【每天一个知识点】主题建模(Topic Modeling)
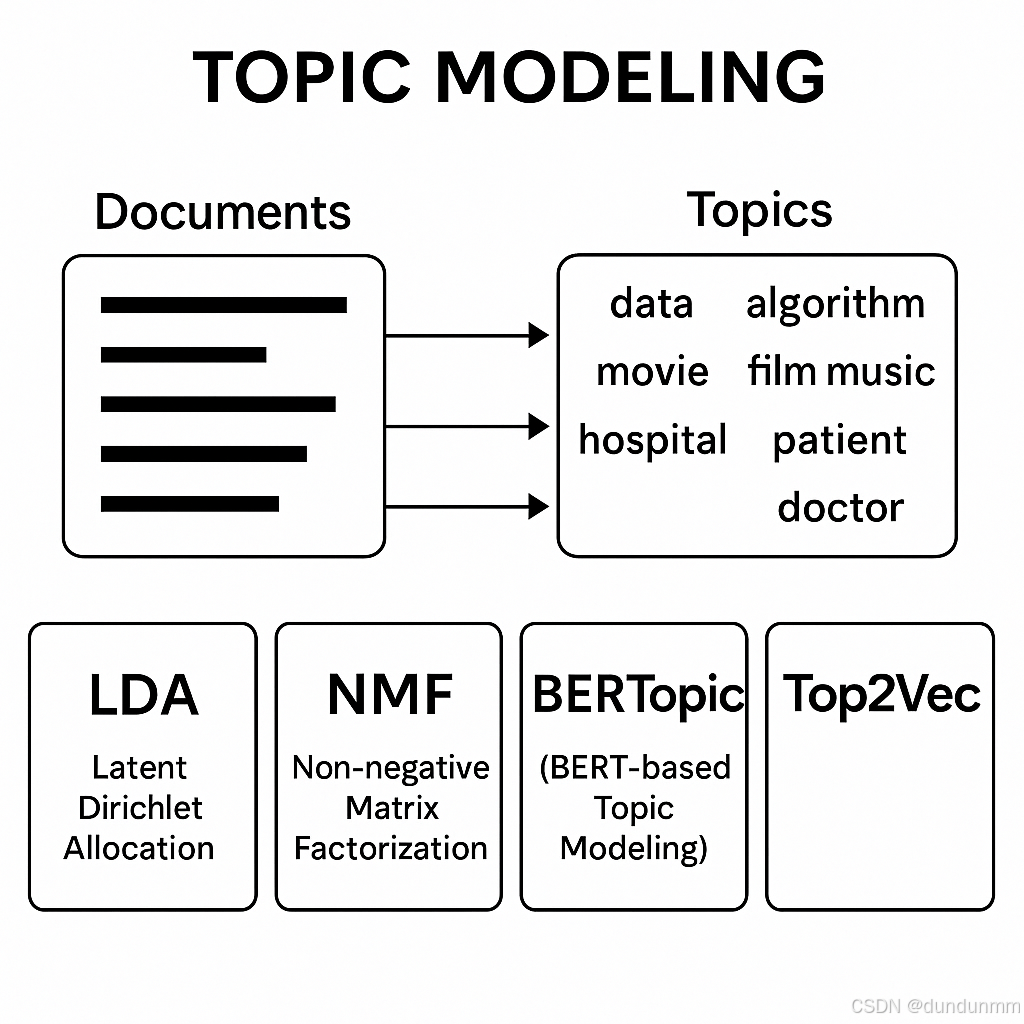
在自然语言处理(Natural Language Processing, NLP)领域,主题建模是一种重要的无监督学习技术,旨在从大量非结构化文本中自动识别出潜在的语义结构或“主题”(Topic)。每个主题可被理解为一组具有一定语义关联性的关键词集合,而每篇文档则被建模为若干主题的概率分布。这一技术已广泛应用于文档归类、舆情分析、推荐系统、知识图谱构建、信息检索等诸多场景之中。
一、主流主题建模方法
1. LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)
LDA是目前最为经典的主题建模算法,由Blei等人于2003年提出。它基于一种生成式概率模型,假设:
-
每篇文档是多个主题的混合;
-
每个主题是若干单词的概率分布;
-
文档中的每个单词都是通过“先从主题分布中采样主题,再从该主题中采样词汇”来生成的。
该算法通过变分推断或吉布斯采样求解参数,可输出每个主题下的高频关键词,以及每篇文档的主题分布,从而实现语义理解与聚类。
优点包括模型解释性强、理论成熟、支持大规模训练,广泛用于政务、金融、医疗等领域的文本分析任务。但其缺点也较为明显:对超参数(如主题数量、Dirichlet分布先验)敏感,且在处理短文本或语义模糊文本时效果不佳。
2. NMF(Non-negative Matrix Factorization,非负矩阵分解)
NMF从线性代数的角度对文档-词语矩阵进行非负矩阵分解,从而获得主题-词矩阵和文档-主题矩阵。该方法相比LDA更加简单,计算效率更高,且具有稀疏性,有利于可视化。
NMF适用于文档结构清晰、语料较干净的场景,常用于新闻聚类、学术论文分类等应用。但由于其本质上是一种数值方法,缺乏明确的概率语义解释,可能会影响在某些任务中的适用性。
3. BERTopic:基于嵌入与聚类的现代主题建模方法
随着预训练语言模型(如BERT、RoBERTa)的兴起,主题建模也逐步演进为更具语义表达能力的新一代模型。BERTopic 是近年来较为先进的一个主题建模框架,它采用如下流程:
-
利用BERT等模型对文档进行句向量嵌入;
-
通过UMAP进行降维;
-
利用HDBSCAN进行密度聚类;
-
从聚类结果中提取主题关键词。
该方法的优点是能捕捉上下文语义信息,聚类结果更加贴合人类语义认知,特别适合用于语义搜索、问答系统的文档预处理阶段。
BERTopic的主题标签可根据TF-IDF、c-TF-IDF或关键短语提取(如KeyBERT)方法生成,支持交互式可视化,适用于分析高维语义空间中的文本结构。
4. Top2Vec:文档与词语共嵌入的自组织主题建模
Top2Vec是一种创新的无监督主题建模方法,核心思想是将文档和词语同时映射到同一个嵌入空间中,从而通过空间密度聚类自动发现语义接近的主题簇。该方法的优点包括:
-
不需要预设主题数;
-
可发现细粒度语义;
-
输出的主题词具有较好的上下文关联性。
适合用于海量文本中挖掘潜在知识结构,尤其是在数据驱动的应用场景中表现出色。
二、主题建模的应用价值与适用场景
主题建模能够在数据预处理阶段提升文本理解能力,在多个领域具有广泛应用价值:
-
文档聚类与自动分类:通过主题分布对文档进行分类或分组,提升信息组织效率;
-
舆情分析:识别社交媒体、评论平台上的热点话题及其变化趋势;
-
信息检索与问答系统:构建主题索引结构,实现精准召回与语义增强;
-
数据标签推荐与知识图谱构建:基于主题标签为文本标注语义元信息,辅助实体识别与关系抽取;
-
文本摘要与内容推荐:将文档映射为主题向量,用于个性化推荐或多文档摘要。
主题建模作为理解和组织文本语料的关键技术,已经从传统的概率模型(如LDA)演进到融合预训练语言模型与聚类技术的新一代方法(如BERTopic、Top2Vec)。在智能问答、语义聚类、金融数据要素治理等复杂场景中,合适地引入主题建模不仅有助于提升问答系统的检索精度与响应准确性,也为系统的可解释性、安全性与知识管理提供了坚实基础。