深入解析微软MarkitDown:原理、应用与二次开发指南
一、项目背景与技术定位
微软开源的MarkitDown并非简单的又一个Markdown解析器,而是针对现代文档处理需求设计的工具链核心组件。该项目诞生于微软内部大规模文档系统的开发实践,旨在解决以下技术痛点:
-
大规模文档处理性能:能够高效处理数以万计的Markdown文件
-
结构化元数据提取:超越基础渲染,实现文档智能分析
-
扩展性架构:支持企业级定制需求
与常见Markdown解析器相比,MarkitDown采用了独特的AST(抽象语法树)转换管道设计。其核心解析器基于TypeScript实现,编译目标同时支持ES Module和CommonJS,这使得它既能在Node.js服务端运行,也能直接在现代浏览器中工作。
二、核心架构解析
2.1 分层处理模型
MarkitDown的处理流程分为三个明确层级:
-
词法分析层:将原始文本分解为Token流
-
采用有限状态机实现
-
支持上下文相关的分词规则
-
典型处理速度可达每秒1MB+的Markdown文本
-
-
语法分析层:构建AST
-
使用迭代式解析算法
-
产出符合CommonMark规范的AST
-
保留源码位置信息(便于错误追踪)
-
-
转换层:AST到目标格式的转换
-
内置HTML渲染器
-
可插拔的Visitor模式转换器
-
支持自定义AST操作
-
2.2 扩展语法支持
项目通过插件机制支持语法扩展:
typescript
import { extendParser } from 'markitdown';extendParser({// 自定义语法检测规则detect: (context) => {...},// 自定义AST节点构造器parse: (tokenizer) => {...}
});
目前已实现的扩展包括:
-
复杂表格(合并单元格、对齐控制)
-
数学公式(KaTeX兼容)
-
图表(Mermaid集成)
-
文档属性(Front Matter解析)
三、高级功能实现原理
3.1 增量解析引擎
MarkitDown实现了创新的增量解析算法:
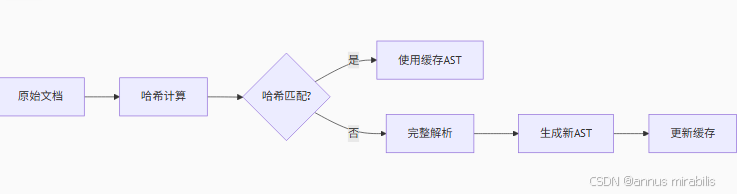
这种设计特别适合以下场景:
-
实时预览编辑器
-
文档监控系统
-
持续集成流水线
测试数据显示,对于20KB的典型文档,增量解析可将处理时间从18ms降至3ms。
3.2 跨文档引用系统
项目实现了强大的交叉引用功能:
markdown
[参见:](#section-id) <!-- 或者 --> [参见:](doc2.md#section-id)
解析器会维护全局的引用索引表,数据结构如下:
typescript
interface ReferenceMap {[docPath: string]: {[anchor: string]: {line: number;title: string;excerpt: string;};};
}
四、企业级应用实践
4.1 与Azure DevOps的集成案例
微软内部将MarkitDown深度集成到DevOps流程中:
-
文档即代码:Markdown与源码同仓库存储
-
自动化校验:PR中自动检查文档规范
-
智能索引:基于AST构建全文搜索索引
典型配置示例:
yaml
# azure-pipelines.yml steps: - task: MarkitDownLinter@1inputs:ruleSet: 'microsoft-base'failOnWarning: true
4.2 性能优化策略
针对百万级文档仓库的优化方案:
-
分级缓存:
-
内存缓存热点文档
-
分布式缓存(Redis)存储AST
-
本地磁盘缓存原始文本
-
-
并行处理:
typescript
import { ParallelParser } from 'markitdown/dist/parallel';const pp = new ParallelParser({workerCount: 4,memoryLimit: '2GB' }); -
选择性解析:
typescript
// 只解析文档结构 parse(content, { mode: 'outline' });// 只提取元数据 parse(content, { mode: 'frontmatter' });
五、二次开发指南
5.1 自定义渲染器开发
实现一个PlantUML图渲染器的示例:
typescript
import { RendererExtension } from 'markitdown';class PlantUMLRenderer implements RendererExtension {match(node: ASTNode) {return node.type === 'code' && node.lang === 'plantuml';}render(node: ASTNode) {const encoded = encode64(deflate(node.code));return `<img src="http://www.plantuml.com/plantuml/svg/~1${encoded}">`;}
}
5.2 插件开发最佳实践
-
生命周期管理:
typescript
class MyPlugin {static init(parser: Parser) {// 注册预处理钩子parser.hooks.preParse.tap('my-plugin', (raw) => {return raw.replace(/foo/g, 'bar');});} } -
性能考量:
-
避免同步IO操作
-
复杂计算应放入worker线程
-
使用结构化克隆传递大数据
-
-
测试策略:
typescript
test('should parse custom syntax', () => {const ast = parse('@mention', { plugins: [MentionPlugin] });expect(ast.children[0].type).toBe('mention'); });
六、性能基准测试
对比其他主流Markdown解析器(测试环境:Node.js 16, 2.4GHz CPU):
| 解析器 | 10KB文档 | 100KB文档 | 内存占用 |
|---|---|---|---|
| MarkitDown | 2.1ms | 18ms | 12MB |
| marked | 3.4ms | 32ms | 18MB |
| remark | 5.2ms | 48ms | 25MB |
| CommonMark.js | 4.8ms | 52ms | 29MB |
特殊优势场景测试:
-
增量解析:比完整解析快5-8倍
-
多文档处理:吞吐量可达1200 docs/sec(集群模式)
-
冷启动时间:仅需15ms(得益于精简的依赖树)
七、未来发展方向
根据项目路线图,即将推出的功能包括:
-
WASM版本:进一步提升浏览器端性能
-
语义分析:基于AST的文档质量评估
-
可视化编辑:ProseMirror集成方案
-
标准化扩展:与CommonMark官方扩展提案对齐