MySQL索引知识点(笔记)
索引
1.什么是索引?有什么用?
![]()

一个表在制定了主键后,后自动创建主键索引.表数据根据这个主键索引会存储相应的数据,并构成b+树数据结构
索引为什么可以提高检索效率? 其实最根本的原理是缩小了扫描的范围
例如:对于一本字典来说,查找某个汉字
a.一页一页的找,直到找到为止,全字典扫描、
b.先通过目录(索引)去定位一个大概的位置,然后直接定位到这个位置,做局域扫描,缩小扫描范围,快速查找,通过索引检索,效率很高
* 索引虽然可以提高检索效率,但是不能随意的添加索引,因为索引也是数据库当中的对象,也需要数据库不断的维护.是有维护成本的.比如,表中的数据经常被修改.这样就不适合添加索引,因为数据一旦修改,索引需要重新排序,进行维护!
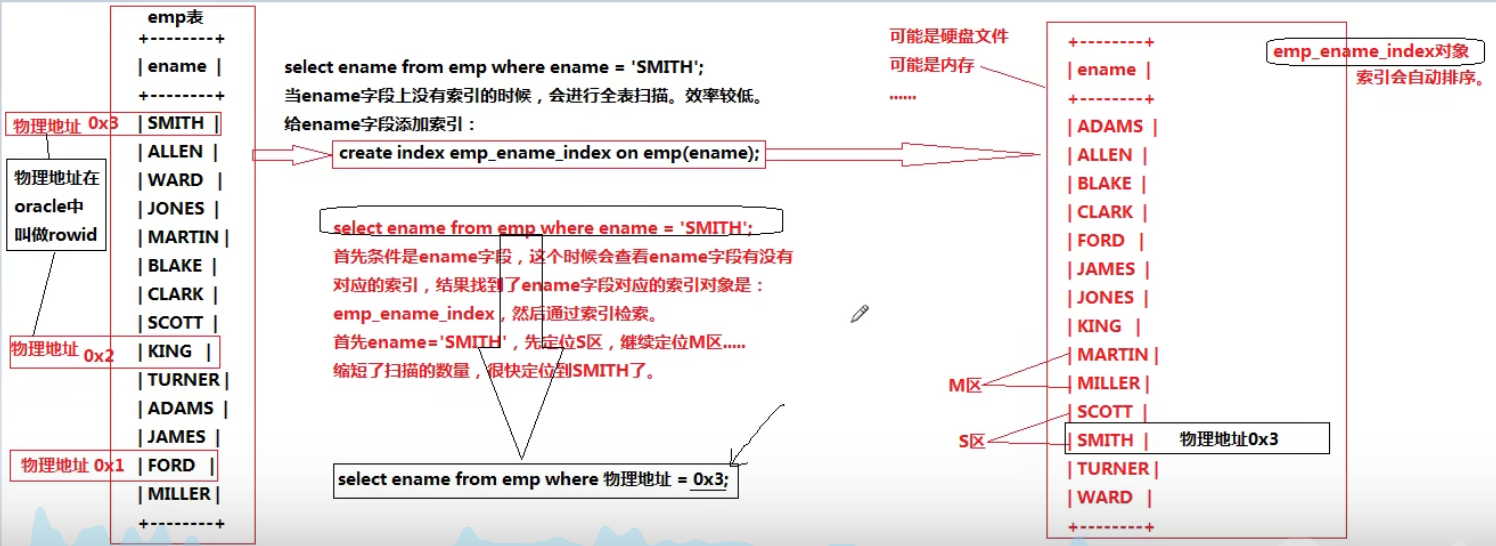
例:select*from user where user.name='jack'
第一种情况:
添加了name索引,以上的这条sql语句会去name的字段上扫描(检索 index nameindex),一条一条的找,因为name=‘jack’,相当于扫描的东西少了,
name字段是目录,目录也需要排序,也就是索引,只有排序才会有区间查找
第二种情况:
如果没有添加(创建)name索引,mysql会进行全表扫描,会将name字段上的每一个值都比对一遍
加与不加索引的区别:
![]()

当在索引中找到一个要查找的数据后,不再去表上查找,而是直接通过索引中这个数据的物理地址直接定位到硬盘上,效率就很高.
什么时候考虑给字段添加索引?(满足什么条件)?
* 数据量庞大.(根据客户的需求,线上的环境)
* 该字段很少的DML操作.(因为字段进行修改操作,索引也需要维护)
*![]() (经常根据哪个字段查询..)
(经常根据哪个字段查询..)
注意:
![]()
* 创建主键会生成主键索引
* unique约束会生成唯一索引
* 外检约束会生成普通索引
*mysql当中索引也需要排序,并且这个索引的排序和treeSet数据结构相同,treeSet底层是一个自平衡二叉树,遵循左小右大原则,
采用中序遍历
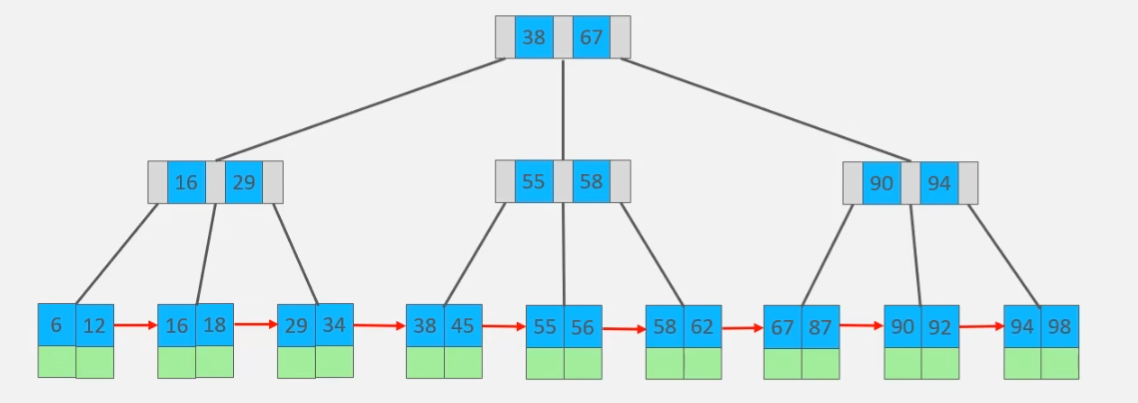
索引是一个B-tree数据结构
根据主键查询效率较高.尽量根据主键检索
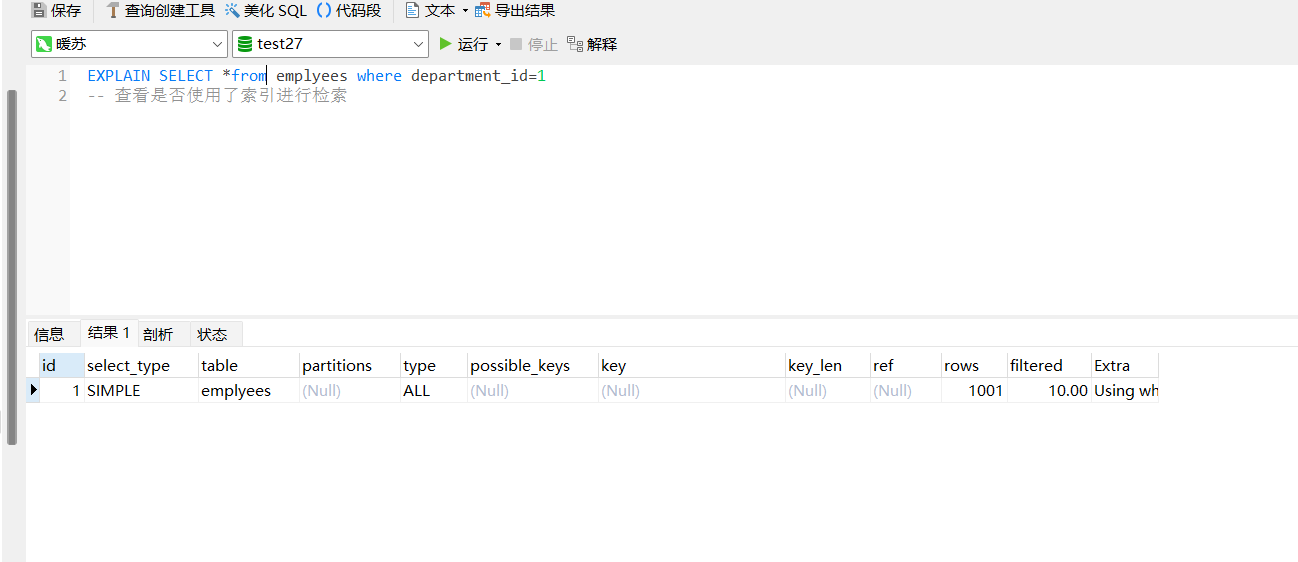
查看sql语句的执行计划:

type:all,表示没有索引
给薪资sal字段添加索引:
create index emp_sal_index on emp(sal);

(MySQL索引底层是由B + Tree树的数据结构实现的)
索引的实现原理:
只要一创建索引,也就是只要create语句一执行.就会在内存中或者硬盘上创建一个对应的索引(要注意创建索引的时候会把记录的物理地址携带过去)
创建出的索引其实就是一个索引对象!
索引创建的时候会自动排序!
索引对象中可能会分区!
分区之后会把这些数据拆分开存储在BTree上
物理地址/物理位置: 在硬盘上也会有一个硬盘编号.数据库当中的任何一条记录(一行记录)都会有物理地址(在硬盘上叫硬盘编号)(在表中),当创建索引的时候,会把每一条记录的物理地址携带过去.
理解:![]()

当根据索引定位到smith之后,通过smith拿到这条记录的物理地址,马上
![]()
这条sql语句变形成
![]()
!!这条转换后的sql语句不再走表了!!而是直接定位的是硬盘上的这个数据!!(重点)
也就是缩短了扫描的范围.

补充:
索引的分类?索引是各种数据库进行优化的重要手段,优化的时候优先考虑索引

索引什么时候失效??
a.模糊查询的时候,第一个通配符使用的是%,这个时候索引是失效的.不会走索引,因为模糊匹配当中以百分号开头,尽量避免,这也是优化的一种策略;
b.使用or的时候也会失效,如果使用or那么要求or两边的条件字段都有索引,才会走索引,就算两者之中有一个
c.使用复合索引的时候,没有使用左侧的列查找,索引失效(两个字段或者更多的字段联合起来添加一个索引
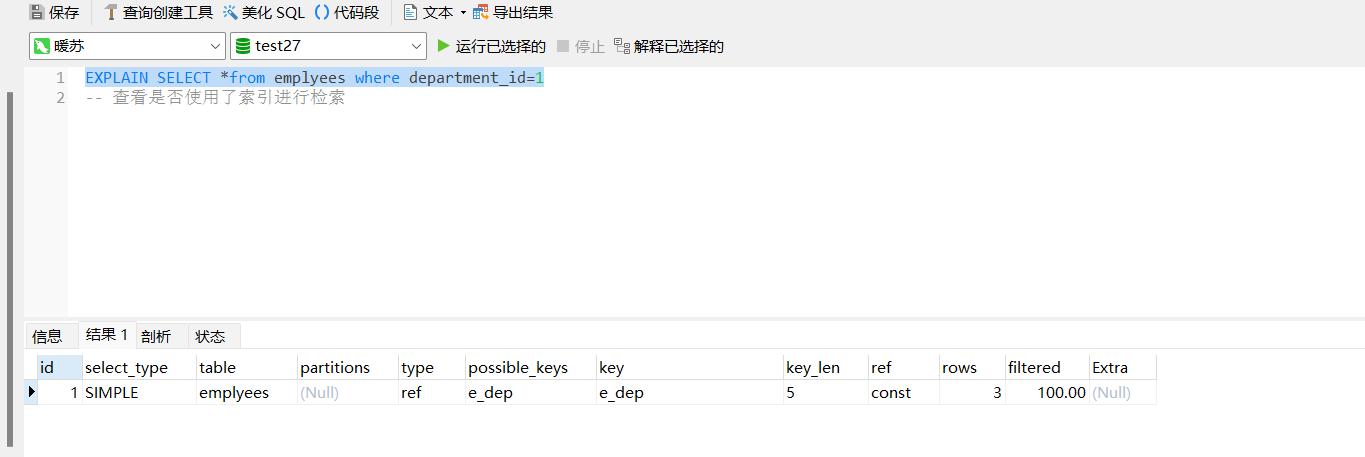
create index emp_name_dep on emplyees(name,department_id)
explain select *from where name='xxxx' 有起到索引检索的效果
explain select *from where department_id=1 那么索引失效,那么按照默认的全局查询
d.在where 中索引列参与了运算,那么索引失效
e.在where中索引列参与了函数
实现原理(b+树):
假设有一张用户表,t_user
id(PK) name email address 每一行记录在硬盘上都有物理存储编号
1 zs 0x00001
2 jack 0x00002
3 ls 0x00003
4 tom 0x00005
5 jane
.....a.在任何数据库中,主键都会自动添加索引对象,id字段上自动有索引,id是PK,另外在mysql当中,一个字段上如果有unique约束,也会自动创建索引对象
b.在任何数据库当中,任何一张表的任何一条记录,在硬盘存储上都有硬盘的物理存储编号(肯定表面上看不出来),
c.在mysql当中索引是一个单独的对象,不同的存储引擎以不同形式存在,myISAM,索引存储在.MYI文件中,InnoDB存储引擎当中索引存储在一个逻辑名称当中tablespace的当中,在MEMORY当中索引被存储在内存当中,不管索引存储在哪,索引在mysql当中都是以一个树的形式存在
d.select*from t_user where id=101, 发现id字段上有索引对象,通过索引对象idIndex查找,
遵循查找机制从树根开始查,假如101,判断是比该根节点(100)大走左还是右,这时候比100大,往右子树走....
找到后,通过index索引对象定位到:101(缩小扫描范围,快速定位),再通过101得出物理编号0x00001,此时马上语句转换:
select*from t_user where 物理编号=0x0001(从之前的select*from t_user id=101)
重点:当给字段添加索引的时候,这个字段就会生成树的结构(这个结构的目的就是缩小扫描范围,避免全表扫描,然后拿到我们的存储编号,然后我们通过物理编号快速定位到该条记录),其实这个MySQL的树比我们画的还是要高级(复杂)得多,可能直接扫描一条就能快速找出来
注意不是记录自己排序,而是索引对象会自己去排序。