深度解析 PointNet:点云深度学习的开山之作
🔍 深度解析 PointNet:点云深度学习的开山之作
PointNet 是深度学习处理点云数据的里程碑式方法。它首次实现了对无序点集的端到端特征学习,并在分类与分割任务中均取得显著效果。本篇我们将从 数据结构、对称函数建模、变换不变性、局部全局特征融合 等核心思想出发,结合数学公式进行深入解析。
(论文地址:https://arxiv.org/abs/1612.00593)
1️⃣ 点云作为无序集合(Unordered Set)
设一个点云 P = { x 1 , x 2 , … , x n } ⊂ R d \mathcal{P} = \{ \mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_n \} \subset \mathbb{R}^d P={x1,x2,…,xn}⊂Rd,每个点 x i ∈ R d \mathbf{x}_i \in \mathbb{R}^d xi∈Rd(一般为三维坐标 ( x , y , z ) (x, y, z) (x,y,z),可附加颜色、法向等属性)。
问题核心: 神经网络需要对输入顺序不敏感,即满足置换不变性(Permutation Invariance)。
2️⃣ 函数建模:对称函数的逼近理论
PointNet 要学习一个函数:
f : P → R k , P ⊂ ( R d ) n f : \mathcal{P} \to \mathbb{R}^k, \quad \mathcal{P} \subset (\mathbb{R}^d)^n f:P→Rk,P⊂(Rd)n
其中 f f f 需要满足:
f ( x 1 , … , x n ) = f ( x π ( 1 ) , … , x π ( n ) ) ∀ π ∈ S n f(\mathbf{x}_1, \ldots, \mathbf{x}_n) = f(\mathbf{x}_{\pi(1)}, \ldots, \mathbf{x}_{\pi(n)}) \quad \forall \pi \in S_n f(x1,…,xn)=f(xπ(1),…,xπ(n))∀π∈Sn
这是一个典型的置换不变函数问题。作者提出了如下结构性假设:
f ( { x 1 , … , x n } ) ≈ γ ( MAX i = 1 , … , n h ( x i ) ) f(\{\mathbf{x}_1, \ldots, \mathbf{x}_n\}) \approx \gamma \left( \underset{i=1,\ldots,n}{\text{MAX}} \ h(\mathbf{x}_i) \right) f({x1,…,xn})≈γ(i=1,…,nMAX h(xi))
- h : R d → R K h: \mathbb{R}^d \to \mathbb{R}^K h:Rd→RK:通过 MLP 实现的点特征提取
- M A X MAX MAX:对所有点做维度级的最大池化,提取全局特征
- γ : R K → R k \gamma: \mathbb{R}^K \to \mathbb{R}^k γ:RK→Rk:用于后续分类或回归
📌 MAX 操作是关键,因为它是一个对称函数,天然满足输入顺序不变性。
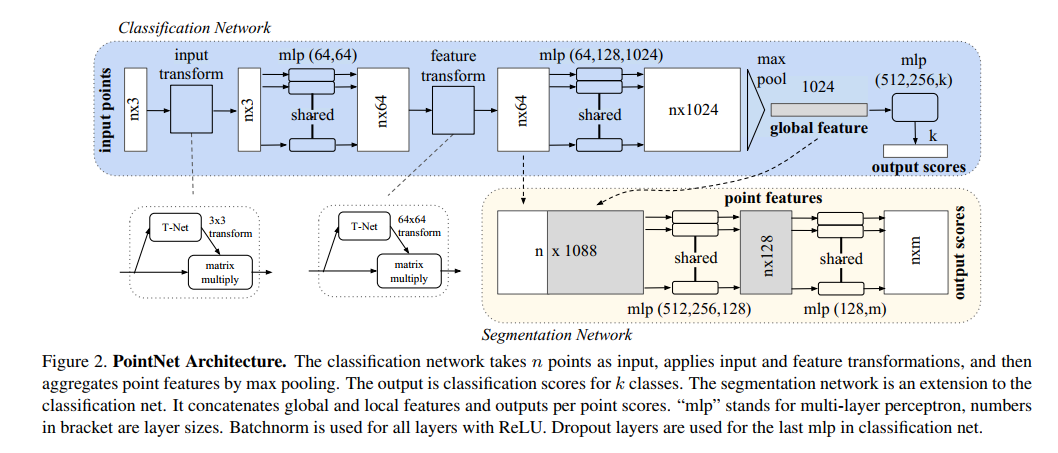
3️⃣ 空间变换不变性(Transformation Invariance)
点云中存在各种刚性变换(旋转、平移),PointNet 通过 T-Net 子网络预测一个变换矩阵 T T T,对输入点进行配准(alignment):
x i ′ = T x i \mathbf{x}_i' = T \mathbf{x}_i xi′=Txi
T-Net 的结构类似于主干网络,由共享 MLP + Max Pooling + FC 层组成,输出一个 d × d d \times d d×d 的矩阵(常为 3 × 3 3 \times 3 3×3)。此外,为了增强训练稳定性,在损失函数中引入正交性正则项:
L reg = ∥ I − T T ⊤ ∥ F 2 L_{\text{reg}} = \| I - TT^\top \|_F^2 Lreg=∥I−TT⊤∥F2
约束 T T T 接近于正交矩阵,避免信息丢失。
4️⃣ 全局与局部特征融合(用于分割任务)
对于点云分割,需要输出每个点的标签,因此不能只用全局特征。
PointNet 的做法是:
- 每个点:用共享 MLP 得到 h ( x i ) ∈ R K h(\mathbf{x}_i) \in \mathbb{R}^K h(xi)∈RK
- 整体点云:用 max pooling 得到全局特征 g = max i h ( x i ) \mathbf{g} = \max_i h(\mathbf{x}_i) g=maxih(xi)
- 每个点再拼接全局特征:
f i = MLP ( [ h ( x i ) , g ] ) \mathbf{f}_i = \text{MLP}([h(\mathbf{x}_i), \mathbf{g}]) fi=MLP([h(xi),g])
这样,每个点的最终表示同时融合了 局部几何 和 整体语义,非常适合进行点级任务如语义分割或法向预测。
5️⃣ 整体架构小结
- 输入: n × d n \times d n×d 点云数据
- 特征提取:对每个点施加共享的 MLP
- 特征汇聚:max pooling 得到全局描述
- 分类任务:用全局特征进行 MLP 分类
- 分割任务:全局特征拼接回每点,继续 MLP 分类
- T-Net:对坐标和特征做空间对齐
6️⃣ 理论保障:函数逼近能力
PointNet 在论文中还证明了:
任何一个对称连续函数 f f f 都可以被上述结构近似:
f ( { x 1 , … , x n } ) ≈ γ ( max i h ( x i ) ) f(\{ \mathbf{x}_1, \ldots, \mathbf{x}_n \}) \approx \gamma \left( \max_i h(\mathbf{x}_i) \right) f({x1,…,xn})≈γ(imaxh(xi))
这从理论上保证了 PointNet 的表达能力。
📈 实验回顾
- 分类任务(ModelNet40): PointNet 与 volumetric CNN 持平甚至略优,且参数少、速度快
- 语义分割(ShapeNet Part, ScanNet): 在多个类上表现优秀,能精确分辨零件
- 法向预测: 能重建空间几何细节,展示了其理解局部结构的能力
✍️ 总结:为什么 PointNet 值得学?
| 特性 | 描述 |
|---|---|
| 无序输入处理 | 使用对称函数结构(max pooling)解决输入顺序问题 |
| 几何变换不变 | T-Net 实现空间对齐,并有正则稳定优化 |
| 局部全局融合 | 特征拼接机制支持语义分割等复杂任务 |
| 理论基础 | 提供置换不变函数的逼近证明 |
一句话总结: PointNet 是一个结构极其优雅、理论充分、实验扎实的 3D 点云深度学习模型,具有里程碑意义。