BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection
背景
基于多视角图片的3D感知被LSS证明是可行的,它使用估计的深度将图像特征转化为3D视椎,再将其压缩到BEV平面上。对于这个得到的BEV特征图,它支持端到端训练以及各种下游任务。但是对于深度估计这一块学习的深度质量如何,到目前为止没有相关工作研究。
贡献
本文的贡献如下:
- 提出了使用点云深度信息显示监督深度预测,提高了深度预测质量
- 将相机参数加入网络中,能够实现camera-aware功能。
- 提出了深度优化模块,对深度维度进行整合,使其变得紧凑
- 提出了有效体素化和视椎特征级对齐方法
现有问题研究
因此我们在一个基于LSS的基础检测器上进行实验发现,虽然他能在nuscenes数据集上取得不错的指标效果,但是针对深度进行可视化发现,深度估计质量很差,只有一部分区域的特征预测比较合理的深度,而其他地方则并没有。如下图所示,在基础检测器上,深度可视化后,对于物体与地面接触的地方深度估计会好些,别的地方则不会。

在这里回顾一下LSS的基础检测器架构,首先就是图像编码器提取特征,接着是一个深度网络估计这些特征图的深度,接着就是一个视角变换器以及检测头。
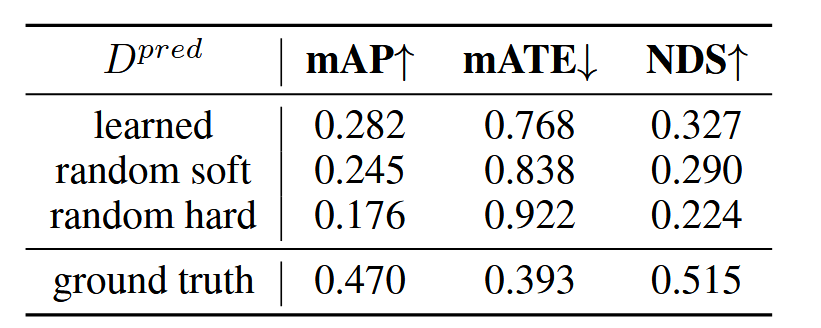
在这里使用对比实验,将我们的深度网络部分替换成随机的深度分布图并冻结,将其用在训练验证中,发现最终得到的mAP指标只降低了3.7%。这说明了即便深度估计质量很差,但是深度分布的性质还是在一定程度上帮助将特征投影到正确的深度位置,因此即便深度估计质量差也能得到一个还行的指标,当然由于质量不佳,肯定也是引入了噪声所以会有指标的降低。为了证明深度分布是有效的,我们将随机的深度分布替换为one-hot深度,指标降低显著,印证猜想。总结下来,只要正确位置的深度有激活,检测头就能工作,即便深度分布不佳,指标也是合理的。通过点云数据生成真实深度标签替代学习的深度可以发现,mAP与NDS提升了快20%,这说明了在深度估计上还有很大的进步空间。
现有的LSS深度学习上有三个不足之处,首先深度预测是通过最终检测损失来间接监督,深度质量不佳;第二就是大多数像素都不能预测合理的深度,这意味着学习时并没有训练好;第三是不准确的深度预测导致只有部分特征投影到正确区域,导致BEV语义信息不佳。
在这里对第一个点做实验发现,对于目标区域所有前景区域进行深度估计,基础检测器与我们使用雷达数据监督深度的增强检测器深度质量相差较多,但是如果是对每个物体预测最好的像素进行深度评估,则两者差不多,这就说明了基于LSS的算法学习了部分的深度。第二个点通过实验发现,深度估计受图像大小、相机内外参等的影响,因此有较高概率过拟合。
具体方法
本文提出了BEVDepth,它在基于相机的深度预测模块上使用显式的深度监督,这就是DepthNet模块,再结合一个深度修正模块进行最终的投影到BEV的操作。
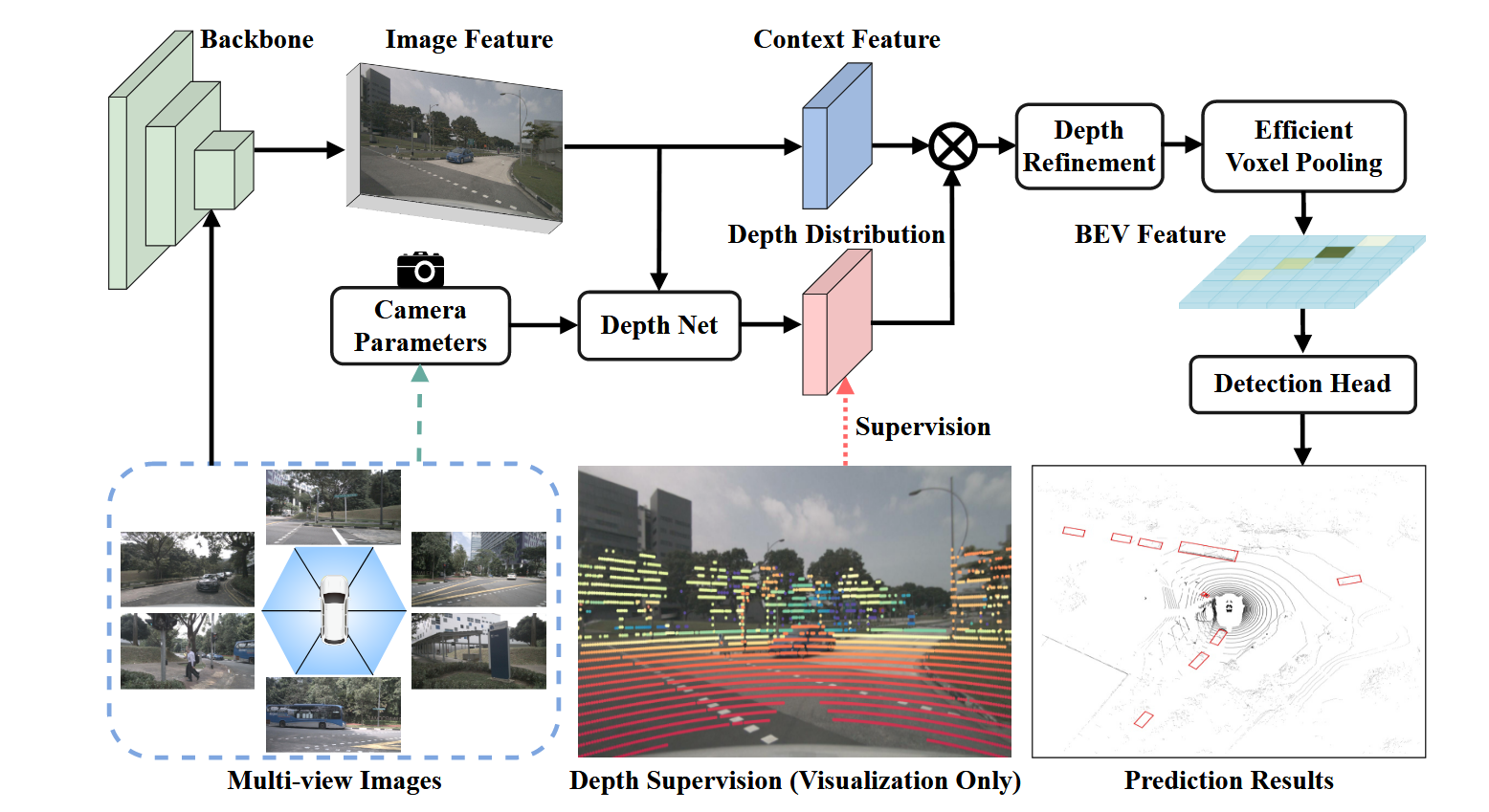
显式深度监督
对于基础的检测器,深度监督唯一来源是检测器的损失,很难有效监督。因此这里提出对于预测的深度分布中间值 D p r e d D^{pred} Dpred进行直接监督,具体是对于点云数据P,结合旋转矩阵 R i R_i Ri与平移矩阵 t i t_i ti将P从世界坐标系转到相机坐标系,再使用相机内参 K i K_i Ki将其转到图像坐标系,公式如下
P i i m g