线性回归之正则化(regularization)
文章目录
- 机器学习中的"防过拟合神器":正则化全解析
- 1. 正则化:不只是"规矩"那么简单
- 1.1 鲁棒性案例说明
- 2. L1正则化:冷酷的特征选择器
- 3. L2正则化:温柔的约束者
- 4. L1 vs L2:兄弟间的较量
- 5. 正则化的超参数调优
- 6. 正则化的数学直觉
- 7. 常见误区
- 8. 总结
机器学习中的"防过拟合神器":正则化全解析
1. 正则化:不只是"规矩"那么简单
-
想象一下,你正在教一个特别勤奋但有点死板的学生学习数学。这个学生能把所有例题背得滚瓜烂熟,但遇到稍微变化的新题目就束手无策——这就是机器学习中的**过拟合(Overfitting)**现象。
-
正则化(Regularization)就是给这个"过于勤奋"的模型制定一些"规矩",防止它过度记忆训练数据中的噪声和细节,从而提高泛化能力。简单说,正则化就是在损失函数中额外添加一个惩罚项,让模型参数不要变得太大。
-
正则化就是防止过拟合,增加模型的鲁棒性robust。鲁棒性调优就是让模型拥有更好的鲁棒性,也就是让模型的泛化能力和推广能力更加的强大。
1.1 鲁棒性案例说明
- 下面两个式子描述同一条直线那个更好?
0.5 x 1 + 0.4 x 2 + 0.3 = 0 5 x 1 + 4 x 2 + 3 = 0 0.5x_1+0.4x_2+0.3=0 \\ 5x_1+4x_2+3=0 0.5x1+0.4x2+0.3=05x1+4x2+3=0 - 第一个更好,因为下面的公式是上面的十倍,当w越小公式的容错的能力就越好。因为把测试集带入公式中如果测试集原来是100在带入的时候发生了一些偏差,比如说变成了101,第二个模型结果就会比第一个模型结果的偏差大的多。公式中
y ^ = w T x \hat y=w^Tx y^=wTx当x有一点错误,这个错误会通过w放大从而影响z。但w也不能太小,当w太小时正确率就无法保证,就没法做分类。想要有一定的容错率又要保证正确率就要由正则项来决定。 - 所以正则化(鲁棒性调优)的本质就是牺牲模型在训练集上的正确率来提高推广能力,W在数值上越小越好,这样能抵抗数值的扰动。同时为保证模型的正确率W又不能极小。故而人们将原来的损失函数加上一个惩罚项,这里面损失函数就是原来固有的损失函数,比如回归的话通常是MSE,然后在加上一部分惩罚项来使得计算出来的模型W相对小一些来带来泛化能力。
- 常用的惩罚项有L1正则项或者L2正则项
L 1 = ∑ i = 0 m ∣ w i ∣ L 2 = ∑ i = 0 m w i 2 L_1=\sum_{i=0}^m|w_i| \\ L_2=\sum_{i=0}^m w_{i}^{2} L1=i=0∑m∣wi∣L2=i=0∑mwi2 - L1和L2正则的公式数学里面的意义就是范数,代表空间中向量到原点的距离
2. L1正则化:冷酷的特征选择器
- L1正则化,又称Lasso回归,它在损失函数中添加的是模型权重的绝对值和:
损失函数 = 原始损失 + λ * Σ|权重|
特点:
-
倾向于产生稀疏解(许多权重精确为0)
-
自动执行特征选择
-
对异常值敏感
-
在零点不可导
-
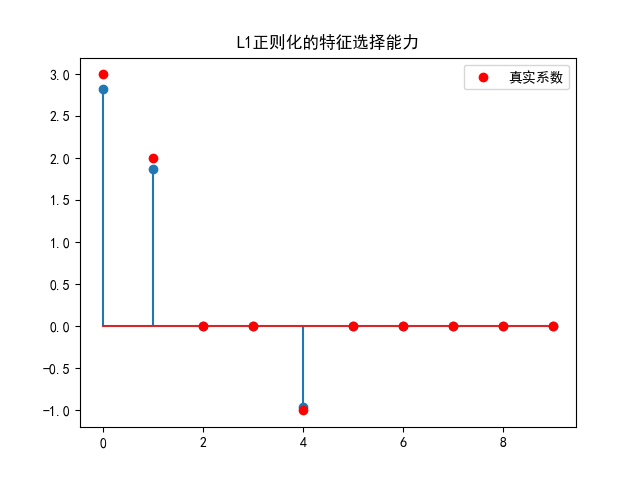
L1正则化自动选择重要特征:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso# 设置支持中文的字体
# 使用SimHei字体,这是一种常见的中文字体,能够正确显示中文字符
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示问题,确保在图表中正确显示负号
plt.rcParams['axes.unicode_minus'] = False# 生成一些数据,其中只有3个特征真正有用
# 设置随机种子以确保结果可重复
np.random.seed(42)
# 生成100个样本,每个样本有10个特征的随机数据
X = np.random.randn(100, 10)
# 定义真实系数,只有前3个和第5个特征有用
true_coef = [3, 2, 0, 0, -1, 0, 0, 0, 0, 0]
# 生成目标变量y,通过线性组合X和true_coef,并添加一些噪声
y = np.dot(X, true_coef) + np.random.normal(0, 0.5, 100)# 使用L1正则化(Lasso回归)
# 创建Lasso模型实例,设置正则化参数alpha
lasso = Lasso(alpha=0.1)
# 使用生成的数据拟合模型
lasso.fit(X, y)# 查看学到的系数
# 使用stem图显示Lasso模型学到的系数
plt.stem(range(10), lasso.coef_)
# 在同一图表上绘制真实系数,用红色圆圈标记
plt.plot(range(10), true_coef, 'ro', label='真实系数')
# 添加图例
plt.legend()
# 设置图表标题
plt.title('L1正则化的特征选择能力')
# 显示图表
plt.show()
- 你会惊讶地发现,Lasso几乎完美地识别出了哪些特征真正重要,哪些可以忽略!
3. L2正则化:温柔的约束者
- L2正则化,又称权重衰减(Weight Decay)或岭回归(Ridge Regression),它在损失函数中添加了模型权重的平方和作为惩罚项:
损失函数 = 原始损失 + λ * Σ(权重²)
其中λ是正则化强度,控制惩罚的力度。
特点:
- 使权重趋向于小而分散的值
- 对异常值不敏感
- 数学性质良好,总是可导
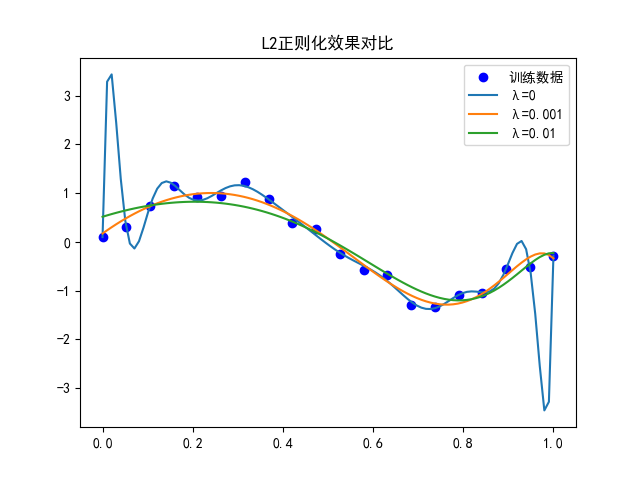
L2正则化在行动:
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt# 设置支持中文的字体
# 使用SimHei字体,这是一种常见的中文字体,能够正确显示中文字符
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示问题,确保在图表中正确显示负号
plt.rcParams['axes.unicode_minus'] = False# 生成一些带噪声的数据
np.random.seed(42)
X = np.linspace(0, 1, 20)
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.2, 20)# 准备不同阶数的多项式特征
X_test = np.linspace(0, 1, 100)
plt.scatter(X, y, color='blue', label='训练数据')# 对比不同正则化强度
for alpha in [0, 0.001, 0.01]:model = make_pipeline(PolynomialFeatures(15),Ridge(alpha=alpha))model.fit(X[:, np.newaxis], y)y_test = model.predict(X_test[:, np.newaxis])plt.plot(X_test, y_test, label=f'λ={alpha}')plt.legend()
plt.title('L2正则化效果对比')
plt.show()
- 运行这段代码,你会看到随着λ增大,曲线从过拟合(完美拟合噪声)逐渐变得平滑,更接近真实的sin函数形状。
4. L1 vs L2:兄弟间的较量
| 特性 | L1正则化 | L2正则化 |
|---|---|---|
| 惩罚项 | Σ | w |
| 解的性质 | 稀疏 | 非稀疏 |
| 特征选择 | 是 | 否 |
| 计算复杂度 | 高(需特殊优化) | 低 |
| 对异常值 | 敏感 | 不敏感 |
经验法则:
- 当特征很多且认为只有少数重要时 → 用L1
- 当所有特征都可能相关且重要性相当时 → 用L2
- 不确定时 → 用ElasticNet(两者结合)
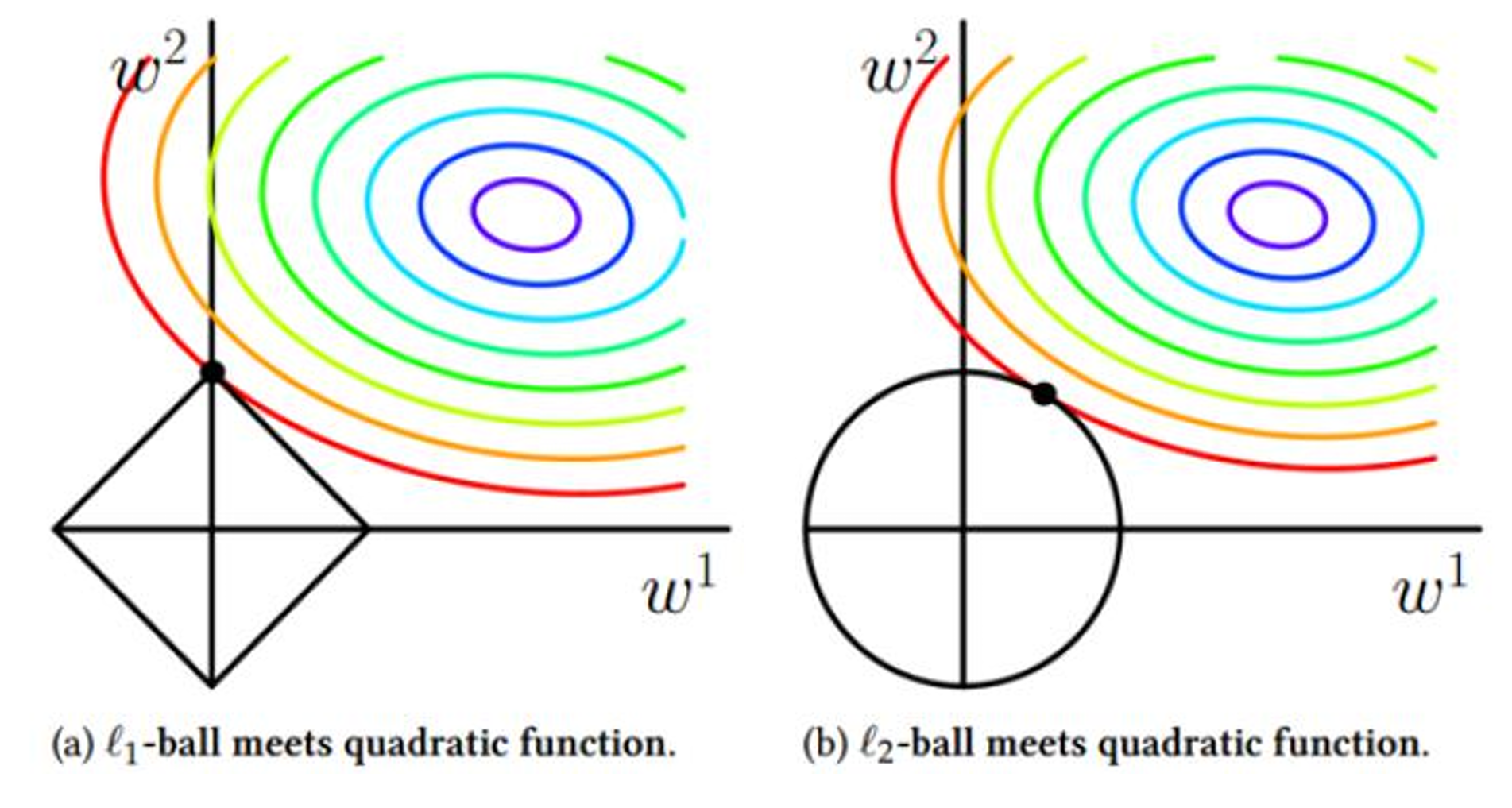
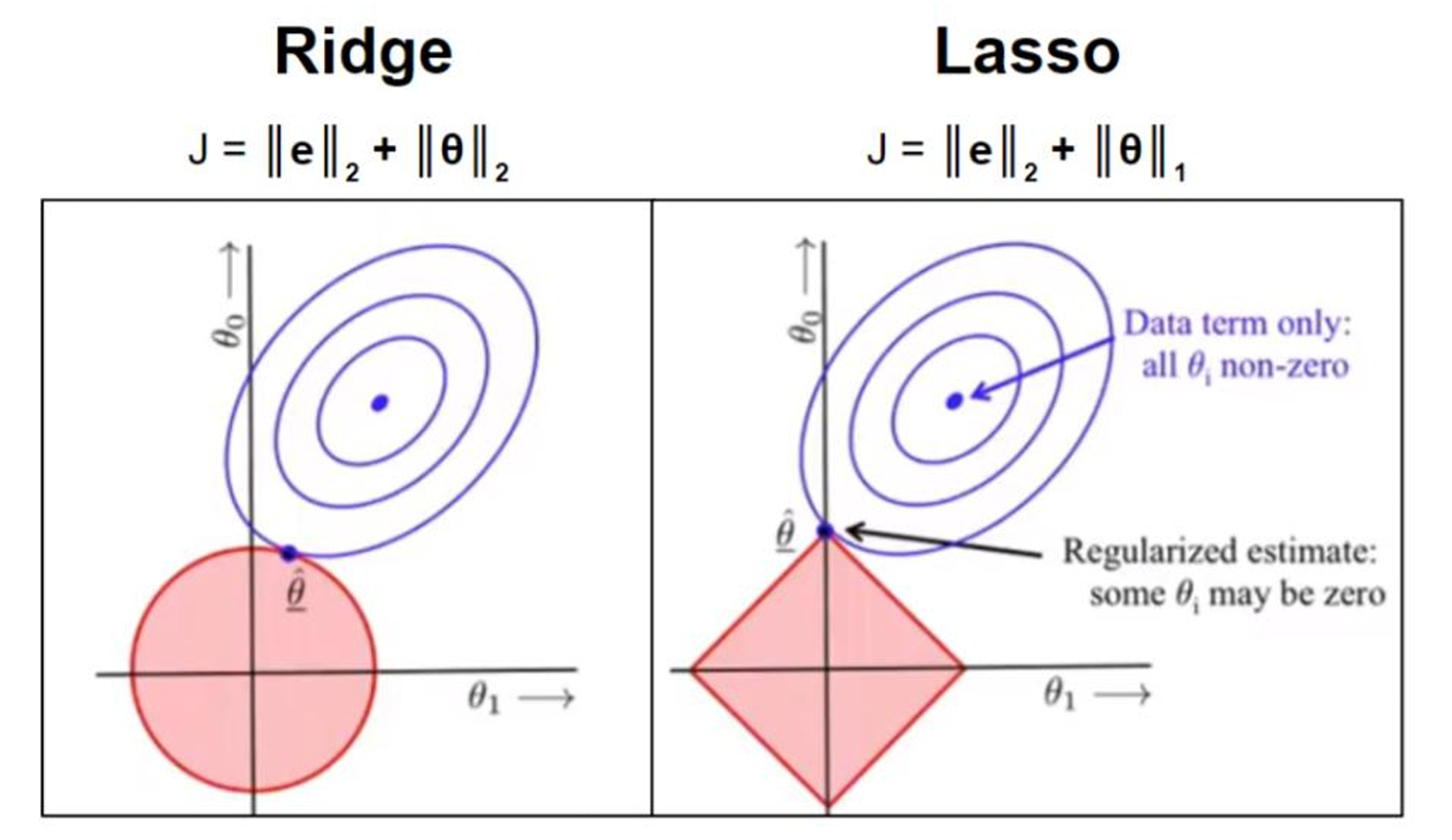
- L 1 L_1 L1更容易相交于坐标轴上,而 L 2 L_2 L2更容易相交于非坐标轴上。如果相交于坐标轴上,如图 L 1 L_1 L1就使得是 W 2 W_2 W2非0, W 1 W_1 W1是0,这个就体现出 L 1 L_1 L1的稀疏性。如果没相交于坐标轴,那 L 2 L_2 L2就使得W整体变小。通常为去提高模型的泛化能力 L 1 L_1 L1和 L 2 L_2 L2都可以使用。 L 1 L_1 L1的稀疏性在做机器学习的时候,可以帮忙去做特征的选择。
5. 正则化的超参数调优
选择正确的λ值至关重要:
- λ太大 → 欠拟合(模型太简单)
- λ太小 → 过拟合(模型太复杂)
可以使用交叉验证来寻找最佳λ:
from sklearn.linear_model import LassoCV# 使用LassoCV自动选择最佳alpha
lasso_cv = LassoCV(alphas=np.logspace(-4, 0, 20), cv=5)
lasso_cv.fit(X, y)print(f"最佳alpha值: {lasso_cv.alpha_}")
6. 正则化的数学直觉
为什么限制权重大小能防止过拟合?想象模型是一个画家:
- 没有正则化:画家可以用极其精细的笔触(大权重)来完美复制训练数据中的每个细节(包括噪声)
- 有正则化:画家被迫用更粗的笔触(小权重),不得不忽略一些细节,从而捕捉更一般的模式
7. 常见误区
误区:
- 认为正则化可以完全替代更多的训练数据
- 在所有特征上使用相同的正则化强度
- 忽略特征缩放(正则化对尺度敏感!
8. 总结
- 正则化就像给模型戴上的"紧箍咒",看似限制了模型的自由,实则让它更加专注和高效。记住,在机器学习中,有时候"约束"反而能带来"解放"——解放模型从训练数据的桎梏中解脱出来,获得更好的泛化能力。