高性能数据库集群:分库分表
一、引言
前面我们已经介绍了另一种高性能数据库集群,读写分离,其本质是将访问压力分散到集群中的多个节点,但是没有分散存储压力,随着用户数量的增加,数据量激增,数据存储将会是我们系统的瓶颈所在,因此就有了第二种高性能数据库集群,分库分表方案,这种方案既可以分散访问压力,又可以分散存储压力,完美解决了我们现有的系统瓶颈,接下来我们看看,分库分表这种方案。
二、分库
我们首先要明白,分库分表是两回事儿,可能是光分库不分表,也可能是光分表不分库,都有可能。
首先我们先来看看所谓的分库是什么样的。
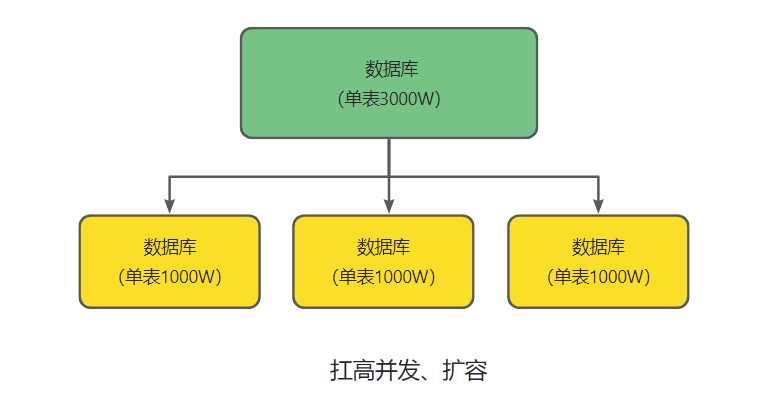
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
不仅如此我们还可以根据业务分库,按照业务模块将数据分散到不同的数据库服务器。例如,一个简单的电商网 站,包括用户、商品、订单三个业务模块,我们可以将用户数据、商品数据、订单数据分开 放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。这是根据我们的业务进行分库。
虽然业务分库能够分散存储和访问压力,但同时也带来了新的问题,接下来我们就进行详细分析。
2.1 事务问题
原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同的数据库中,无法通过事务统一修改。虽然数据库厂商提供了一些分布式事务的解决方案(例如,MySQL 的 XA),但性能实在太低,与高性能存储的目标是相违背的。
2.2 join 操作问题
业务分库后,原本在同一个数据库中的表分散到不同数据库中,导致无法使用 SQL 的 join 查询。使得原本简单的单库表间 JOIN 操作变得复杂。
2.3 成本问题
业务分库同时也带来了成本的代价,本来 1 台服务器搞定的事情,现在要 3 台,如果考虑 备份,那就是 3 台变成了 6 台。
基于上述原因,对于小公司初创业务,并不建议一开始就这样拆分,主要有几个原因:
- 初创业务存在很大的不确定性,业务不一定能发展起来,业务开始的时候并没有真正的存 储和访问压力,业务分库并不能为业务带来价值。
- 业务分库后,表之间的 join 查询、数据库事务无法简单实现了。
- 业务分库后,因为不同的数据要读写不同的数据库,代码中需要增加根据数据类型映射到 不同数据库的逻辑,增加了工作量。而业务初创期间最重要的是快速实现、快速验证,业 务分库会拖慢业务节奏。
三、分表
我们先来思考这个样一个问题你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
单表数据拆分有两种方式:水平分表和垂直分表。
3.1 水平拆分
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
3.2 垂直拆分
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
水平分表相比垂直分表,会引入更多的复杂性,主要表现在下面几个方面:
- 路由:水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算,这个算法 会引入一定的复杂性。
常见的路由算法有:
- 范围路由:选取有序的数据列(例如,整形、时间戳等)作为路由的条件,不同分段分散到 不同的数据库表中。以最常见的用户 ID 为例,路由算法可以按照 1000000 的范围大小进 行分段,1 ~ 999999 放到数据库 1 的表中,1000000 ~ 1999999 放到数据库 2 的表中, 以此类推。
- Hash 路由:选取某个列(或者某几个列组合也可以)的值进行 Hash 运算,然后根据 Hash 结果分散到不同的数据库表中。同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,路由算法可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号, ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的字表中。
- 配置路由:配置路由就是路由表,用一张独立的表来记录路由信息。同样以用户 ID 为例, 我们新增一张 user_router 表,这个表包含 user_id 和 table_id 两列,根据 user_id 就可 以查询对应的 table_id。
四、分库分表带来的问题及解决方案
分库分表虽然缓解了我们存储上带来的瓶颈,但是同时也引入了其他的问题,最常见的有以下几个问题:
- 跨库查询
采用分库分表之后,如何满足跨越分库的查询?使用ES的宽表。
借助分库网关+分库业务虽然能够实现多维度查询的能力,但整体上性能不佳且对正常的写入请求有一定的影响。业界应对多维度实时查询的最常见方式便是借助 ElasticSearch;
- 数据倾斜
数据分库基础上再进行分表;
- 深分页问题
按游标查询,或者叫每次查询都带上上一次查询经过排序后的最大 ID;
4.1 分库分表优化
由于数据量过大,进行了分库分表,当时分库分表初期经常产生一些问题。典型的就是查询中使用了深分页,通过一些工具如MAT、Jstack追踪到是由于sharding-jdbc内部引用造成的。
当数据被存放在两个库中。如果没有提供切分键,查询语句就会被分发到所有的数据库中,比如查询语句是 limit 10、offset 1000,最终结果只需要返回 10 条记录,但是数据库中间件要完成这种计算,则需要 (1000+10)*2=2020 条记录来完成这个计算过程。如果 offset 的值过大,使用的内存就会暴涨。虽然 sharding-jdbc 使用归并算法进行了一些优化,但在实际场景中,深分页仍然引起了内存和性能问题。这种在中间节点进行归并聚合的操作,在分布式框架中非常常见。
业界解决方案:
方法一:全局视野法
(1)将order by time offset X limit Y,改写成order by time offset 0 limit X+Y
(2)服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录
这种方法随着翻页的进行,性能越来越低。
方法二:业务折衷法-禁止跳页查询
(1)用正常的方法取得第一页数据,并得到第一页记录的time_max
(2)每次翻页,将order by time offset X limit Y,改写成order by time where time>$time_max limit Y
以保证每次只返回一页数据,性能为常量。
方法三:业务折衷法-允许模糊数据
(1)将order by time offset X limit Y,改写成order by time offset X/N limit Y/N
方法四:二次查询法
(2)将order by time offset X limit Y,改写成order by time offset X/N limit Y
(3)找到最小值time_min
(4)between二次查询,order by time between timeminandtime_i_max
(5)设置虚拟time_min,找到time_min在各个分库的offset,从而得到time_min在全局的offset
(6)得到了time_min在全局的offset,自然得到了全局的offset X limit Y
五、小结
本文主要讲解了高性能数据库集群的分库分表架构,包括业务分库产生的问题和分表的两种方式及其带来的复杂度,以及分库分表带来的一些问题及解决方案。