Linux:进程的概念
基本概念
课本概念:程序的一个可执行实例,正在执行的程序。
内核观点:担当分配系统资源实体。
当操作系统要执行程序时,也就是说操作系统要执行代码,但一个操作系统需要执行多个程序,而CPU只有一块,那么这些需要执行代码的程序要排队依次执行。
CPU有一个task_struct结构体将代码和关于这代码所处程序的信息存起来,比如进程的状态,优先级等,而这个task_struct被称为PCB
为了让进程依次执行,所以需要将进程进程排队,操作系统中有一个链表,就是运行队列,通过将PCB结构体链入链表中的方式来将进程进行排队,所以本质上是PCB给我们的进程排队,不是进程在排队,当有一个PCB被选中的时候,加载对应的进程。
内容分类
以下是一些task_struct的一些信息
标识符:用来标识进程的唯一标识符,用于区别其它进程
状态:任务状态,退出代码,退出信号等。
优先级:相对其它进程的优先级。
程序计数器:程序中即将被执行的下一条语句的地址
内存指针:包括进程代码和程序相关数据的指针,还有和其它进程共享的内存指针块的指针
上下文数据:程序执行时处理器中寄存器的数据
I/O状态信息:包括显示I/O请求,分配给进程的I/O设备和被文件使用的进程列表
再说内存指针,用于标识代码执行到那个语句在下次执行程序时,可以直接运行。
再说记账信息,其存储这进程共占有多久CPU,这样可以让CPU做出更好的决策防止一个进程过久占据CPU.
组织进程
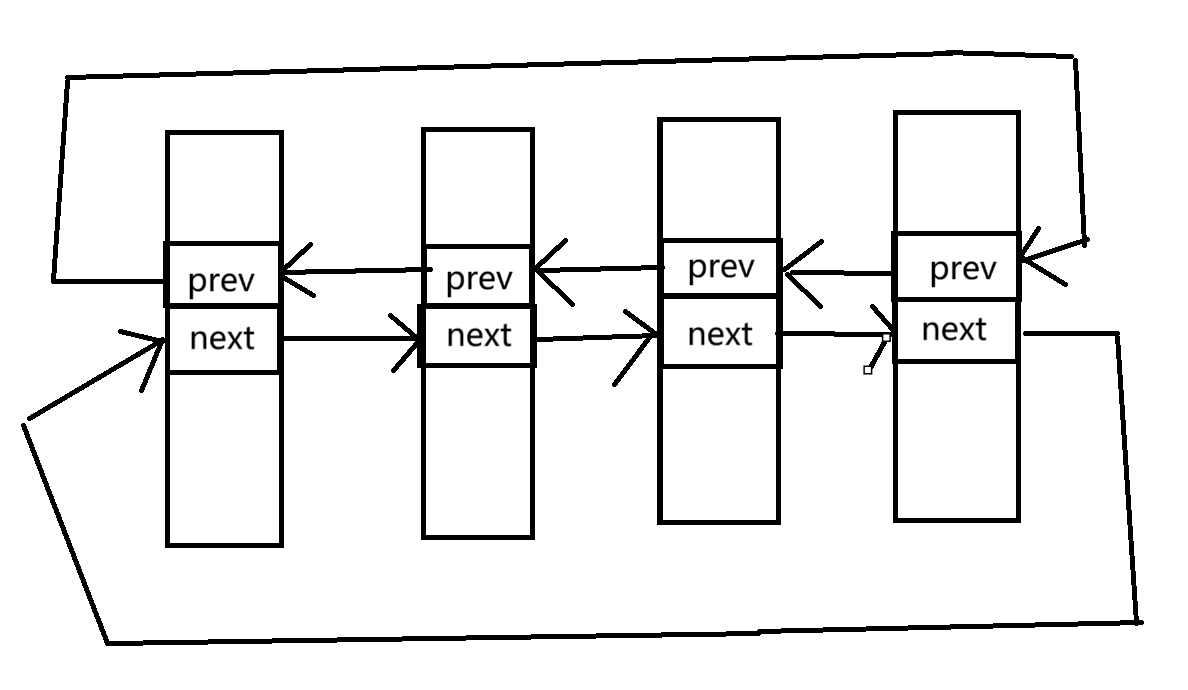
查看进程
进程的信息可以通过/proc系统文件查看所有进程
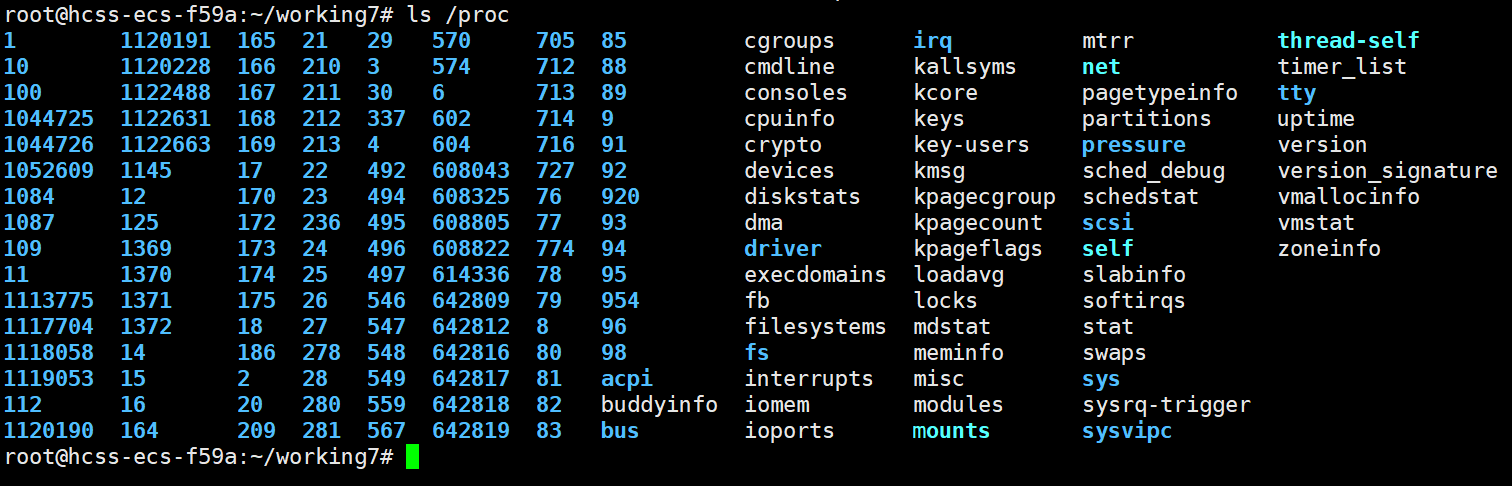
也可以通过 ps axj 和ps aux来查看所有进程状态信息
如果我们想要获取某一个进程的信息我们可以使用ps axj | grep 进程名
这里我们写一个死循环进程,就是一值在运行的进程
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main()
{while(1){printf("我是一个进程,我的PID是%d\n",getpid());sleep(1);}
}
我们开始让这个程序运行
获取进程信息有两种方式
通过进程名获取信息

通过进程PID获取信息

父子进程
在Linux中每个进程都有一个父进程,在刚刚ps axj中PPID就是父进程的PID,查看图片process的父进程PID是1123083
函数getppid()可以获取父进程PID,其包含在unistd.h头文件中,返回值类型是pid_t
写入以下代码
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>int main()
{pid_t pid = getpid();pid_t ppid = getppid();while(1){printf("ppid = %d,pid = %d\n", ppid, pid); sleep(1);}
}
输出结果
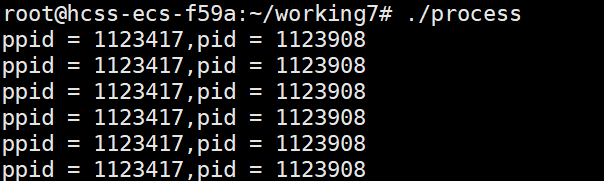
此进程的PID是1123908,父进程的PID是1123417
我们可以用ps axj 来查询以下父进程

这里1123417是bash的进程这里提出一个重要的概念
一切命令行调用的进程都是在bash的子进程
/proc
proc的全称是process,翻译过来就是进程的意思,我们可以通过proc来查看所有进程
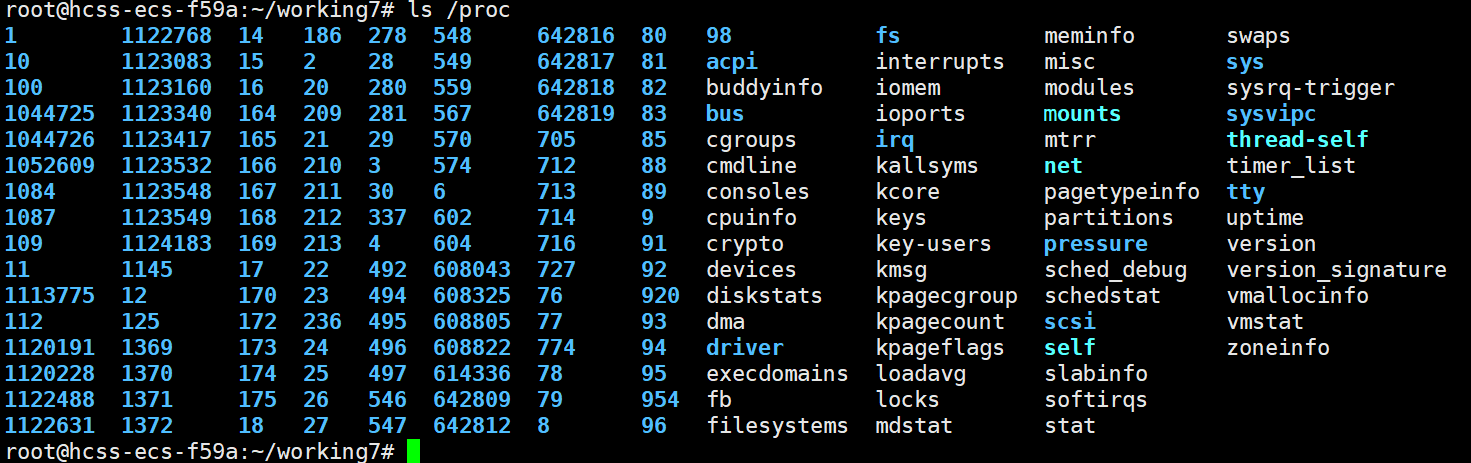
蓝色的代表文件目录,可以看到大部分呢数字都是文件,这些文件对应了PID值,我们之前的bash的PID就是1123160,就在这个文件中,我们可以查看一下
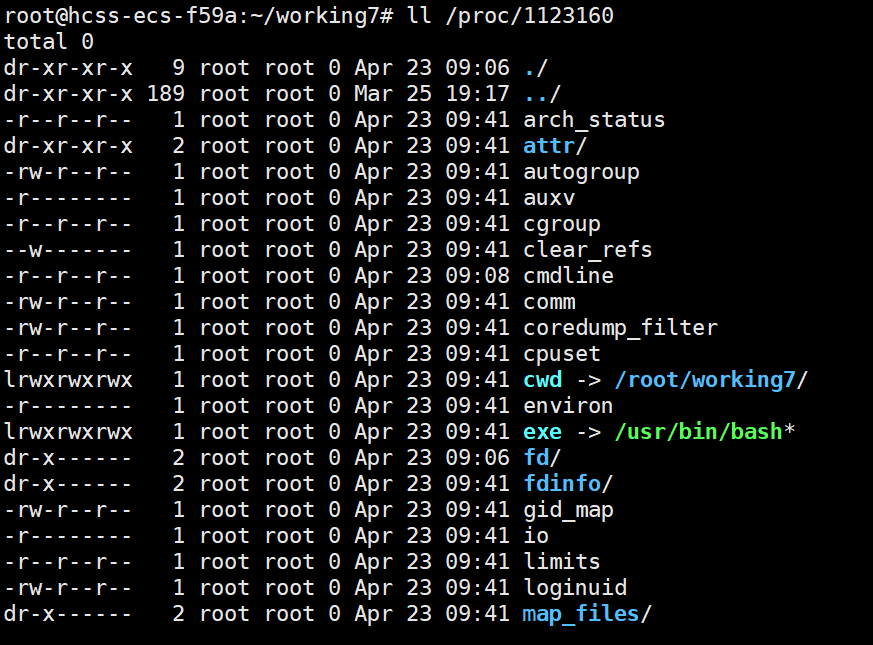
里面存放了很多描述性文件,我们就不一 一举例了,我们就那两个来说明
cwd:当前文件下的路径
我现在的工作路径就是/root/working7/,所有cwd可以显示当前的工作路径
exe:可执行程序路径
exe的可执行路径是/usr/bin/中这个很重要我们以后会讲到
fork
fork可以用来在程序中创建子进程,它的头文件在unistd.h中,直接调用fork就可以创建子进程了
#include <stdio.h>
#include <unistd.h> int main()
{ printf("before: ppid = %d,pid = %d\n", getppid(), getpid()); fork(); printf("after: ppid = %d,pid = %d\n", getppid(), getpid()); return 0;
}
先输出before的pid和ppid,after之后在输出pid和ppid
运行结果
 我们在输出before时只输出了一个before的信息,而fork之后输出了两个after的信息,说明,我们的进程创建成功了,一共运行了两次语句。
我们在输出before时只输出了一个before的信息,而fork之后输出了两个after的信息,说明,我们的进程创建成功了,一共运行了两次语句。
对于第一条语句就是这个进程执行的
而第二条语句的pid和ppid都和第一条一样,说明这两条语句都由一个进程运行
而第三条语句是新的,所以第三条语句是新建立出来的,是原先进程的子进程
fork之后会创建两个进程
一个是原本的进程
一个是原本进程的子进程
fork也有返回值
对于父进程,返回子进程的PID
对于子进程返回0
如果创建失败返回-1
根据fork的返回值判断父子进程
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h> int main()
{ pid_t id = fork(); if(id == 0) { printf("child: ppid = %d,pid = %d\n", getppid(), getpid()); } else { printf("father: ppid = %d,pid = %d\n", getppid(), getpid()); } return 0;
}
输出结果

我们可以来了解一下子进程和父进程
当使用fork创建子进程的时候,子进程是以父进程为模板来进程创建,会继承父进程的PCB,
子进程会和父进程公用一份代码和数据
当子进程需要修改代码或数据时,操作系统会为子进程创建一份需要修改的代码或数据,将需要修改的代码和数据进行创建,将不需要的代码和数据继续和父进程公用。
如果父子进程一旦有某个数据需要修改,就需要写时拷贝,这样父进程和子进程的代码和数据就互不影响了,如果某个数据和代码从头到尾都没有进行修改,那么这份数据和代码就会一直公用
PCB里面还存在一个内存指针的数据,定义如下
内存指针:包括进程和代码的相关数据指针 ,还有和其它进程共享的内存块指针
当父进程进行到fork时,便会创建子进程,子进程会继承父进程的PCB和内存指针,此时子进程的内存指针也指向fork,所以子进程会从fork处开始运行