sglang部署DeepSeek-R1-Distill-Qwen-7B
sglang部署DeepSeek-R1-Distill-Qwen-7B
-
模型:DeepSeek-R1-Distill-Qwen-7B
-
显卡:4090 1张
-
显存占用:约22.6G
-
重要包的版本
vllm==0.8.4 sglang== 0.4.5.post3
下载7B模型
-
可以使用huggingface或者ModelScope下载
-
这里我使用HuggingFace下载,假设当前目录为
/root
-
创建文件夹统一存放
Huggingface下载的模型mkdir Hugging-Face -
配置镜像源
vim ~/.bashrc填入以下两个,以修改HuggingFace 的镜像源 、模型保存的默认
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=/root/Hugging-Face重新加载,查看环境变量是否生效
source ~/.bashrcecho $HF_ENDPOINT echo $HF_HOME -
安装 HuggingFace 官方下载工具
pip install -U huggingface_hub -
如果使用的GPU平台是 AutoDL 或者是 蓝耘 ,则可以通过下面的命令开启学术加速
source /etc/network_turbo -
执行下载模型的命令,下载 DeepSeek-R1-Distill-Qwen-7B,地址在下面
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
复制全名
DeepSeek-R1-Distill-Qwen-7B
执行下面的下载命令,等待下载完成
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-7B

-
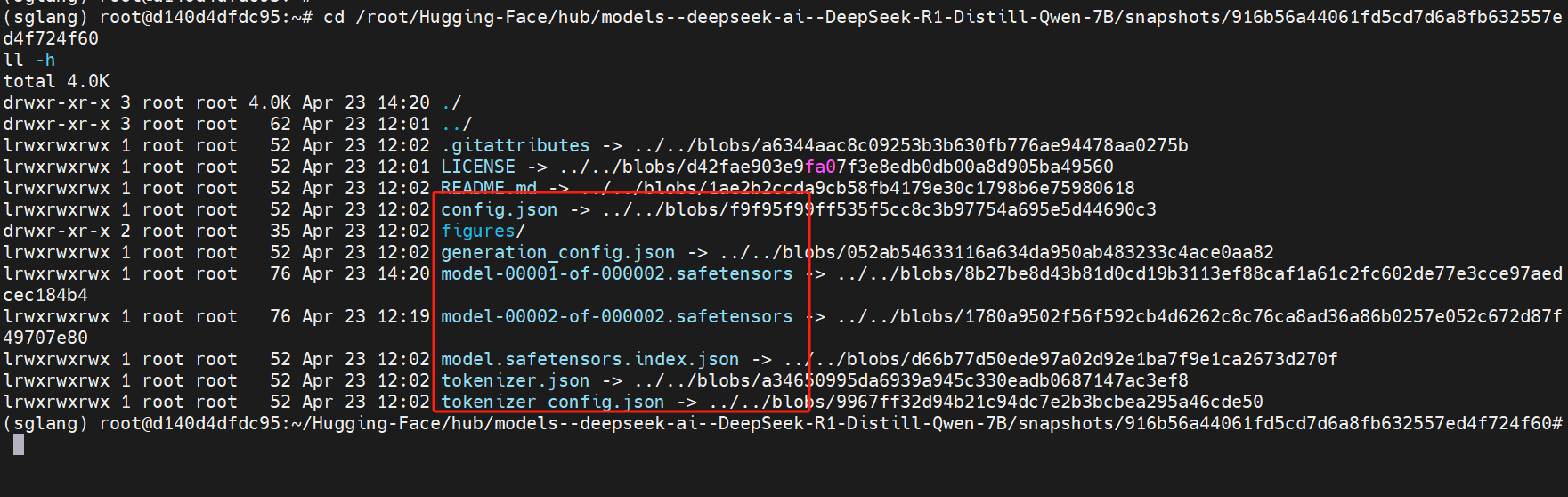
查看
cd /root/Hugging-Face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B/snapshots/916b56a44061fd5cd7d6a8fb632557ed4f724f60 ll -h
安装sglang
-
使用conda创建虚拟环境
conda create -n sglang python=3.12conda activate sglang -
下载vllm
pip install vllm -
下载sglang
pip install sglang pip install sgl_kernel -
其他依赖包
pip install orjson pip install torchao
sglang启动
-
注意,启动从huggingface下载的DS-R1-7B, 需要指定到下载的snapshots地址
/root/Hugging-Face/hub/models–deepseek-ai–DeepSeek-R1-Distill-Qwen-7B/snapshots/916b56a44061fd5cd7d6a8fb632557ed4f724f60
-
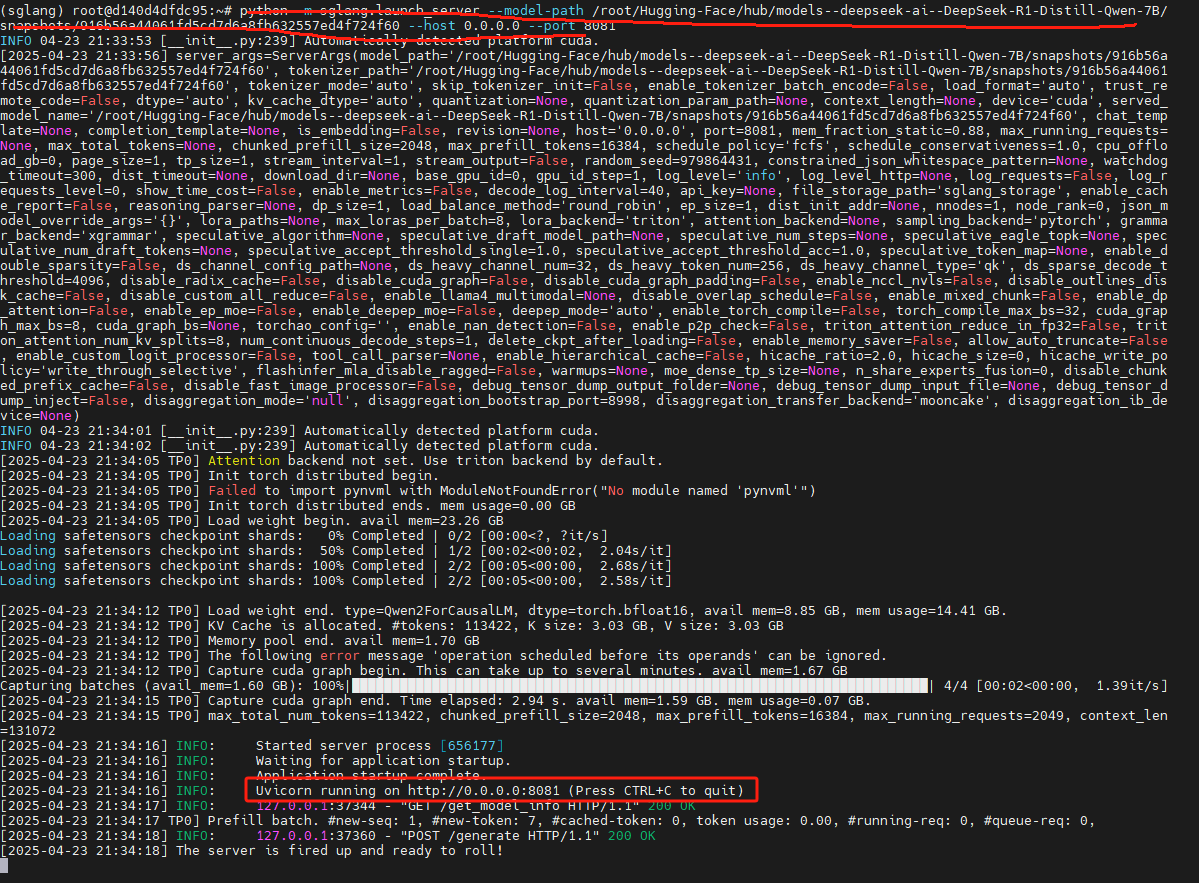
启动DeepSeek-R1-Distill-Qwen-7B
python -m sglang.launch_server --model-path /root/Hugging-Face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B/snapshots/916b56a44061fd5cd7d6a8fb632557ed4f724f60 --host 0.0.0.0 --port 8081这里就是以默认参数来启动的,默认端口是30000,这里手动指定了8081
-
连接代码
from openai import OpenAI import openaiopenai.api_key = '1111111' # 这里随便填一个 openai.base_url = 'http://127.0.0.1:8081/v1'def get_completion(prompt, model="QwQ-32B"):client = OpenAI(api_key=openai.api_key,base_url=openai.base_url)messages = [{"role": "user", "content": prompt}]response = client.chat.completions.create(model=model,messages=messages,stream=False)return response.choices[0].message.contentprompt = '你好,请简短并幽默的介绍下你自己'response = get_completion(prompt, model="DeepSeek-R1-Distill-Qwen-7B") print(response)"""输出""" 好,我需要给对方简单幽默地介绍自己。我叫DeepSeek-R1,是一个由深度求索公司开发的智能助手。要保持幽默,可以提到我是AI,这样既专业又有趣。然后,可以举个例子,比如我擅长回答各种问题,甚至会下棋,这样显得我多才多艺。最后,可以加上一句闲话,增加亲切感,比如“你有什么问题吗?或者我可以下盘棋给你看看。”这样整个介绍就既简短又有趣了。 </think>您好!我是DeepSeek-R1,一个由深度求索公司开发的智能助手,擅长回答各种问题,甚至会下棋。您有什么问题吗?或者我可以下盘棋给你看看。 -
速度大概是 64tokens/s

-
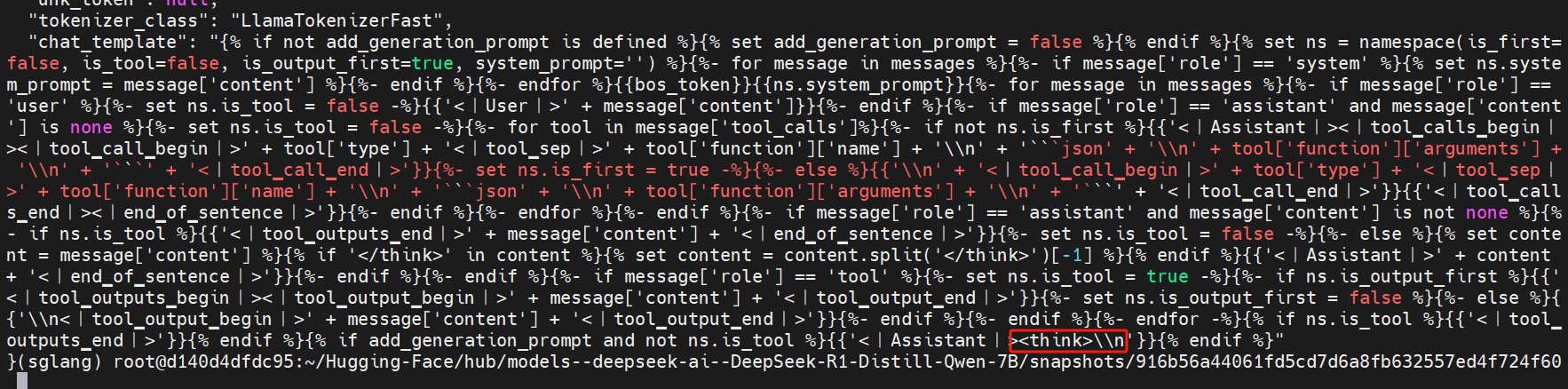
这里Deepseek模型的输出没有 开头,如果需要有,则需要将模型文件中的 tokenizer配置文件的
chat_template后面增加的<think>\\n去掉然后再重新部署模型。文件名:
tokenizer_config.json