YOLOv12综述:基于注意力的增强与先前版本的对比分析
A Review of YOLOv12
Attention-Based Enhancements vs. Previous Versions
https://arxiv.org/pdf/2504.11995
The YOLO (You Only Look Once) series has been a leading framework in real-time object detection, consistently improving the balance between speed and accuracy. However, integrating attention mechanisms into YOLO has been challenging due to their high computational overhead. YOLOv12 introduces a novel approach that successfully incorporates attention-based enhancements while preserving real-time performance. This paper provides a comprehensive review of YOLOv12's architectural innovations, including Area Attention for computationally efficient self-attention, Residual Efficient Layer Aggregation Networks for improved feature aggregation, and FlashAttention for optimized memory access. Additionally, we benchmark YOLOv12 against prior YOLO versions and competing object detectors, analyzing its improvements in accuracy, inference speed, and computational efficiency. Through this analysis, we demonstrate how YOLOv12 advances real-time object detection by refining the latency-accuracy trade-off and optimizing computational resources.
YOLO(You Only Look Once)系列 一直是实时目标检测领域的领先框架,通过不断改进速度与精度的平衡取得了显著进展。然而,由于高计算开销的问题,将注意力机制集成到YOLO中一直存在挑战。YOLOv12引入了一种新颖的方法,成功实现了基于注意力的增强,同时保持了实时性能。本文全面回顾了YOLOv12的架构创新,包括用于计算高效自注意力的区域注意力(Area Attention)、用于改进特征聚合的残差高效层聚合网络(Residual Efficient Layer Aggregation Networks),以及用于优化内存访问的FlashAttention。此外,本文将YOLOv12与先前的YOLO版本和竞争性目标检测器进行基准测试,分析其在准确性、推理速度和计算效率方面的改进。通过这一分析,展示了YOLOv12如何通过优化延迟-准确性权衡和计算资源来推动实时目标检测的发展。
1 Introduction
Real-time object detection is a cornerstone of modern computer vision, playing a pivotal role in applications such as autonomous driving [1, 2, 3, 4], robotics [5, 6, 7], and video surveillance [8, 9, 10]. These domains demand not only high accuracy but also low-latency performance to ensure real-time decision-making. Among the various object detection frameworks, the YOLO (You Only Look Once) series has emerged as a dominant solution [11], striking a balance between speed and precision by continuously refining convolutional neural network (CNN) architectures [12, 13, 14, 15, 16, 17, 18, 19, 20, 21]. However, a fundamental challenge in CNN-based detectors lies in their limited ability to capture long-range dependencies, which are crucial for understanding spatial relationships in complex scenes. This limitation has led to increased research into attention mechanisms, particularly Vision Transformers (ViTs) [22, 23], which excel at global feature modeling. Despite their advantages, ViTs suffer from quadratic computational complexity [24] and inefficient memory access [25, 26], making them impractical for real-time deployment.
实时目标检测是现代计算机视觉的基石,在自动驾驶[1, 2, 3, 4]、机器人技术[5, 6, 7]和视频监控[8, 9, 10]等应用中发挥着关键作用。这些领域不仅要求高精度,还需要低延迟性能以确保实时决策。在众多目标检测框架中,YOLO(You Only Look Once)系列已成为主导解决方案[11],通过持续优化卷积神经网络(CNN)架构[12, 13, 14, 15, 16, 17, 18, 19, 20, 21],在速度与精度之间取得了平衡。然而,基于CNN的检测器面临的一个根本性挑战是其捕获长距离依赖关系的能力有限,而这对于理解复杂场景中的空间关系至关重要。这一局限性促使研究者们加大对注意力机制的研究,尤其是视觉变换器(ViTs)[22, 23],其在全局特征建模方面表现出色。尽管具有优势,ViTs仍存在二次计算复杂度[24]和内存访问效率低[25, 26]的问题,使其难以应用于实时部署。
To address these limitations, YOLOv12 [27] introduces an attention-centric approach that integrates key innovations to enhance efficiency while maintaining real-time performance. By embedding attention mechanisms within the YOLO framework, it successfully bridges the gap between CNN-based and transformer-based detectors without compromising speed. This is achieved through several architectural enhancements that optimize computational efficiency, improve feature aggregation, and refine attention mechanisms:
Area Attention (A²): A novel mechanism that partitions spatial regions to reduce the complexity of self-attention, preserving a large receptive field while improving computational efficiency. This enables attention-based models to compete with CNNs in speed.
Residual Efficient Layer Aggregation Networks (R-ELAN): An enhancement over traditional ELAN, designed to stabilize training in large-scale models by introducing residual shortcuts and a revised feature aggregation strategy, ensuring better gradient flow and optimization.
Architectural Streamlining: Several structural refinements, including the integration of FlashAttention for efficient memory access, the removal of positional encoding to simplify computations, and an optimized MLP ratio to balance performance and inference speed.
为解决这些局限性,YOLOv12[27]提出了一种以注意力为核心的方法,通过集成关键创新来提升效率,同时保持实时性能。通过将注意力机制嵌入YOLO框架,它成功弥合了基于CNN和基于变换器的检测器之间的差距,且未牺牲速度。这是通过多项架构增强实现的,包括优化计算效率、改进特征聚合以及完善注意力机制:
区域注意力(Area Attention, A²):一种创新机制,通过划分空间区域来降低自注意力机制的计算复杂度,在保持大感受野的同时提升计算效率。这使得基于注意力的模型能够在速度上与CNN相媲美。
残差高效层聚合网络(Residual Efficient Layer Aggregation Networks, R-ELAN):对传统ELAN的改进,通过引入残差连接和优化的特征聚合策略,旨在稳定大规模模型的训练,确保更好的梯度流动和优化效果。
架构精简优化:包含多项结构改进,包括集成FlashAttention以实现高效内存访问、移除位置编码以简化计算,以及采用优化的MLP比率来平衡性能与推理速度。
2 Technical Evolution of YOLO Architectures
The You Only Look Once (YOLO) series has revolutionized real-time object detection through continuous architectural innovation and performance optimization. The evolution of YOLO can be traced through distinct versions, each introducing significant advancements.
YOLO(You Only Look Once)系列通过持续的架构创新和性能优化,彻底改变了实时目标检测领域。YOLO的发展历程可以通过各个版本追溯,每个版本都带来了重大技术进步。
YOLOv1 (2015) [11], developed by Joseph Redmon et al., introduced the concept of single-stage object detection, prioritizing speed over accuracy. It divided the image into a grid and predicted bounding boxes and class probabilities directly from each grid cell, enabling real-time inference. This method significantly reduced the computational overhead compared to two-stage detectors, albeit with some trade-offs in localization accuracy.
YOLOv2 (2016) [12], also by Joseph Redmon, enhanced detection capabilities with the introduction of anchor boxes, batch normalization, and multi-scale training. Anchor boxes allowed the model to predict bounding boxes of various shapes and sizes, improving its ability to detect diverse objects. Batch normalization stabilized training and improved convergence, while multi-scale training made the model more robust to varying input resolutions.
YOLOv1(2015)[11]由Joseph Redmon等人开发,首次提出了单阶段目标检测的概念,优先考虑速度而非精度。该方法将图像划分为网格,直接从每个网格单元预测边界框和类别概率,实现了实时推理。与两阶段检测器相比,虽然定位精度有所妥协,但显著降低了计算开销。
YOLOv2(2016)[12]同样由Joseph Redmon开发,通过引入锚框、批量归一化和多尺度训练增强了检测能力。锚框使模型能够预测各种形状和大小的边界框,提高了检测多样化物体的能力。批量归一化稳定了训练过程并改善了收敛性,而多尺度训练使模型对不同输入分辨率具有更强的鲁棒性。
YOLOv3 (2018) [13], again by Joseph Redmon, further improved accuracy with the Darknet-53 backbone, Feature Pyramid Networks (FPN), and logistic classifiers. Darknet-53 provided a deeper and more powerful feature extractor, while FPN enabled the model to leverage multi-scale features for improved detection of small objects. Logistic classifiers replaced softmax for class prediction, allowing for multi-label classification.
YOLOv4 (2020) [14], developed by Alexey Bochkovskiy et al., incorporated CSPDarknet, Mish activation, PANet, and Mosaic augmentation. CSPDarknet reduced computational costs while maintaining performance, Mish activation improved gradient flow, PANet enhanced feature fusion, and Mosaic augmentation increased data diversity.
YOLOv3(2018)[13]再次由Joseph Redmon开发,通过Darknet-53骨干网络、特征金字塔网络(FPN)和逻辑分类器进一步提高了准确度。Darknet-53提供了更深层、更强大的特征提取器,FPN使模型能够利用多尺度特征来改进小物体检测,逻辑分类器取代softmax进行类别预测,支持多标签分类。
YOLOv4(2020)[14]由Alexey Bochkovskiy等人开发,整合了CSPDarknet、Mish激活函数、PANet和Mosaic数据增强。CSPDarknet在保持性能的同时降低了计算成本,Mish激活函数改善了梯度流动,PANet增强了特征融合能力,Mosaic数据增强则增加了数据多样性。
YOLOv5 (2020) [15], developed by Ultralytics, marked a pivotal shift by introducing a PyTorch implementation. This significantly simplified training and deployment, making YOLO more accessible to a wider audience. It also featured auto-anchor learning, which dynamically adjusted anchor box sizes during training, and incorporated advancements in data augmentation. The transition from Darknet to PyTorch was a major change, and greatly contributed to the model's popularity.
YOLOv6 (2022) [16], developed by Meituan, focused on efficiency with the EfficientRep backbone, Neural Architecture Search (NAS), and RepOptimizer. EfficientRep optimized the model's architecture for speed and accuracy, NAS automated the search for optimal hyperparameters, and RepOptimizer reduced inference time through structural re-parameterization.
YOLOv5(2020)[15]由Ultralytics开发,通过采用PyTorch实现标志着关键转折。这极大地简化了训练和部署流程,使YOLO对更广泛的用户群体更加易用。该版本还具备自动锚框学习功能,可在训练过程中动态调整锚框尺寸,并采用了先进的数据增强技术。从Darknet转向PyTorch的转变是一个重大变革,极大地提升了该模型的普及度。
YOLOv6(2022)[16]由美团开发,专注于效率优化,采用EfficientRep骨干网络、神经架构搜索(NAS)和RepOptimizer。EfficientRep优化了模型架构以实现速度与精度的平衡,NAS自动搜索最优超参数,RepOptimizer通过结构重参数化减少了推理时间。
YOLOv7 (2022) [17], developed by Wang et al., further improved efficiency through Extended Efficient Layer Aggregation Network (E-ELAN) and re-parameterized convolutions. E-ELAN enhanced feature integration and learning capacity, while re-parameterized convolutions reduced computational overhead.
YOLOv8 (2023) [18], also developed by Ultralytics, introduced C2f modules, task-specific detection heads, and anchor-free detection. C2f modules enhanced feature fusion and gradient flow, task-specific detection heads allowed for more specialized detection tasks, and anchor-free detection eliminated the need for predefined anchor boxes, simplifying the detection process.
YOLOv7(2022)[17]由Wang等人开发,通过扩展高效层聚合网络(E-ELAN)和重参数化卷积进一步提升了效率。E-ELAN增强了特征整合和学习能力,而重参数化卷积则降低了计算开销。
YOLOv8(2023)[18]同样由Ultralytics开发,引入了C2f模块、任务特定检测头和无锚框检测。C2f模块优化了特征融合和梯度流动,任务特定检测头支持更专业的检测任务,无锚框检测消除了对预定义锚框的需求,简化了检测流程。
YOLOv9 (2024) [19], developed by Chien-Yao Wang et al., introduces Generalized Efficient Layer Aggregation Network (GELAN) and Programmable Gradient Information (PGI). GELAN improves the model's ability to learn diverse features, and PGI helps to avoid information loss during deep network training.
YOLOv10 (2024) [20], developed by various research contributors, emphasizes dual label assignments, NMS-free detection, and end-to-end training. Dual label assignments enhance the model's ability to handle ambiguous object instances, NMS-free detection reduces computational overhead, and end-to-end training simplifies the training process. The reason for stating "various research contributors" is that, at this time, there isn't a single, universally recognized, and consistently credited developer or organization for this specific release, as with previous versions.
YOLOv9(2024)[19]由Chien-Yao Wang等人开发,采用广义高效层聚合网络(GELAN)和可编程梯度信息(PGI)。GELAN提升了模型学习多样化特征的能力,PGI有效避免了深度网络训练中的信息丢失问题。
YOLOv10(2024)[20]由多方研究贡献者共同开发,重点采用双重标签分配、无NMS检测和端到端训练。双重标签分配增强了模型处理模糊目标实例的能力,无NMS检测降低了计算开销,端到端训练简化了训练流程。标注"多方研究贡献者"是因为该版本不像前代那样有明确单一的开发主体。
YOLOv11 (2024) [21], developed by Glenn Jocher and Jing Qiu, focuses on the C3K2 module, feature aggregation, and optimized training pipelines. The C3K2 module enhances feature extraction, feature aggregation improves the model's ability to integrate multi-scale features, and optimized training pipelines reduce training time. Similar to YOLOv10, the developer information is less consolidated and more collaborative.
YOLOv12 (2025) [27], the latest iteration, integrates attention mechanisms while preserving real-time efficiency. It introduces A², Residual-Efficient Layer Aggregation Networks (R-ELAN), and FlashAttention, alongside a hybrid CNN-Transformer framework. These innovations refine computational efficiency and optimize the latency-accuracy trade-off, surpassing both CNN-based and transformer-based object detectors.
YOLOv11(2024)[21]由Glenn Jocher和Jing Qiu主导开发,聚焦C3K2模块、特征聚合和优化训练流程。C3K2模块强化了特征提取能力,特征聚合优化了多尺度特征整合,优化训练流程显著缩短了训练时间。与YOLOv10类似,其开发信息呈现去中心化的协作特征。
YOLOv12(2025)[27]作为最新迭代版本,在保持实时效率的同时整合了注意力机制。创新性地引入A²模块、残差高效层聚合网络(R-ELAN)和FlashAttention,结合CNN-Transformer混合框架。这些突破性设计优化了计算效率,完善了延迟-精度平衡,性能超越传统CNN基检测器和Transformer基检测器。
The evolution of YOLO models highlights a shift from Darknet-based architectures [11, 12, 13, 14] to PyTorch implementations [15, 16, 17, 18, 19, 20, 21], and more recently, towards hybrid CNN-transformer architectures [27]. Each generation has balanced speed and accuracy, incorporating advancements in feature extraction, gradient optimization, and data efficiency. Figure 1 illustrates the progression of YOLO architectures, emphasizing key innovations across versions.
Figure 1: Evolution of YOLO architectures
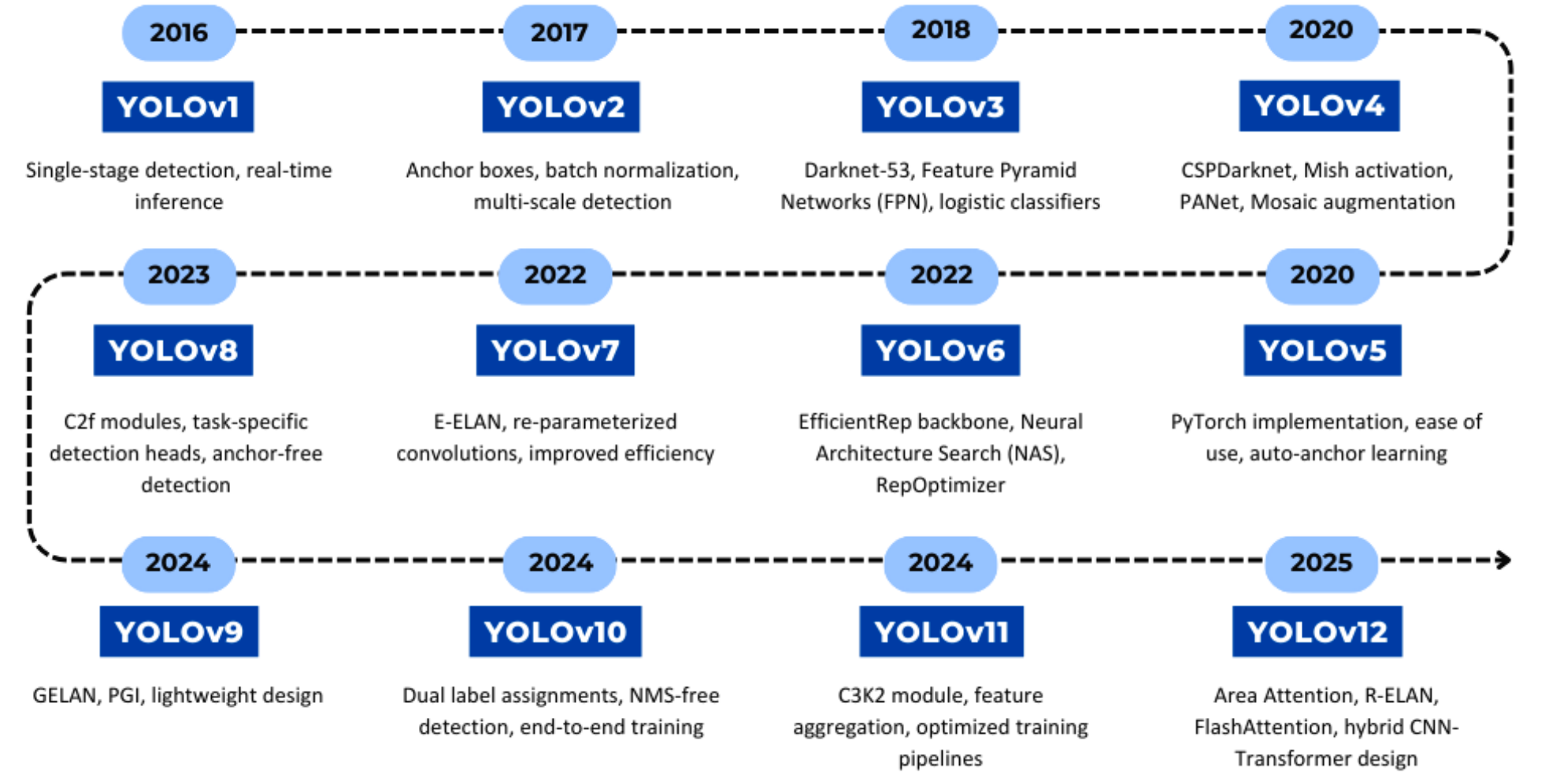
With YOLOv12's architectural refinements, attention mechanisms are now embedded within the YOLO framework, optimizing both computational efficiency and high-speed inference. The next section analyzes these enhancements in detail, benchmarking YOLOv12's performance across multiple detection tasks.
YOLO模型的演进历程清晰展现了从Darknet架构到PyTorch实现,再到CNN-Transformer混合架构的技术跃迁。每一代都完美平衡了速度与精度,在特征提取、梯度优化和数据效率方面持续突破。图1直观呈现了YOLO架构的演进路线,突出各版本的关键技术革新。
YOLOv12架构革新将注意力机制深度集成至YOLO框架,在优化计算效率的同时确保高速推理性能。下文将详细解析这些架构增强,并通过多维度检测任务对YOLOv12性能进行全面基准测试。
3 Architectural Design of YOLOv12
The YOLO framework revolutionized object detection by introducing a unified neural network that simultaneously performs bounding box regression and object classification in a single forward pass [28]. Unlike traditional two-stage detection methods, YOLO adopts an end-to-end approach, making it highly efficient for real-time applications. Its fully differentiable design allows seamless optimization, leading to improved speed and accuracy in object detection tasks.
At its core, the YOLOv12 architecture consists of two primary components: the backbone and the head. The backbone serves as the feature extractor, processing the input image through a series of convolutional layers to generate hierarchical feature maps at different scales. These features capture essential spatial and contextual information necessary for object detection. The head is responsible for refining these features and generating final predictions by performing multi-scale feature fusion and localization. Through a combination of upsampling, concatenation, and convolutional operations, the head enhances feature representations, ensuring robust detection of small, medium, and large objects. The Backbone and Head Architecture of YOLOv12 is depicted in Algorithm 1.

YOLO框架通过构建统一神经网络架构,实现单次前向传播中同步完成边界框回归与目标分类,彻底革新了目标检测领域。相较于传统两阶段检测方法采用的端到端方案使其在实时应用场景中展现卓越效能。其全可微设计支持无缝优化,显著提升了目标检测任务的速度与精度表现。
YOLOv12架构核心包含两大组件:骨干网络与检测头。骨干网络作为特征提取器,通过级联卷积层处理输入图像,生成多尺度层级特征图。这些特征精准捕获目标检测所需的空间与上下文信息。检测头通过多尺度特征融合与精确定位,实现特征优化并输出最终预测。结合上采样、特征拼接与卷积操作的协同机制,显著增强特征表征能力,确保对大/中/小目标的鲁棒检测性能。YOLOv12骨干网络与检测头架构详见算法1示意图。
3.1 Backbone: Feature Extraction
The backbone of YOLOv12 processes the input image through a series of convolutional layers, progressively reducing its spatial dimensions while increasing the depth of feature maps. The process begins with an initial convolutional layer that extracts low-level features, followed by additional convolutional layers that perform downsampling to capture hierarchical information. The first stage applies a 3×3 convolution with a stride of 2 to generate the initial feature map. This is followed by another convolutional layer that further reduces the spatial resolution while increasing feature depth.
As the image moves through the backbone, it undergoes multi-scale feature learning using specialized modules like C3k2 and A2C2F. The C3k2 module enhances feature representation while maintaining computational efficiency, and the A2C2F module improves feature fusion for better spatial and contextual understanding. The backbone continues this process until it generates three key feature maps: P3, P4, and P5, each representing different scales of feature extraction. These feature maps are then passed to the detection head for further processing.
3.1 骨干网络:特征提取
YOLOv12的骨干网络通过一系列卷积层处理输入图像,在逐步降低空间维度的同时增加特征图深度。该过程始于提取低级特征的初始卷积层,随后通过执行下采样的额外卷积层来捕获层次化信息。第一阶段采用步长为2的3×3卷积生成初始特征图,随后通过另一卷积层在提升特征深度的同时进一步降低空间分辨率。
当图像通过骨干网络时,系统采用C3k2和A2C2F等专用模块进行多尺度特征学习。其中C3k2模块在保持计算效率的同时增强特征表征能力,而A2C2F模块则通过优化特征融合来提升空间与上下文理解能力。该处理持续进行直至生成三个关键特征图:P3、P4和P5,分别代表不同尺度的特征提取结果,这些特征图随后被传递至检测头进行后续处理。
3.2 Head: Feature Fusion and Object Detection
The head of YOLOv12 is responsible for merging multi-scale features and generating final object detection predictions. It employs a feature fusion strategy that combines information from different levels of the backbone to enhance detection accuracy across small, medium, and large objects. This is achieved through a series of upsampling and concatenation operations. The process begins with the highest-resolution feature map (P5) being upsampled using a nearest-neighbor interpolation method. It is then concatenated with the corresponding lower-resolution feature map (P4) to create a refined feature representation. The fused feature is further processed using the A2C2F module to enhance its expressiveness.
A similar process is repeated for the next scale by upsampling the refined feature map and concatenating it with the lower-scale feature (P3). This hierarchical fusion ensures that both low-level and high-level features contribute to the final detection, improving the model’s ability to detect objects at varying scales.
3.2 检测头:特征融合与目标检测
YOLOv12的检测头负责融合多尺度特征并生成最终的目标检测预测。其采用的特征融合策略通过整合骨干网络不同层次的特征信息,显著提升了小/中/大目标的检测精度。该过程通过上采样和特征拼接操作实现:首先对最高分辨率特征图(P5)进行最近邻插值上采样,随后与低分辨率特征图(P4)进行特征拼接,形成优化后的特征表示,最后通过A2C2F模块进一步增强其特征表达能力。
系统通过迭代优化流程对下一尺度特征进行处理:将优化后的特征图再次上采样后与更小尺度特征(P3)进行拼接。这种层级融合机制确保底层细节特征和高层语义特征共同参与最终检测,显著提升模型在多尺度目标上的检测性能。
After feature fusion, the network undergoes final processing to prepare for detection. The refined features are downsampled again and merged at different levels to strengthen object representations. The C3k2 module is applied at the largest scale (P5/32-large) to ensure that high-resolution features are preserved while reducing computational cost. These processed feature maps are then passed through the final detection layer, which applies classification and localization predictions across different object categories. The detailed breakdown of its backbone and head architecture is formally described in Algorithm 1.
完成特征融合后,网络进入检测前处理阶段:通过重复下采样在不同层级强化目标特征表示。在最大尺度(P5/32-large)应用C3k2模块,在降低计算开销的同时保留高分辨率特征优势。最终,处理完成的特征图输入检测输出层,同步完成多类别目标的分类预测与定位回归。完整的骨干网络-检测头架构技术细节详见算法1规范描述。
4 Architectural Innovations of YOLOv12
YOLOv12 introduces a novel attention-centric approach to real-time object detection, bridging the performance gap between conventional CNNs and attention-based architectures. Unlike previous YOLO versions that primarily relied on CNNs for efficiency, YOLOv12 integrates attention mechanisms without sacrificing speed. This is achieved through three key architectural improvements: the A² Module, R-ELAN, and enhancements to the overall model structure, including FlashAttention and reduced computational overhead in the multi-layer perceptron (MLP). Each of these components is detailed below.
YOLOv12提出创新的注意力核心方案,在实时目标检测中成功弥合了传统CNN与注意力架构之间的性能鸿沟。不同于早期YOLO版本主要依赖CNN保证效率,YOLOv12集成注意力机制的同时仍保持高速性能。这一突破源自三大核心架构改进:A²模块、R-ELAN以及包含FlashAttention和MLP计算开销优化在内的整体模型增强。各组件技术细节如下。
4.1 Area Attention Module
The efficiency of attention mechanisms has traditionally been hindered by their high computational cost, particularly due to the quadratic complexity associated with self-attention operations [29]. A common strategy to mitigate this issue is linear attention [30], which reduces complexity by approximating attention interactions with more efficient transformations. However, while linear attention improves speed, it suffers from global dependency degradation [31], instability during training [32], and sensitivity to input distribution shifts [33]. Additionally, due to its low-rank representation constraints [34, 32], it struggles to retain fine-grained details in high-resolution images, limiting its effectiveness in object detection.
4.1 区域注意力模块
传统注意力机制效率受限于高计算成本,尤其是自注意力操作[29]的平方级复杂度。常用解决方案线性注意力[30]通过高效变换近似注意力交互来降低复杂度,但存在全局依赖退化[31]、训练不稳定性[32]和输入分布敏感性[33]等缺陷。受低秩表示约束[34,32]影响,其在高分辨率图像中难以保持细粒度细节,制约了目标检测效果。
To address these limitations, YOLOv12 introduces the A² Module, which retains the strengths of self-attention while significantly reducing computational overhead [27]. Unlike traditional global attention mechanisms that compute interactions across the entire image, Area Attention divides the feature map into equal-sized non-overlapping segments, either horizontally or vertically. Specifically, a feature map of dimensions (H, W) is partitioned into L segments of size (H/L, W) or (H, W/L), eliminating the need for explicit window partitioning methods seen in other attention models such as Shifted Window [35], Criss-Cross Attention [36], or Axial Attention [37]. These methods often introduce additional complexity and reduce computational efficiency, whereas A² achieves segmentation via a simple reshape operation, maintaining a large receptive field while significantly enhancing processing speed [27]. This approach is depicted in Figure 2.
Figure 2: Comparison of different local attention techniques, with the proposed Area Attention method
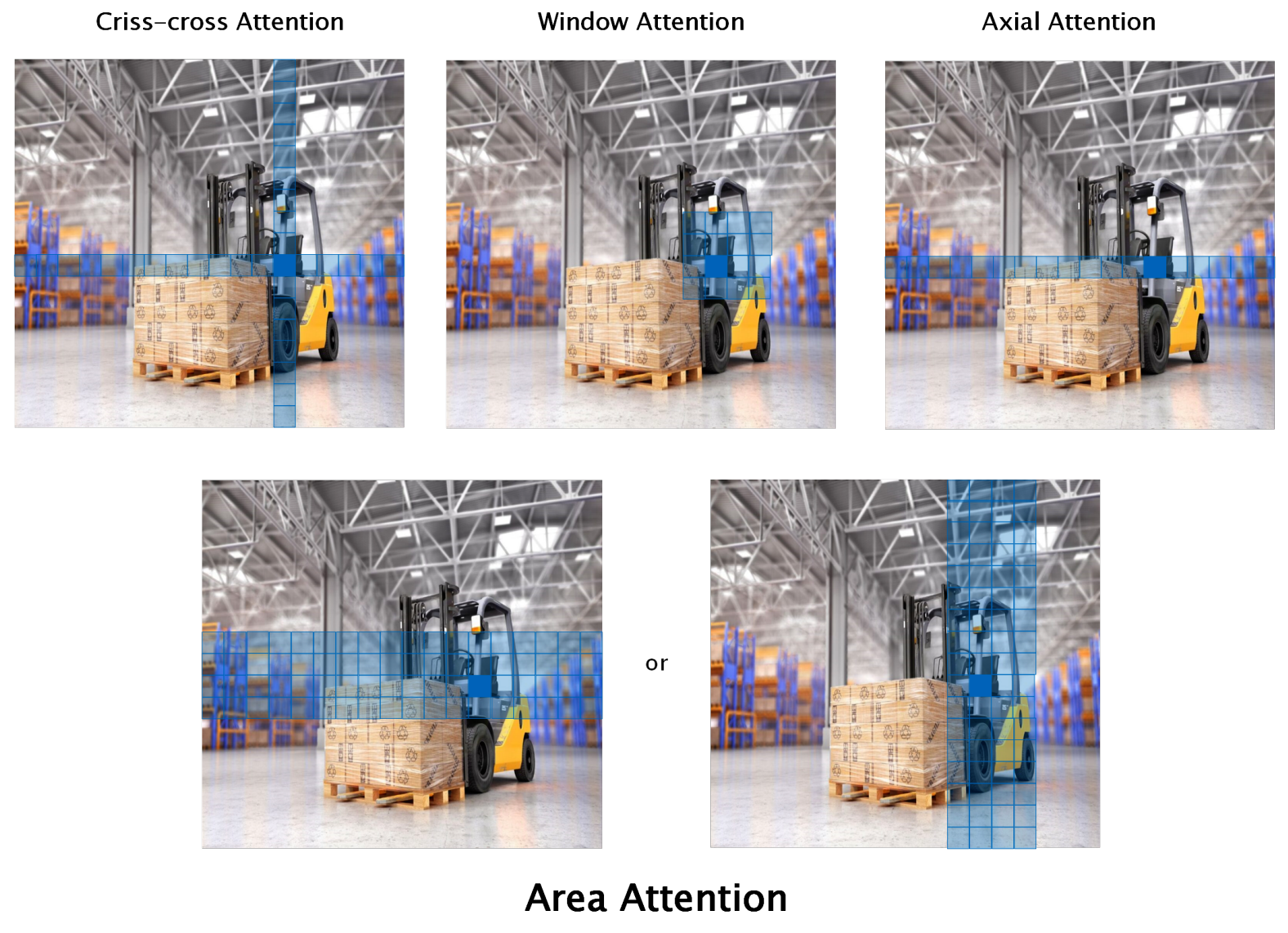
YOLOv12提出的A²模块在保留自注意力优势的同时大幅降低计算开销[27]。不同于传统全局注意力需计算全图交互,区域注意力将特征图划分为均等非重叠区块(水平或垂直方向)。具体而言,(H,W)尺寸特征图被分割为L个(H/L,W)或(H,W/L)区块,摒弃了移位窗口[35]、十字交叉注意力[36]等方案复杂的窗口划分方法。这些方法往往引入额外复杂度,而A²模块仅需简单变形操作即可实现分割,在保持大感受野的同时显著提升处理速度[27](如图2所示)。
Although A² reduces the receptive field to 1/4 of the original size, it still surpasses conventional local attention methods in coverage and efficiency. Moreover, its computational cost is nearly halved, reducing from 2n²hd (traditional self-attention complexity) to n²hd/2. This efficiency gain allows YOLOv12 to process large-scale images more effectively while maintaining robust detection accuracy [27].
尽管A²将感受野缩减至原尺寸1/4,但其覆盖范围与效率仍优于传统局部注意力。计算成本从2n²hd(传统自注意力)降至n²hd/2,近乎减半。这一效率提升使YOLOv12能更高效处理大规模图像,同时保持强健检测精度[27]。
4.2 Residual Efficient Layer Aggregation Networks (R-ELAN)
Feature aggregation plays a crucial role in improving information flow within deep learning architectures. Previous YOLO models incorporated Efficient Layer Aggregation Networks (ELAN) [17], which optimized feature fusion by splitting the output of 1 × 1 convolution layers into multiple parallel processing streams before merging them back together. However, this approach introduced two major drawbacks: gradient blocking and optimization difficulties. These issues were particularly evident in deeper models, where the lack of direct residual connections between the input and output impeded effective gradient propagation, leading to slow or unstable convergence.
To address these challenges, YOLOv12 introduces R-ELAN, a novel enhancement designed to improve training stability and convergence. Unlike ELAN, R-ELAN integrates residual shortcuts that connect the input directly to the output with a scaling factor (default set to 0.01) [27]. This ensures smoother gradient flow while maintaining computational efficiency. These residual connections are inspired by layer scaling techniques in Vision Transformers [38], but they are specifically adapted to convolutional architectures to prevent latency overhead, which often affects attention-heavy models.
Figure 3 illustrates a comparative overview of different architectures, including CSPNet, ELAN, C3k2, and R-ELAN, highlighting their structural distinctions.
Figure 3: Comparison of CSPNet, ELAN, C3k2, and R-ELAN Architectures.
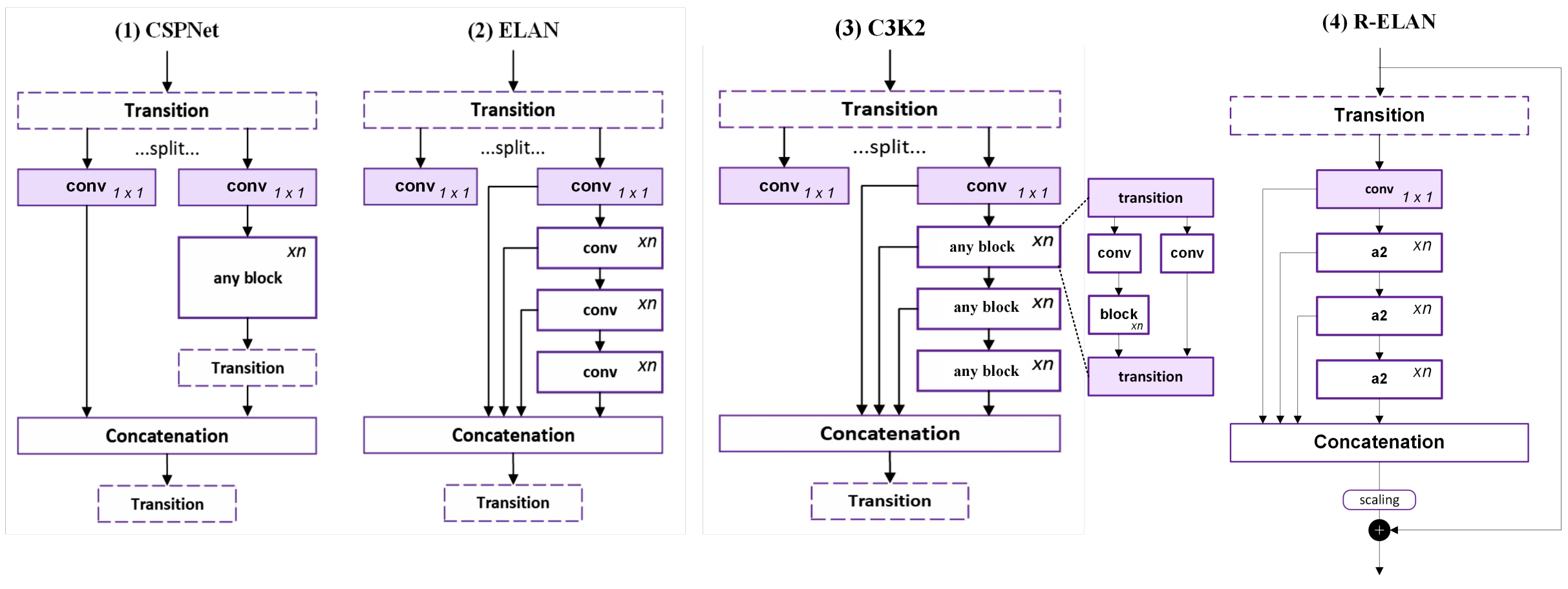
4.2 残差高效层聚合网络(R-ELAN)
特征聚合在改善深度学习架构的信息流动方面具有关键作用。早期YOLO模型采用的高效层聚合网络(ELAN)[17]通过将1×1卷积层输出分割为多个并行处理流再进行融合来优化特征融合,但存在梯度阻断和优化困难两大缺陷。这些问题在深层模型中尤为显著,由于输入输出间缺乏直接残差连接,严重阻碍了有效梯度传播,导致收敛缓慢或不稳定。
为解决这些问题,YOLOv12提出创新性改进方案R-ELAN。不同于ELAN,R-ELAN通过引入残差捷径连接(默认缩放因子0.01[27]),在保持计算效率的同时确保梯度平滑流动。这些残差连接借鉴了视觉Transformer[38]的层缩放技术,但专门针对卷积架构进行适配,有效避免了注意力密集型模型常见的延迟开销问题。
图3对比展示了CSPNet、ELAN、C3k2和R-ELAN的结构差异,直观呈现各架构特性。
• CSPNet (Cross-Stage Partial Network): CSPNet improves gradient flow and reduces redundant computation by splitting the feature map into two parts, processing one through a sequence of convolutions while keeping the other unaltered, and then merging them. This partial connection approach enhances efficiency while preserving representational capacity [39].
• CSPNet(跨阶段部分网络):CSPNet通过将特征图分割为两部分——一部分经过卷积序列处理,另一部分保持原状,最后合并两者——从而改善梯度流动并减少冗余计算[39]。这种部分连接方法在保持表征能力的同时提升了计算效率。
• ELAN (Efficient Layer Aggregation Networks): ELAN extends CSPNet by introducing deeper feature aggregation. It utilizes multiple parallel convolutional paths after the initial 1 × 1 convolution, which are concatenated to enrich feature representation. However, the absence of direct residual connections limits gradient flow, making deeper networks harder to train [17].
• ELAN(高效层聚合网络):ELAN在CSPNet基础上引入深层特征聚合机制,通过1×1卷积后的多路并行卷积路径进行特征拼接,丰富特征表示[17]。但由于缺乏直接残差连接,其梯度流动受限,导致深层网络训练困难。
• C3k2: A modified version of ELAN, C3k2 incorporates additional transformations within the feature aggregation process, but it still inherits the gradient-blocking issues from ELAN. While it improves structural efficiency, it does not fully resolve the optimization challenges faced in deep networks [21, 19].
• C3k2:作为ELAN的改进版,C3k2在特征聚合过程中增加了额外变换操作,但仍存在梯度阻断问题[21,19]。虽然提升了结构效率,但未能完全解决深层网络的优化挑战。
• R-ELAN: Unlike ELAN and C3k2, R-ELAN restructures feature aggregation by incorporating residual connections. Instead of first splitting the feature map and processing the parts independently, R-ELAN adjusts channel dimensions upfront, generating a unified feature map before passing it through bottleneck layers. This design significantly enhances computational efficiency by reducing redundant operations while ensuring effective feature integration [27].
• R-ELAN:相较ELAN和C3k2,R-ELAN创新性地整合残差连接结构。其先调整通道维度生成统一特征图,再通过瓶颈层处理,而非先分割后处理的方式。这一设计通过减少冗余运算显著提升计算效率,同时确保特征整合效果[27]。
The introduction of R-ELAN in YOLOv12 yields several advantages, including faster convergence, improved gradient stability, and reduced optimization difficulties, particularly for larger-scale models (L- and X-scale). Previous versions often faced convergence failures under standard optimizers like Adam and AdamW [17], but R-ELAN effectively mitigates these issues, making YOLOv12 more robust for deep learning applications [27].
R-ELAN的引入为YOLOv12带来三大优势:更快收敛速度、更强梯度稳定性,以及针对大尺度模型(L/X规格)的优化难度降低。早期版本使用Adam/AdamW[17]等优化器常出现收敛失败,而R-ELAN有效解决这些问题,使YOLOv12在深度学习应用中表现更鲁棒[27]。
4.3 Additional Improvements and Efficiency Enhancements
Beyond the introduction of A² and R-ELAN, YOLOv12 incorporates several additional architectural refinements to enhance overall performance:
• Streamlined Backbone with Fewer Stacked Blocks: Prior versions of YOLO [18, 19, 20, 21] incorporated multiple stacked attention and convolutional layers in the final stages of the backbone. YOLOv12 optimizes this by retaining only a single R-ELAN block, leading to faster convergence, better optimization stability, and improved inference efficiency—especially in larger models.
4.3 其他改进与效率优化
除引入A²模块和R-ELAN外,YOLOv12还进行了多项架构优化以提升整体性能:
• 精简骨干网络结构:早期YOLO版本[18-21]在骨干网络末端使用多个堆叠注意力与卷积层,而YOLOv12仅保留单个R-ELAN模块,显著提升收敛速度、优化稳定性和推理效率,在大模型中表现尤为突出。
• Efficient Convolutional Design: To enhance computational efficiency, YOLOv12 strategically retains convolution layers where they offer advantages. Instead of using fully connected layers with Layer Normalization (LN), it adopts convolution operations combined with Batch Normalization (BN), which better suits real-time applications [27]. This allows the model to maintain CNN-like efficiency while incorporating attention mechanisms.
• 高效卷积设计:为增强计算效率,YOLOv12策略性保留优势卷积层。采用卷积运算结合批归一化(BN)替代全连接层+层归一化(LN),更适配实时应用场景[27]。该设计在集成注意力机制的同时,保持CNN级效率。
• Removal of Positional Encoding: Unlike traditional attention-based architectures, YOLOv12 discards explicit positional encoding and instead employs large-kernel separable convolutions (7×7) in the attention module [27], known as the Position Perceiver. This ensures spatial awareness without adding unnecessary complexity, improving both efficiency and inference speed.
• 取消位置编码:不同于传统注意力架构,YOLOv12摒弃显式位置编码,转而在注意力模块采用大核可分离卷积(7×7)[27](称为位置感知器)。该方案在确保空间感知力的同时避免冗余计算复杂度,同步提升效率与推理速度。
• Optimized MLP Ratio: Traditional Vision Transformers typically use an MLP expansion ratio of 4, leading to computational inefficiencies in real-time settings. YOLOv12 reduces the MLP ratio to 1.2 [27], ensuring that the feed-forward network does not dominate overall runtime. This refinement helps balance efficiency and performance, preventing unnecessary computational overhead.
• 优化MLP比率:传统视觉Transformer通常采用MLP扩展比4,导致实时场景出现计算效率低下问题。YOLOv12将MLP比率降至1.2[27],确保前馈网络不会主导整体运行时间,有效平衡效率与性能,避免不必要计算开销。
• FlashAttention Integration: One of the key bottlenecks in attention-based models is memory inefficiency [25, 26]. YOLOv12 incorporates FlashAttention, an optimization technique that reduces memory access overhead by restructuring computation to better utilize GPU high-speed memory (SRAM). This allows YOLOv12 to match CNNs in speed while leveraging the superior modeling capacity of attention mechanisms.
• 集成FlashAttention:针对注意力模型的内存效率低下[25,26]瓶颈,YOLOv12引入FlashAttention优化技术。通过重构计算流程以更好利用GPU高速内存(SRAM),显著降低内存访问开销,使模型在保持注意力机制优越建模能力的同时,达到CNN级推理速度。
5 Discussion
(Chapter 7 in the paper)
YOLOv12在目标检测领域实现了重大突破,在YOLOv11的坚实基础之上,融入了前沿架构优化。该模型在精度、速度和计算效率之间取得了精妙平衡,成为实时计算机视觉应用的最优解决方案。
5.1 模型效率与部署
YOLOv12提供从纳米级(12n)到超大型(12x)的多尺寸模型,可适配各类硬件平台。这种可扩展性确保其既能高效运行于资源受限的边缘设备,也能充分发挥高性能GPU的潜力,在优化推理速度的同时保持高精度。其中纳米级和小型变体在保持检测精度的前提下显著降低延迟,是自主导航[44,45]、机器人技术[5]及智能监控[46-48]等实时应用的理想选择。
5.2 架构创新与计算效率
YOLOv12通过多项关键架构改进同时提升了特征提取和处理效率。R-ELAN优化了特征融合与梯度传播,支持构建更深层却更高效的网络结构。引入7×7可分离卷积在减少参数量的同时保持空间一致性,以最小计算开销实现更优的特征提取。
YOLOv12最突出的优化之一是采用FlashAttention驱动的区域注意力机制,在提升检测精度的同时降低内存开销。这使得模型能在复杂动态环境中更精准地定位目标,且不影响推理速度。这些架构改进共同实现了更高mAP,同时维持实时处理效率,使其特别适合需要低延迟目标检测的应用场景。
5.3 性能提升与硬件适应性
基准测试表明,YOLOv12在精度和效率上均超越前代YOLO版本。其中YOLOv12m变体在参数量减少25%的情况下,达到了与YOLOv11x相当甚至更优的mAP值,展现了显著的计算效率提升。更小型的YOLOv12s变体则大幅降低了推理延迟,使其特别适合边缘计算和嵌入式视觉应用[49]。
从硬件部署角度看,YOLOv12展现出卓越的可扩展性,既能充分发挥高性能GPU的算力,也能适配低功耗AI加速器。其优化的模型变体可灵活部署于自动驾驶车辆、工业自动化、安防监控等实时应用场景[50-52]。该模型高效的内存利用率和较低的计算占用,使其成为资源受限环境的理想选择。