第9章 多模态大语言模型
当提到大型语言模型(LLMs)时,多模态能力或许并非首先跃入脑海的概念。毕竟,它们本质上是语言模型!但我们很快会发现,如果模型能够处理文本以外的数据类型,其实用性将得到极大提升。例如,若语言模型能"看一眼"图片并就其内容回答问题,这种能力将极具价值。如图9-1所示,能够同时处理文本和图像(每种数据类型被称为一种模态)的模型即被称为多模态模型。
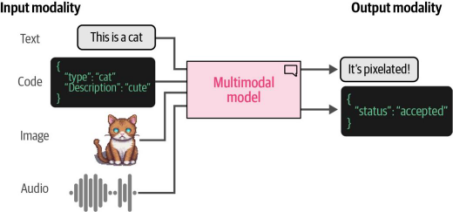
图9-1. 能够处理不同类型(或模态)数据的模型(如图像、音频、视频或传感器数据)被称为多模态模型。值得注意的是,模型可能具备接收某种模态输入的能力,但并不一定具备生成该模态输出的能力
我们已经看到大型语言模型(LLMs)展现出各种新兴能力,从泛化能力和推理能力到算术运算和语言学应用。随着模型变得越来越大且越来越智能,它们的技能集也在持续扩展¹。
接收并推理多模态输入的能力可能进一步增强,并帮助释放此前被限制的潜力。实际上,语言并非存在于真空中。例如,你的肢体语言、面部表情、语调等都是增强口头表达的交流方式。同样的逻辑也适用于LLMs——如果我们能使其具备对多模态信息的推理能力,它们的潜力将得到释放,我们也将能够将其用于解决新型问题。
在本章中,我们将探索多种具备多模态能力的LLMs及其在实际应用场景中的意义。首先,我们将通过改进原始Transformer技术,研究图像如何被转化为数值表示;接着,我们将展示如何通过这种Transformer扩展LLMs以涵盖视觉任务。
视觉Transformer
在本书的各章中,我们已经见证了基于Transformer的模型在多种语言建模任务中的成功应用,从分类、聚类到搜索和生成式建模。因此,研究人员尝试将Transformer的成功经验推广到计算机视觉领域也就不足为奇了。
他们提出的方法是视觉Transformer(Vision Transformer, ViT)。与传统的默认卷积神经网络(CNN)相比,ViT在图像识别任务中表现极为出色2。与原始Transformer类似,ViT的目标是将非结构化数据(即图像)转换为可用于多种任务的表示形式,例如分类任务(如图9-2所示)。
ViT依赖于Transformer架构中的一个关键组件——编码器。如第1章所述,编码器的作用是将文本输入转换为数值表示,然后再传递给解码器。不过,在编码器执行任务之前,文本输入需要先经过分词处理(如图9-3所示)。
1 Jason Wei et al. “Emergent abilities of large language models.” arXiv preprint arXiv:2206.07682 (2022).
2 Alexey Dosovitskiy et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
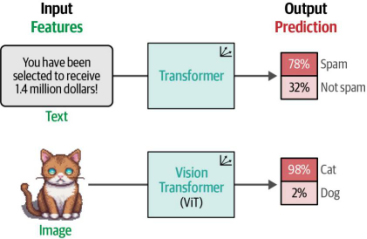
图9-2原始Transformer模型与视觉Transformer模型均接收非结构化数据,将其转换为数值表示,并最终用于分类等任务
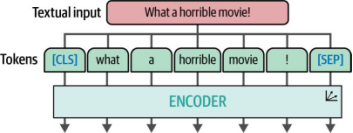
图9-3. 文本首先通过分词器(tokenizer)进行分词处理,随后被传入一个或多个编码器(encoder)中
由于图像不包含文字,这种分词流程无法直接应用于视觉数据。为此,Vision Transformer(ViT)的作者们提出了一种将图像分割为"词"的词元方法,使其能够沿用原始的编码器架构。
试想一幅猫的图像。该图像由若干像素构成,比如512×512像素规格。单个像素承载的信息量微乎其微,但当我们将像素组合成块时,图像的细节特征便开始逐渐显现。
ViT采用了类似的处理原理。与将文本拆分为词元不同,它将原始图像转化为由多个图像块组成的集合。具体而言,如图9-4所示,该模型通过横向和纵向切割,将输入图像分割为若干离散的图像块单元。
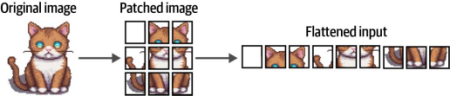
图9-4. 图像输入的“分块化”过程。该过程将图像分割为多个子图像块
就像我们将文本转换为文本词元(tokens)一样,我们也将图像转换为一系列图像块(patches)。图像块的展平输入可以被视为一段文本中的词元。然而与文本词元不同,我们不能简单地为每个图像块分配一个ID,因为这些图像块在其他图像中很少重复出现(不像文本拥有固定词汇表)。
取而代之的是,图像块通过线性嵌入(linearly embedded)生成数值化表示,即嵌入向量(embeddings)。这些嵌入向量随后可作为Transformer模型的输入。通过这种方式,图像块被以与文本词元完全相同的方式进行处理。完整流程如图9-5所示。
为便于说明,示例中的图像被分割为3×3的块,但原始论文实现实际使用了16×16的块(毕竟这篇论文的标题正是《一张图像价值16x16个词》)。
这种方法最有趣之处在于:一旦嵌入向量被传递到编码器,它们就被视作与文本词元完全相同的存在。从这一刻起,无论是处理文本还是图像,模型的训练方式将没有任何差异。
基于这种相似性,Vision Transformer(ViT)常被用于构建多模态语言模型。其最直接的应用场景之一就是在嵌入模型(embedding models)的训练过程中发挥作用。
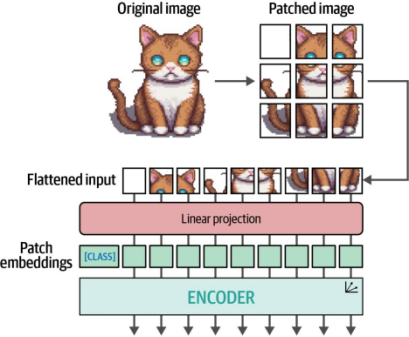
图9-5. ViT背后的主要算法。将图像分块并进行线性投影后,这些图像块嵌入会被输入到编码器中,并像处理文本词元一样进行处理
多模态嵌入模型
在前面的章节中,我们使用嵌入模型来捕捉文本表征(如论文和文档)的语义内容。我们发现可以利用这些嵌入或其数值表示来查找相似文档、执行分类任务,甚至进行主题建模。
正如我们之前多次所见,嵌入通常是大型语言模型(LLM)应用背后的重要驱动力。它们是一种高效的方法,能够捕获大规模信息并在信息“大海捞针”中快速定位所需内容。
不过到目前为止,我们讨论的仅是专注于生成文本表征的嵌入模型。虽然存在专门用于图像嵌入的模型,但本章我们将探讨能够同时捕获文本和视觉表征的嵌入模型(如图9-6所示)。
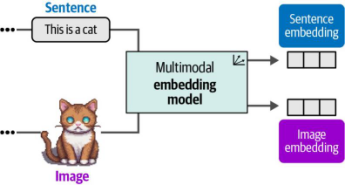
图9-6. 多模态嵌入模型可在同一向量空间中为多种模态创建嵌入
其优势在于,由于生成的嵌入向量位于同一向量空间(图9-7),因此可以对多模态表示进行比较。例如,使用此类多模态嵌入模型,我们可以根据输入的文本查找相关图像。例如,若搜索与"小狗图片"相似的图像,我们会找到哪些图像?反过来也成立——哪些文档与该问题最相关?
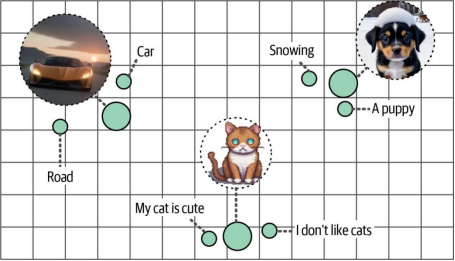
图9-7. 尽管来自不同模态,但具有相似含义的嵌入向量在向量空间中会彼此接近。
目前有许多多模态嵌入模型,但最著名且应用最广泛的是对比语言-图像预训练模型(CLIP)
CLIP:连接文本与图像
CLIP 是一种嵌入模型,可同时计算图像和文本的嵌入向量。生成的嵌入向量位于同一向量空间中,这意味着图像的嵌入可以与文本的嵌入进行比较3。这种比较能力使 CLIP 及类似模型能够应用于以下任务:
零样本分类
通过将图像的嵌入与其可能类别描述之间的嵌入进行比较,可以确定最相似的类别。
聚类
对图像和关键词集合同时进行聚类,以发现哪些关键词对应哪些图像集合
搜索
在数十亿文本或图像中,快速找到与输入文本或图像相关的内容。
生成
利用多模态嵌入驱动图像生成(例如 stable diffusion⁴)。
CLIP如何生成多模态嵌入?
CLIP的工作过程其实非常直观。假设你有一个包含数百万张图像及其对应标题的数据集(如图9-8所示)。

图9-8. 训练多模态嵌入模型所需的数据类型
3 Alec Radford et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
4 Robin Rombach et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
该数据集可用于为每对(图像及其描述)创建两种表示形式——图像本身及其对应的文本描述。为此,CLIP采用文本编码器对文本进行编码,并使用图像编码器对图像进行编码。如图9-9所示,最终为图像及其对应的描述分别生成了各自的嵌入表示。
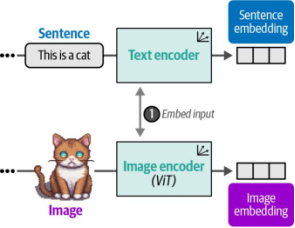
图9-9. 在训练CLIP的第一步中,图像和文本分别通过图像编码器和文本编码器进行嵌入
生成的嵌入对通过余弦相似度进行比较。正如我们在第4章中看到的,余弦相似度是向量之间夹角的余弦值,通过嵌入的点积除以它们的长度乘积计算得出。
在训练开始时,由于图像嵌入和文本嵌入尚未被优化到同一向量空间,它们的相似度会较低。在训练过程中,我们会对嵌入间的相似度进行优化——对于相似的图文对需要最大化其相似度,对于不相似的图文对则需要最小小化其相似度(图9-10)。
在计算相似度后,模型会进行参数更新,并使用新的数据批次和更新后的表示重新开始这一过程(图9-11)。这种方法被称为对比学习,我们将在第10章深入探讨其工作原理,并创建我们自己的嵌入模型。
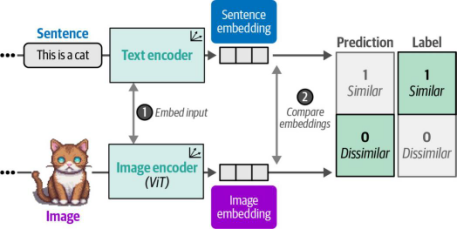
图9-10. 在CLIP训练的第二步中,通过余弦相似度计算句子与图像嵌入之间的相似度
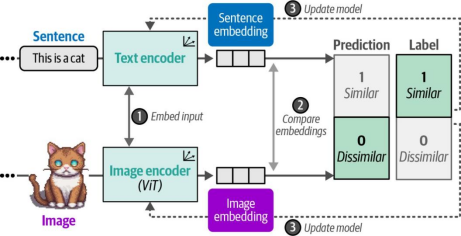
图9-11. 在CLIP训练的第三步中,会更新文本编码器和图像编码器以匹配预期的相似性。这种更新会使嵌入向量在输入内容相似时,在向量空间中的位置更加接近
最终,我们期望猫的图像嵌入与短语“一张猫的图片”的嵌入具有相似性。正如我们将在第10章中讨论的,为了确保表征尽可能准确,训练过程中还需要包含不相关的图像和文本描述作为负样本。建模相似性不仅需要理解事物之间的相似性来源,还需要厘清它们产生差异和非相似性的根本原因。
OpenCLIP
最终,我们期望猫的图像嵌入与短语“一张猫的图片”的嵌入具有相似性。正如我们将在第10章中讨论的,为了确保表征尽可能准确,训练过程中还需要包含不相关的图像和文本描述作为负样本。建模相似性不仅需要理解事物之间的相似性来源,还需要厘清它们产生差异和非相似性的根本原因。
from urllib.request import urlopenfrom PIL import Image# Load an AI-generated image of a puppy playing in the snowpuppy_path = "https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/puppy.png"image = Image.open(urlopen(puppy_path)).convert("RGB")caption = "a puppy playing in the snow"
图9-12. 人工智能生成的小狗雪地嬉戏图像
由于我们为此图像提供了标题,因此可以使用OpenCLIP为两者生成嵌入。
为此,我们需要加载三个模型:
• 分词器(Tokenizer):用于对文本输入进行分词
• 预处理器(Preprocessor):负责对图像进行预处理和尺寸调整
• 主模型(Main Model):将前两步的输出转换为嵌入向量(Embeddings)
from transformers import CLIPTokenizerFast, CLIPProcessor, CLIPModelmodel_id = "openai/clip-vit-base-patch32"# Load a tokenizer to preprocess the textclip_tokenizer = CLIPTokenizerFast.from_pretrained(model_id)# Load a processor to preprocess the imagesclip_processor = CLIPProcessor.from_pretrained(model_id)# Main model for generating text and image embeddingsmodel = CLIPModel.from_pretrained(model_id)在加载模型后,预处理输入会非常简单。让我们从分词器开始,看看预处理输入时会发生什么:
# Tokenize our inputinputs = clip_tokenizer(caption, return_tensors="pt")这会输出一个包含输入ID的字典:
{'input_ids': tensor([[49406, 320, 6829, 1629, 530, 518, 2583, 49407]]), 'at-
tention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
要查看这些ID代表的内容,我们可以通过使用名称贴切的convert_ids_to_tokens函数将它们转换为词元:
# Convert our input back to tokensclip_tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]) 这会给出以下输出:
['<|startoftext| >',
'a</w>',
'puppy</w>',
'playing</w>',
'in</w>',
'the</w>',
'snow</w>',
'<|endoftext|>']
正如我们之前经常看到的,文本会被拆分成词元(tokens)。此外,我们现在还看到文本的开头和结尾被明确标识,以便将其与潜在的图像嵌入区分开来。您可能还会注意到[CLS]词元缺失了——在CLIP模型中,[CLS]词元实际上用于表示图像嵌入。
现在我们已经对标题进行了预处理,可以创建其嵌入向量:
# Create a text embeddingtext_embedding = model.get_text_features(**inputs)text_embedding.shape这会生成一个包含512个值的嵌入向量:
torch.Size([1, 512])
在创建图像嵌入之前(与文本嵌入类似),我们需要按照模型的要求对图像进行预处理,比如调整大小和形状等特征。
我们可以使用之前创建的处理器来完成这一步:
# Preprocess imageprocessed_image = clip_processor(text=None, images=image, return_tensors="pt")["pixel_values"]processed_image.shape原始图像是512×512像素。请注意,图像预处理将其尺寸缩小到了224×224像素,这是模型期望的输入尺寸:
torch.Size([1, 3, 224, 224])
图9-13展示了这种预处理的结果可视化:
import torchimport numpy as npimport matplotlib.pyplot as plt# Prepare image for visualizationimg = processed_image.squeeze(0)img = img.permute(*torch.arange(img.ndim - 1, -1, -1))img = np.einsum("ijk->jik", img)# Visualize preprocessed imageplt.imshow(img)plt.axis("off")
要将此预处理后的图像转换为嵌入向量,我们可以像之前一样调用模型并查看其返回的形状
# Create the image embeddingimage_embedding = model.get_image_features(processed_image)image_embedding.shape这将返回以下形状:
torch.Size([1, 512])
请注意,所得图像嵌入向量的形状与文本嵌入向量的形状相同。这一点非常重要,因为它允许我们比较两者的嵌入向量以判断相似性。
我们可以通过以下方式计算它们的相似度:首先对嵌入向量进行归一化处理,然后计算点积得到相似度得分:
# Normalize the embeddingstext_embedding /= text_embedding.norm(dim=-1, keepdim=TΓue)image_embedding /= image_embedding.norm(dim=-1, keepdim=TΓue)# Calculate their similaritytext_embedding = text_embedding.detach().cpu().numpy()image_embedding = image_embedding.detach().cpu().numpy()score = np.dot(text_embedding, image_embedding.T)这将给出如下相似度得分:
array([[0.33149648]], dtype=float32)
我们得到的相似性得分为0.33,但若不清楚模型对低分与高分的判定标准,这一结果将难以直接解读。因此,我们通过图9-14展示的更多图像与文本示例进行扩展分析.

图9-14. 三张图像与三段文本之间的相似性矩阵
从矩阵中可见,与其他图像更低的相似性得分相比(例如0.083等极低值),0.33的得分实际上已属于较高水平。
使用Sentence Transformers加载CLIP模型.Sentence Transformers实现了多个基于CLIP的模型,可大幅简化嵌入向量的生成过程。只需几行代码即可完成:
from sentence_transformers import SentenceTransformer, util# Load SBERT-compatible CLIP modelmodel = SentenceTransformer("clip-ViT-B-32")# Encode the imagesimage_embeddings = model.encode(images)# Encode the captionstext_embeddings = model.encode(captions)#Compute cosine similaritiessim_matrix = util.cos_sim(image_embeddings, text_embeddings)让文本生成模型具备多模态能力
传统意义上的文本生成模型——正如其名——是通过处理文本信息来运作的。诸如Llama 2和ChatGPT等模型,都擅长对文本信息进行推理并生成自然语言回应。
然而,这些模型仅局限于受训练的单一模态(即文本)。正如之前在探讨多模态嵌入模型时所见的,引入视觉能力可以显著增强模型的功能。
对于文本生成模型,我们希望它能根据输入的视觉信息进行推理。例如:向模型展示一张披萨的图片,便能询问其成分构成;展示埃菲尔铁塔的照片,便能让它回答建造时间或地理位置。图9-15进一步展示了这种跨模态对话能力的具体应用场景。

图9-15. 多模态文本生成模型(BLIP-2)的示例,该模型能够对输入图像进行推理
为弥合视觉与语言领域之间的差距,研究者尝试为现有模型引入多模态能力。其中一种方法称为BLIP-2:通过引导式语言-图像预训练实现统一视觉语言理解与生成。BLIP-2是一种易用且模块化的技术,可为现有语言模型赋予视觉能力.
BLIP-2:弥合模态差距
从头打造多模态语言模型需要耗费大量计算资源和数据,我们必须使用数十亿级别的图像、文本以及图文对才能构建这样一个模型。可想而知,这绝非易事!
与其从头开始构建架构,BLIP-2通过搭建一座名为"查询变换器"(Querying Transformer/Q-Former)的桥梁结构,实现了视觉与语言的跨模态连接——这座桥梁巧妙地将预训练图像编码器与预训练大语言模型(LLM)衔接起来5。
该设计充分体现了技术复用理念:通过调用现有预训练模型,BLIP-2仅需训练这座桥梁结构,而无需对图像编码器和LLM进行从头训练,从而高效利用了现有技术及模型资源!这种创新架构如图9-16所示。
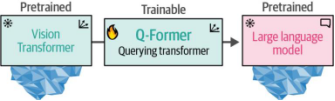
图9-16. Querying Transformer是视觉(ViT)与文本(LLM)之间的桥梁,也是整个流程中唯一可训练的组件
为了连接两个预训练模型,Q-Former 借鉴了它们的架构。它包含两个共享注意力层的模块:
• 图像Transformer:用于与冻结的视觉Transformer交互以实现特征提取
• 文本Transformer:用于与大语言模型(LLM)交互
如图9-17所示,Q-Former 分两个阶段进行训练,每个模态各一个阶段:
在第一步中,使用图像-文档对训练Q-Former 使其能够同时表征图像和文本。这类图像-文档对通常采用图像描述(如我们在训练CLIP时所见)。
具体流程如下:
图像被输入到冻结的ViT中以提取视觉嵌入,这些嵌入将作为Q-Former视觉Transformer的输入。而图像描述则作为Q-Former文本Transformer的输入。
5 Junnan Li et al. “BLIP-2: Bootstrapping language-image pretraining with frozen image encoders and large language models.” International Conference on Machine Learning. PMLR, 2023.
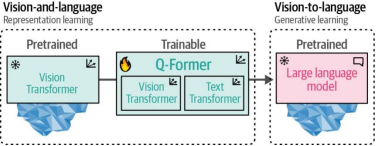
图9-17. 在第一步中,通过表示学习同时学习视觉和语言的表征。在第二步中,这些表征被转化为软视觉提示以输入大语言模型
通过这些输入,Q-Former通过以下三个任务进行训练:
图像-文本对比学习
该任务试图对齐图像与文本的嵌入对,以最大化它们的互信息。
图像-文本匹配
这是一个分类任务,用于预测图像与文本对是正例(匹配)还是负例(不匹配)。
基于图像的文本生成
训练模型根据从输入图像中提取的信息生成文本。
这三个目标被联合优化,以改进从冻结的ViT中提取的视觉表征。从某种意义上说,我们试图将文本信息注入冻结的ViT的嵌入中,以便在LLM中使用它们。BLIP-2的这第一步如图9-18所示。
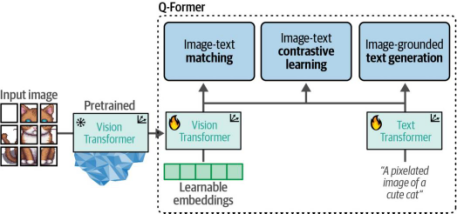
图9-18 在第一步中,冻结的ViT输出与其对应的描述文本共同用于训练,通过三个类对比学习任务来学习视觉-文本表征。
第二步中,从第一步获得的可学习嵌入已包含与对应文本信息处于相同维度空间的视觉信息。这些可学习嵌入随后被输入到大型语言模型(LLM)中。从某种意义上说,这些嵌入作为软视觉提示,通过Q-Former提取的视觉表征来调节LLM的条件生成。两者之间还包含一个全连接线性层,以确保可学习嵌入的形状与LLM的输入要求一致。这种将视觉转换为语言的第二步骤如图9-19所示。
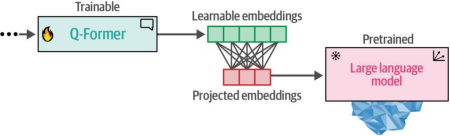
图9-19. 在步骤2中,来自Q-Former的学习嵌入通过投影层传输至大型语言模型(LLM)。这些经过投影的嵌入将作为软性视觉提示使用
当我们将这些步骤结合起来时,Q-Former能够在同一维度空间中学习视觉和文本表示,这些表示可作为向大语言模型(LLM)提供的软提示。因此,LLM将以与您向LLM提供提示时类似的上下文方式接收关于图像的信息。完整的深入处理过程如图9-20所示
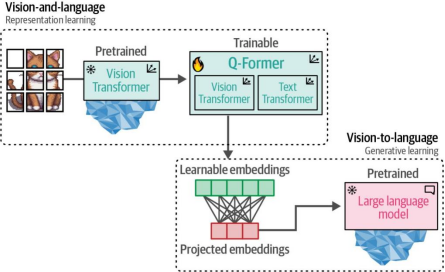
图9-20. 完整的BLIP-2流程
自BLIP-2发布以来,相继涌现出许多具有类似架构的视觉大语言模型(Visual LLM)。例如通过文本大语言模型实现多模态能力的LLaVA框架6,以及基于Mistral 7B大语言模型构建的高效视觉大语言模型Idefics27。尽管这些视觉大语言模型采用不同的架构设计,但其核心思路均是通过将预训练的类CLIP视觉编码器与文本大语言模型相连接,实现将输入图像中的视觉特征投射到语言嵌入空间,使其可作为大语言模型的输入。这种架构设计与Q-Former类似,旨在弥合图像与文本之间的表征鸿沟。
6 Haotian Liu et al. “Visual instruction tuning.” Advances in Neural Information Processing Systems 36 (2024).
7 Hugo Laurençon et al. “What matters when building vision-language models?” arXiv preprint arXiv:2405.02246 (2024).
预处理多模态输入
既然我们已经了解了BLIP-2的构建方式,这种模型便有许多有趣的用例,包括但不限于图像描述、视觉问答甚至执行提示工程。
在探讨具体用例之前,我们先加载模型并探索如何使用它:
通过使用model.vision_model和model.language_model,我们可以分别查看已加载的BLIP-2模型中所采用的视觉Transformer(ViT)和生成式模型。
我们加载了组成完整流程的两个组件:处理器和模型。
处理器类似于语言模型的分词器,其作用是将图像、文本等非结构化输入转换为模型通常期望的表示形式。
预处理图像
首先,我们来探究处理器对图像的处理过程。我们首先加载一张非常宽的图片作为示例:
# Load image of a supercarcar_path = "https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/car.png"image = Image.open(urlopen(car_path)).convert("RGB")
该图像的尺寸为520 × 492像素,这通常是一种非标准格式。让我们看看处理器会对它做些什么:
# Preprocess the imageinputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)inputs["pixel_values"].shape 这将得到以下形状:
torch.Size([1, 3, 224, 224])
结果是一个224 × 224大小的图像。比原始尺寸小了很多!这也意味着所有原始不同形状的图像都会被处理成正方形。因此,在输入非常宽或高的图像时需格外小心,因为它们可能会出现变形。
预处理文本
现在让我们转而用文本继续探索这个处理器。首先,我们可以访问用于对输入文本进行分词的分词器:
blip_processor.tokenizer
这将输出以下内容:
GPT2TokenizerFast(name_or_path='Salesforce/blip2-opt-2.7b', vocab_size=50265,
model_max_length=1000000000000000019884624838656, is_fast=True, pad-
ding_side='right', truncation_side='right', special_tokens={'bos_token': '</
s>', 'eos_token': '</s>', 'unk_token': '</s>', 'pad_token': '<pad>'},
clean_up_tokenization_spaces=True), added_tokens_decoder={
1: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normal-
ized=True, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normal-
ized=True, special=True),
}
此处使用的BLIP-2模型采用了GPT2分词器。正如我们在第2章探讨的,不同分词器处理输入文本的方式可能存在显著差异。
为了探究GPT2Tokenizer的工作原理,我们可以用一个简短的句子进行测试。首先将句子转换为词元ID,然后再将这些ID还原为原始词元:
# Preprocess the texttext = "Her vocalization was remarkably melodic"token_ids = blip_processor(image , text=text , return_tensors="pt")token_ids = token_ids.to(device , torch.float16)["input_ids"][0]# Convert input ids back to tokenstokens = blip_processor.tokenizer.convert_ids_to_tokens(token_ids)得到的词元如下:
['</s>', 'Her', 'Ġvocal', 'ization', 'Ġwas', 'Ġremarkably', 'Ġmel', 'odic']
当我们检查令牌时,您可能会注意到某些令牌开头有一个奇怪的符号——即Ġ符号。这实际上应该是一个空格。然而,某个内部函数会将特定代码点的字符偏移256位使其可显示。因此,原本空格(代码点32)就变成了Ġ(代码点288)。出于说明目的,我们将把这些符号转换为下划线:
# Replace the space token with an underscoretokens = [token.replace("Ġ" , "_ ") for token in tokens]这为我们提供了更美观的输出:
['</s>', 'Her', ' _vocal', 'ization', ' _was', ' _remarkably', ' _mel', 'odic']
输出显示下划线表示单词的起始位置。通过这种方式,可以识别由多个词元组成的单词。
用例1:图像字幕生成
BLIP-2这类模型最直接的应用是为数据集中的图像生成描述。例如,你可能是一家希望为其服装生成描述的商店,或者是一位需要快速为1000多张婚礼照片手动标注标签的摄影师。
图像字幕的生成过程与模型处理流程高度契合:图像会被转换为模型可识别的像素值,这些像素值随后输入BLIP-2,生成可供大语言模型(LLM)用于确定合适字幕的软视觉提示。
让我们以一张超跑的图像为例,使用处理器来提取符合预期形状的像素点:
# Load an AI-generated image of a supercarimage = Image.open(urlopen(car_path)).convert("RGB")# Convert an image into inputs and preprocess itinputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)
下一步是使用BLIP-2模型将图像转换为令牌ID。完成这一步后,我们可以将这些ID转换为文本(即生成的描述):
# Generate image ids to be passed to the decoder (LLM)generated_ids = model.generate(**inputs, max_new_tokens=20)# Generate text from the image idsgenerated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=TΓue )generated_text = generated_text[0].strip()an orange supercar driving on the road at sunset
这似乎是对这张图片的完美描述!
图像字幕生成是一个很好的入门方法,可以帮助你在进入更复杂的应用场景之前熟悉这个模型。你可以尝试用一些图片亲自测试,观察它在哪些场景表现良好,哪些场景存在不足。对于特定领域的图像(如特定卡通角色或虚构生物的图片),模型的表现可能会受限,因为它主要基于公开数据进行训练。
让我们以一个有趣的例子结束本章节——图9-21展示的罗夏测验图像。这个心理实验通过墨迹图测试个体对抽象图案的感知8,据罗伊·沙费尔(Roy Schafer)在《罗夏测验中的精神分析解读:理论与应用》(1954年)中的描述,受试者在墨迹中看到的形象被认为能反映其性格特征。尽管这种测试具有很强的主观性,但这也正是它的魅力所在!
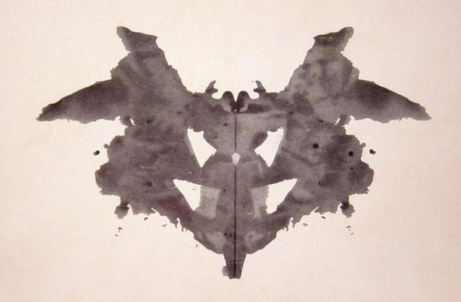
图9-21. 罗夏墨迹测验中的一幅图像。你从中看到了什么?
让我们以图9-21展示的图像作为输入:
# Load Rorschach imageurl = "https://upload.wikimedia.org/wikipedia/commons/7/70/Rorschach_blot_01.jpg"image = Image.open(urlopen(url)).convert("RGB")# Generate captioninputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)generated_ids = model.generate(**inputs, max_new_tokens=20)generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=TΓue )generated_text = generated_text[0].strip()8 Roy Schafer. Psychoanalytic Interpretation in Rorschach Testing: Theory and Application (1954).
与之前一样,当我们检查generated_text变量时,可以看到其生成的说明文字:
一幅黑白墨水绘制的蝙蝠图像
我完全能理解模型为何会用这样的描述来为这幅图像添加说明文字。鉴于这实际上是一个罗夏墨迹测试,您认为这说明了模型的哪些特点?
用例2:基于多模态聊天的提示
虽然图像描述是一项重要任务,但我们可以进一步扩展其应用场景。
在前面的示例中,我们展示了从单一模态(视觉/图像)到另一模态(文本/描述)的转换。
与其遵循这种线性结构,我们可以通过执行所谓的"视觉问答"(Visual Question Answering, VQA)同时呈现两种模态。在此特定用例中,我们会向模型提供一张图像及与该图像相关的提问,要求其进行回答。模型需要同时处理图像和问题。
为了演示,我们以一辆汽车的图片为例,要求 BLIP-2 描述该图像。为此,我们需要像之前几次一样对图像进行预处理:
# Load an AI-generated image of a supercarimage = Image.open(urlopen(car_path)).convert("RGB")要执行视觉问答,我们不仅需要提供图像,还需要给出提示词(prompt)。若缺少提示词,模型将如之前一样仅生成描述性文本。我们将要求模型描述已处理的图像:
# Visual question answeringprompt = "Question: Write down what you see in this picture. Answer:"# Process both the image and the promptinputs = blip_processor(image, text=prompt, return_tensors="pt").to(device,torch.float16)# Generate textgenerated_ids = model.generate(**inputs, max_new_tokens=30)generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=TΓue )generated_text = generated_text[0].strip()这给出了以下输出:
一辆跑车在夕阳下的道路上行驶
它正确描述了图像。然而,这是一个相当简单的例子,因为我们的问题本质上是让模型生成一个标题。相反,我们可以以基于聊天的方式提出后续问题。
为此,我们可以向模型提供之前的对话(包括其对问题的回答),然后提出一个后续问题:
# Chat-like promptingprompt = "Question: Write down what you see in this picture. Answer: A sportscar driving on the road at sunset. Question: What would it cost me to drivethat car? Answer:"# Generate outputinputs = blip_processor(image, text=prompt, return_tensors="pt").to(device,torch.float16)generated_ids = model.generate(**inputs, max_new_tokens=30)generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)generated_text = generated_text[0].strip()这给出了以下答案:
$1,000,000
$1,000,000这个金额非常具体!这显示出BLIP-2具备更多类聊天行为特征,从而能够促成更有趣的对话。最后,我们可以通过使用ipywidgets(一款Jupyter笔记本扩展工具,可创建交互式按钮、文本输入框等功能)来构建交互式聊天机器人,使这一交互过程更加流畅。
from IPython.display import HTML, display
import ipywidgets as widgetsdef text_eventhandler(*args):question = args[0]["new"]if question:args[0]["owner"].value = ""# Create promptif not memory:prompt = " Question: " + question + " Answer:"else:template = "Question: {} Answer: {}."prompt = " ".join([template.format(memory[i][0], memory[i][1])for i in range(len(memory))]) + " Question: " + question + " Answer:"# Generate textinputs = blip_processor(image, text=prompt, return_tensors="pt")inputs = inputs.to(device, torch.float16)generated_ids = model.generate(**inputs, max_new_tokens=100)generated_text = blip_processor.batch_decode(generated_ids,skip_special_tokens=True)generated_text = generated_text[0].strip().split("Question")[0]# Update memorymemory.append((question, generated_text))# Assign to outputoutput.append_display_data(HTML("<b>USER:</b> " + question))output.append_display_data(HTML("<b>BLIP-2:</b> " + generated_text))output.append_display_data(HTML("<br>"))# Prepare widgetsin_text = widgets.Text()in_text.continuous_update = Falsein_text.observe(text_eventhandler, "value")output = widgets.Output()memory = []# Display chat boxdisplay(widgets.VBox(children=[output, in_text],layout=widgets.Layout(display="inline-flex", flex_flow="column-reverse"),))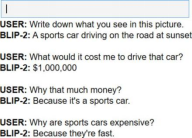
看起来我们可以通过对话继续提出一系列问题。利用这种基于聊天的方法,我们本质上创建了一个能够理解图像的聊天机器人!
本章总结
在本章中,我们探讨了通过弥合文本与视觉表征之间的鸿沟来实现大型语言模型(LLMs)多模态化的各种方法。首先讨论了面向视觉的Transformer——这类模型通过图像编码器和图像块嵌入技术将图像转化为数值表征,使模型能够处理不同尺度的图像信息。
接着我们研究了如何通过CLIP构建能将图像和文本映射为统一数值表征的嵌入模型。分析了CLIP如何利用对比学习在共享空间中对齐图文表征,从而支持零样本分类、聚类和检索等任务,并介绍了开源多模态嵌入工具OpenCLIP的应用价值。
最后探索了如何使文本生成模型具备多模态能力,重点研究了BLIP-2模型的工作原理。这些多模态文本生成模型的核心思想在于将输入图像的视觉特征投射到文本嵌入中,以便LLM进行后续处理。演示了该模型在图像描述生成和多模态对话式交互中的应用,通过融合两种模态信息生成响应内容。总体而言,本章揭示了多模态技术在LLMs中的强大潜力,并展示了其在图像描述、检索和对话系统等领域的应用前景。
在本书第三部分,我们将深入探讨模型的训练与微调技术。第10章将重点讲解文本嵌入模型的构建与微调方法——这是驱动众多语言建模应用的核心技术。下一章将为语言模型的训练与微调提供入门指导。