从规则到大模型:知识图谱信息抽取实体NER与关系RE任务近10年演进发展详解
摘要:
本文回顾了关系抽取与实体抽取领域的经典与新兴模型,清晰地梳理了它们的出现时间与核心创新,并给出在 2025 年不同资源与场景下的最佳实践推荐。文章引用了 BiLSTM‑CRF、BiLSTM‑CNN‑CRF、SpanBERT、LUKE、KnowBERT、CasRel、REBEL、UIE,大模型抽取 等模型的原始论文与权威来源,帮助读者全面、系统地理解信息抽取技术的发展脉络与应用指南。
一、信息抽取技术的发展时间线
| 年份 | 代表模型 | 核心贡献 |
|---|---|---|
| 2016 | BiLSTM‑CRF(Lample et al.) | 将双向 LSTM 与 CRF 解码结合,实现端到端序列标注 |
| 2016 | BiLSTM‑CNN‑CRF(Ma & Hovy) | 引入字符级 CNN 捕捉形态特征,增强未登录词处理 |
| 2019 | KnowBERT(Peters et al.) | 将 WordNet/Wikipedia 知识注入 BERT,提升实体与关系抽取 |
| 2020 | SpanBERT(Joshi et al.) | 用 span‑masking 学习片段边界表示,提升 QA 与关系抽取 (ArXiv 版本) |
| 2020 | LUKE(Yamada et al.) | 实体感知自注意力,词与实体同处编码,刷新多项 SOTA |
| 2020 | CasRel(Wei et al.) | 级联二元标注解决三元组重叠(SEO/EPO)问题 |
| 2021 | REBEL(Huguet Cabot & Navigli) | 基于 BART 的 Seq2Seq 生成式关系抽取,支持 200+ 关系类型 |
| 2022 | UIE(Lu et al.) | 统一 Text‑to‑Structure 生成框架,涵盖实体/关系/事件等 (ArXiv 版本)0样本,少样本 |
| 2022 | 提示词抽取 | 0样本,少样本学习 |
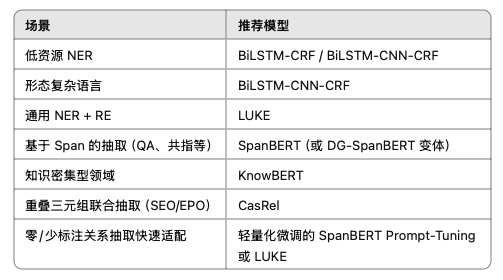
二、2025 年的主流选型
1. 资源有限时:BiLSTM‑CRF 与 BiLSTM‑CNN‑CRF
-
依旧是无大规模预训练模型支持时的坚实基线;
-
在 CoNLL‑2003 上可达 ~91% F1,轻量、易部署 。
1.1 BiLSTM‑CRF(pipeline:实体抽取模型)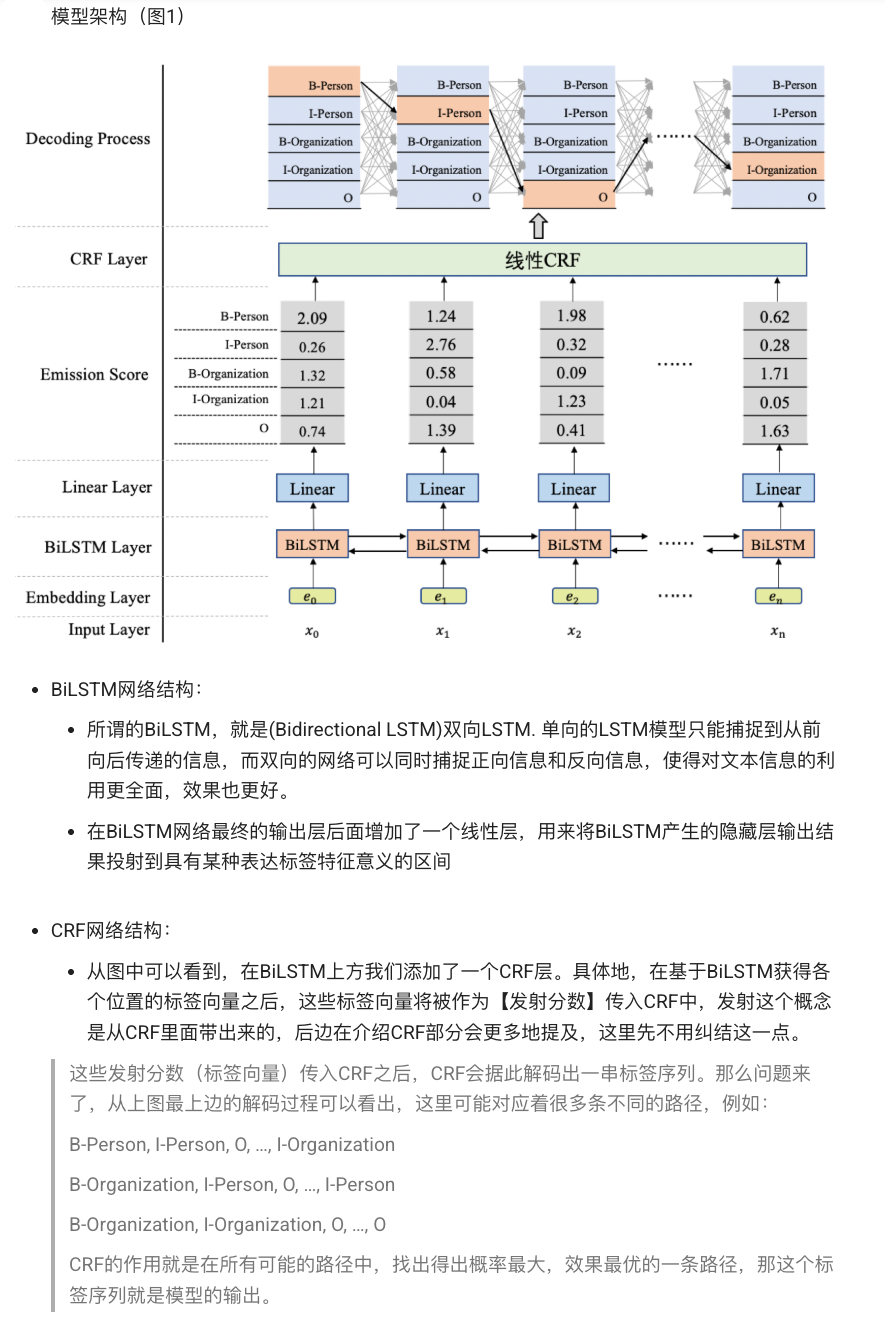
-
结构:双向 LSTM 编码器 + CRF 解码层,用以同时建模上下文依赖和标签间转移关系。
-
性能:在 CoNLL‑2003 英文数据集上,无需外部特征即可达到约 91.2% 的 F1 值,堪比早期 BERT 结果。
-
适用场景:标注数据量适中、希望用端到端模型而不做大量特征工程时;也适合缺少大规模预训练模型支持的语言或领域。
-
bilstm+attention(pipeline:关系抽取模型)
-
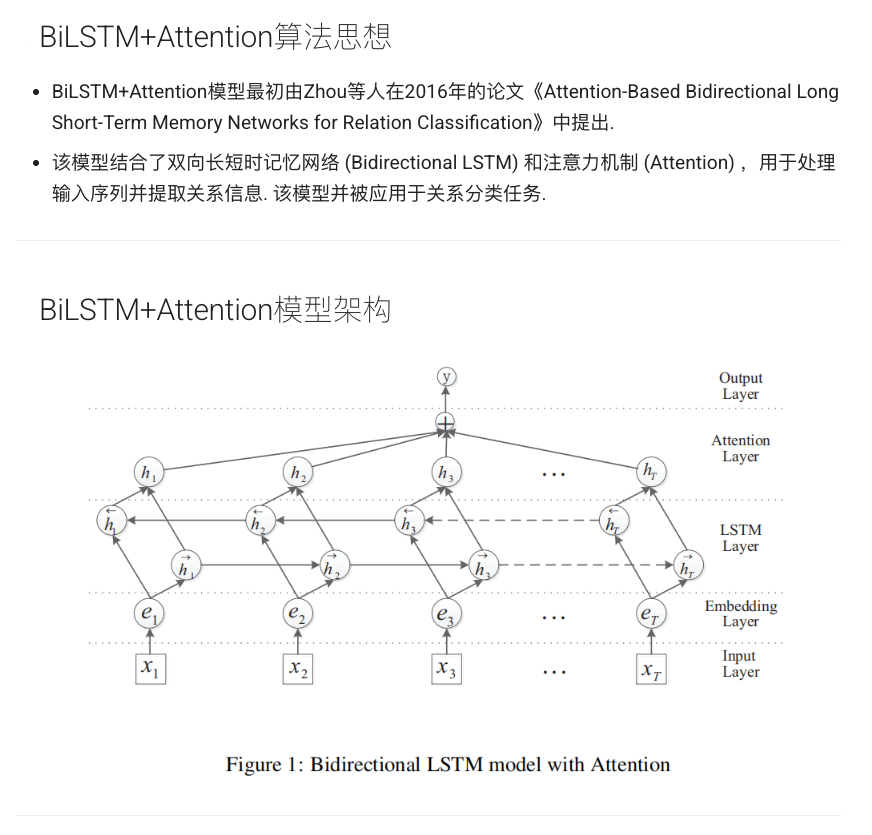
1.2 BiLSTM‑CNN‑CRF
-
结构:在 BiLSTM 前加入字符级 CNN,用以捕捉形态学特征,增强对低频词或未登录词的处理能力。
-
性能:同样能在 CoNLL‑2003 上达到约 91.2% F1,在形态丰富的语言(如医学、生物领域)中通常略优于纯 BiLSTM‑CRF。
-
适用场景:字符或子词模式重要(如专业术语、黏着语);模型尺寸或延迟对实时性有严格要求、无法部署大型 Transformer 时。
预训练语言模型(PLM)在 NER 与 RE 中的应用
2. 资源充足时:SpanBERT / LUKE / KnowBERT
-
SpanBERT 擅长 span 表征,适合联合任务与 QA 管道 ;
-
LUKE 一体化 NER+RE 端到端解决方案,需实体链接支撑 ;
-
KnowBERT 面向知识密集型领域,KB 注入减少“编造”事实 。
2.1 SpanBERT
-
预训练目标:遮蔽连续 span,并让模型学习该 span 边界的表示,而非单个词。
-
NER & RE 表现:在 span 选择任务(问答、共指解析)和关系抽取(如 TACRED 加入图网络改进版 DG‑SpanBERT)上均优于 BERT。
-
适用场景:需精确 span 表征的场景——联合实体关系抽取、问答管道等。
2.2 LUKE
-
实体感知自注意力:将词与实体都作为输入 token,额外引入实体嵌入,并在自注意力中区分词-词、词-实体、实体-实体的注意力权重。
-
基准成绩:在 CoNLL‑2003、TACRED(关系分类)和 Open Entity Typing 等任务上均刷新 SOTA,表现稳健。
-
适用场景:既要做高质量 NER 又要做 RE,一体化端到端系统;当已有高质量实体链接(如维基百科实体)做支撑时效果最佳。
2.3 KnowBERT
-
知识注入:通过实体链接在预训练阶段将知识库(WordNet、维基百科)事实融合进 BERT 权重。
-
下游收益:在实体分类、关系抽取、困惑度评估等任务上提升明显,且推理时开销与纯 BERT 相近。
-
适用场景:知识密集型领域(医学、金融),需要依赖外部 KB 校正模型输出、避免“编造”事实。
3. 重叠抽取场景:CasRel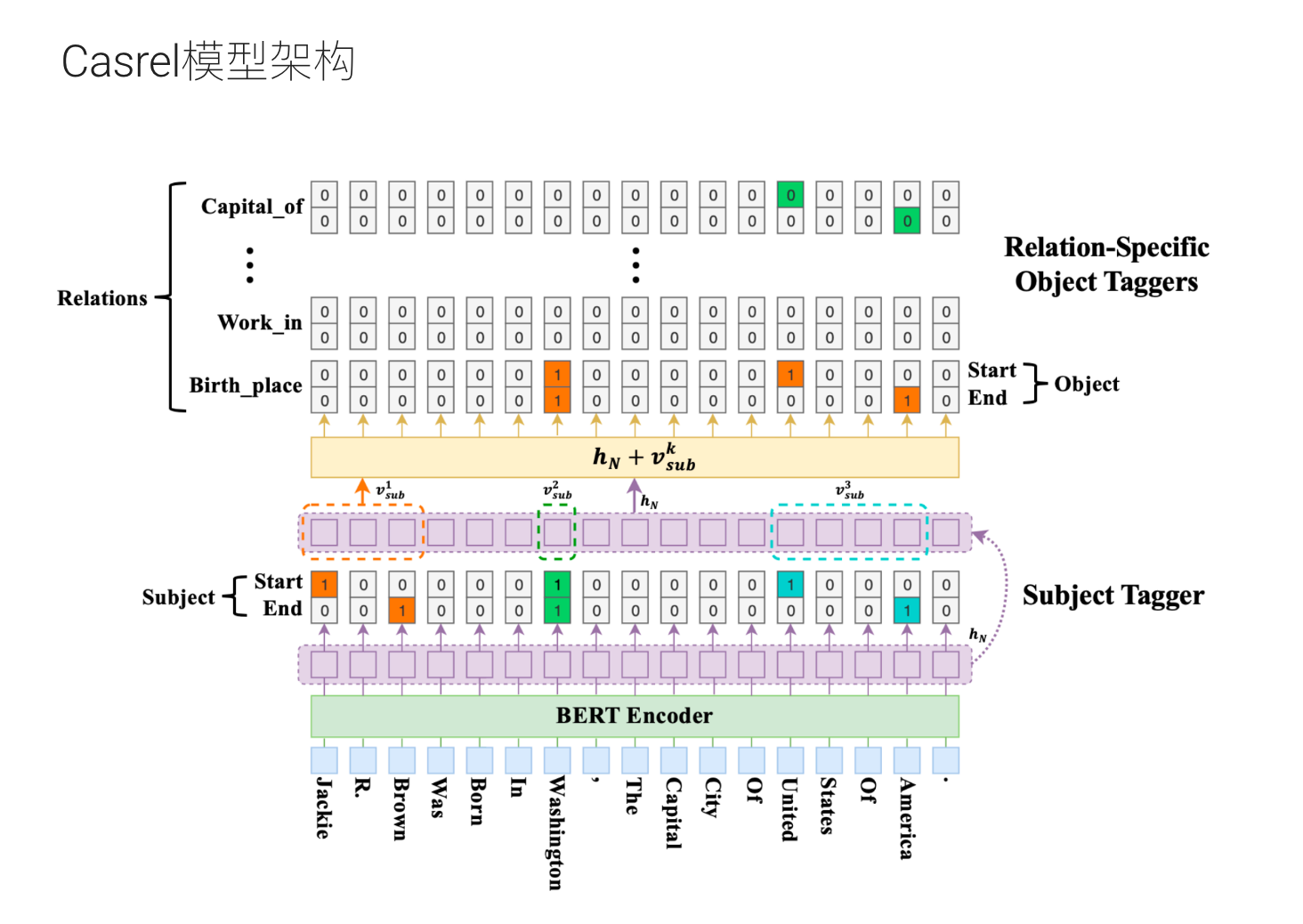
-
天然处理单实体/实体对重叠(SEO/EPO),新闻与法律文本场景优选 。
3.1. 联合抽取:CasRel
-
级联二元标注:先用线性+Sigmoid 在 BERT 输出上识别所有可能的“主语” span;再对每个主语,在每个关系类别下独立预测“宾语” span。
-
重叠关系支持:自然涵盖单实体重叠(SEO)与实体对重叠(EPO)场景,不需额外后处理。
-
性能表现:在 WebNLG 数据集上约 91.8% F1,NYT10 上约 89.6% F1,与或优于传统流水线方法。
-
适用场景:关系种类多且三元组重叠严重(如新闻语料);希望用统一模型替代分步 NER+RE 管道时。
4. 端到端生成式:REBEL
-
将三元组线性化为文本序列,少样本与跨领域表现杰出 。
5. 通用一体化:UIE
-
统一实体/关系/事件/情感抽取,支持零/少样本与跨任务迁移 。
6. 大模型时代:提示词工程(chatgpt,deepseek等)
任务:从下面句子中抽取 PERSON、ORG 实体及其“创办者”关系。
定义:PERSON 表示人物;ORG 表示机构;“创办者”关系示例:{ "subject": "马云", "relation": "创办者", "object": "阿里巴巴" }.
示例1:
句子:马云于1999年创办了阿里巴巴。
标注:{"subject":"马云","relation":"创办者","object":"阿里巴巴"}
示例2:
句子:比尔·盖茨是微软的联合创始人。
标注:{"subject":"比尔·盖茨","relation":"创办者","object":"微软"}
请在下方句子中做同样抽取:
句子:……
格式要求:JSON 数组,字段顺序固定为 subject→relation→object。
总结:
在资源有限时,BiLSTM‑系列模型仍是坚实基线;当拥有充足计算和数据时,SpanBERT、LUKE、KnowBERT 等预训练模型显著超越传统方法;而 CasRel 则在复杂重叠的联合抽取场景中表现尤为出色,当然如果不做标注的话大模型提示词也是可以的。
如果这篇文章对你有帮助,欢迎 点赞、 收藏、 转发,并在评论区留下你的 疑问 或 实践经验,一起交流、共同进步!
声明:文中引用均来自权威论文与官方开源项目,点击查看原文链接。希望对你的项目选型与技术学习有所裨益!