ViViT: 一种视频视觉Transformer
摘要
我们提出了基于纯transformer的视频分类模型,借鉴了这种模型在图像分类中的成功经验。我们的模型从输入视频中提取时空token,然后通过一系列transformer层进行编码。为了处理视频中遇到的长序列token,我们提出了几种高效的模型变种,这些变种将输入的空间和时间维度进行了分解。尽管基于transformer的模型通常只有在有大量训练数据时才有效,但我们展示了如何在训练过程中有效地正则化模型,并利用预训练的图像模型,在相对较小的数据集上进行训练。我们进行了彻底的消融研究,并在多个视频分类基准测试上取得了最先进的结果,包括Kinetics 400和600、Epic Kitchens、Something-Something v2和Moments in Time,超过了基于深度3D卷积网络的先前方法。为了促进进一步的研究,我们在https://github.com/google-research/scenic发布了代码。
1. 引言
基于深度卷积神经网络的方法自AlexNet [38]以来,已经推动了视觉问题标准数据集上的最先进技术。同时,序列到序列建模(例如自然语言处理)中最突出的架构是transformer [68],它不使用卷积,而是基于多头自注意力机制。该操作在建模长程依赖关系方面特别有效,允许模型在输入序列的所有元素之间进行注意力操作。这与卷积的“感受野”形成鲜明对比,后者是有限的,并随着网络深度的增加而线性增长。
自注意力模型在自然语言处理中的成功,最近激发了计算机视觉领域的研究,尝试将transformer集成到CNN中 [75, 7],以及一些完全替代卷积的尝试 [49, 3, 53]。然而,直到最近,纯transformer架构在图像分类中超越了其卷积对手,这一成就出现在Vision Transformer (ViT) [18]中。Dosovitskiy 等人 [18] 紧跟[68]的原始transformer架构,并注意到其主要优势是在大规模数据上得到体现——由于transformer缺乏卷积的一些归纳偏置(如平移不变性),它们似乎需要更多的数据 [18] 或更强的正则化 [64]。
受ViT启发,并考虑到自注意力架构在建模视频中的长程上下文关系时的直观性,我们开发了几种基于transformer的视频分类模型。目前,性能最好的模型基于深度3D卷积架构 [8, 20, 21],这些模型是图像分类CNN [27, 60] 的自然扩展。最近,这些模型通过在其后层引入自注意力机制,以更好地捕捉长程依赖关系 [75, 23, 79, 1]。
如图1所示,我们提出了用于视频分类的纯transformer模型。该架构中执行的主要操作是自注意力,并且它是计算在从输入视频中提取的时空token序列上。为了有效处理视频中可能遇到的大量时空token,我们提出了几种沿空间和时间维度分解模型的方法,以提高效率和可扩展性。此外,为了在较小的数据集上有效训练我们的模型,我们展示了如何在训练过程中对模型进行正则化,并利用预训练的图像模型。
我们还注意到,卷积模型已经由社区开发了多年,因此与这些模型相关的“最佳实践”已经有了很多。由于纯transformer模型具有不同的特性,我们需要确定这些架构的最佳设计选择。我们对token化策略、模型架构和正则化方法进行了彻底的消融分析。在此分析的基础上,我们在多个标准视频分类基准测试中取得了最先进的结果,包括Kinetics 400和600 [35]、Epic Kitchens 100 [13]、Something-Something v2 [26] 和 Moments in Time [45]。
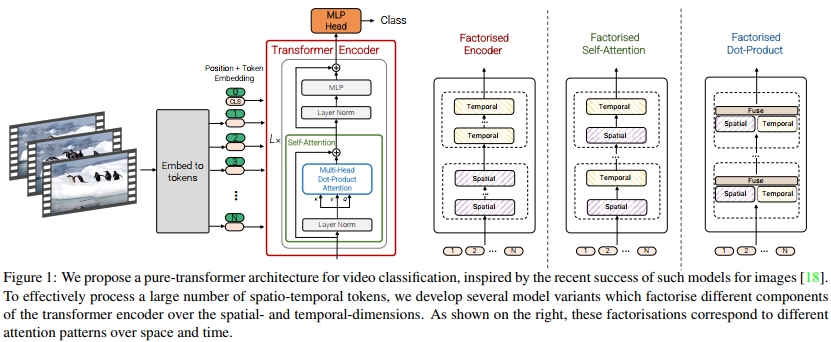
2. 相关工作
视频理解的架构与图像识别的进展相一致。早期的视频研究使用手工提取的特征来编码外观和运动信息 [41, 69]。AlexNet 在 ImageNet [38, 16] 上的成功最初促使了 2D 图像卷积网络 (CNN) 被用于视频处理,形成了“二流”网络 [34, 56, 47]。这些模型分别处理 RGB 帧和光流图像,然后在最后进行融合。随着像 Kinetics [35] 这样的更大视频分类数据集的出现,推动了时空 3D CNN 的训练 [8, 22, 65],这些模型拥有显著更多的参数,因此需要更大的训练数据集。由于 3D 卷积网络比图像卷积网络需要更多的计算,许多架构在空间和时间维度上对卷积进行了分解,或使用了分组卷积 [59, 66, 67, 81, 20]。我们也利用了视频的空间和时间维度的分解来提高效率,但是在基于 transformer 的模型中进行的。
与此同时,在自然语言处理 (NLP) 领域,Vaswani 等人 [68] 通过用只包含自注意力、层归一化和多层感知机 (MLP) 操作的 transformer 网络替代卷积和递归网络,取得了最先进的结果。目前,NLP 领域的最先进架构 [17, 52] 仍然是基于 transformer 的,并且已被扩展到 Web 规模的数据集 [5]。为了减少处理更长序列时自注意力的计算成本,许多 transformer 变体也被提出 [10, 11, 37, 62, 63, 73],并且为了提高参数效率 [40, 14],这些变体在许多任务中得到了应用。尽管自注意力在计算机视觉中得到了广泛应用,但与此不同的是,它通常被集成到网络的后期阶段或通过残差块 [30, 6, 9, 57] 来增强 ResNet 架构中的一层 [27]。
虽然之前的工作曾试图在视觉架构中替代卷积 [49, 53, 55],但直到最近,Dosovitskiy 等人 [18] 通过他们的 ViT 架构表明,类似于 NLP 中使用的纯 transformer 网络,也可以在图像分类中取得最先进的结果。作者展示了这种模型只有在大规模数据集下才有效,因为 transformer 缺乏卷积网络的一些归纳偏置(如平移不变性),因此需要比常见的 ImageNet ILSVRC 数据集 [16] 更大的数据集来进行训练。ViT 激发了社区中的大量后续工作,我们注意到有一些同时的研究尝试将其扩展到计算机视觉中的其他任务 [71, 74, 84, 85],以及提高其数据效率的研究 [64, 48]。特别是,文献 [4, 46] 也提出了用于视频的 transformer 模型。
本文中,我们开发了用于视频分类的纯 transformer 架构。我们提出了几种模型变体,其中包括通过分解输入视频的空间和时间维度来提高效率的变体。我们还展示了如何利用额外的正则化和预训练模型来应对视频数据集不像 ViT 最初训练的图像数据集那样庞大的问题。此外,我们在五个流行数据集上超越了最先进的技术。
3. 视频 Vision Transformer
我们首先在第 3.1 节简要介绍最近提出的 Vision Transformer [18],然后在第 3.2 节讨论两种从视频中提取 token 的方法。最后,我们在第 3.3 和第 3.4 节中提出几种用于视频分类的基于 transformer 的架构。
3.1 Vision Transformer (ViT) 概述
Vision Transformer(ViT)[18] 将 [68] 中的 transformer 架构最小化修改后应用于处理二维图像。具体而言,ViT 从图像中提取 N N N个不重叠的图像 patch, x i ∈ R h × w x_i \in \mathbb{R}^{h \times w} xi∈Rh×w,对其进行线性投影后展开为一维 token z i ∈ R d z_i \in \mathbb{R}^d zi∈Rd。输入到后续 transformer 编码器中的 token 序列为:
z = [ z c l s , E x 1 , E x 2 , … , E x N ] + p , (1) \mathbf{z} = [z_{cls}, \mathbf{E}x_1, \mathbf{E}x_2, \ldots, \mathbf{E}x_N] + \mathbf{p}, \tag{1} z=[zcls,Ex1,Ex2,…,ExN]+p,(1)
其中 E \mathbf{E} E表示线性投影操作,其本质等价于一个 2D 卷积。如图 1 所示,一个可学习的分类 token z c l s z_{cls} zcls会被加在序列开头,并在 transformer 编码器的最终层中作为分类器使用的最终表示 [17]。另外,为了保留位置信息,还会为 token 加上可学习的位置编码 p ∈ R N × d \mathbf{p} \in \mathbb{R}^{N \times d} p∈RN×d,因为 transformer 中的 self-attention 机制本身对序列位置顺序是不敏感的(permutation invariant)。
这些 token 随后会被输入到一个由 L L L层 transformer 构成的编码器中。每一层 l l l包括多头自注意力(Multi-Headed Self-Attention, MSA)[68]、层归一化(Layer Normalisation, LN)[2] 和 MLP 模块,其计算方式如下:
y ℓ = M S A ( L N ( z ℓ ) ) + z ℓ z ℓ + 1 = M L P ( L N ( y ℓ ) ) + y ℓ (3) \begin{array}{r} \mathbf{y}^{\ell} = \mathbf{MSA}(\mathbf{LN}(\mathbf{z}^{\ell})) + \mathbf{z}^{\ell} \\ \mathbf{z}^{\ell + 1} = \mathbf{MLP}(\mathbf{LN}(\mathbf{y}^{\ell})) + \mathbf{y}^{\ell} \end{array} \tag{3} yℓ=MSA(LN(zℓ))+zℓzℓ+1=MLP(LN(yℓ))+yℓ(3)
其中 MLP 由两个线性层和一个 GELU 非线性激活函数 [28] 构成。在整个网络的所有层中,token 的维度 d d d保持不变。
最后,如果在输入序列中添加了分类 token z c l s z_{cls} zcls,则将其在第 L L L层输出的表示 z c l s L ∈ R d z_{cls}^{L} \in \mathbb{R}^d zclsL∈Rd输入至一个线性分类器进行分类;如果没有添加分类 token,则采用所有 token 的全局平均池化作为输入。
由于 transformer 架构 [68] 是一种灵活的结构,能够处理任意 token 序列 z ∈ R N × d \mathbf{z} \in \mathbb{R}^{N \times d} z∈RN×d,接下来我们将介绍用于视频 token 化的策略。
3.2 视频片段嵌入
我们考虑两种简单的方法将视频 V ∈ R T × H × W × C \mathbf{V} \in \mathbb{R}^{T \times H \times W \times C} V∈RT×H×W×C映射到一个 token 序列 z ~ ∈ R n t × n h × n w × d \tilde{\mathbf{z}} \in \mathbb{R}^{n_t \times n_h \times n_w \times d} z~∈Rnt×nh×nw×d。然后我们添加位置嵌入并重新形状调整为 R N × d \mathbb{R}^{N \times d} RN×d,以得到输入到 transformer 的 z z z。
均匀帧采样
如图 2 所示,将输入视频 token 化的一个简单方法是从输入视频片段中均匀采样 n t n_t nt帧,使用与 ViT [18] 相同的方法独立嵌入每一帧 2D 图像,并将这些 token 连接在一起。具体而言,如果每一帧中提取 n h ⋅ n w n_h \cdot n_w nh⋅nw<