【Python爬虫详解】第二篇:HTML结构的基本分析
在上一篇文章中,我们介绍了网络爬虫的基本概念、发展历程和工作原理。要进行有效的网页内容爬取,首先需要理解我们要爬取的对象 —— 网页的基本结构和语法。网页本质上是由HTML代码构成的,爬虫程序需要从HTML中提取我们需要的信息。因此,理解HTML结构是开发高效爬虫的基础和前提。本文将带你快速了解HTML的基本知识,为后续的数据提取和解析打下坚实基础。
HTML简介:网页的骨架
HTML(HyperText Markup Language,超文本标记语言)是构建网页的标准语言。它通过一系列标签来定义网页的结构和内容,告诉浏览器如何展示信息。HTML不是一种编程语言,而是一种标记语言,它使用标签来描述网页的结构。
对于爬虫开发者来说,理解HTML结构的意义在于:爬虫实际上是在模拟浏览器获取网页后,从HTML代码中提取有价值的信息。如果不了解HTML的基本结构,就很难精确定位并提取我们需要的数据。
HTML文档的基本结构
一个标准的HTML文档通常包含以下几个部分:
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>页面标题</title><link rel="stylesheet" href="style.css"><script src="script.js"></script>
</head>
<body><header><h1>这是页面的主标题</h1></header><main><p>这是一个段落。</p><div class="content"><h2>这是一个子标题</h2><p>这是更多的内容。</p></div></main><footer><p>这是页脚内容</p></footer>
</body>
</html>
让我们逐一分析这个HTML文档的结构:
-
DOCTYPE声明:
<!DOCTYPE html>告诉浏览器这是一个HTML5文档。 -
html元素:
<html>是文档的根元素,包含整个HTML文档。 -
head元素:
<head>包含文档的元数据,如字符集、标题、外部资源链接等。<meta charset="UTF-8">定义文档的字符编码<title>定义网页标题,会显示在浏览器标签上<link>用于引入外部CSS文件<script>用于引入JavaScript文件
-
body元素:
<body>包含文档的可见内容,是爬虫主要关注的部分。<header>定义页面的头部区域<main>定义页面的主要内容区域<footer>定义页面的底部区域
HTML元素的基本语法
HTML元素(也称为标签)是构建网页的基本单位。理解HTML元素的语法对于爬虫开发至关重要。
基本结构
一个HTML元素通常由以下部分组成:
<标签名 属性名="属性值">内容</标签名>
例如:
<a href="https://www.baidu.com">这是一个跳转到百度的链接</a>
这里:
a是标签名,表示这是一个超链接href是属性名,"https://www.baidu.com"是属性值,它们共同定义了链接的目标地址这是一个跳转到百度的链接是元素的内容,会显示在页面上
自闭合标签
有些标签不需要包含内容,它们是自闭合的:
<img src="image.jpg" alt="图片描述">
<input type="text" name="username">
<br>
<hr>
嵌套规则
HTML元素可以嵌套,形成树状结构:
<div class="container"><h1>主标题</h1><p>这是<strong>重要</strong>内容</p>
</div>
嵌套应遵循先开后闭的原则,不正确的嵌套可能导致解析错误:
<!-- 错误的嵌套 -->
<p><strong>这是错误的</p></strong><!-- 正确的嵌套 -->
<p><strong>这是正确的</strong></p>
常见HTML元素分类
为了更好地理解网页结构,我们可以将HTML元素分为不同类别:
1. 结构元素
这些元素用于定义网页的整体结构:
<html>,<head>,<body><header>,<nav>,<main>,<section>,<article>,<aside>,<footer>
2. 块级元素
块级元素会占据一整行空间,并自动在前后添加换行:
<div>- 通用块容器<p>- 段落<h1>到<h6>- 标题<ul>,<ol>,<li>- 列表<table>,<tr>,<th>,<td>- 表格
3. 内联元素
内联元素只占据必要的空间,不会自动换行:
<span>- 通用内联容器<a>- 超链接<img>- 图片<strong>,<em>- 强调文本<br>- 换行
4. 表单元素
用于收集用户输入的元素:
<form>- 表单容器<input>- 输入字段<textarea>- 多行文本输入<select>,<option>- 下拉选择<button>- 按钮
HTML属性:元素的特性
HTML元素可以包含各种属性,用于提供额外信息或修改元素行为。对于爬虫来说,属性往往是定位和提取数据的关键。
通用属性
所有HTML元素都可以使用的属性:
id- 元素的唯一标识符class- 元素的类名,用于样式和JavaScriptstyle- 内联CSS样式title- 元素的提示文本
示例:
<div id="main-content" class="content-box" style="color: blue;" title="主要内容">这是页面的主要内容
</div>
特定元素的属性
不同元素有特定的属性:
<a>的href属性 - 链接目标地址<img>的src属性 - 图片源文件<input>的type属性 - 输入类型<table>的border属性 - 表格边框
示例:
<a href="https://www.example.com">示例链接</a>
<img src="image.jpg" alt="示例图片">
<input type="text" name="username" placeholder="请输入用户名">
理解HTML文档的DOM树结构
当浏览器加载HTML文档时,会将其解析成DOM(Document Object Model)树,这是一种树状结构,表示文档中元素的层次关系。
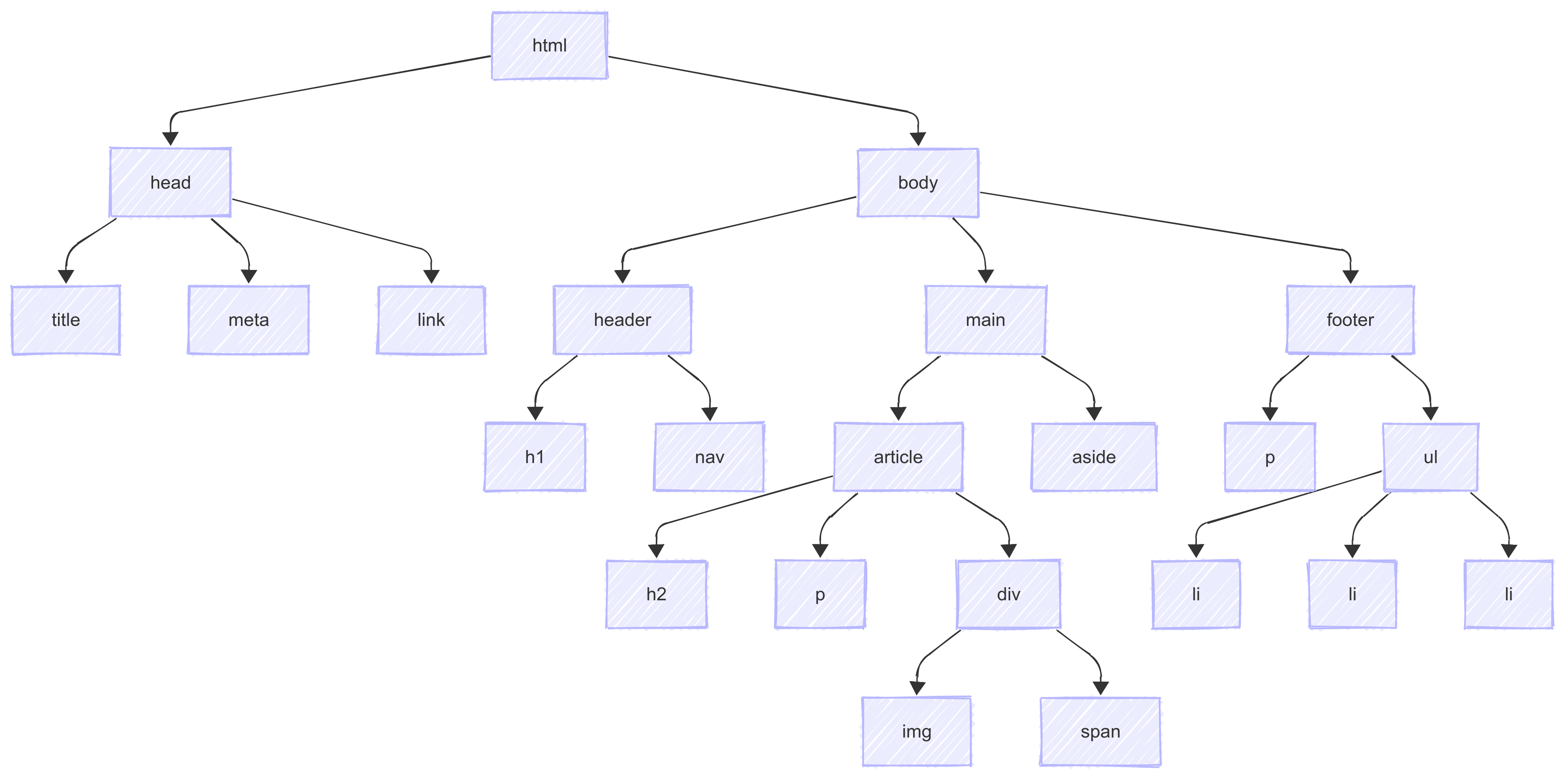
DOM树结构对爬虫非常重要,因为:
- 许多爬虫解析库(如BeautifulSoup)使用类似的树形结构来表示和操作HTML
- 导航和选择元素的方法(如XPath、CSS选择器)基于DOM树结构
- 理解元素间的层次关系有助于精确定位目标数据
在浏览器中检查HTML结构
浏览器的开发者工具是分析网页结构的利器,也是爬虫开发的必备工具。
如何打开开发者工具
- Chrome/Edge: 按F12或右键点击页面选择"检查"
- Firefox: 按F12或右键点击页面选择"查看元素"
- Safari: 启用开发者菜单后,点击"检查元素"
开发者工具的主要功能
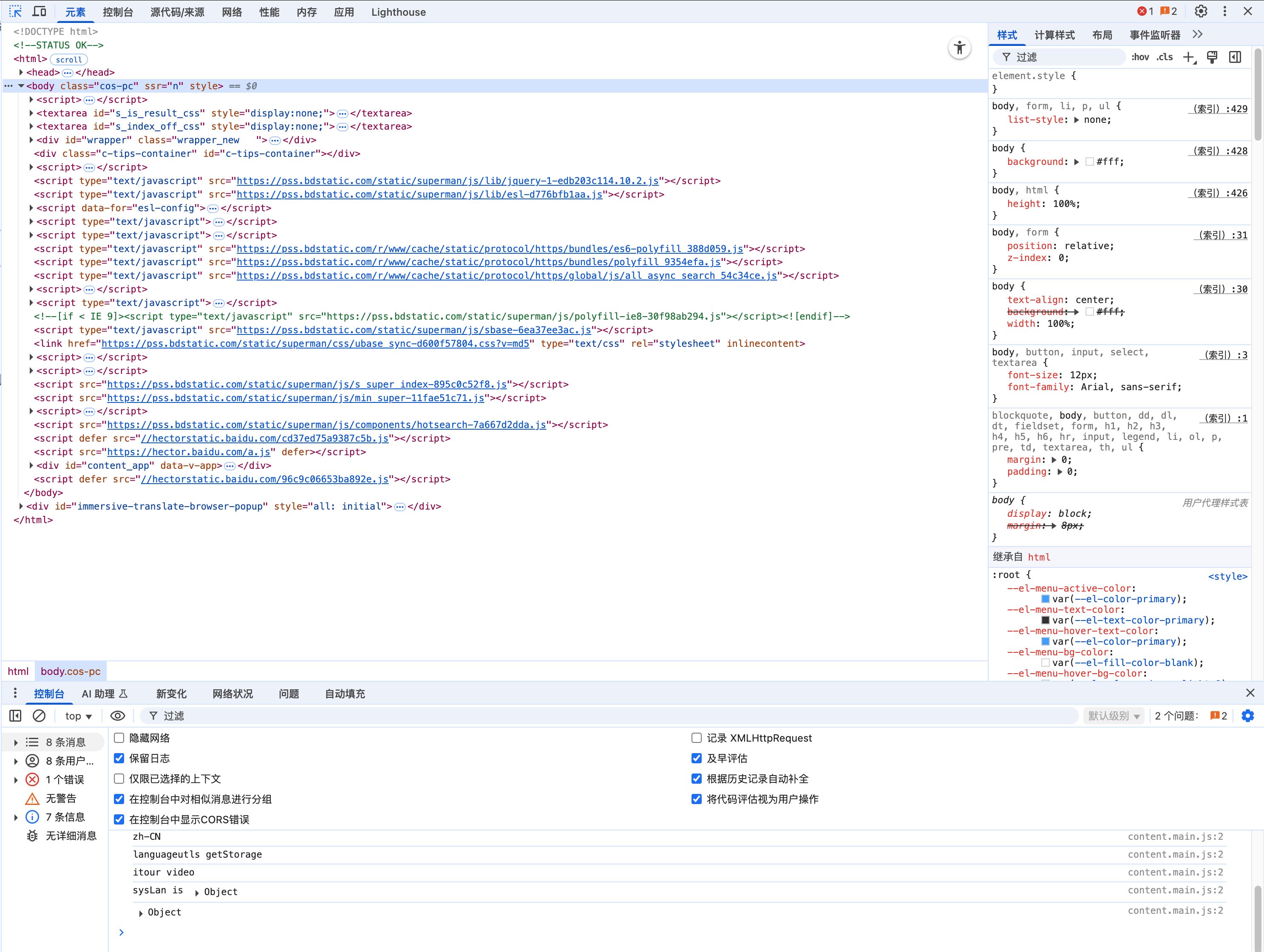
-
元素面板(Elements):显示当前页面的HTML结构,可以:
- 查看和编辑HTML
- 右键选择复制元素的选择器或XPath
- 高亮显示所选元素在页面中的位置
-
控制台(Console):JavaScript交互环境,可以:
- 执行JavaScript代码
- 查看网页错误和日志
-
网络面板(Network):监控网络请求,可以:
- 查看所有HTTP请求和响应
- 分析请求头、响应头和负载
- 了解资源加载时间和顺序
这些工具对爬虫开发特别有用,可以帮助我们:
- 分析网页结构,找到目标数据的位置
- 确定选择器或XPath表达式
- 检查网络请求,了解如何获取数据
数据提取的关键:选择器
为了从HTML中提取数据,爬虫需要使用选择器来定位元素。了解HTML中的两个关键属性对开发爬虫至关重要:
1. ID选择器
ID是元素的唯一标识符,在整个页面中应该是唯一的。使用#符号选择:
<div id="unique-element">这是唯一的元素</div>
CSS选择器:#unique-element
XPath://div[@id='unique-element']
2. Class选择器
Class用于对元素进行分组,多个元素可以共享同一个class。使用.符号选择:
<div class="product-item">产品1</div>
<div class="product-item">产品2</div>
CSS选择器:.product-item
XPath://div[@class='product-item']
3. 组合选择器
在实际爬取中,常常需要组合多种选择器来精确定位元素:
<div class="container"><ul class="product-list"><li class="product-item" data-id="1"><h3 class="product-title">iPhone</h3><span class="price">5999元</span></li></ul>
</div>
CSS选择器:.product-list .product-item .price
XPath://ul[@class='product-list']/li[@class='product-item']/span[@class='price']
HTML特殊字符和实体
HTML使用一些特殊字符来表示特定含义,例如<、>用于标签。如果要在内容中显示这些字符,需要使用HTML实体:
| 字符 | 实体名称 | 实体编号 |
|---|---|---|
| < | < | < |
| > | > | > |
| & | & | & |
| " | " | " |
| ’ | ' | ' |
| 空格 |
爬虫解析HTML时,库通常会自动处理这些实体,但了解它们有助于理解网页内容。
HTML的语义化
语义化HTML使用合适的标签来表示内容的含义,而不仅仅是外观。这对爬虫非常有利,因为语义化标签可以更清晰地表达内容的结构和重要性。
非语义化示例:
<div class="header"><div class="title">网站标题</div>
</div>
<div class="content"><div class="article"><div class="article-title">文章标题</div><div class="article-text">文章内容</div></div>
</div>
语义化示例:
<header><h1>网站标题</h1>
</header>
<main><article><h2>文章标题</h2><p>文章内容</p></article>
</main>
语义化HTML对爬虫的好处:
- 更容易理解页面结构
- 可以基于标签本身的含义定位内容
- 减少对特定class和id的依赖
总结
本文我们介绍了HTML的基本结构和语法,包括:
- HTML文档的整体结构
- 元素的基本语法和嵌套规则
- 常见HTML元素的分类
- 属性的作用和用法
- DOM树结构的概念
- 浏览器开发者工具的使用
- 选择器的基本概念
- HTML实体和语义化
掌握这些HTML基础知识对爬虫开发至关重要。当我们需要从网页中提取特定数据时,首先要做的就是分析HTML结构,找到目标数据所在的位置,然后使用适当的选择器来定位和提取这些数据。
在下一篇文章中,我们将深入探讨如何编写自己的第一个爬虫程序。我们将学习爬虫程序的基本结构,包括发送请求、解析响应、提取数据和保存结果等核心步骤。我们还会提供实用的爬虫模板,帮助你快速开始自己的爬虫项目,并讨论常见的爬虫设计模式和最佳实践。
通过系统地学习HTML结构和爬虫技术,你将能够开发出高效、精准的网络爬虫,为数据分析和研究提供坚实的基础。
下一篇:【Python爬虫详解】第三篇:编写你的第一个爬虫程序