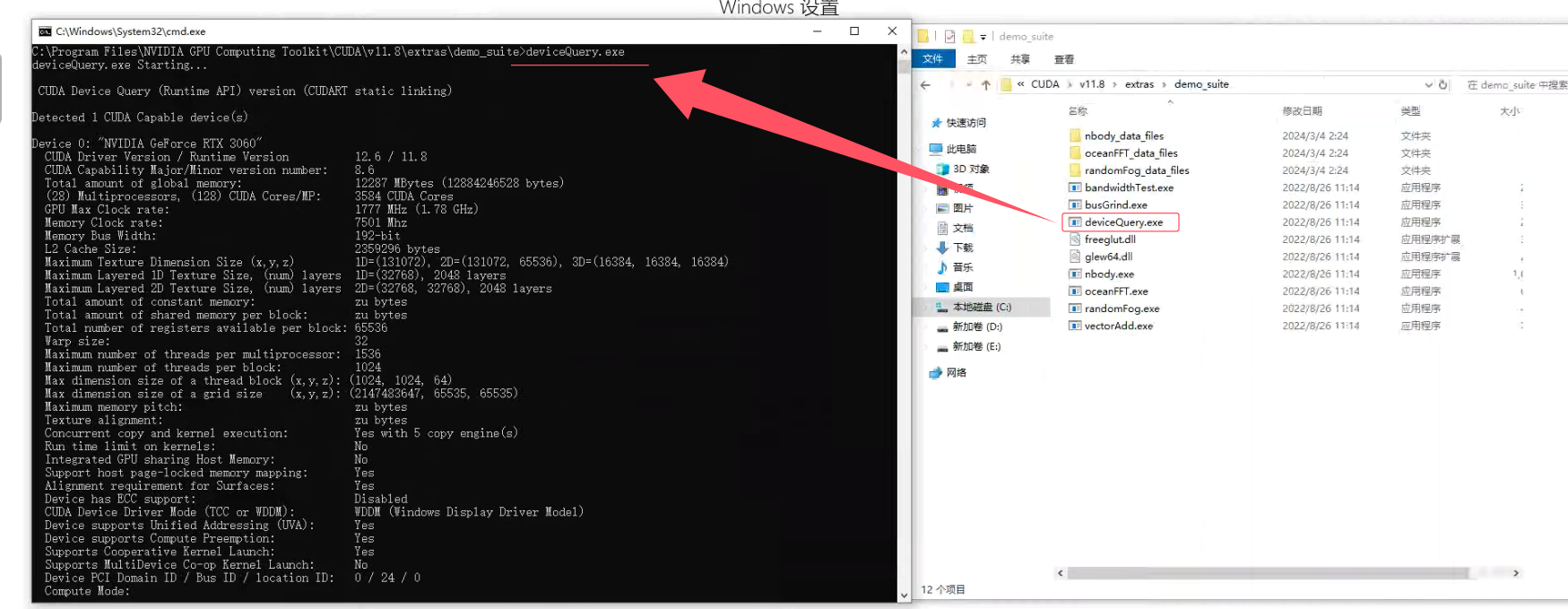
(2)运行 deviceQuery.exe
路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite\deviceQuery.exe
根目录终端命令行键入回车:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite\deviceQuery.exe
或直接进入C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite\目录下终端键入回车:
deviceQuery.exe输出以下信息表示成功:
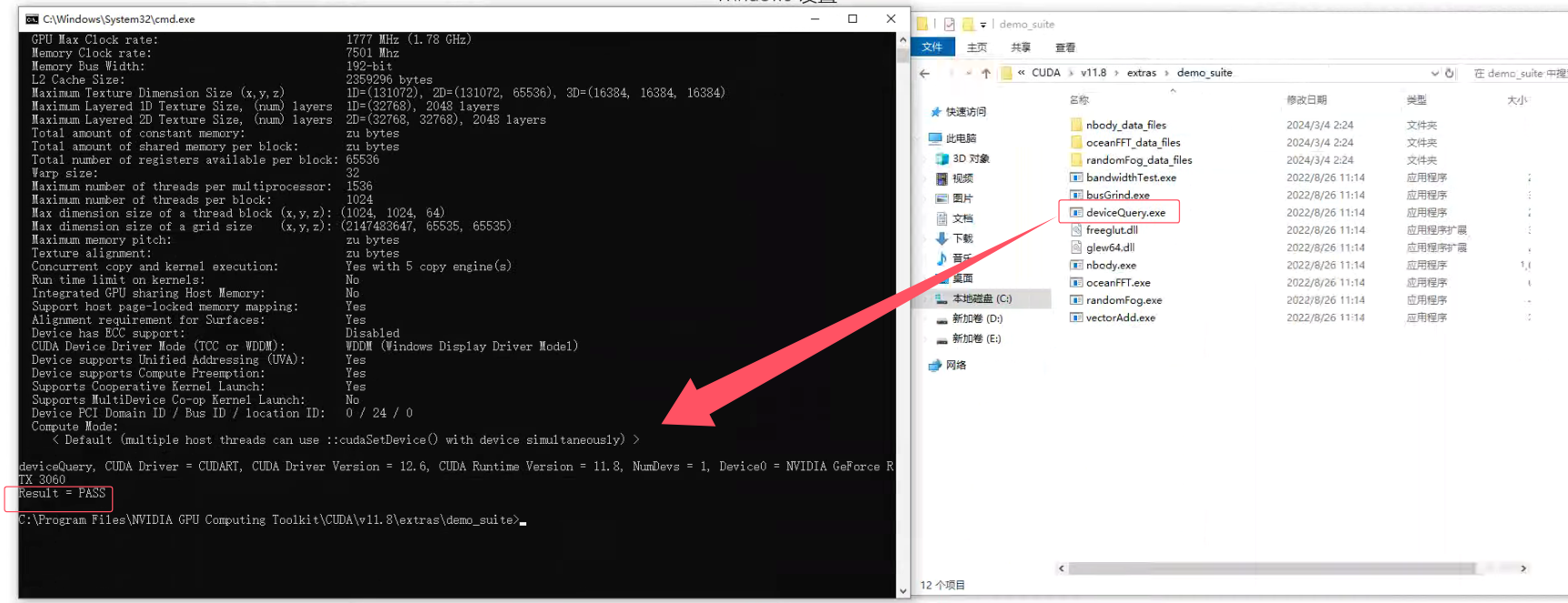
如果两个最后输出“Results=PASS”,检查通过,至此,CUDA何cuDNN安装完毕!
三、创建虚拟环境
使用Pycharm创建Python虚拟环境,以隔离项目依赖。
Pycharm创建Python虚拟环境详见这篇文章:PyCharm中虚拟环境.venv搭建详解_pycharm venv-CSDN博客
四、安装虚拟环境包
4.1 安装GPU版本的PyTorch
选择与CUDA版本兼容的PyTorch版本进行安装。选择与 cuda 对应的 pytorch 版本。如果安装的 cuda 版本大于 pytorch 支持的版本,请选择向下版本的[2]。
访问PyTorch官网: Start Locally | PyTorch,根据电脑配置和CUDA版本,选择对应的PyTorch下载命令,以我为例,使用Pip下载,CUDA版本11.8,选择配置参数后将命令行进行复制。
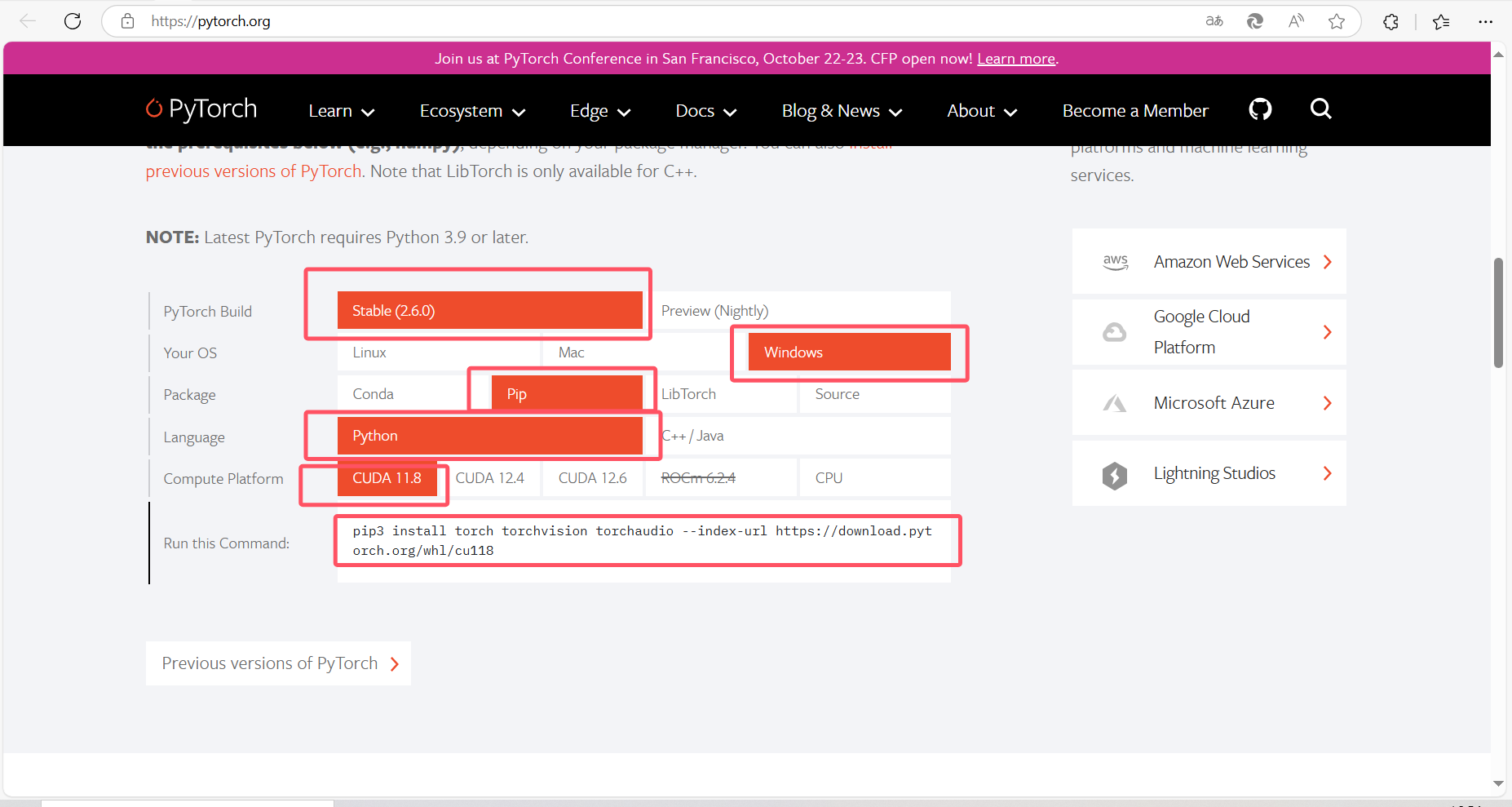
进入Pycharm虚拟环境,键入Pycharm的终端界面,粘贴复制的命令行回车安装。
由于GPU版本的Pytorch特别大,2.6G多,下载特别慢,建议使用国内镜像[3]。
对于一般库下载,配置国内镜像见笔者另一篇文章:YOLOv8环境配置及依赖安装过程记录_yolo 训练模型 安装依赖-CSDN博客 ,终端键入命令:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
但对于pytorch而言,要使用专门的镜像(仅针对本案例的torch版本,本案例测试使用的是镜像一,如果你的pytorch版本和本案例不一样,请使用正确的对应镜像源):
镜像一:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 -f https://mirrors.aliyun.com/pytorch-wheels/cu118镜像二:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 -f https://mirror.sjtu.edu.cn/pytorch-wheels/torch_stable.html4.2 YOLOv8环境搭建
详见笔者这篇文章:YOLOv8环境配置及依赖安装过程记录_yolo 训练模型 安装依赖-CSDN博客
- 下载YOLOv8代码 :从GitHub下载ultralytics的YOLOv8代码库。
- 在PyCharm中搭建环境 :将下载的代码导入PyCharm,并配置项目以使用创建的虚拟环境。
- 安装依赖 :使用pip安装ultralytics库及其他必要的依赖包。
训练与模型操作
- 数据标注 :使用工具如Label Studio对数据进行标注,为模型训练做准备。
- 训练模型 :提供训练命令示例,包括指定数据集、模型配置、预训练模型、训练轮数等参数。
- 预测推理 :给出预测命令示例,用于对新图像进行预测。
- 模型导出 :说明如何将训练好的模型导出为ONNX格式,以便在其他平台或工具中使用。
五、错误问题解决
5.1 问题一:pytorch使用出现"RuntimeError: An attempt has been made to start a new process before the..."
Pytorch使用出现运行时错误"RuntimeError: An attempt has been made to start a new process before the..." 解决方法[4]
原因在于笔者训练模型时将train.py代码直接写入运行,推测可能是Python模块之间的导入相关问题导致的,即可能与导入库的相关线程发生冲突。比较可靠的说法是python在linux上和windows上创建多进程的逻辑不一样导致的,并不是说windows不能用多个子进程加载数据。报这个错是因为windows创建子进程的时候递归创建了,在创建子进程的代码上加个if __name__ == '__main__':就好了。(来自知乎相关帖子的评论区)
最后的解决办法是将运行代码块放入“if __name__=='__main__:”下,这样就能正常运行了,关于if __name__=='__main__的作用如下:
当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;
当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
5.2 问题二:报错No module named ‘numpy._core‘
这里的错误 "ModuleNotFoundError: No module named 'numpy._core'" 说明 NumPy 安装不完整或损坏,可以按照以下方法修复[5]:
首先我们指定安装一个稳定版本,以1.23.5为例
pip install numpy==1.23.5
然后将数据集中train和val下的train.cache和val.cache删除
这里是因为在训练之前,会对已有的数据集有一个预处理,在dataset/train和dataset/val文件夹中,生成一个.cache格式的文件,如果这个文件已有的话,是不会再次生成的。
而这个文件的生成依赖于numpy,不同的numpy版本会造成上面的报错。
5.3 问题三:Numpy版本报错
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.1.1 as it may crash. To support both 1.x and 2.x versions of NumPy, modules must be compiled with NumPy 2.0. Some module may need to rebuild instead e.g. with 'pybind11>=2.12'. If you are a user of the module, the easiest solution will be to downgrade to 'numpy<2' or try to upgrade the affected module. We expect that some modules will need time to support NumPy 2.原因:模块不兼容[5]:
- 这个错误信息表示你当前运行的环境中,某些模块是使用 NumPy 1.x 版本编译的,而你当前的 NumPy 版本是 2.0.0。由于版本不兼容,这些模块可能会崩溃或产生错误。
解决办法:卸载现有的Numpy,安装低版本
pip uninstall numpypip install numpy==1.23.5六、相关说明
1. PyTorch、CUDA、cuDNN的作用
1.1 PyTorch的作用
PyTorch是一个开源的机器学习库,基于Torch,主要用于应用如计算机视觉和自然语言处理等人工智能领域。它为开发者提供了一个灵活且高效的平台来构建和训练深度学习模型。
- 动态计算图:PyTorch采用动态计算图,允许用户在运行时动态地改变计算图的结构。这使得模型的构建和调试更加灵活,开发者可以根据需要随时修改模型的架构或操作,而无需重新定义整个计算图。例如,在训练YOLO模型时,开发者可以轻松地添加或删除某些层,或者调整层之间的连接关系,以优化模型的性能。
- 易用性与灵活性:PyTorch的API设计简洁直观,易于上手。它提供了丰富的预定义模块和函数,使得开发者可以快速地构建复杂的神经网络模型。同时,PyTorch还支持自定义操作和模块,这为开发者提供了极大的灵活性,能够满足各种特殊需求。在YOLO模型训练中,开发者可以利用PyTorch的自定义功能来实现特定的损失函数或优化算法,从而进一步提升模型的训练效果。
- 强大的社区支持:PyTorch拥有一个活跃的开源社区,社区成员提供了大量的教程、代码示例和预训练模型。这些资源对于新手来说是非常宝贵的,可以帮助他们快速入门并掌握PyTorch的使用方法。对于有经验的开发者而言,社区也是一个交流经验和解决问题的好地方。在YOLO模型训练过程中,开发者可以参考社区中其他用户的经验和代码,避免走弯路,提高开发效率。
1.2 CUDA的作用
CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程模型,它允许开发者利用NVIDIA GPU的强大计算能力来加速计算密集型任务。
- 加速深度学习计算:深度学习模型的训练和推理过程通常需要大量的矩阵运算和张量操作,这些操作在GPU上可以通过CUDA进行高效并行计算。与传统的CPU计算相比,使用CUDA的GPU计算可以显著提高计算速度。例如,在训练YOLO模型时,大量的卷积运算和反向传播过程都可以通过CUDA在GPU上快速完成,从而大大缩短了模型的训练时间。根据实验数据,使用CUDA的GPU加速可以使YOLO模型的训练速度比仅使用CPU提高数十倍甚至上百倍。
- 支持多种编程语言和框架:CUDA不仅支持C/C++等编程语言,还与多种深度学习框架(如PyTorch、TensorFlow等)无缝集成。这意味着开发者可以在这些框架中方便地利用CUDA的加速功能,而无需深入了解底层的CUDA编程细节。在PyTorch中,开发者只需简单地将张量和模型移动到GPU上,PyTorch就会自动调用CUDA来进行计算,使得开发过程更加便捷高效。
- 优化资源分配:CUDA提供了多种机制来优化GPU资源的分配和管理。例如,开发者可以通过CUDA流(CUDA Stream)来实现多个操作的并行执行,从而进一步提高计算效率。此外,CUDA还提供了内存管理功能,允许开发者灵活地分配和释放GPU内存,确保资源的合理利用。在训练YOLO模型时,合理地管理GPU内存和调度计算任务是非常重要的,CUDA的这些功能可以帮助开发者更好地优化模型的训练过程。
1.3 cuDNN的作用
cuDNN(CUDA Deep Neural Network)是NVIDIA为深度神经网络开发的GPU加速库,它提供了高度优化的深度学习原语(如卷积、池化、激活函数等)的实现。
- 优化深度学习原语:cuDNN对深度学习中常用的原语进行了深度优化,使其在GPU上能够以极高的效率运行。例如,cuDNN中的卷积操作采用了高效的算法和内存布局,能够充分利用GPU的并行计算能力,从而显著提高卷积运算的速度。在YOLO模型中,卷积层是模型的核心部分,使用cuDNN加速卷积运算可以大大提高模型的训练和推理效率。实验表明,使用cuDNN的卷积运算速度比未优化的实现快数倍甚至数十倍。
- 与深度学习框架集成:cuDNN与PyTorch等深度学习框架紧密集成,开发者在使用这些框架时无需手动调用cuDNN的API。框架会自动根据硬件环境选择最优的cuDNN实现来加速计算。这种无缝集成的方式使得开发者可以专注于模型的设计和开发,而无需关心底层的优化细节。在YOLO模型训练中,开发者只需使用PyTorch的API来构建和训练模型,PyTorch会自动利用cuDNN来加速模型中的卷积、池化等操作,从而实现高效的训练过程。
- 跨平台支持:cuDNN支持多种操作系统和硬件平台,包括Windows、Linux等操作系统以及不同型号的NVIDIA GPU。这意味着开发者可以在不同的环境中使用cuDNN来加速深度学习模型的训练和推理。对于YOLO模型的开发者来说,无论是在个人电脑上进行模型开发,还是在服务器上进行大规模训练,都可以通过cuDNN获得高效的计算支持。
2. PyTorch、CUDA、cuDNN之间的关系
2.1 PyTorch与CUDA的关系
PyTorch与CUDA紧密协作,共同为深度学习模型的高效训练提供支持。
- 计算加速:PyTorch通过CUDA充分利用GPU的并行计算能力。在YOLO模型训练中,大量的卷积运算、激活函数计算以及反向传播过程都可以通过CUDA在GPU上并行执行。例如,在处理大规模数据集时,使用CUDA加速的YOLO模型训练速度比仅使用CPU的训练速度可提高数十倍甚至上百倍。这是因为GPU拥有成千上万个核心,能够同时处理多个计算任务,而CPU的核心数量相对较少,更适合顺序执行任务。
- 无缝集成:PyTorch与CUDA的集成非常便捷。开发者只需将张量和模型移动到GPU上,PyTorch就会自动调用CUDA进行计算。这种无缝集成使得开发者无需深入了解CUDA的底层细节,就可以轻松地利用GPU加速模型训练。例如,通过简单的
.to(device)操作,开发者可以将数据和模型从CPU转移到GPU,然后PyTorch会自动处理后续的计算任务。 - 资源管理:PyTorch借助CUDA提供的资源管理功能,优化GPU资源的使用。在YOLO模型训练过程中,合理管理GPU内存和调度计算任务至关重要。CUDA的内存管理机制允许开发者灵活地分配和释放GPU内存,确保资源的高效利用。例如,通过使用CUDA流(CUDA Stream),开发者可以实现多个操作的并行执行,进一步提高计算效率。
2.2 PyTorch与cuDNN的关系
PyTorch与cuDNN深度集成,共同提升深度学习模型的训练和推理效率。
- 性能优化:cuDNN为PyTorch提供了高度优化的深度学习原语实现。在YOLO模型中,卷积层是模型的核心部分,cuDNN对卷积操作进行了深度优化,使其在GPU上运行速度极快。实验表明,使用cuDNN加速的卷积运算速度比未优化的实现快数倍甚至数十倍。此外,cuDNN还优化了池化、激活函数等操作,进一步提升了模型的整体性能。
- 自动调用:PyTorch与cuDNN的集成非常紧密,开发者在使用PyTorch构建和训练模型时无需手动调用cuDNN的API。PyTorch会自动根据硬件环境选择最优的cuDNN实现来加速计算。这种无缝集成的方式使得开发者可以专注于模型的设计和开发,而无需关心底层的优化细节。例如,在YOLO模型训练中,开发者只需使用PyTorch的API来构建和训练模型,PyTorch会自动利用cuDNN来加速模型中的卷积、池化等操作。
- 跨平台支持:cuDNN支持多种操作系统和硬件平台,包括Windows、Linux等操作系统以及不同型号的NVIDIA GPU。这意味着开发者可以在不同的环境中使用cuDNN来加速深度学习模型的训练和推理。对于YOLO模型的开发者来说,无论是在个人电脑上进行模型开发,还是在服务器上进行大规模训练,都可以通过cuDNN获得高效的计算支持。
2.3 CUDA与cuDNN的关系
CUDA为cuDNN提供了底层的并行计算支持,cuDNN则在CUDA的基础上进一步优化深度学习原语的实现。
- 底层支持:CUDA是NVIDIA推出的并行计算平台和编程模型,为cuDNN提供了底层的硬件加速支持。cuDNN中的所有优化操作都是基于CUDA的并行计算能力实现的。例如,cuDNN中的卷积操作采用了高效的算法和内存布局,这些优化都是通过CUDA的并行计算机制在GPU上实现的。
- 优化实现:cuDNN在CUDA的基础上,对深度学习中常用的原语进行了深度优化。例如,cuDNN中的卷积操作不仅采用了高效的算法,还针对不同的硬件配置进行了优化,使其在不同的NVIDIA GPU上都能以极高的效率运行。这种优化使得cuDNN能够充分利用CUDA提供的并行计算能力,进一步提升深度学习模型的性能。
- 协同工作:CUDA和cuDNN协同工作,为深度学习框架(如PyTorch)提供了高效的计算支持。开发者在使用PyTorch等框架时,无需关心底层的CUDA和cuDNN实现细节,只需将数据和模型移动到GPU上,框架会自动调用CUDA和cuDNN来加速计算。这种协同工作模式使得深度学习模型的训练和推理过程更加高效,同时也降低了开发者的使用门槛。
: NVIDIA CUDA Documentation
PyTorch Documentation - CUDA
NVIDIA CUDA Stream Documentation
NVIDIA cuDNN Documentation
PyTorch Documentation - cuDNN
NVIDIA cuDNN Supported Platforms
NVIDIA CUDA and cuDNN Relationship
cuDNN Convolution Optimization
PyTorch and CUDA/cuDNN Integration
3. PyTorch、CUDA、cuDNN在YOLO模型训练中的作用
3.1 加速模型训练
YOLO模型训练过程中涉及大量的计算任务,如卷积运算、激活函数计算、反向传播等。PyTorch通过CUDA充分利用GPU的并行计算能力,显著提高了这些计算任务的执行速度。例如,使用CUDA加速的YOLO模型训练速度比仅使用CPU的训练速度可提高数十倍甚至上百倍。此外,cuDNN对深度学习中常用的原语进行了深度优化,如卷积操作采用了高效的算法和内存布局,能够充分利用GPU的并行计算能力,进一步提高卷积运算的速度。实验表明,使用cuDNN的卷积运算速度比未优化的实现快数倍甚至数十倍。这种加速效果使得YOLO模型能够在更短的时间内完成训练,提高了开发效率。
3.2 提高模型性能
cuDNN为PyTorch提供了高度优化的深度学习原语实现,如卷积、池化、激活函数等。在YOLO模型中,卷积层是模型的核心部分,cuDNN对卷积操作进行了深度优化,使其在GPU上运行速度极快。此外,cuDNN还优化了池化、激活函数等操作,进一步提升了模型的整体性能。例如,在YOLO模型的推理阶段,使用cuDNN优化后的卷积操作可以显著提高模型的推理速度,从而实现更高效的实时目标检测。同时,PyTorch的动态计算图特性允许开发者在训练过程中动态调整模型结构,以优化模型的性能。这种灵活性使得开发者可以根据训练数据和任务需求,对YOLO模型进行微调,进一步提升模型的准确性和鲁棒性。
3.3 简化开发流程
PyTorch与CUDA和cuDNN的紧密集成,极大地简化了YOLO模型的开发流程。开发者只需将张量和模型移动到GPU上,PyTorch就会自动调用CUDA和cuDNN进行计算。这种无缝集成使得开发者无需深入了解底层的CUDA和cuDNN编程细节,就可以轻松地利用GPU加速模型训练。例如,通过简单的.to(device)操作,开发者可以将数据和模型从CPU转移到GPU,然后PyTorch会自动处理后续的计算任务。此外,PyTorch的API设计简洁直观,易于上手,提供了丰富的预定义模块和函数,使得开发者可以快速地构建复杂的神经网络模型。在YOLO模型训练中,开发者可以利用PyTorch的自定义功能来实现特定的损失函数或优化算法,进一步提升模型的训练效果。同时,PyTorch拥有一个活跃的开源社区,社区成员提供了大量的教程、代码示例和预训练模型。这些资源对于新手来说是非常宝贵的,可以帮助他们快速入门并掌握PyTorch的使用方法。对于有经验的开发者而言,社区也是一个交流经验和解决问题的好地方。
PyTorch Documentation
PyTorch Documentation - CUDA
NVIDIA cuDNN Documentation
PyTorch Documentation - cuDNN
4. 总结
PyTorch、CUDA 和 cuDNN 在深度学习领域尤其是 YOLO 模型训练中发挥着至关重要的作用,它们相互协作,共同推动了深度学习模型的高效训练和广泛应用。
PyTorch 作为开源的机器学习库,凭借其动态计算图、易用性与灵活性以及强大的社区支持,为开发者提供了一个高效且灵活的平台来构建和训练深度学习模型。它能够满足开发者在模型构建、调试以及优化过程中的多样化需求,使得复杂模型的开发变得更加简单高效。在 YOLO 模型训练中,PyTorch 的这些特性使得开发者可以轻松地调整模型结构,实现特定的损失函数和优化算法,从而提升模型的训练效果和性能。
CUDA 是 NVIDIA 推出的并行计算平台和编程模型,它为深度学习模型的训练提供了强大的硬件加速支持。通过利用 GPU 的并行计算能力,CUDA 能够显著提高深度学习模型中大量矩阵运算和张量操作的执行速度。在 YOLO 模型训练中,使用 CUDA 的 GPU 加速可以使模型的训练速度比仅使用 CPU 提高数十倍甚至上百倍,大大缩短了训练时间,提高了开发效率。此外,CUDA 还提供了多种机制来优化 GPU 资源的分配和管理,进一步提高了计算效率和资源利用率。
cuDNN 是 NVIDIA 为深度神经网络开发的 GPU 加速库,它对深度学习中常用的原语进行了深度优化,如卷积、池化、激活函数等。这些优化使得这些操作在 GPU 上能够以极高的效率运行,进一步提高了深度学习模型的训练和推理效率。在 YOLO 模型中,卷积层是模型的核心部分,使用 cuDNN 加速的卷积运算速度比未优化的实现快数倍甚至数十倍,显著提升了模型的性能。同时,cuDNN 与 PyTorch 等深度学习框架紧密集成,开发者在使用这些框架时无需手动调用 cuDNN 的 API,框架会自动根据硬件环境选择最优的 cuDNN 实现来加速计算,这种无缝集成的方式使得开发者可以专注于模型的设计和开发,而无需关心底层的优化细节。
在 YOLO 模型训练中,PyTorch、CUDA 和 cuDNN 的协同作用至关重要。PyTorch 通过 CUDA 充分利用 GPU 的并行计算能力,显著提高了模型训练的速度;而 cuDNN 则在 CUDA 的基础上进一步优化了深度学习原语的实现,进一步提升了模型的性能。这种协同工作模式使得 YOLO 模型能够在更短的时间内完成训练,同时在推理阶段也能实现更高效的实时目标检测。此外,PyTorch 与 CUDA 和 cuDNN 的紧密集成还极大地简化了 YOLO 模型的开发流程,使得开发者无需深入了解底层的 CUDA 和 cuDNN 编程细节,就可以轻松地利用 GPU 加速模型训练,提高了开发效率和开发体验。
PyTorch、CUDA 和 cuDNN 在深度学习领域尤其是 YOLO 模型训练中发挥着不可或缺的作用。它们相互协作,共同为深度学习模型的高效训练和广泛应用提供了强大的支持。随着深度学习技术的不断发展和应用场景的不断拓展,PyTorch、CUDA 和 cuDNN 也将不断优化和改进,为开发者提供更加高效、便捷和强大的工具,推动深度学习技术的进一步发展。
参考资料:
[1] Windows 打开cmd/dos窗口的12种方式(全网最全)-CSDN博客
[2]【yolov8基础教程】Yolov8模型训练GPU环境配置保姆级教程(附安装包)-CSDN博客
[3] pytorch gpu国内镜像下载,目前最快下载_pytorch镜像下载-CSDN博客
[4] pytorch使用出现"RuntimeError: An attempt has been made to start a new process before the..." 解决方法-CSDN博客
[5]解决yolov11训练过程中报错No module named ‘numpy._core‘_yolov11 numpy报错-CSDN博客