spark基础介绍
一)Spark概述
Spark是一种基于内存的快速、通用、可拓展的大数据分析计算引擎。Hadoop是一个分布式系统基础架构。
1)官网地址:Apache Spark™ - Unified Engine for large-scale data analytics
2)文档查看地址:Redirecting…
3)下载地址:Downloads | Apache Spark
https://archive.apache.org/dist/spark/
(二)为什么我们需要Spark
处理速度
Hadoop:Hadoop MapReduce 基于磁盘进行数据处理,数据在 Map 和 Reduce 阶段会频繁地写入磁盘和读取磁盘,这使得数据处理速度相对较慢,尤其是在处理迭代式算法和交互式查询时,性能会受到较大影响。
Spark:Spark 基于内存进行计算,能将数据缓存在内存中,避免了频繁的磁盘 I/O。这使得 Spark 在处理大规模数据的迭代计算、交互式查询等场景时,速度比 Hadoop 快很多倍。例如,在机器学习和图计算等需要多次迭代的算法中,Spark 可以显著减少计算时间。
编程模型
Hadoop:Hadoop 的 MapReduce 编程模型相对较为底层和复杂,开发人员需要编写大量的代码来实现数据处理逻辑,尤其是在处理复杂的数据转换和多阶段计算时,代码量会非常庞大,开发和维护成本较高。
Spark:Spark 提供了更加简洁、高层的编程模型,如 RDD(弹性分布式数据集)、DataFrame 和 Dataset 等。这些抽象使得开发人员可以用更简洁的代码来实现复杂的数据处理任务,同时 Spark 还支持多种编程语言,如 Scala、Java、Python 等,方便不同背景的开发人员使用。
实时性处理
Hadoop:Hadoop 主要用于批处理任务,难以满足实时性要求较高的数据处理场景,如实时监控、实时推荐等。
Spark:Spark Streaming 提供了强大的实时数据处理能力,它可以将实时数据流分割成小的批次进行处理,实现准实时的数据分析。此外,Spark 还支持 Structured Streaming,提供了更高级的、基于 SQL 的实时流处理模型,使得实时数据处理更加容易和高效。
HadoopMR框架,从数据源获取数据,经过分析计算之后,将结果输出到指定位置,核心是一次计算,不适合迭代计算。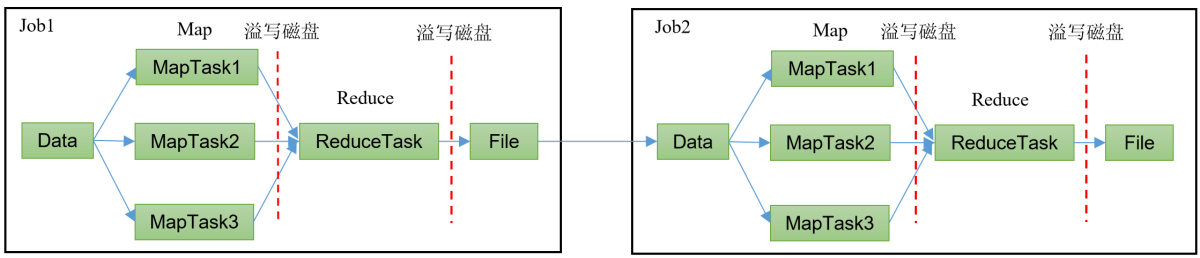
Spark框架,支持迭代式计算,图形计算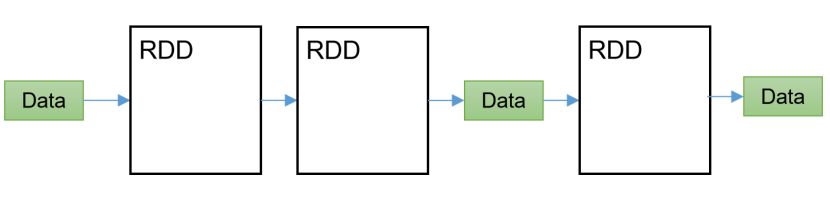 (三)Spark内置模块
(三)Spark内置模块
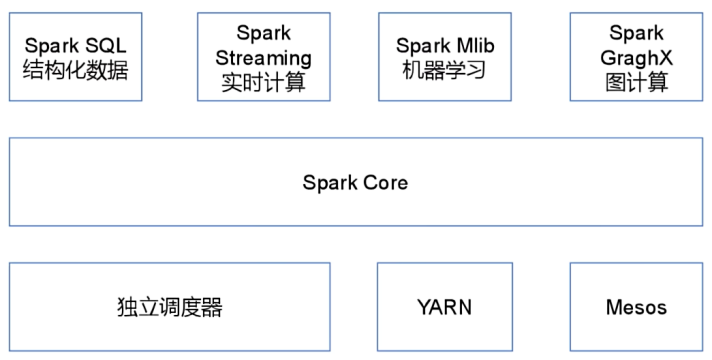
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
(四) Spark的运行模式
部署Spark集群大体上分为两种模式:单机模式(Local模式)与集群模式。大多数分布式框架都支持单机模式:就是运行在一台计算机上的模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
下面详细列举了Spark目前支持的部署模式。
(1)Local模式:单机模式,在本地部署单个Spark服务
(2)Standalone模式:集群模式,Spark自带的任务调度模式。
(3)YARN模式:集群模式,Spark使用Hadoop的YARN组件进行资源与任务调度。
(4)Mesos模式:集群模式,Spark使用Mesos平台进行资源与任务的调度。
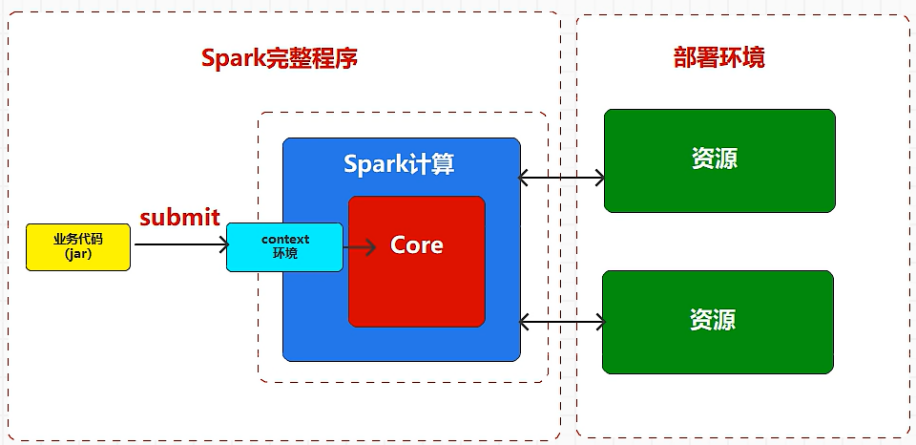
如果资源(cpu,内存)是当前单节点提供的,那么称之为单机模式。
如果资源(cpu,内存)是当前多节点提供的,那么称之为分布式模式。
(五)安装Spark
安装Spark的过程就是下载和解压的过程。接下来的操作,我们把它上传到集群中的节点,并解压运行。
1.启动虚拟机
2.通过finalshell连接虚拟机,并上传安装文件到 /opt/software下
3.解压spark安装文件到/opt/module下
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
4.重命名,把解压后的文件夹改成spark-local。因为后续我们还会使用其他的配置方式,所以这里先重命名一次。mv是linux的命令,
mv spark-3.3.1-bin-hadoop3 spark-local
(六)配置环境变量
1.打开etc/profile.d/my_env.sh文件中,补充设置spark的环境变量。
# 省略其他...
# 添加spark 环境变量
export SPARK_HOME=/opt/module/spark-local
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.使用 source /etc/profile 命令让环境变量生效
(七)单机模式运行第一个Spark程序
这里使用单机模式快运行第一个Spark程序,让大家有个基本的印象。在安装Spark时,它就提供了一些示例程序,我们可以直接来调用。进入到spark-local,运行命令spark-submit命令。
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /opt/module/spark-local/examples/jars/spark-examples_2.12-3.1.1.jar 10
或者写成
$ cd /opt/module/spark-local
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10
这里的 \ 是换行输入的意思,整体的代码就只有一句,只不过太长了,我们把它拆开成几个部分来输入,其中\ 的意思就是这里写不下,写在下一行。
结果展示
该算法是利用蒙特·卡罗算法求PI的值,具体运行效果如下。请注意,它并不会产生新的文件,而是直接在控制台输出结果。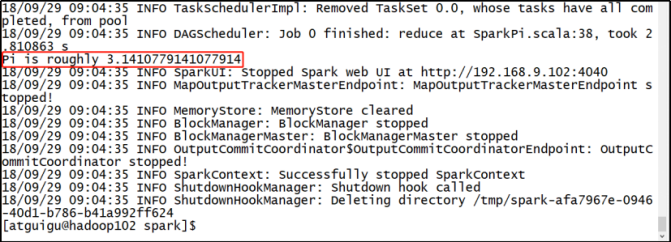
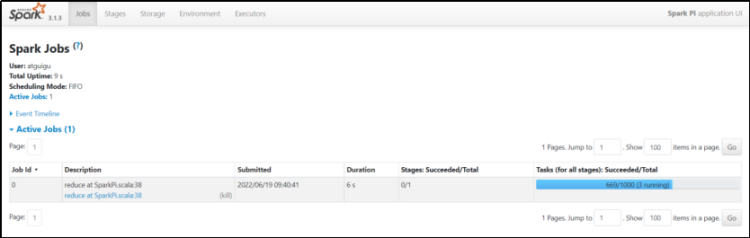
(八)查看运行任务详情
在任务还处于运行状态时,可以通过hadoop100:4040来查看。请注意,一旦任务结束,则这个界面就不可访问了。