缩放点积注意力
Scaled Dot-Product Attention
-
论文地址
https://arxiv.org/pdf/1706.03762
注意力机制介绍
-
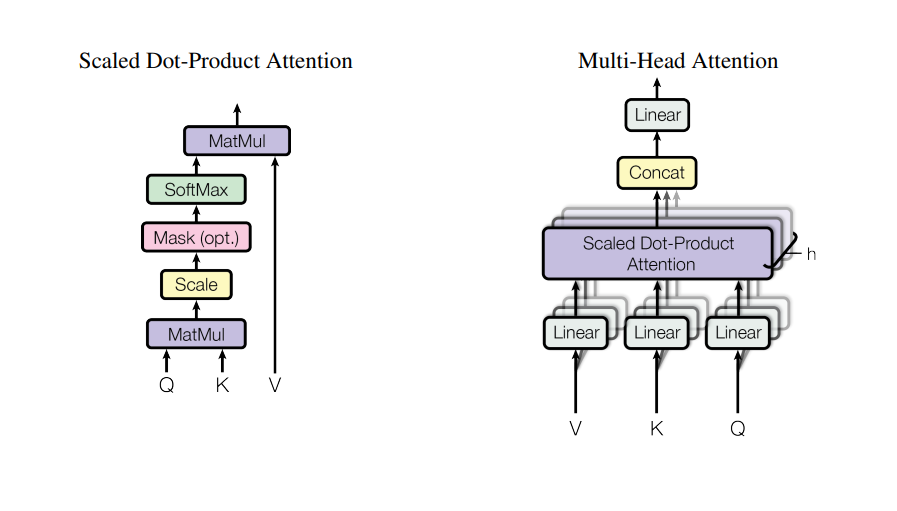
缩放点积注意力是Transformer模型的核心组件,用于计算序列中不同位置之间的关联程度。其核心思想是通过查询向量(query)和键向量(key)的点积来获取注意力分数,再通过缩放和归一化处理,最后与值向量(value)加权求和得到最终表示。
数学公式
-
缩放点积注意力的计算过程可分为三个关键步骤:
- 点积计算与缩放:通过矩阵乘法计算查询向量与键向量的相似度,并使用 d k \sqrt{d_k} dk 缩放
- 掩码处理(可选):对需要忽略的位置施加极大负值掩码
- Softmax归一化:将注意力分数转换为概率分布
- 加权求和:用注意力权重对值向量进行加权
公式表达为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dkQKT)V
其中:- Q ∈ R s e q _ l e n × d _ k Q \in \mathbb{R}^{seq\_len \times d\_k} Q∈Rseq_len×d_k:查询矩阵
- K ∈ R s e q _ l e n × d _ k K \in \mathbb{R}^{seq\_len \times d\_k} K∈Rseq_len×d_k:键矩阵
- V ∈ R s e q _ l e n × d _ k V \in \mathbb{R}^{seq\_len \times d\_k} V∈Rseq_len×d_k:值矩阵
s e q _ l e n seq\_len seq_len 为序列长度, d _ k d\_k d_k 为embedding的维度。
代码实现
-
计算注意力分数
#!/usr/bin/env python # -*- coding: utf-8 -*- import torchdef calculate_attention(query, key, value, mask=None):"""计算缩放点积注意力分数参数说明:query: [batch_size, n_heads, seq_len, d_k]key: [batch_size, n_heads, seq_len, d_k] value: [batch_size, n_heads, seq_len, d_k]mask: [batch_size, seq_len, seq_len](可选)"""d_k = key.shape[-1]key_transpose = key.transpose(-2, -1) # 转置最后两个维度# 计算缩放点积 [batch, h, seq_len, seq_len]att_scaled = torch.matmul(query, key_transpose) / d_k ** 0.5# 掩码处理(解码器自注意力使用)if mask is not None:att_scaled = att_scaled.masked_fill_(mask=mask, value=-1e9)# Softmax归一化att_softmax = torch.softmax(att_scaled, dim=-1)# 加权求和 [batch, h, seq_len, d_k]return torch.matmul(att_softmax, value) -
相关解释
-
输入张量 query, key, value的形状
如果是直接计算的话,那么shape是 [batch_size, seq_len, d_model]
当然为了学习更多的表征,一般都是多头注意力,这时候shape则是[batch_size, n_heads, seq_len, d_k]
其中
-
batch_size:批量
-
n_heads:注意力头的数量
-
seq_len: 序列的长度
-
d_model: embedding维度
-
d_k: d_k = d_model / n_heads
-
-
代码中的shape转变
-
key_transpose :key的转置矩阵
由 key 转置了最后两个维度,维度从 [batch_size, n_heads, seq_len, d_k] 转变为 [batch_size, n_heads, d_k, seq_len]
-
**att_scaled **:缩放点积
由 query 和 key 通过矩阵相乘得到
[batch_size, n_heads, seq_len, d_k] @ [batch_size, n_heads, d_k, seq_len] --> [batch_size, n_heads, seq_len, seq_len]
-
att_score: 注意力分数
由两个矩阵相乘得到
[batch_size, n_heads, seq_len, seq_len] @ [batch_size, n_heads, seq_len, d_k] --> [batch_size, n_heads, seq_len, d_k]
-
-
使用示例
-
测试代码
if __name__ == "__main__":# 模拟输入:batch_size=2, 8个注意力头,序列长度512,d_k=64x = torch.ones((2, 8, 512, 64))# 计算注意力(未使用掩码)att_score = calculate_attention(x, x, x)print("输出形状:", att_score.shape) # torch.Size([2, 8, 512, 64])print("注意力分数示例:\n", att_score[0,0,:3,:3])在实际使用中通常会将此实现封装为
nn.Module并与位置编码、残差连接等组件配合使用,构建完整的Transformer层。