深度学习--ResNet残差神经网络解析
文章目录
- 前言
- 一、什么是ResNet网络
- 二、传统卷积神经网络存在的问题
- 1、梯度消失和梯度爆炸
- 2、退化问题
- 三、如何解决问题
- 四、残差结构
- 五、18层残差网络
- 1、解释
- 2、隔层相加优点
- 3、隔层相加数值增大问题
- 六、18层残差网络以外的表格示例
- 七、BN层(Batch Normalization)
- 1、定义以及操作原理:
- 2、主要作用
- 总结
前言
在ResNet之前,VGG、AlexNet等模型通过增加网络深度提升性能,但人们发现:当网络层数超过20层后,模型的训练误差和测试误差反而会不降反升。这一现象被称为“网络退化”(Degradation),并非由过拟合导致,而是因为深层网络难以优化。
一、什么是ResNet网络
- 2015年,微软研究院的何恺明团队提出了ResNet(Residual NeuralNetwork),这一模型以3.57%的Top-5错误率首次在ImageNet图像识别竞赛中超越人类水平,并成为深度学习历史上的里程碑。ResNet的核心创新在于残差学习(Residual Learning),通过引入“跳级连接”(Shortcut Connection)解决了深度网络训练中的梯度消失和网络退化问题。
- ResNet网络与传统的神经网络的区别在于其独特的残差结构和批次归一化处理,而这也是其最大的两个特点。
二、传统卷积神经网络存在的问题
- 卷积神经网络都是通过卷积层和池化层的叠加组成的。
- 在实际的试验中发现,随着卷积层和池化层的叠加,学习效果不会逐渐变好,反而出现2个问题:
1、梯度消失和梯度爆炸
- 梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
- 梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
2、退化问题
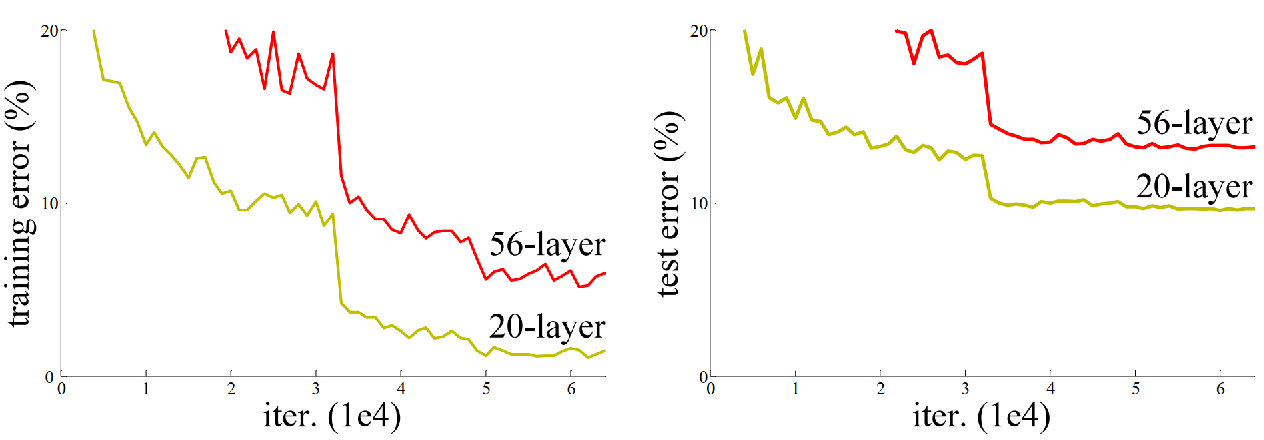
- 上图表示即为当网路是20层和56层时的错误率,可以发现层数越多反而错误率更高
三、如何解决问题
- 为了解决梯度消失或梯度爆炸问题,通过数据的预处理以及在网络中使用 BN(Batch Normalization)层来解决。
- 为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
四、残差结构
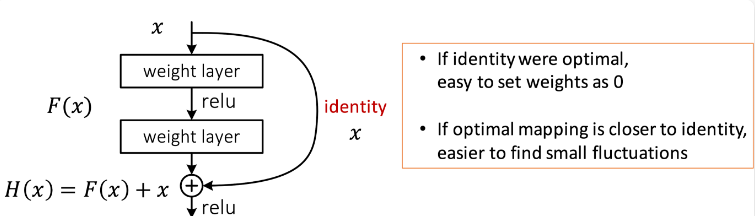
-
残差结构(Residual Block)是ResNet(残差网络)的核心组成部分,解决深层神经网络训练中的退化问题。
-
其主要特点是通过引入跳跃连接(SkipConnection)来实现残差学习,允许网络学习输入和输出之间的残差(即差异),而不是直接学习从输入到输出的映射。
-
让特征矩阵隔层相加,注意F(X)和X形状要相同,
-
F(X)是经过两次卷积层得到的结果,X是原始特征矩阵
-
所谓相加是特征矩阵相同位置上的数字进行相加。
-
相加之后的矩阵作为输入,可以有效解决深层网络退化问题,提高网络的深度
五、18层残差网络
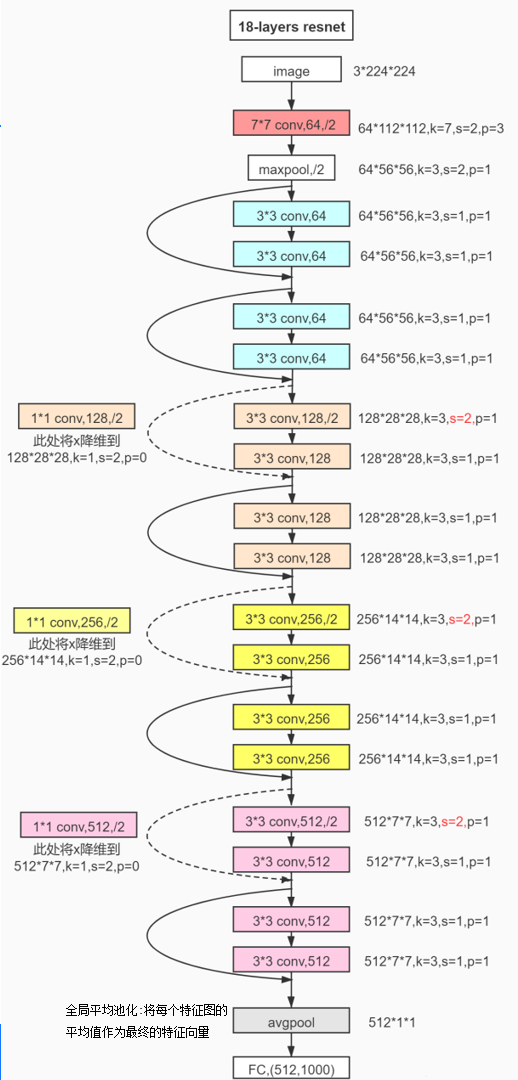
1、解释
上图为18层的卷积神经网络,现传入图片,图片格式为3 * 244 * 244,首先传入到第一层卷积核,卷积核的大小为7 * 7,一共有64个小卷积核,移动步长为2,将图片四周填充3层0值,将其处理完使图片大小变为112 * 112,一共有64张,然后将这么多的特征图进行最大池化,池化层大小为3 * 3,移动步长为2,填充1层,然后得到新的图片格式为64 * 56 * 56,将这些特征图再次传入卷积神经网络,不改变其大小,但是此时发生了改变,这64张大小为56*56的特征图不仅传入下列卷积层,同时又复制一份一样的跳过下面的卷积层,然后再将经过两层卷积层处理过的特征图与没有处理的特征图相加得到新的特征图,此时相加的为特征图中每个像素点对应的数值,然后再一次进行剩余同样的操作…最终对特征图进行全局平均池化,即将每一张图求一个平均值并输出单个值,将这个值当做特征图再次进行全连接,这个全连接有1000个神经元,即输出1000个预测结果。
2、隔层相加优点
-
通过将特征图的数值隔层相加,可以让信息从一层直接传递到另一层,而不受梯度消失的影响。这样可以使得网络更容易进行优化和训练,减少了优化问题的复杂性。同时,残差结构还能够有效地学习到残差的信息,即网络输出与输入之间的差异,从而更好地捕捉到数据中的细微变化和特征。
-
通过隔层相加的方式,残差结构实现了"跳跃连接",使得信息可以直接从较浅的层次直达较深的层次,消除了信息的丢失和模糊化。这样可以提高网络的表达能力,更好地捕捉到输入数据的变化特征,提高了网络的性能和准确率。
3、隔层相加数值增大问题
-
在残差结构中,特征图的数值隔层相加是在两个或多个层的特征图上进行的。这些特征图经过卷积、激活函数等操作后,通常会引入缩放因子(scale factor)或者使用卷积核尺寸为1的卷积层进行调整,以确保两个特征图的通道数相同。
-
此外,残差结构中也会使用批归一化(Batch Normalization, BN)层来进一步调整和稳定特征图的数值。BN层通过对每个特征图的通道进行归一化,将其数值范围限制在较小的范围内,有助于避免数值的过大或过小。BN层还引入了可学习的参数,可以根据数据的分布调整特征图的均值和方差,从而进一步提升网络的性能和收敛速度。
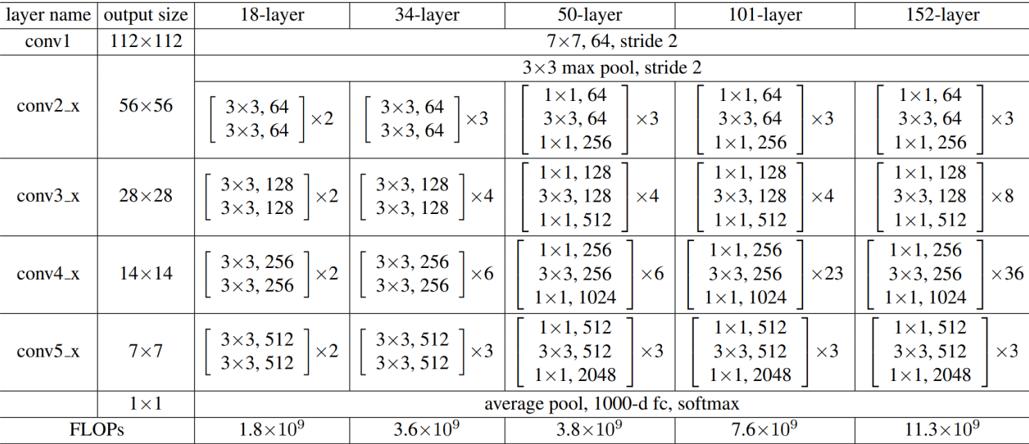
六、18层残差网络以外的表格示例
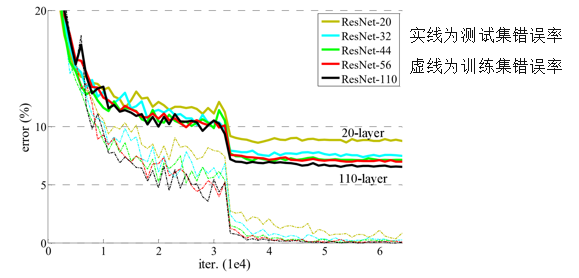
- 18层,34层,50层,101层,152层,及其结构
- 每种结构及其对应的权重参数个数也在上图表示为FLOPs
七、BN层(Batch Normalization)
1、定义以及操作原理:
- BN(BatchNormalization)层在深度学习中被广泛应用,其主要作用是对神经网络的输入进行归一化,以加速网络的训练并提高模型的鲁棒性和泛化能力。
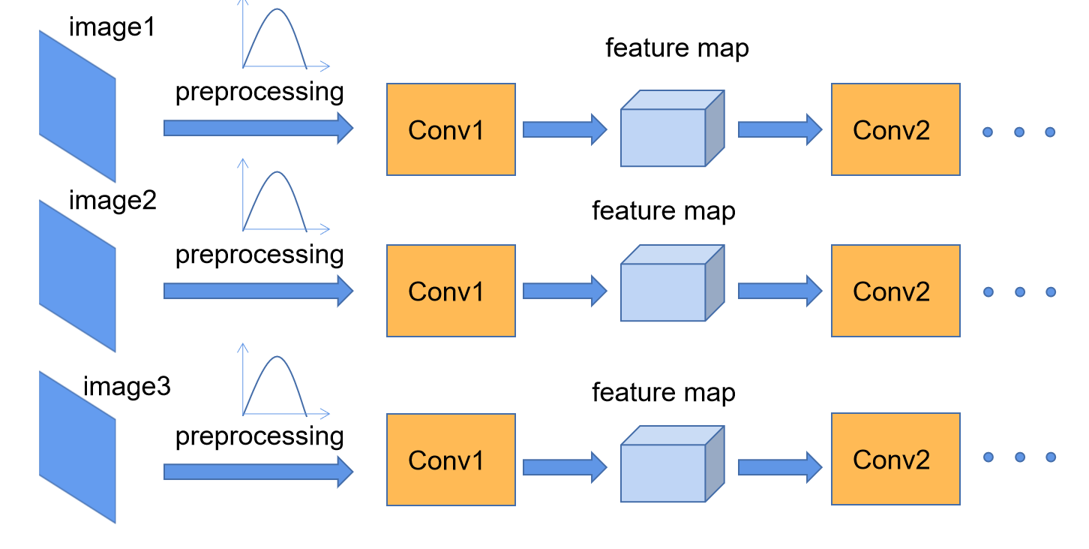
- 如上图所示,对每个传入的图片进行归一化后,将其传入卷积神经层进行处理后得到特征图,然后再对这个特征图进行归一化处理,处理完再次进入卷积层处理,输出的特征图再次进行归一化。
2、主要作用
- 减轻内部协变量偏移:通过标准化每一层的输入,使得其均值接近0,方差接近1,从而减少了层间输入的变化,帮助模型更快地收敛。
- 提高训练速度:批次归一化能够使得更大的学习率得以使用,从而加速训练。
- 缓解梯度消失:通过规范化输入,有助于保持激活值的稳定性,从而在一定程度上减轻了梯度消失现象。
- 具有正则化效果:批次归一化可以在某种程度上减少对其他正则化技术(如Dropout)的依赖,因为它引入了一定的噪声。
- 提高模型泛化能力:通过使训练过程更加稳定,批次归一化有助于提高模型在未见数据上的表现。
总结
ResNet通过残差学习重新定义了深度神经网络的训练方式,解决了深度神经网络的训练难题,成为现代深度学习模型的基石。其设计哲学“让网络学习变化量而非绝对值”不仅提升了模型性能,更启发了后续诸多架构创新,是深度学习发展史上的里程碑。