NeRF:原理 + 实现 + 实践全流程配置+数据集测试【Ubuntu20.04 】【2025最新版】
一、引言
从三维建模、虚拟现实到电影级渲染,真实感建模一直是计算机视觉和图形学的核心目标。
在传统方法中,我们往往依赖:
- 多视角立体(MVS)
- 点云重建 + 网格拟合
- 显式建模(如多边形、体素、TSDF)
直到 2020 年,Google Research 提出了 Neural Radiance Fields(NeRF),用 神经网络建模一个连续隐式 3D 场景,突破了传统方法在细节、视角一致性、重建质量上的天花板。
NeRF 不仅是新型表示方式,更是一种将图像建模与物理一致性结合的范式。
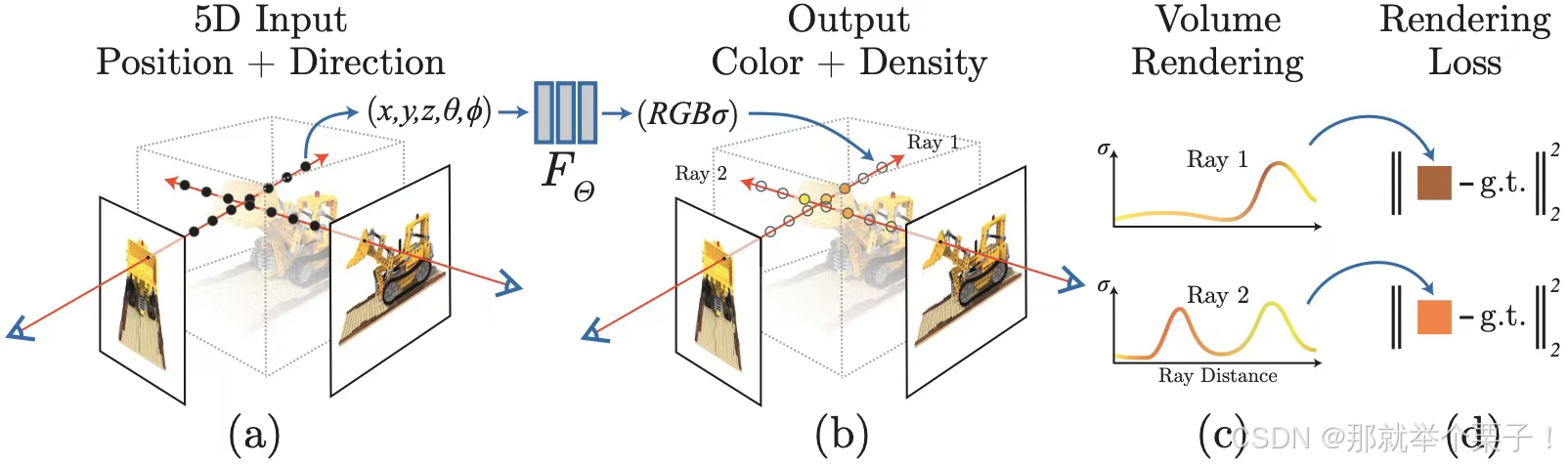
神经辐射场(Neural Radiance Fields, NeRF)是一种前沿的 3D 场景重建技术,利用深度学习从 2D 图像中建模场景的辐射场,实现高质量的新视角合成。NeRF 在虚拟现实、增强现实、影视特效和游戏开发等领域展现出巨大潜力。
二、什么是NeRF
NeRF 将一个 3D 场景表示为一个 多层感知机(MLP),输入为:
- 三维空间坐标
- 观察方向
输出为: - 颜色
- 体积密度
换句话说,NeRF 建模的是一个连续的函数:
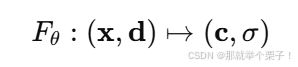
该函数表示某点在某观察方向上的颜色及其对光线的影响(体积密度)。
三、NeRF和核心技术:体积渲染(Volume Rendering)
为了从这个神经表示中合成图像,NeRF 引入了基于物理一致的体积渲染公式:
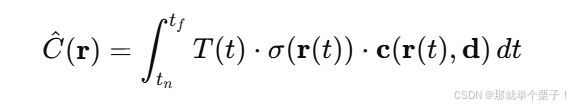
其中:
r ( t ) = o + t d \mathbf{r}(t) = \mathbf{o} + t\mathbf{d} r(t)=o+td 是射线函数
T ( t ) T(t) T(t) 是累积透射率
σ \sigma σ 是密度, c \mathbf{c} c 是颜色
实际实现中使用 分段积分近似,每条光线采样 N N N 个点,前向传播预测 ( σ i , c i ) (\sigma_i, \mathbf{c}_i) (σi,ci),累加渲染出图像像素值。
四、NeRF的训练原理
4.1 训练数据要求
- 多视角图像(一般 20~100 张)
- 每张图像对应的相机位姿(外参)+ 相机内参
4.2 损失函数
对每个像素比较预测颜色与真实图像颜色:
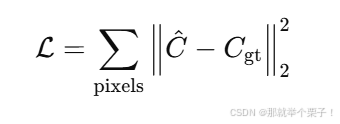
五、环境配置
5.1 硬件要求
- GPU:NeRF 的训练和推理对计算性能要求较高,推荐使用 NVIDIA GPU(如 GTX 1080 Ti、RTX 2080 Ti 或更高型号)。
- 内存:至少 16GB 系统内存,GPU 显存建议 8GB 以上。
- 操作系统:Ubuntu 20.04 LTS。
5.2 软件安装
5.2.1 克隆NeRF-Pytorch代码
NeRF-Pytorch:https://github.com/yenchenlin/nerf-pytorch
git clone https://github.com/yenchenlin/nerf-pytorch.git
5.2.2 创建并激活虚拟环境
conda create -n nerf python=3.7
conda activate nerf
5.2.3 安装Pytorch
根据系统级CUDA决定安装的Pytorch版本,可以输入nvcc --version进行查看
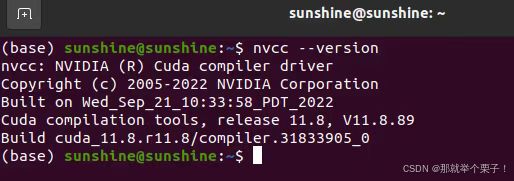
安装支持cuda11.8的pytorch
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
验证 PyTorch 是否支持 GPU:
python -c "import torch; print(torch.cuda.is_available())"
如果输出 True,说明安装成功且 GPU 可用
5.2.4 安装项目依赖
cd nerf-pytorch
pip install -r requirements.txt
conda install imagemagick #安装 ImageMagick(用于处理 LLFF 数据集)
六、公共示例数据集测试
6.1 下载并准备测试数据集
我们将使用官方提供的 “lego” 示例数据集进行测试。这是一个合成数据集,适合快速验证环境和代码是否正常工作。
(1)下载 “lego” 数据集:
bash download_example_data.sh
- 这将自动下载 “lego” 和 “fern” 数据集到 ./data 目录。
- 下载完成后,检查 ./data/lego 目录,里面应包含 train、val 和 test 子目录。
(2)检察数据集结构
ls ./data/nerf_synthetic/lego

6.2 运行训练(测试数据集)
(1)修改配置文件
保证自己的数据路径与configs/fern.txt文件里的datadir路径相同:
(2)使用提供的配置文件 configs/lego.txt 进行训练:
python run_nerf.py --config configs/lego.txt
训练将开始,模型会保存在 ./logs 目录下。
根据你的 GPU 性能(例如我的 NVIDIA 4090),训练可能需要半小时左右。
你可以通过以下命令监控 GPU 使用情况:
nvidia-smi
(3)检查训练进度:
- 训练过程中,日志会显示在终端上,包括损失值(loss)。
- 中间结果会保存在 ./logs/lego 目录下,你可以用文件浏览器查看生成的图片。
6.3 结果输出
(1)输出目录
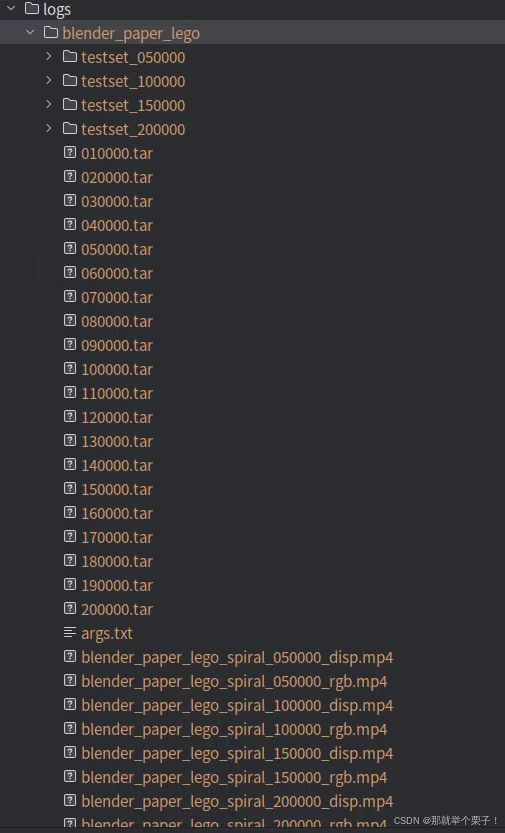
在训练了 200k 次迭代(在单个 4090 上训练 半小时)后,可以得到上述结果
(2)输出结构说明
1、主目录 logs/
存放所有训练日志、模型权重、渲染结果等输出文件的根目录。
2、实验场景目录 blender_paper_lego
每个独立训练的场景或实验对应一个子目录。
命名规则一般为数据集或场景名称,如这里的 blender_paper_lego 表示使用了 Blender Lego 数据集。
3、目录内详细文件介绍
(一) 模型权重(.tar 文件)
010000.tar、020000.tar … 200000.tar:
这些文件是模型的训练检查点(checkpoints)。
文件名数字表示训练的迭代次数(steps)。
文件内部存储了:
模型权重参数
优化器状态
当前训练进度
作用:
可用于恢复训练。
用于后续渲染与推理。
(二) 测试集渲染结果文件夹 (testset_xxxxxx)
如:testset_050000、testset_100000 等:
每个文件夹对应不同迭代次数下的测试集图像预测结果。
文件夹内包含:
渲染后的图片(.png),表示模型对测试集的推理结果。
图片以序号或场景名称为命名,便于观察模型随训练进展的效果变化。
(三) 视频文件 (.mp4)
视频文件通常有两种类型:
*_rgb.mp4:RGB视频,展示模型从不同视角(一般是螺旋路径,spiral path)渲染出的彩色场景效果。是模型可视化的直观表现,用于快速评估渲染质量。*_disp.mp4:Disparity(视差)视频,展示对应场景深度信息或视差图。可用以直观地观察深度估计的质量。
示例:
blender_paper_lego_spiral_050000_rgb.mp4 表示迭代数 50,000 时模型渲染出的彩色视频。blender_paper_lego_spiral_050000_disp.mp4 表示迭代数 50,000 时对应的深度渲染视频。
四、重要配置文件 (args.txt)
记录训练期间的全部超参数和配置选项。
如:
训练迭代次数 (N_iters)学习率 (lrate)数据集路径 (datadir)模型架构参数(如隐藏层大小,深度等)便于后续复现实验或调整优化参数。
五、如何使用这些文件?
恢复训练
使用 checkpoint 文件:
python run_nerf.py --config configs/lego.txt --ft_path ./logs/blender_paper_lego/200000.tar
单独渲染结果
生成图片:
python run_nerf.py --config configs/lego.txt --render_only --ft_path ./logs/blender_paper_lego/200000.tar
生成测试视频:
python run_nerf.py --config configs/lego.txt --render_test --ft_path ./logs/blender_paper_lego/200000.tar
六、实际情况参数调整建议
若显存不足或训练过慢:降低 batch size 或训练图片的分辨率。降低迭代次数或增加 lrate_decay(学习率衰减步数)。若模型精度不足:提高迭代次数 N_iters。调整分层采样的数目 (N_samples, N_importance)。
(3)可视化如下所示


