AI——神经网络以及TensorFlow使用
文章目录
- 一、TensorFlow安装
- 二、张量、变量及其操作
- 1、张量Tensor
- 2、变量
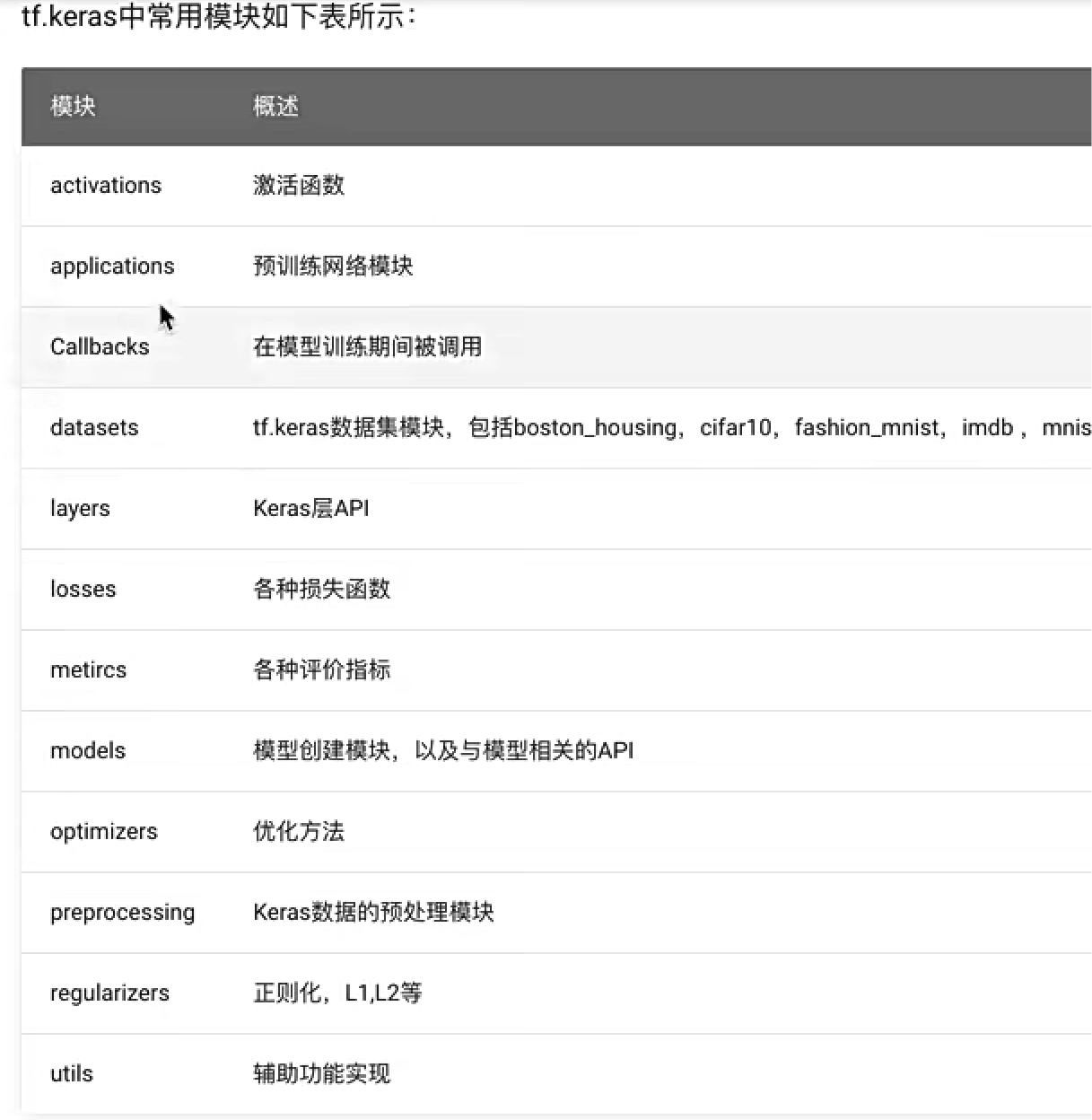
- 三、tf.keras介绍
- 1、使用tf.keras构建我们的模型
- 2、激活函数
- 1、sigmoid/logistics函数
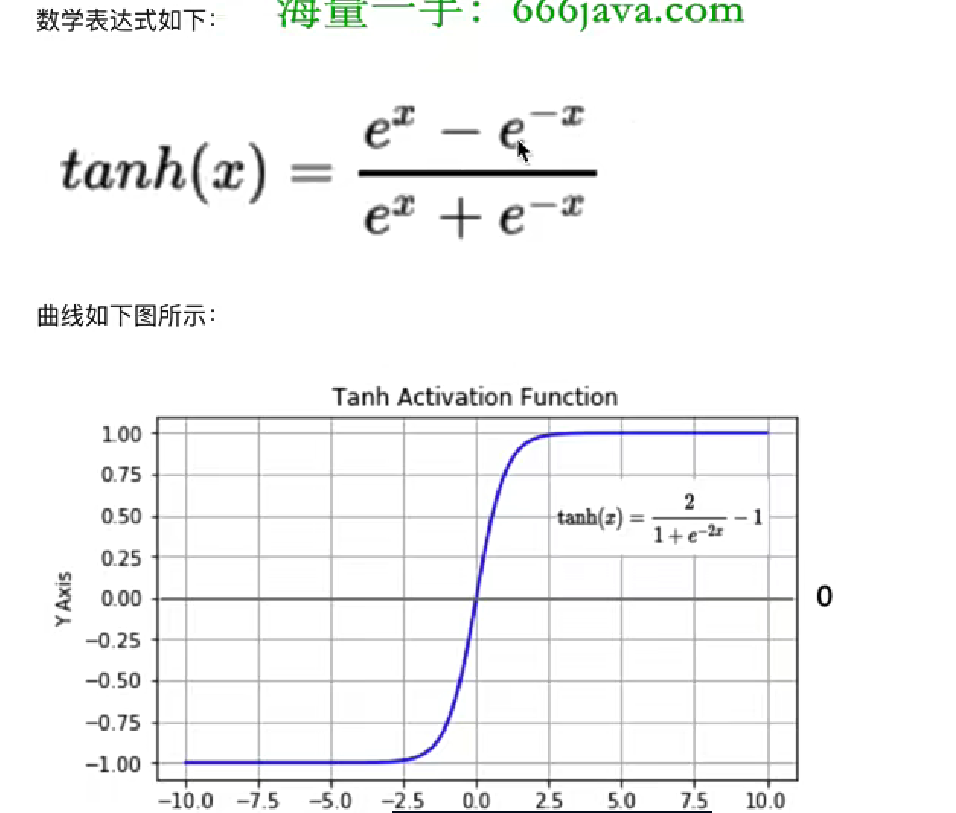
- 2、tanh函数
- 3、RELU函数
- 4、LeakReLu
- 5、SoftMax
- 6、如何选择激活函数
- 3、参数初始化
- 1、bias偏置初始化
- 2、weight权重初始化
- 1、随机初始化
- 2、标准初始化
- 3、Xavier初始化
- 4、He初始化
- 4、神经网络构建
- 1、通过Sequential构建
- 2、function api方式构建
- 3、Model子类构建方式
- 5、神经网络的优缺点
一、TensorFlow安装
# 1、非GPU版本安装
pip3 install tensorflow==2.3.0# 2、GPU版本安装
pip3 install tensorflow-gpu==2.3.0
二、张量、变量及其操作
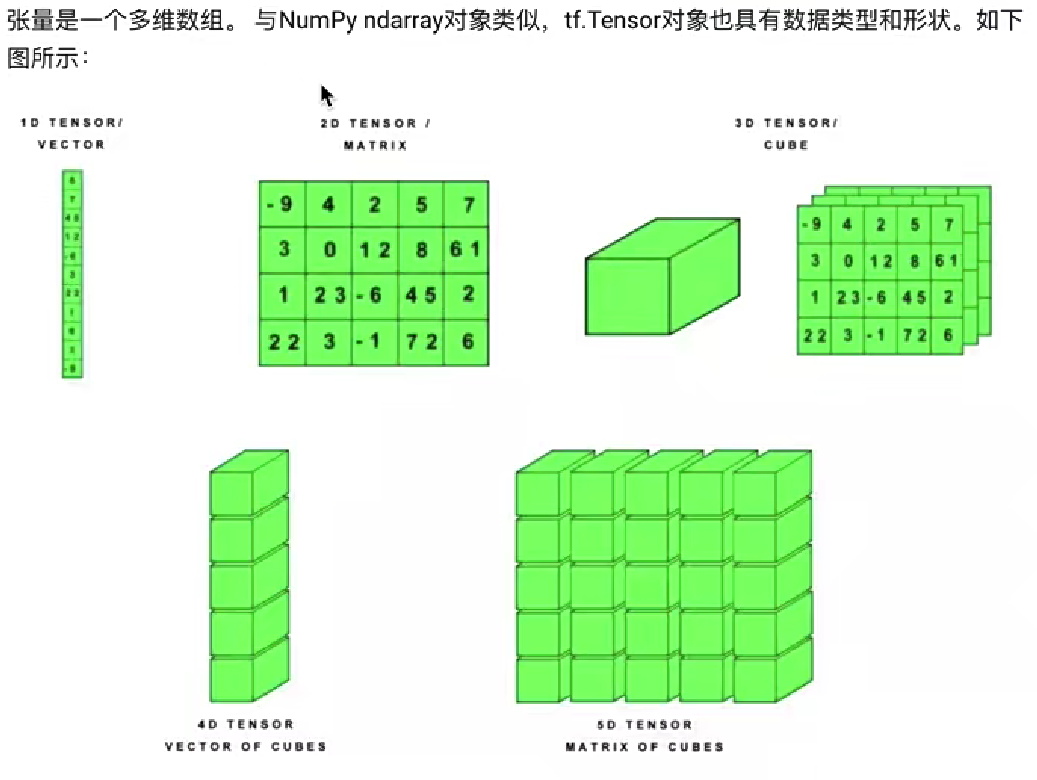
1、张量Tensor
import tensorflow as tf
import numpy as np# 创建基础的张量
## 1.创建int32类型的0维张量,即标量
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)## 2.创建float32类型的1维张量
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)## 3.创建float16类型的二维张量
rank_2_tensor = tf.constant([[1, 2],[3, 4],[5, 6]
], dtype=tf.float16)
print(rank_2_tensor)## 4.将张量转化为ndarray
np1 = np.array(rank_2_tensor)
print(np1)np2 = rank_2_tensor.numpy
print(np2)# 张量常用函数
a = tf.constant([[1, 2],[3, 4]
])
b = tf.constant([[1, 1],[1, 1]
])
print(tf.add(a, b)) # 计算张量元素的和
print(tf.multiply(a, b)) # 计算张量元素的乘积
print(tf.matmul(a, b)) # 计算张量矩阵的乘法# 聚合运算
c = tf.constant([[4.0, 5.0],[10.0, 1.0]
])
print(tf.reduce_max(c)) # 最大值
print(tf.reduce_mean(c)) # 平均值
print(tf.reduce_sum(c)) # 求和
print(tf.reduce_min(c)) # 最小值
print(tf.argmax(c)) # 最大值索引
print(tf.argmin(c)) # 最小值索引
2、变量

# 变量
var = tf.Variable([[1, 2],[3, 4]
])
print(var.shape) # 获取变量的形状
print(var.dtype) # 获取变量中数据类型
print(var.numpy) # 转化为ndarray
print(var.assign([[5, 6], [7, 8]])) # 修改变量值
三、tf.keras介绍
1、使用tf.keras构建我们的模型
# 绘图工具
import seaborn as sns
# 数组计算
import numpy as np
# sklearn相关工具
from sklearn.datasets import load_iris
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的层和激活工具
from tensorflow.keras.layers import Dense, Activation
# 数据处理的辅助工具
from tensorflow.keras import utils
# pandas工具,让数据更好看
import pandas as pd# 1.使用sklearn获取鸢尾花数据
iris = load_iris()
iris_d = pd.DataFrame(data=iris.data, columns=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
# 设置其目标值为target_names
iris_d['species'] = iris['target_names'][iris['target']]
# 使用seaborn中的pairplot函数探索数据特征间的关系
sns.pairplot(iris_d, hue="species")# 使用sklearn实现# 所有的特征值
x = iris_d.values[:, :4]# 所有的目标值
y = iris_d.values[:, 4]# 利用train_test_split完成数据集划分,测试集20%,训练集80%
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)# 特征预处理
# transfer = StandardScaler()
transfer = MinMaxScaler((0, 1))
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)## 模型调优 - 交叉验证、网格搜索
# 实例化估计器,CV这个估计器已经调过优了
lr = LogisticRegressionCV()
# 模型训练
lr.fit(x_train, y_train)
# 模型评估
lr.score(x_test, y_test)# 使用tf.keras实现
# 1.生成目标值的热编码
def one_hot_encode(arr):# 获取目标值中的所有类别进行热编码uniques, ids = np.unique(arr, return_inverse=True)return utils.to_categorical(ids, len(uniques))# 2.对目标值进行热编码
y_train_one = one_hot_encode(y_train)
y_test_one = one_hot_encode(y_test)# 3.模型构建
model = Sequential([# 隐藏层,输入层,input_shape表示我们有几个特征Dense(10, activation="relu", input_shape=(4,)),# 隐藏层Dense(10, activation="relu"),# 输出层,3表示我们有几种结果Dense(3, activation="softmax")
])# 4.模型预测与评估
## 4.1 模型编译
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])## 4.2 模型训练
# 类型转换
x_train = np.array(x_train, dtype=np.float32)
x_test = np.array(x_test, dtype=np.float32)
model.fit(x_train, y_train_one, epochs=10, batch_size=1, verbose=1)## 4.3模型评估
loss, accuracy = model.evaluate(x_test, y_test_one, verbose=1)
print("loss: ", loss)
print("准确率:", accuracy)
2、激活函数
1、sigmoid/logistics函数
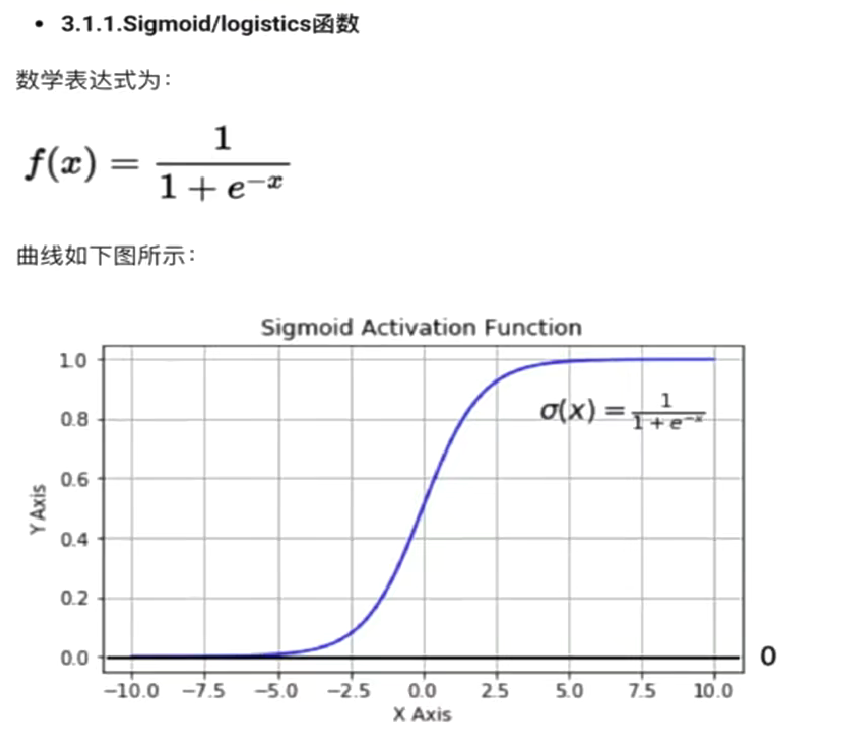

一般只用于输出层的二分类
2、tanh函数

3、RELU函数
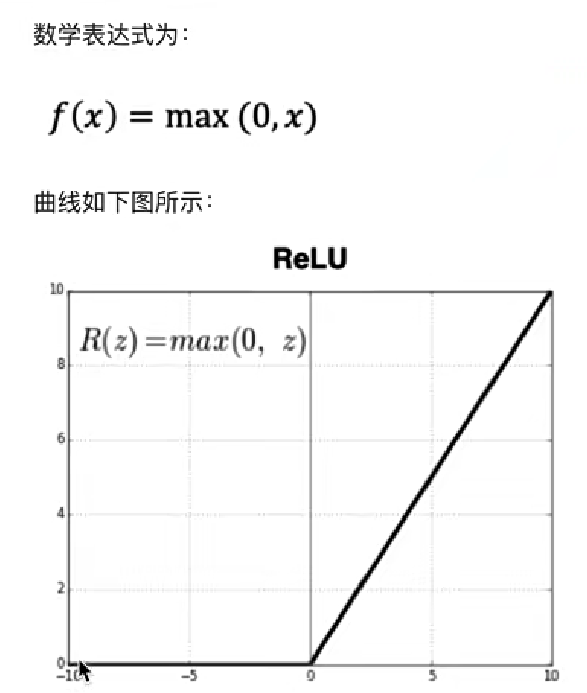


无脑使用RELU
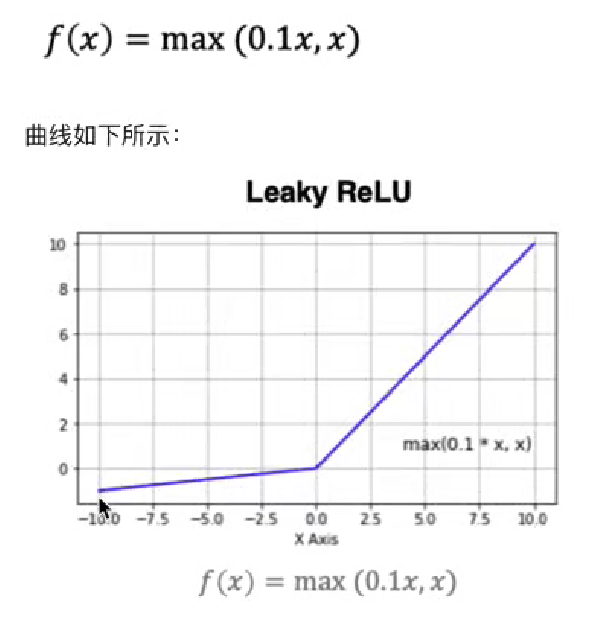
4、LeakReLu
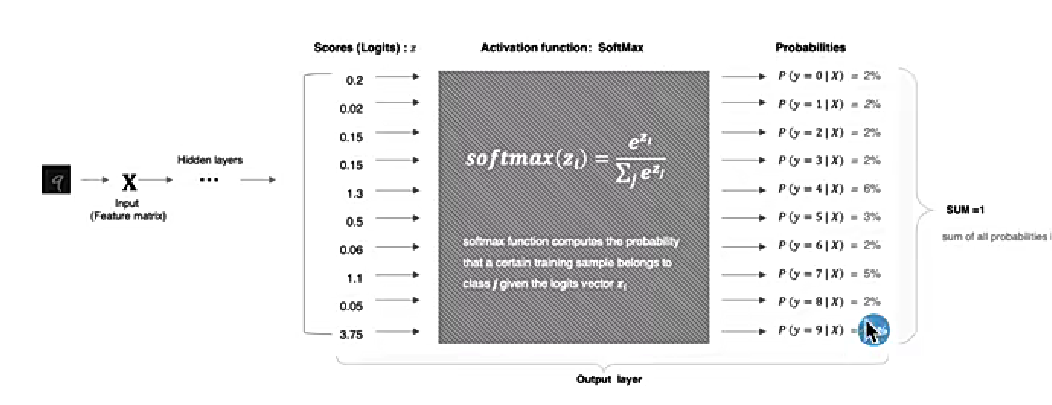
5、SoftMax
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展示出来。
6、如何选择激活函数

3、参数初始化
1、bias偏置初始化
直接初始化为0
2、weight权重初始化
1、随机初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数w进行初始化
2、标准初始化
权重参数初始化从区间均匀随机取值,即在(-1/根号d/,根号d/1)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量
3、Xavier初始化
该方法的基本思想是各层的激活值和梯度的方差在传播过程中保持一致,也叫做Glorot初始化,在tf.keras中实现方法有两种:
- 正态化Xavier初始化

- 标准化Xavier初始化

4、He初始化
he初始化,也称为Kaiming初始化,他的基本思想是正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变
- 正太化的he初始化

- 标准化的he初始化

4、神经网络构建
1、通过Sequential构建
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers# 定义一个Sequential模型,包含3层
model = keras.Sequential([# 第一层:激活函数为relu,权重初始化为he_normallayers.Dense(3, activation="relu", kernel_initializer="he_normal", name="layer1", input_shape=(3, )),# 第二层:激活函数为relu,权重初始化为he_normallayers.Dense(2, activation="relu", kernel_initializer="he_normal", name="layer2"),# 第三次:激活函数为sigmoid,权重初始化和he_normallayers.Dense(2, activation="sigmoid", kernel_initializer="he_normal", name="layer3")
])model.summary()
2、function api方式构建

# 使用function api方式构建神经网络
import tensorflow as tf
# 定义模型的输入
inputs = tf.keras.Input(shape=(3,), name = 'input')
# 第一层:激活函数为relu,其他默认
x = tf.keras.layers.Dense(3, activation='relu', name='layer1')(inputs)
# 第二层:激活函数为relu,其他默认
x = tf.keras.layers.Dense(2, activation='relu', name='layer2')(x)
# 第三次:输出层,激活函数为sigmoid
outputs = tf.keras.layers.Dense(2, activation='sigmoid', name='layer3')(x)
# 使用Model创建模型
model = tf.keras.Model(inputs = inputs, outputs=outputs, name='my_model')
model.summary()
3、Model子类构建方式
# 使用Model子类的方式构建神经网络
import tensorflow as tfclass MyModel(tf.keras.Model):# 在init方法中定义网络的层结构def __init__(self):super(MyModel, self).__init__()# 第一层:激活函数为relu,权重初始化为he_normalself.layer1 = tf.keras.layers.Dense(3, activation='relu', kernel_initializer='he_normal', name='layer1', input_shape=(3,))# 第二层:激活函数为relu,权重初始化为he_normalself.layer2 = tf.keras.layers.Dense(2, activation='relu', kernel_initializer='he_normal', name='layer2')# 第三次:激活函数为sigmoid,权重初始化为he_normalself.layer3 = tf.keras.layers.Dense(2, activation='sigmoid', kernel_initializer='he_normal', name='layer3')# 在call方法中完成前向传播def call(self, inputs):x = self.layer1(inputs)x = self.layer2(x)return self.layer3(x)# 实例化model
model = MyModel()
# 设置一个输入调用模型(否则无法使用summary方法)
x = tf.ones((1, 3))
y = model(x)
model.summary()
5、神经网络的优缺点
