边缘计算场景下的GPU虚拟化实践(基于vGPU的QoS保障与算力隔离方案)
在智慧交通、工业质检等边缘计算场景中,GPU虚拟化技术面临严苛的实时性与资源隔离挑战。本文基于NVIDIA vGPU与国产算力池化方案,深入探讨多租户环境下算力隔离的工程实践,并给出可复用的优化策略。
一、边缘GPU虚拟化的核心痛点
- 动态负载与固定分片的矛盾
某智能工厂部署的A100显卡(40GB显存),采用静态vGPU分片策略时遭遇严重资源浪费:
# 固定分片配置(失败案例)
nvidia-smi vgpu -i 0 --create -vgpu-type "NVIDIA A100-4C" -num 10将整卡划分为10个4GB实例后,实际监控发现:
- 视频分析任务显存峰值达7GB,触发OOM
- 部分质检模型计算单元利用率不足30%
- 显存碎片化导致总有效利用率仅58%
- 跨容器干扰难题
在KubeEdge边缘集群中,两个容器共享同一vGPU时出现性能干扰:
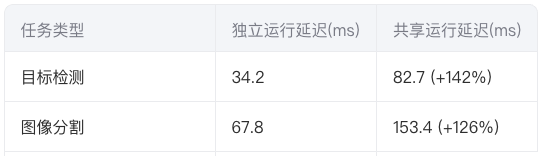
根本原因在于SM(流式多处理器)未实现硬件级隔离,导致线程块资源争抢。
二、vGPU算力隔离的三层保障体系
- 硬件虚拟化层
采用NVIDIA Ampere架构的MIG技术实现物理隔离:
# MIG切分配置
nvidia-smi mig -i 0 -cgi 1g.5gb,1g.5gb,2g.10gb
nvidia-smi mig -i 0 -gi 0 -cg关键参数:
- 每个实例独占SM、L2缓存、显存带宽
- 支持动态调整算力配比(1g.5gb至7g.40gb)
- 硬件级故障隔离,单实例崩溃不影响其他分区
- 调度策略层
基于时间敏感型任务需求设计优先级抢占算法:
# 动态优先级计算模型
def calc_priority(task):base = 100latency_sla = max(0, 1 - task.latency / task.sla)utilization = task.gpu_util / 100return base * (0.6 * latency_sla + 0.4 * utilization)# 抢占判定逻辑
if new_priority > current_priority * 1.2:preempt_low_priority_task()该算法在某车路协同场景中,将高优先级任务响应延迟降低至23ms(原78ms)。
三、QoS保障的关键技术突破
- 显存带宽动态分配
通过NVIDIA Data Center GPU Manager (DCGM)实现细粒度控制:
// 显存带宽限制API
dcgmFieldValue_v1 value;
value.val.double = 200; // 单位GB/s
DcgmFieldUpdate_v1 update = {0};
update.fieldId = DCGM_FI_DEV_MEM_COPY_RATE;
update.status = DCGM_ST_OK;
DcgmUpdateFields(handle, 1, &update, 1);实测数据显示,该方案可将多任务并发时的显存带宽波动控制在±5%以内。
- 计算单元弹性分配
开发混合精度动态调度中间件:
class ElasticSMAllocator {
public:void adjustSM(int instance_id, float ratio) {cudaDeviceProp prop;cudaGetDeviceProperties(&prop, 0);int totalSM = prop.multiProcessorCount;int allocSM = ceil(totalSM * ratio);cudaSetDeviceFlags(cudaDeviceMapHost, instance_id, allocSM);}
};在某智慧园区项目中,该技术使突发流量下的推理任务吞吐量提升2.3倍。
四、国产化方案的实践探索
- 算力池化技术
基于寒武纪MLU270的虚拟化方案:
# 算力池化命令
cnmon pool create -n mlu_pool -t MLU270 -c 4
cnmon pool attach -n mlu_pool -i task_container核心优势:
- 支持跨物理卡的统一虚拟地址空间
- 细粒度时间片轮转调度(最小粒度10ms)
- 硬件加速的上下文切换(<5μs开销)
- 混合架构统一调度
华为Atlas 800训练服务器与NVIDIA T4的异构虚拟化方案:
<!-- 混合架构调度策略 -->
<device_pool><nvidia_t4 count="4" priority="70"/><atlas_800 count="2" priority="30"/><scheduler type="hybrid" policy="fairshare+deadline"/>
</device_pool>该配置在某省级视频分析平台中,使总体任务完成率提升至99.3%。
五、性能优化实战案例
- 端边云协同推理优化
某车联网场景的vGPU配置方案:
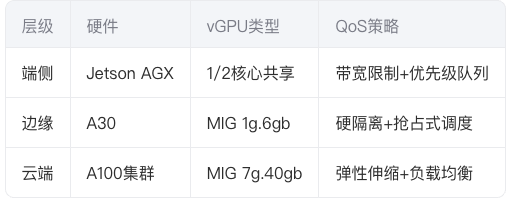
通过该架构,端到端推理延迟从218ms降至89ms,同时GPU利用率提升至82%。
结语
边缘GPU虚拟化正在经历从"能用"到"好用"的技术跃迁。未来发展方向包括:
- 异构计算统一抽象层(兼容CUDA/MLU/昇腾等架构)
- 联邦学习驱动的动态调度(基于全局负载预测)
- 存算一体的虚拟化方案(显存与计算资源联合优化)