TORL:解锁大模型推理新境界,强化学习与工具融合的创新变革
在大语言模型(LLMs)推理能力不断提升的当下,如何让模型更高效地解决复杂计算和推理任务成为关键。本文介绍的TORL(Tool-Integrated Reinforcement Learning)框架给出了全新方案。它通过强化学习让大模型自主运用计算工具,性能提升显著,为LLMs发展开辟新方向,一起来了解吧!
论文标题
TORL: Scaling Tool-Integrated RL
来源
arXiv:2503.23383v1 [cs.CL] 30 Mar 2025
https://arxiv.org/abs/2503.23383
开源代码:https://github.com/GAIR-NLP/ToRL
文章核心
研究背景
大语言模型(LLMs)借助强化学习(RL)展现出强大推理能力,同时工具集成推理(TIR)也在提升模型解决复杂计算任务方面发挥重要作用,但现有方法仍存在局限。
研究问题
- 多数现有工具集成推理(TIR)方法通过从更强模型提取轨迹进行监督微调(SFT),限制了模型探索最优工具使用策略的能力。
- 部分应用RL到SFT训练模型的工作,其工具集成在RL框架内的实现透明度低,难以深入理解。
- 传统语言模型推理在面对复杂计算、方程求解等精确计算任务时表现不佳。

主要贡献
- 创新训练框架:提出TORL框架,直接从基础模型进行强化学习,突破了先前监督微调的限制,让模型能通过广泛探索发现最优工具利用策略,这与基于预定模式改进的方法有本质区别。
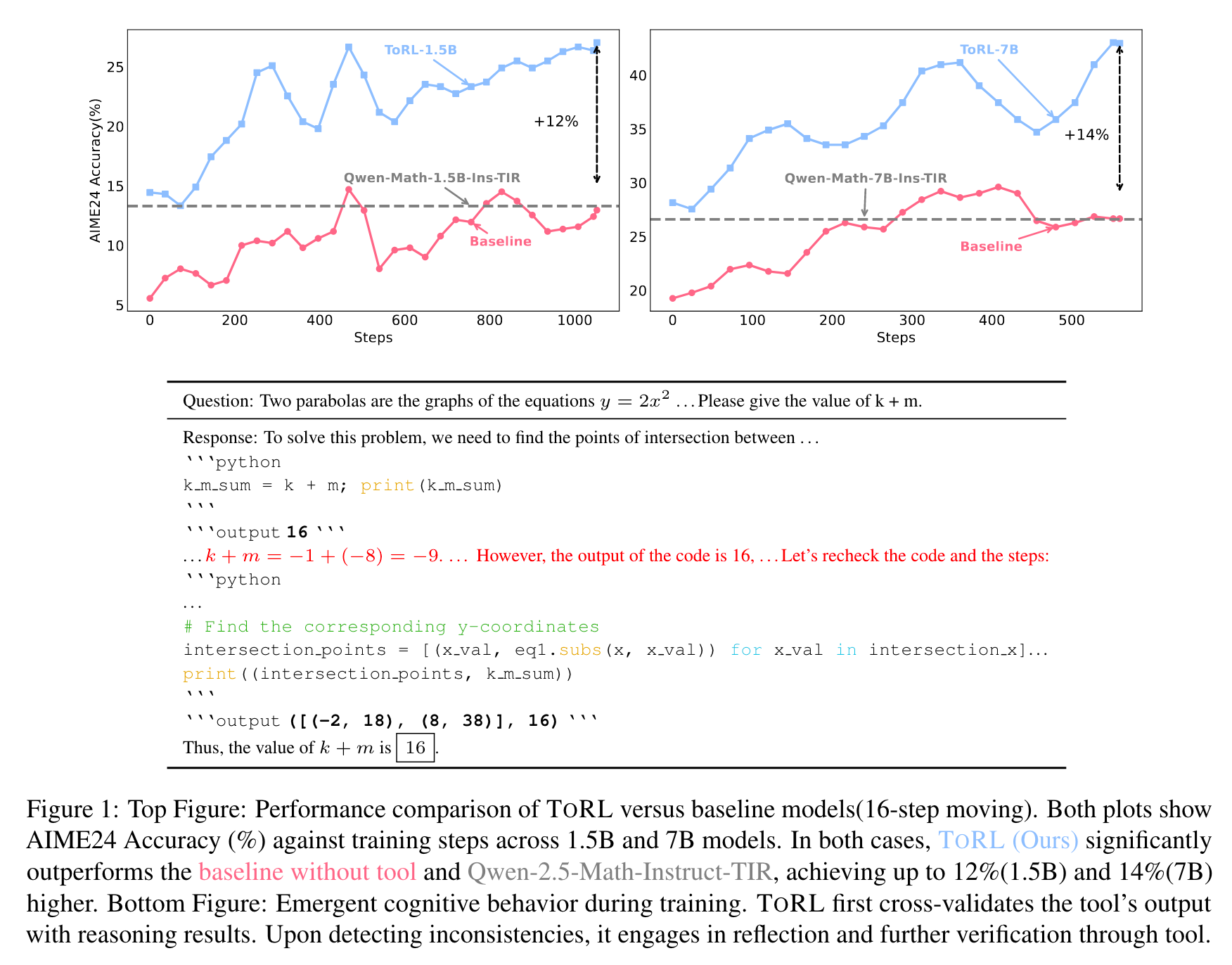
- 显著性能提升:在Qwen2.5-Math基础模型实验中,TORL-7B在AIME24测试上准确率达到43.3%,比无工具集成的RL模型高14%,比现有最好的工具集成推理(TIR)模型高17%,在多个数学基准测试中均优于基线模型。
- 揭示认知行为:发现模型在训练过程中展现出多种新兴认知行为,如策略性工具调用、对无效代码生成的自我调节以及计算和分析推理之间的动态适应,这些行为无需明确指令,仅通过奖励驱动学习就能出现。
- 开源资源推动研究:开源了实现代码、数据集和模型,为研究社区进一步推进工具增强语言模型的发展提供了支持。
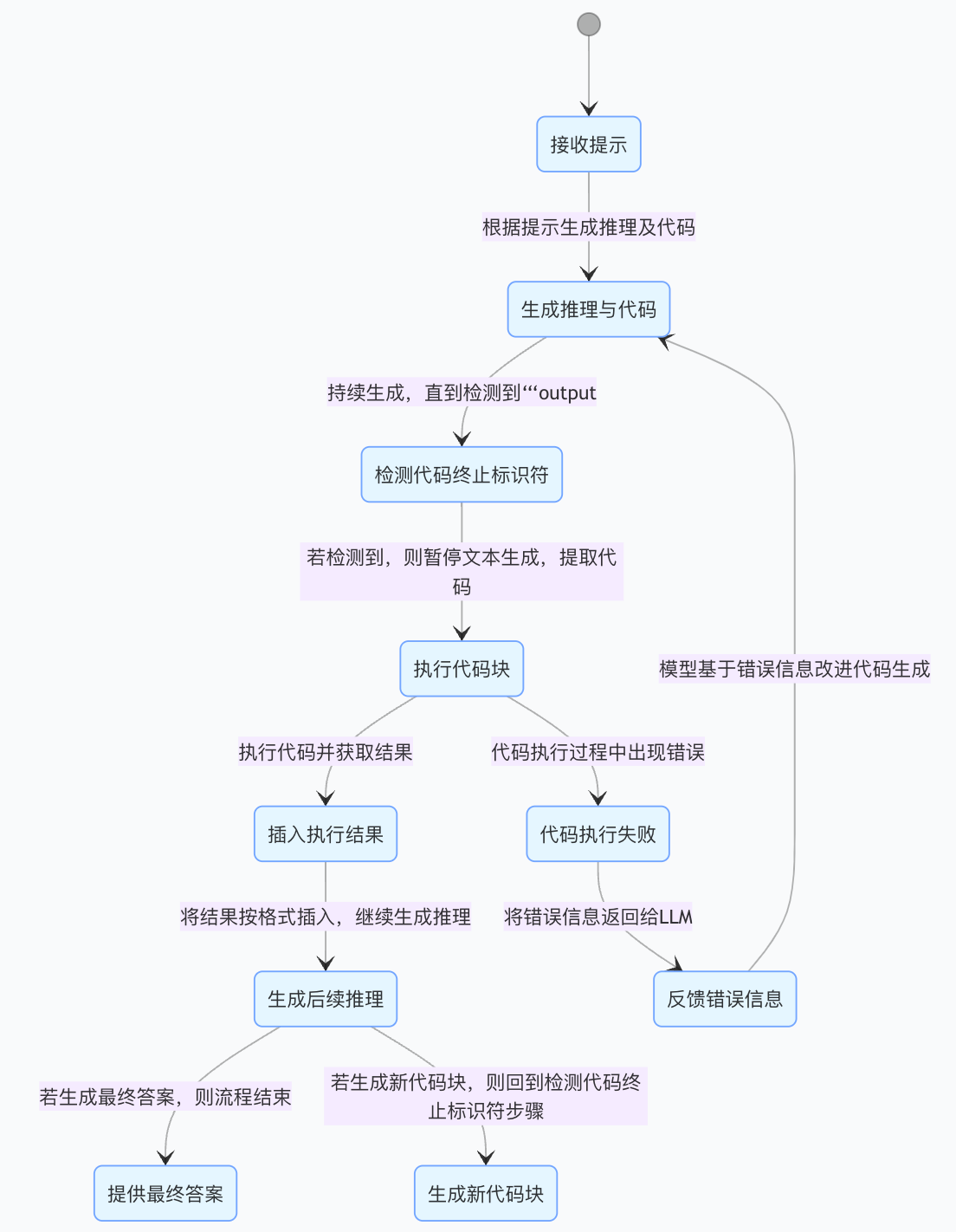
方法论精要
- 核心算法 / 框架:TORL 将工具集成推理(Tool Integrated Reasoning,TIR)与强化学习相结合。TIR 允许大语言模型在推理过程中融入可执行代码,通过迭代的推理与代码执行流程解决问题。在这个过程中,模型会构建推理轨迹,其中包含自然语言推理、生成的代码以及代码的执行结果。强化学习则直接基于基础语言模型展开,使模型在与环境的交互中不断探索,学习到最优的工具利用策略。
- 关键参数设计原理:超参数 c 在 TORL 中至关重要,它用于控制模型在单次响应生成时允许的最大工具调用次数。由于工具集成会引入 GPU 空闲时间,工具调用频率与训练速度呈反比,设置 c 值能够平衡训练效率和模型性能。当模型的工具调用次数达到 c 时,系统会忽略后续的代码执行请求,强制模型切换到纯文本推理模式。
- 创新性技术组合:

- 提示模板设计:运用特定的提示模板(如设定的用户与助手对话模板),引导模型自动输出包含代码块的推理内容。一旦检测到代码终止标识符,系统会暂停文本生成,执行最新的代码块,并将结构化的执行结果插入到上下文当中,推动模型后续的推理。
- 执行环境选择与优化:选择 Sandbox Fusion 作为代码执行环境,它虽然存在一定的延迟,但具备稳定、准确和响应性良好的特点,且能提供隔离的执行环境,有效避免执行错误对整个训练过程的影响。同时,针对 Sandbox Fusion 生成的详细错误信息,只提取最后一行关键信息,减少上下文长度,保留关键错误提示。
- 奖励函数设计:采用基于规则的奖励函数,正确答案给予 1 的奖励,错误答案则为 -1。考虑到代码执行与问题解决准确性的关联,对于包含不可执行代码的响应,会额外给予 -0.5 的奖励惩罚,以此激励模型生成可执行且有助于解决问题的代码。
- 实验验证方式:
- 数据集构建:从 NuminaMATH、MATH 和 DeepScaleR 等来源收集奥林匹克级数学竞赛问题,经过初步筛选去除证明类问题和验证标准模糊的题目,得到 75,149 个可验证问题。再运用 LIMR(一种强化学习数据蒸馏技术),提取高质量样本并平衡难度分布,最终构建出包含 28,740 个问题的数据集用于后续实验。
- 实验设置:使用 veRL 框架和 GRPO 算法开展 RL 实验,选择 Sandbox Fusion 作为代码解释器。设置滚动批次大小为 128,每个问题生成 16 个样本。为增强模型的探索能力,实验中省略 KL 损失并将温度设置为 1。以 Qwen - 2.5 - Math 系列模型作为基础模型,默认最大工具调用次数 c 为 1,且在默认实验中仅保留答案正确性奖励。
- 评估基准:采用贪婪解码(temperature = 0)对所有模型进行评估,选择多个具有挑战性的数学基准测试,包括 AIME24、AIME25、MATH500、OlympiadBench 和 AMC23,将 TORL 模型与多种基线模型(如 Qwen2.5 - Math - 1.5B - Instruct、Qwen2.5 - Math - 1.5B - Instruct - TIR 等)进行对比,以此评估 TORL 模型的性能表现。
实验洞察
- 性能优势:在AIME24测试中,TORL-1.5B准确率达到26.7%,相比Qwen2.5-Math-1.5B-Instruct-TIR提升了13.3%;TORL-7B准确率为43.3% ,相比Qwen2.5-Math-7B-Instruct-TIR提升了10.0%。在多个数学基准测试的平均准确率上,TORL-1.5B达到48.5% ,超越Qwen2.5-Math-1.5B-Instruct-TIR(41.3%);TORL-7B达到62.1% ,相比其他同基础模型的开源模型有显著提升,绝对改进幅度达14.7%。
- 效率突破:研究发现增加最大工具调用次数c虽然能提升模型性能,但会降低训练速度。例如将c从1提高到2时,模型平均准确率提升约2% ,但训练速度明显下降,平均单步时间从237秒增加到288秒(在8*A800 GPU系统上测量)。
- 消融研究:分析关键设置对模型的影响时发现,引入代码可执行性奖励并没有提升模型性能。可能是因为对执行错误的惩罚使得模型为避免错误生成过于简单的代码,从而影响解决问题的能力。同时,模型在训练过程中,随着训练步数增加,使用代码解决问题的比例、正确执行代码的比例都在上升,且能识别和减少无效代码生成,验证了模型自主学习和优化工具使用策略的有效性。
本文由AI辅助完成。