【自然语言处理与大模型】模型压缩技术之蒸馏
知识蒸馏是一种模型压缩技术,主要用于将大型模型(教师模型)的知识转移到更小的模型(学生模型)中。在大语言模型领域,这一技术特别重要。
知识蒸馏的核心思想是利用教师模型的输出作为软标签(soft labels),来指导学生模型的训练。与传统的硬标签(hard labels)不同,软标签包含了更多的信息,不仅告诉学生模型每个样本属于哪个类别,还提供了关于不同类别之间相似性的额外信息。通过学习这些软标签,学生模型可以更好地捕捉到数据中的潜在规律和特征,从而提高其性能。
一、知识蒸馏的基本框架
三个核心组成部分:知识、蒸馏算法以及师生架构。
- 知识:代表从教师模型中提炼出的有效信息,这可能包括输出层的概率分布(通常称为软标签)、中间层的特征表示等;
- 蒸馏算法:关注的是如何高效地将这些宝贵的知识从教师模型转移到学生模型的具体方法与策略;
- 师生架构:则定义了教师模型和学生模型之间的互动方式。这样的结构确保了学生模型不仅能学习到教师模型的精髓,还能在保持较低复杂度的同时实现性能的提升。
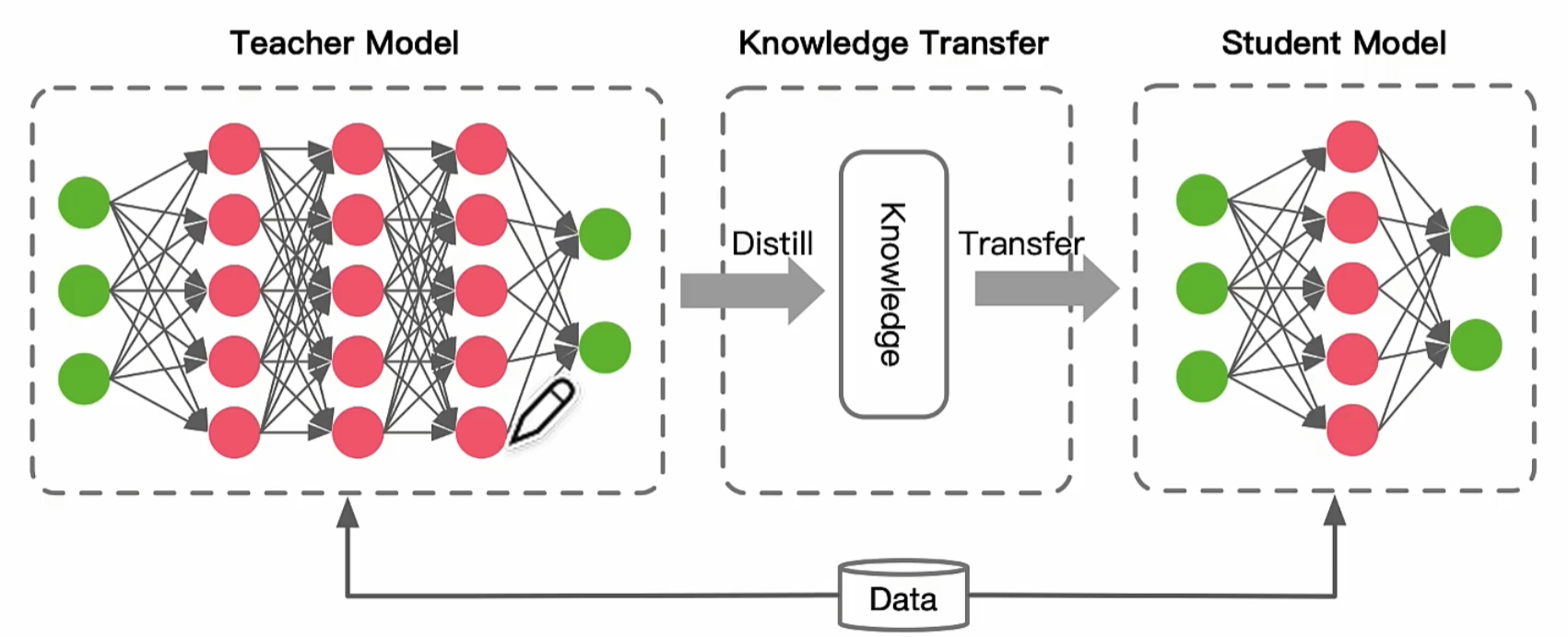
知识蒸馏能够在保持高性能的同时,降低模型的复杂性和计算需求。
二、知识的来源
知识蒸馏中的知识来源方式有很多种,常见的几种有从软标签中获取,还有从特征表示里面获取还可以从注意力机制中获取。
(1)软标签
借用子豪哥的图来说明什么是软标签,一个图形分类模型在训练的时候,想让他学会分辨什么是马。软标签是一组概率分布,反映了教师模型对输入属于各个类别的置信度。这些概率值不仅显示了最可能的类别,还揭示了其他类别的可能性。

硬标签是分类任务中的一组离散值,表示每个类别的绝对归属情况。通常是一个one-hot向量,其中正确类别的位置标记为1,其余类别标记为0。硬标签只传达了模型预测的最终结果,没有提供关于其他类别的任何信息。
| 类别 | 硬标签 (Hard Targets) | 软标签 (Soft Targets) |
|---|---|---|
| 马 | 1 | 0.7 |
| 驴 | 0 | 0.25 |
| 汽车 | 0 | 0.05 |
软标签不仅能指出最有可能的类别(如“马”),还能指示出其他类别(如“驴”和“汽车”)的可能性,帮助学生模型学习到更多的背景知识。由于软标签包含了更多关于数据分布的信息,它们可以帮助学生模型更好地泛化到未见过的数据上。
(2)特征表示
特征表示是指教师模型中某一层的激活值或特征向量,这些特征向量捕捉了输入数据的高级语义信息。特征表示通常包含了丰富的语义信息,可以帮助学生模型学习到更抽象、更高级的特征。可以选择教师模型中不同层次的特征表示进行蒸馏,从而提供多层次的知识转移。
由于教师和学生的网络结构可能不同,采用特征表示来得到知识要注意维度对齐,它包括通道数对齐和空间分辨率对齐。
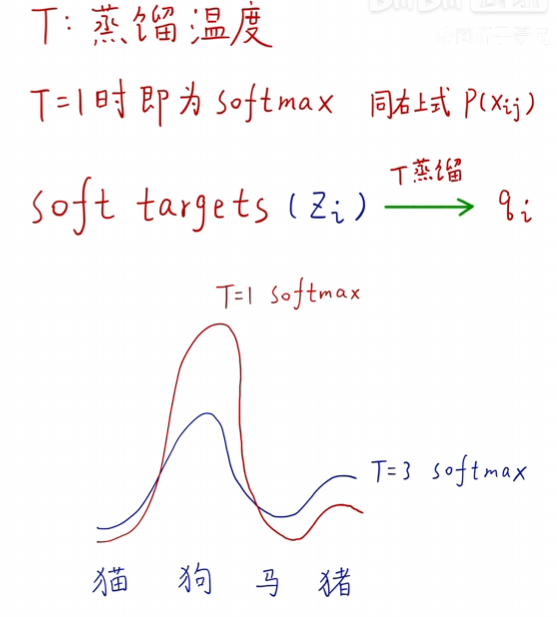
三、蒸馏温度T
蒸馏温度(Temperature, T)是一个重要的超参数,用于调节教师模型输出的软标签的平滑程度。通过调整温度参数,可以控制软标签中不同类别概率的分布,从而影响学生模型的学习重点和蒸馏效果。
在知识蒸馏中,温度参数 T 通常用于调整教师模型输出的Logits(即未经Softmax处理的输出值)。具体来说,使用温度参数调整后的Softmax函数可以表示为:
其中:
表示调整后第
个类别的概率。
表示第
表示温度参数。
当 T=1 时,上述公式即为标准的Softmax函数。当 T>1 时,概率分布会变得更加平滑;当 T<1 时,概率分布会变得更加尖锐。过高的温度值可能导致模型过于关注于那些概率值较小的类别,从而降低模型的判别能力;而过低的温度值可能导致模型过于关注于那些概率值较大的类别,从而降低模型的泛化能力。
四、知识蒸馏的方式
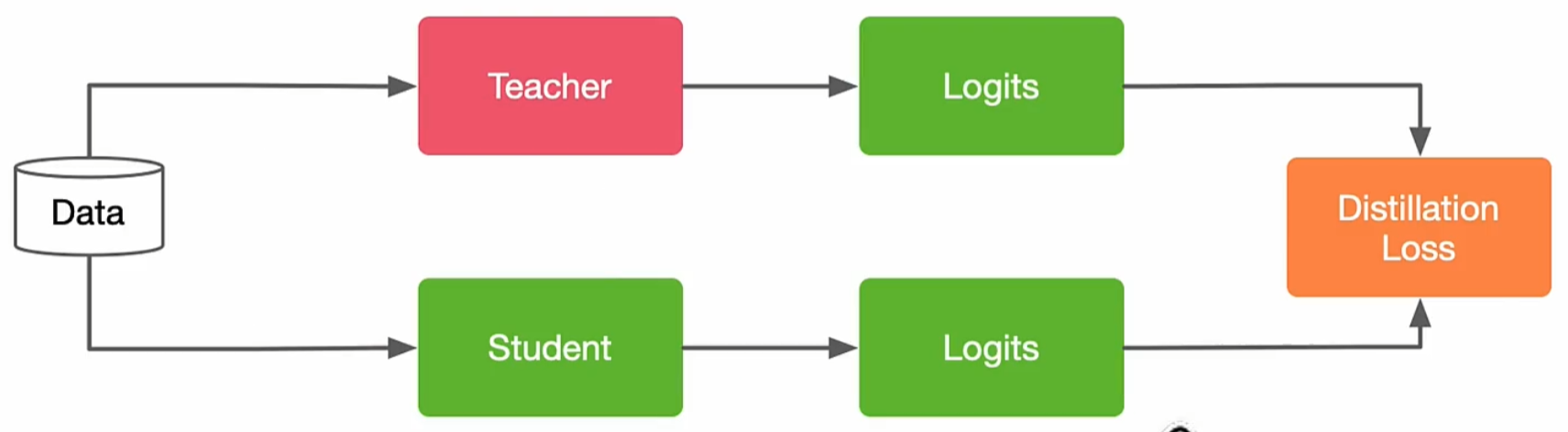
就只介绍一下最常常见的知识蒸馏方式——离线知识蒸馏。其基本流程是先训练好一个大型、复杂的教师模型,然后利用该教师模型的输出来指导小型、简单的学生模型的训练。在学生模型的训练过程中,教师模型的参数是冻结的,即教师模型的参数不再更新。
结合上面这个图来介绍一下,离线知识蒸馏的主要步骤:
第一步:训练教师模型
首先,使用大量的训练数据和适当的损失函数(如交叉熵损失)训练一个高性能的教师模型。教师模型通常是一个大型、复杂的模型,具有较多的参数和较高的计算复杂度。
第二步:生成软标签
在教师模型训练完成后,使用该模型对训练数据进行预测,得到每个样本的软标签。软标签是教师模型输出的概率分布,通过调整蒸馏温度可以控制其平滑程度。
第三步:训练学生模型
使用教师模型生成的软标签作为目标,训练一个小型、简单的学生模型。在训练过程中,教师模型的参数保持不变(冻结状态),仅更新学生模型的参数。学生模型的训练目标包括硬标签(真实类别标签)和软标签(教师模型的输出),通常使用KL散度(Kullback-Leibler Divergence)来衡量学生模型输出与教师模型软标签之间的差异。
KL散度,也称为相对熵(Relative Entropy),是信息论中用于衡量两个概率分布之间差异的一种度量方式。它量化了从一个概率分布 P 转换到另一个概率分布 Q 时所损失的信息量。
- 在知识蒸馏中,KL散度用于衡量学生模型的输出概率分布与教师模型的软标签之间的差异。通过最小化KL散度,学生模型可以更好地学习教师模型的知识。
- 具体来说,学生模型的训练目标包括最小化KL散度和硬标签损失(如交叉熵损失)。
第四步:评估和优化
使用独立的验证集对学生模型进行评估,比较其性能与教师模型的差异。如果性能不理想,可以尝试调整温度参数、改变学生模型的结构或进行微调等操作,以优化蒸馏效果。
参考知识蒸馏开山之作:Distilling the Knowledge in Neural Network