【NLP 67、知识图谱】
你像即将到来的夏季一样鲜明,
以至于我这样寡淡的生命,
竟山崩般为你着迷
—— 25.4.18
一、信息 VS 知识

二、知识图谱
1.起源
于2012年5月17日被Google正式提出,初衷是为了提高搜索引擎的能力,增强用户的搜索质量以及搜索体验
在用户搜索问题时,直接给用户给出答案,将用户搜索到的“信息”直接转化为“知识”给用户显示
现在的大语言模型借助搜索引擎汇总信息,直接总结出知识汇报,这也是大语言模型可以代替搜索引擎的地方所在
2.定义
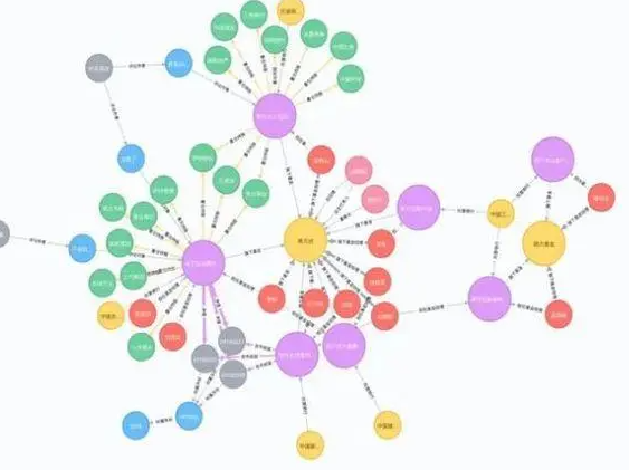
知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。存储一些结构化数据
现在的知识图谱已被用来泛指各种大规模的知识库
3.知识图谱里存的是什么
三元组是知识图谱的一种通用表示方式(互相相关的、足够多的三元组聚合在一起)
三种基本形态:
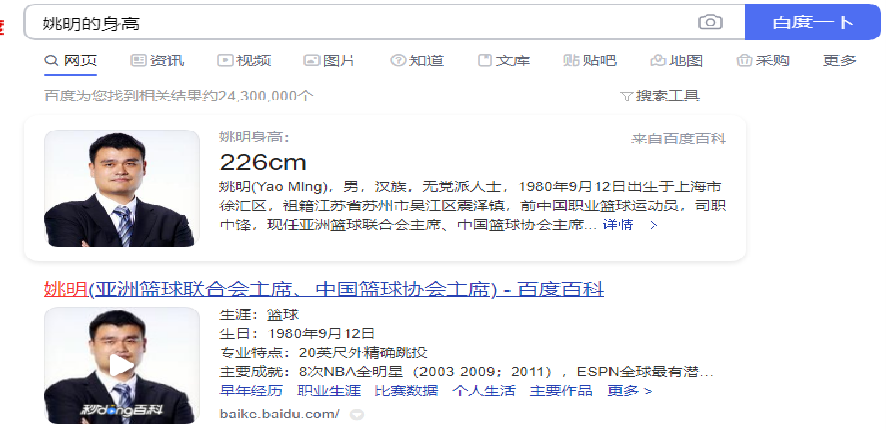
① 实体(head entity) - 关系(relation) - 实体(tail entity),例:姚明 – 妻子 – 叶莉
② 实体 - 属性 - 属性值,例:姚明 – 身高 – 226cm
③ 实体 - 标签 - 标签值,例:姚明 – 标签 – 运动员(为保持格式相似)
4.知识图谱的构建
Ⅰ、定义实体、属性、关系
如何决定哪些是实体,哪些是属性,哪些是关系?
—— 取决于图谱的使用方式和想要完成的任务
例:
关系查找:xx的老婆的父亲是谁?
A:xx(实体) B:xx的老婆(实体:即作为头也作为尾) C:xx的老婆的父亲
属性对比:xx的身高比yy高多少?
A:xx(实体) B:xx的身高(属性) C:yy(实体) D:yy的身高(属性)
【关系的查找和跳转】:属性值无法作为头实体出现,因为涉及到了实体的跳转
【两种属性的比较】:如果任务不需要实体的跳转:也可以用实体 - 属性 - 属性值
Ⅱ、体系架构
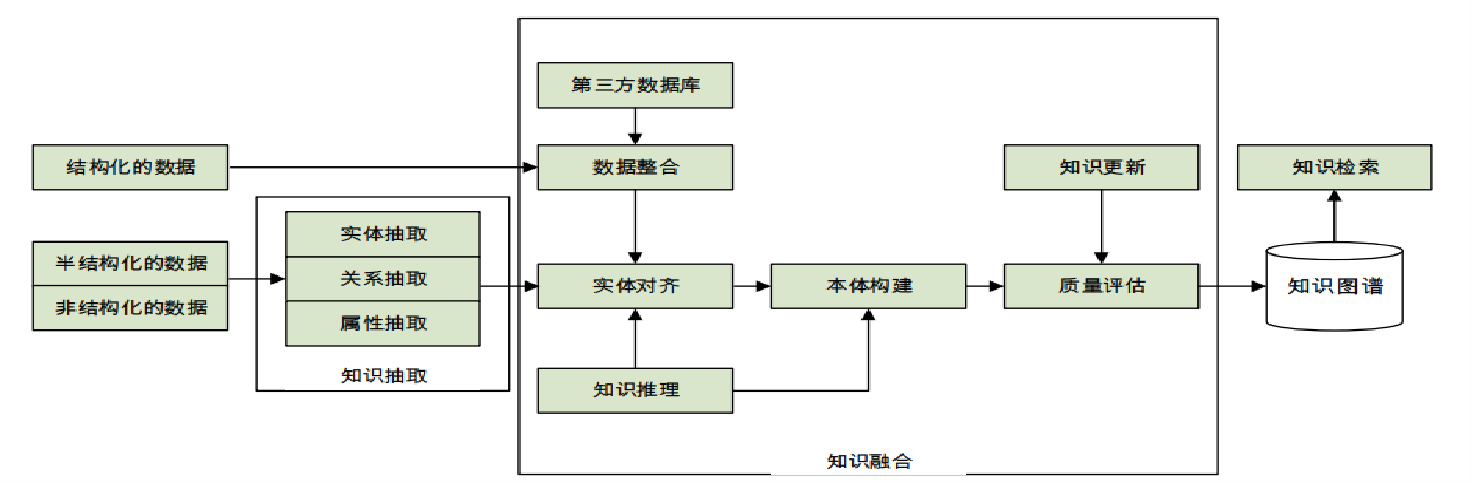
数据来源(多个三元组):① 结构化的数据、② 半/非结构化的数据(从文本中进行知识抽取)
Ⅲ、关键技术
① 知识抽取:非结构化 —> 结构化(实体抽取、关系抽取、属性抽取)
② 知识融合:消歧提升数据质量
③ 知识推理:挖掘扩充或补全数据(对于知识的一种补充)
④ 知识表示:向量化
三、知识挖掘 / 抽取
面向非结构化数据,通过自动化的技术抽取出可用的知识单元
① 实体抽取 ② 关系抽取 ③ 属性抽取
1.实体抽取 NER
实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识库的质量。
命名实体识别:① 基于规则和词典的方法 ② 基于机器学习的模型预测方法(序列标注问题)
2.关系抽取
Ⅰ、限定领域关系抽取
关系类型有限,已知
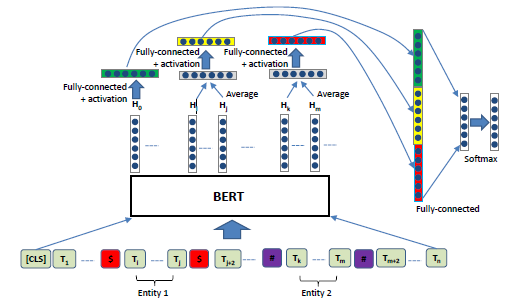
pipeline:① 传入一段文本,对这段文本做序列标注,找到文本中所有的实体;② 将这段文本和识别出的任意两个指定实体同时传入文本分类模型,得到这两个实体基于这段文本的关系;计算过程:文本和两个指定实体过Bert后得到三个向量,第一个向量是整体文本的信息;第二个向量是第一个指定实体的信息;第三个向量是第二个指定实体的信息;三个向量求平均,再接softMax层做分类;向模型强调了两个指定实体的信息
联合训练:联合训练是一种将实体识别和关系分类在一个统一框架内同时进行的技术,能更好地捕捉两者之间的相互作用,有效提高抽取的准确性和效率;通过建立统一的模型,同时对实体和关系进行建模,在训练过程中让实体识别和关系分类两个任务共享参数或特征表示,使得它们能够相互影响、相互促进。
Rbert:relation bert
![]()
Ⅱ、开放领域关系抽取
基于纯序列标注任务做 BIO标注
subject 实体1
predict 关系
object 实体2

Ⅲ、远程监督
通过知识图谱中的三元组数据回标语料
图谱中:姚明 —— 身高 —— 226cm
语料中:身高226cm的姚明被称为小巨人……姚明凭借226cm的身高优势……
将文本标记为指定关系类别,用于训练
3.属性抽取
实体的属性可以看成是实体与属性值之间的一种名称性关系
因此可以将实体属性的抽取问题转换为关系抽取问题
可以借鉴大部分关系抽取的方法
4.知识融合
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合
① 实体对齐 ② 实体消歧 ③ 属性对齐
Ⅰ、实体对齐
实体对齐:将不同来源的知识认定为真实世界的同一实体
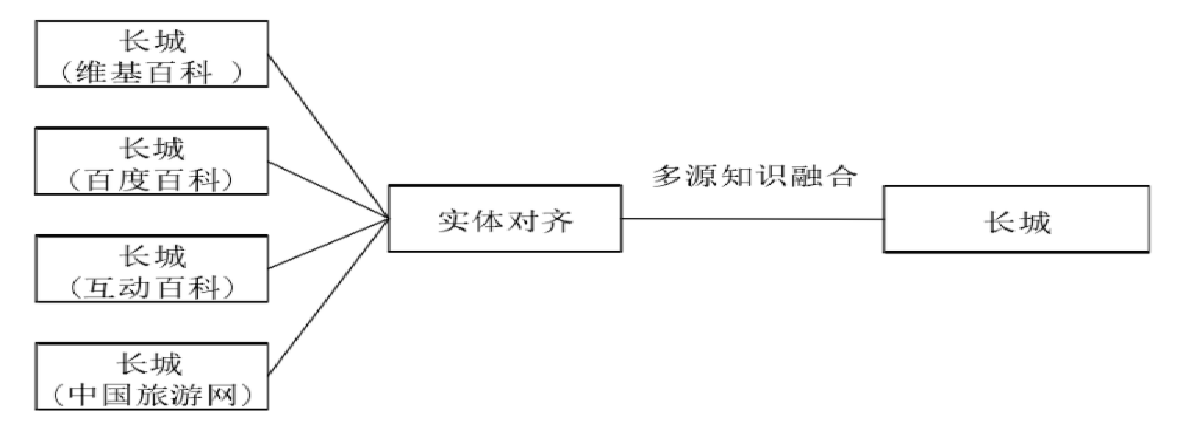
对比依据不同实体所包含的属性之间的相似度,来判断实体是否为同一实体
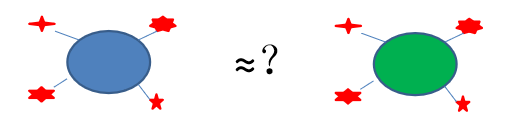
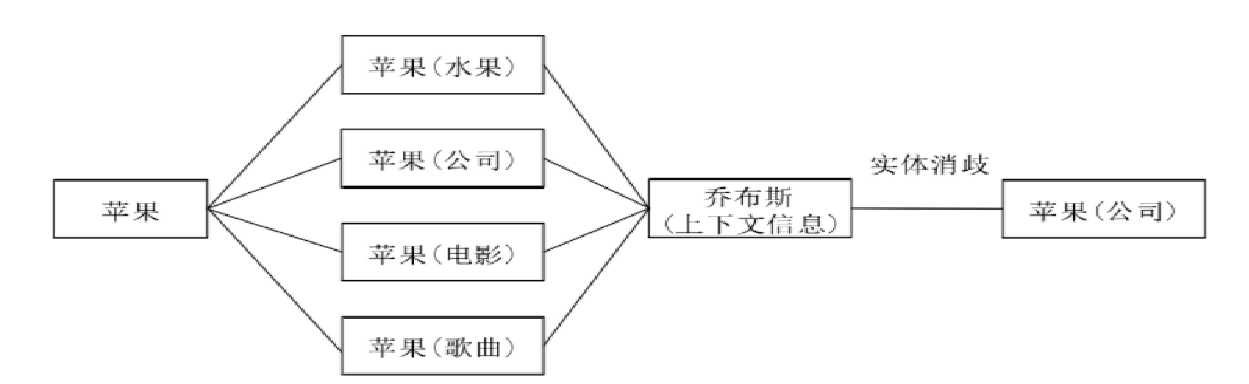
Ⅱ、实体消歧
实体消歧:将同一名称但指代不同事物的实体区分开
Ⅲ、属性对齐
属性对齐:不同数据源对于实体属性的记录可能使用不同的词语
x度百科:姚明 - 生日 - 1980年9月12日
搜x百科:姚明 - 出生日期 - 1980年9月12日
wxkx百科:姚明 - 出生年月 - 1980年9月12日
使用属性名和属性值做相似度计算
四、知识推理
1.深入挖掘
在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库
基于规则 + 句法
传递性:A - 儿子 - B,B - 儿子 - C, A - ? - C
实例性:A - 是 - B,B 属于 C,A - ? - C
2.知识补全
基于模型的知识补全
给出两个实体,推断其关系:h + r -> t, h + t -> r , (h, r, t) -> {0, 1}
相关论文 KG-Bert
五、知识表示
将知识图谱中的实体,关系,属性等转化为向量
利用向量间的计算关系,反映实体间的关联性
TransE:对于三元组(h, r, t) 学习其向量表示lh lr lt 使其满足 lh + lr ≈ lt
知识表示 —— 融合文本
融合文本的知识表示
将文本表示和知识图谱中的实体关系表示放入同一个空间
使得学习到的实体表示可以在文本相关的任务中使用
