【MySQL】基本查询
目录
增加
查询
基本查询
where子句
结果排序
筛选分页结果
修改(更新)
删除
普通删除
截断表
插入查询结果
聚合函数
分组查询
这一节的内容是对表内容的增删查改,其中重点是表的查询
增加
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...
这里面带[]的是可以省略的。values左边是要插入的列,右边是对应列的值
我们先创建一张表
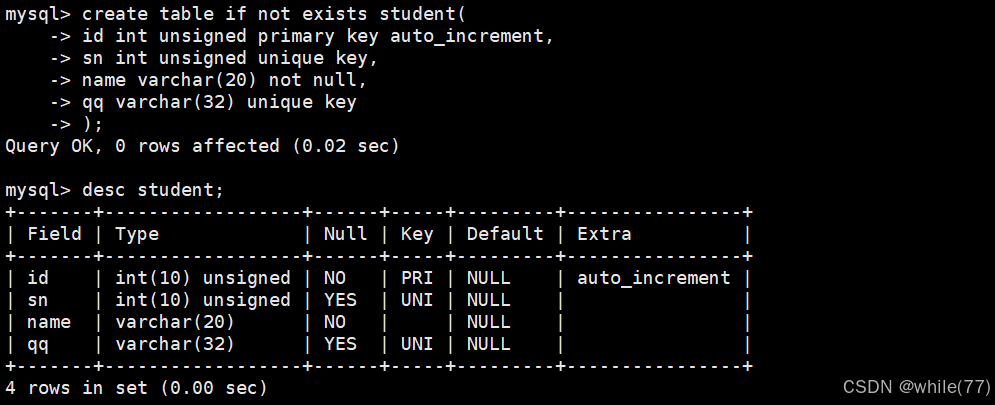
全列插入与指定列插入
values左侧是要插入的列,右侧是对应列的数值。values左侧省略就是全列插入,左侧有值就是指定列插入。
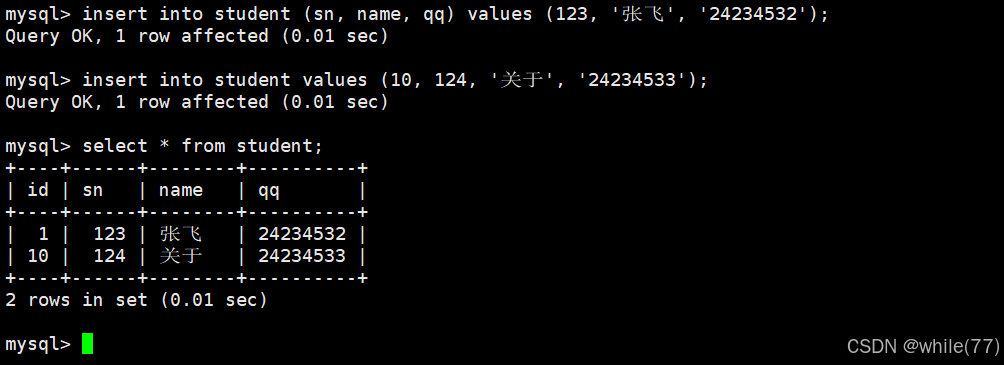
单行插入与多行插入
单行插入是指一次插入一行数据,多行插入是指一次插入多行数据
上面的都是单行插入,现在来看看多行插入
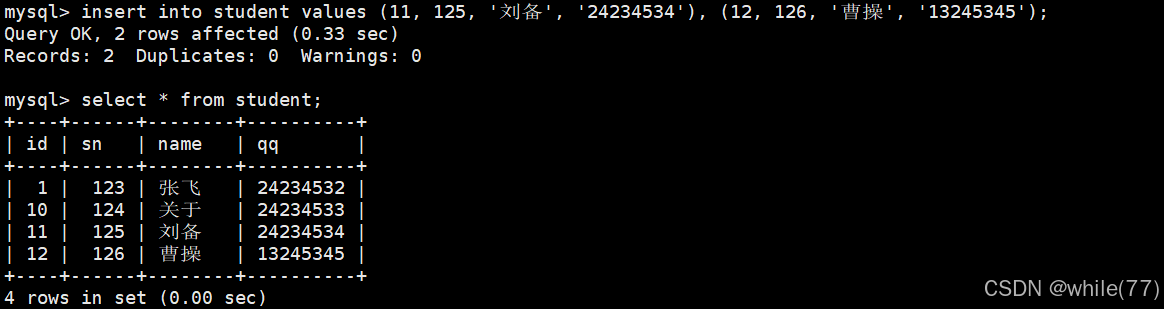
无论是单行插入,还是多行插入,都是可以全列插入或指定列插入的。
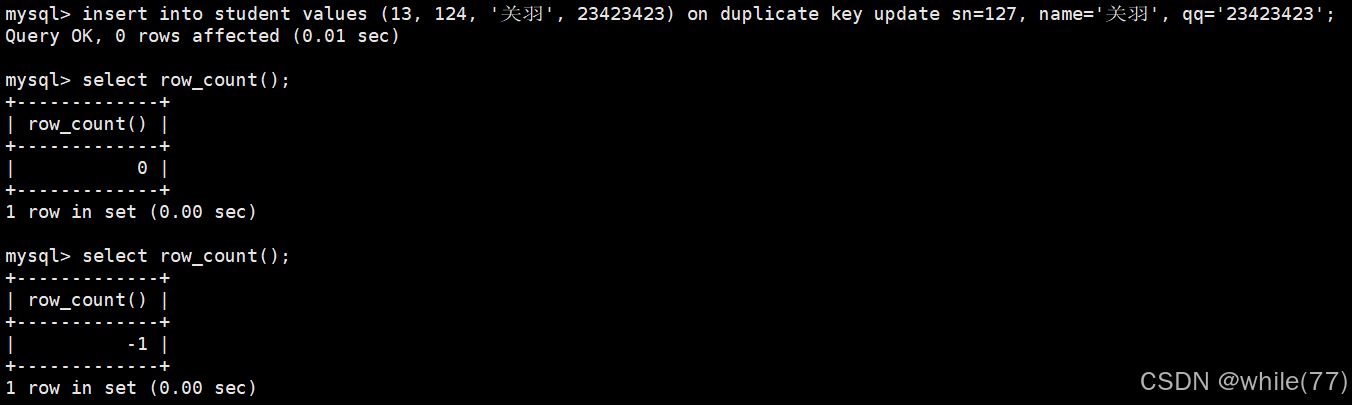
插入否则更新
我们前面介绍过主键和唯一键,当我们向表中插入数据时,是有可能会触发主键/唯一键冲突的。此时可以选择性地进行同步更新操作。语法:
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...
此时是若没有发生冲突,就插入,若发生了冲突,就更新。注意,更新时也不能让主键/唯一键冲突
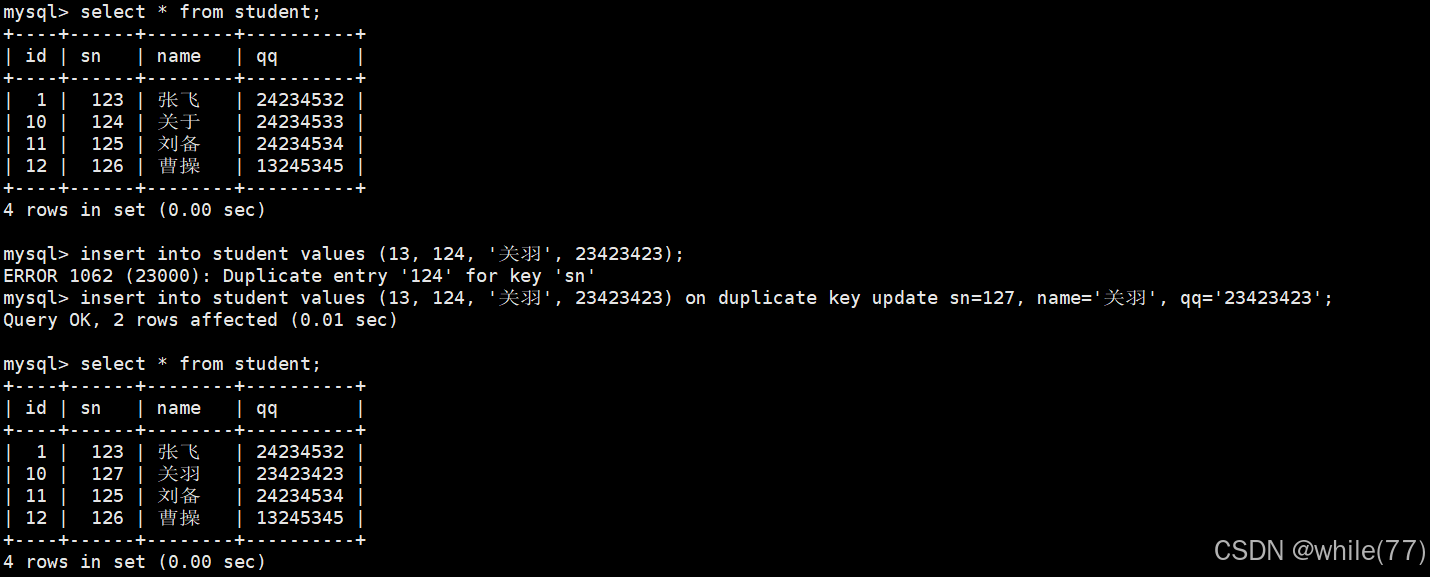
可以看到,前面和后面也并不一定要一样。
我们可以托命令执行后的语句来判断命令执行的结果
| 命令执行后语句 | 代表含义 |
| 0 rows affected | 表中有数据冲突,但冲突数据的值和update的值相等 |
| 1 rows affected | 表中没有数据冲突,数据被插入 |
| 2 rows affected | 表中有冲突数据,并且数据已经被更新 |
我们也可以使用row_count函数来查看前一个SQL语句影响的行数来判断执行结果。返回值:
| 返回值 | 含义 |
| 正整数 | 操作影响的行数或查询结果的行数 |
| 0 | 没有行受到影响,或查询返回空结果 |
| -1 | 通常表示错误或操作不支持行计数 |
| -2 | 某些驱动中表示行数未知 |
替换
在上面的插入否则更新中,可以看到,是将冲突的数据修改成我们指定是数据,而现在说的替换,是将原先冲突的数据删除,再重新插入
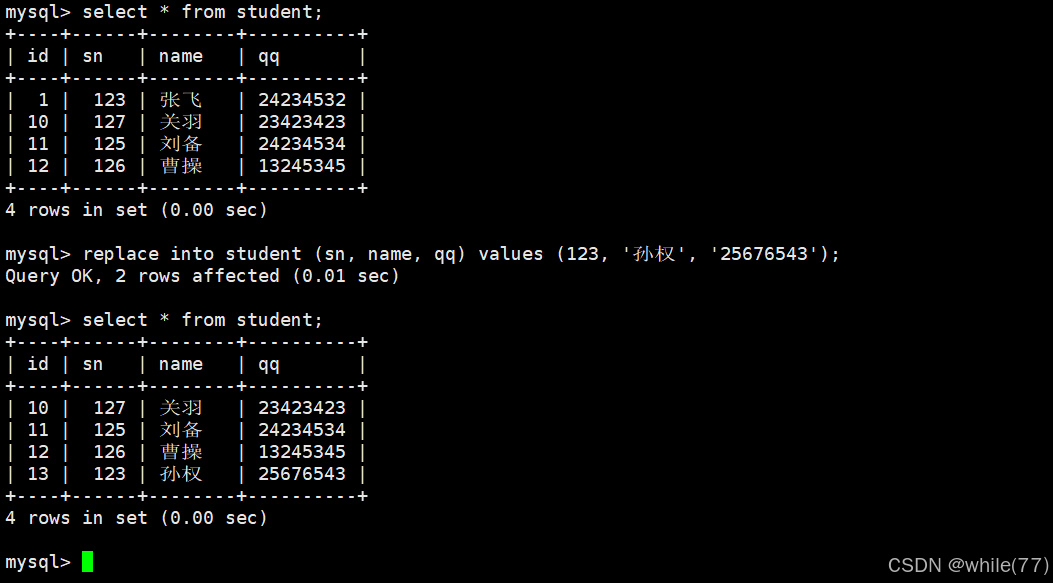
从这里的id值就可看出是先删除再插入
同样可以根据命令执行后的语句判断命令执行结果
| 命令执行后语句 | 代表含义 |
| 1 rows affected | 表中没有数据冲突,数据被插入 |
| 2 rows affected | 表中有数据冲突,删除后重新插入 |
查询
这是最关键的步骤。语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]LIMIT ...
distinct是去重。后面跟*或者指定列,*表示的是对全部的列进行查询。from是对那个表进行查询。where是筛选条件。order by是排序。limit是限定筛选出的结果条数。
我们先创建一个表,方便我们后面进行操作

并向其中插入一些数据
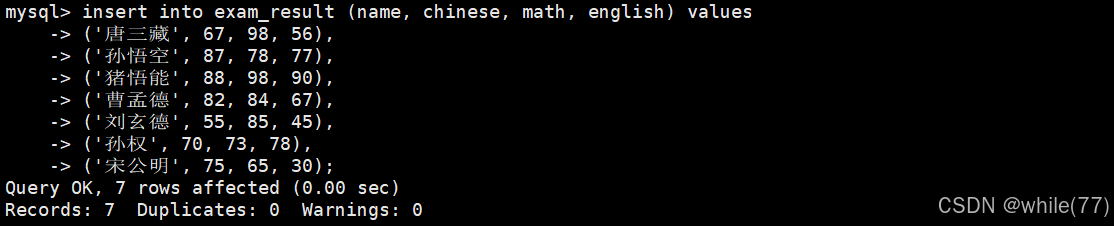
基本查询
全列查询
全列查询就是select的后面跟*
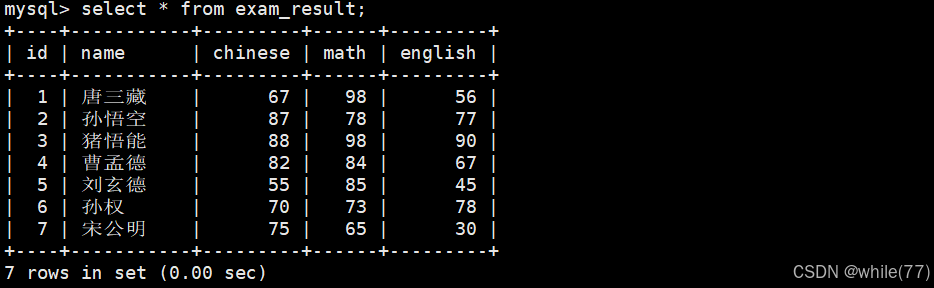
通常不建议使用 * 进行全列查询:
1. 查询的列越多,意味着需要传输的数据量越大
2. 可能会影响到索引的使用
指定列查询
指定列查询就是select后面跟列的名称
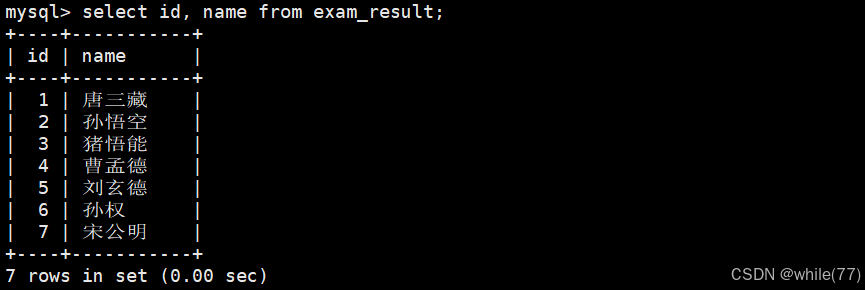
查询字段为表达式
select后面跟的就是要被执行的表达式,这个表达式可以是select自带的各种表达式,也可以是1+1等

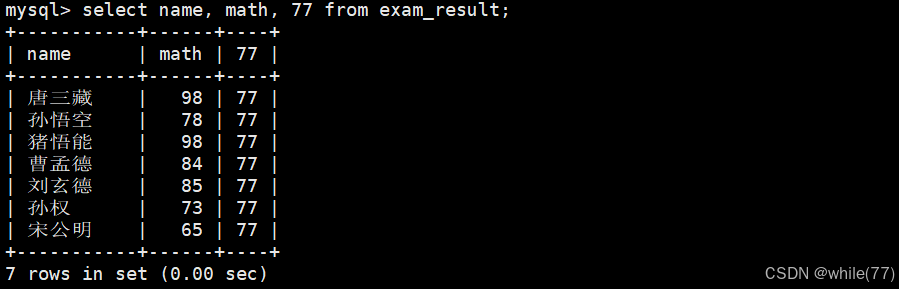
像这样就是给筛选出的信息每一行加上77
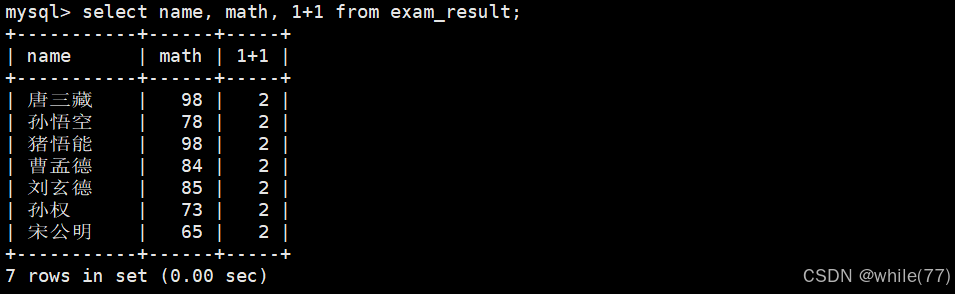
既然可以计算1+1,那么就一定可以计算几行之和,因为几行之和也是一个表达式
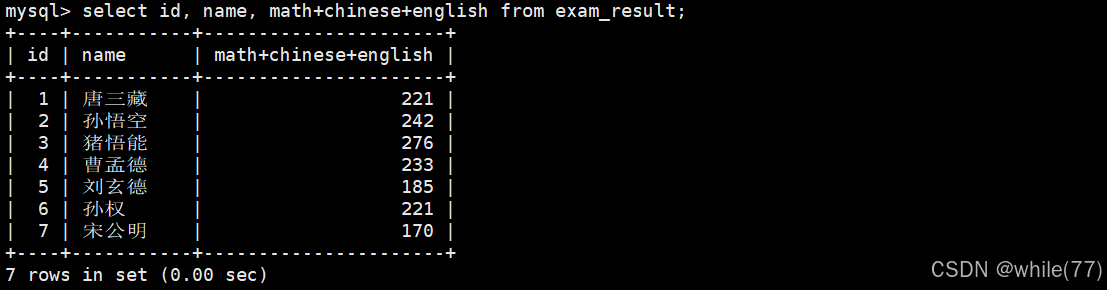
可以给筛选出来的一列取别名
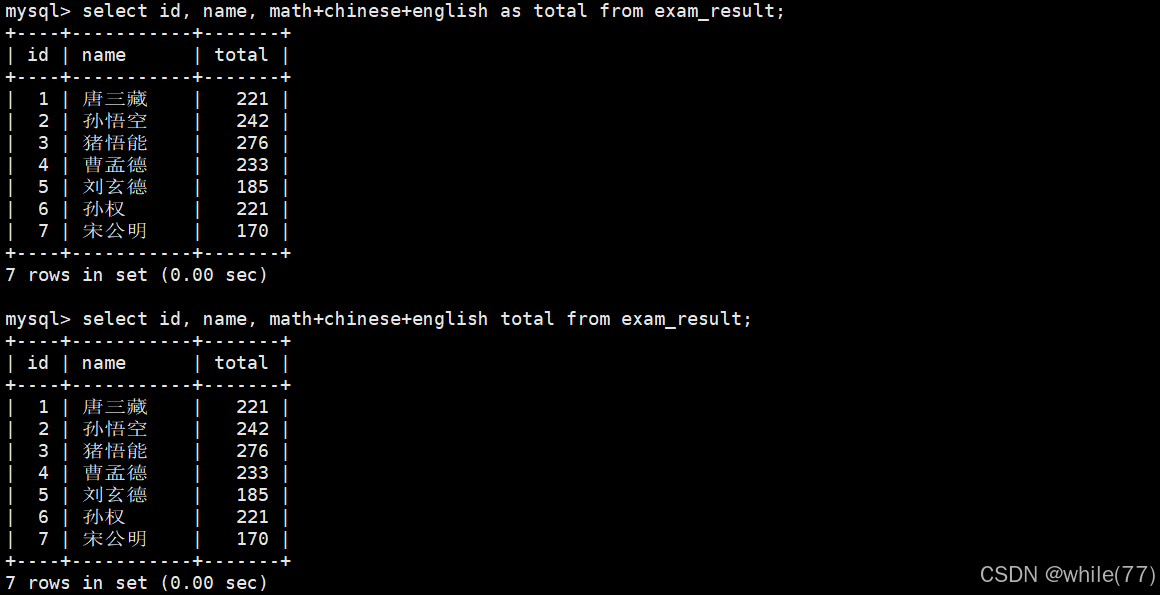
as是可以省略的
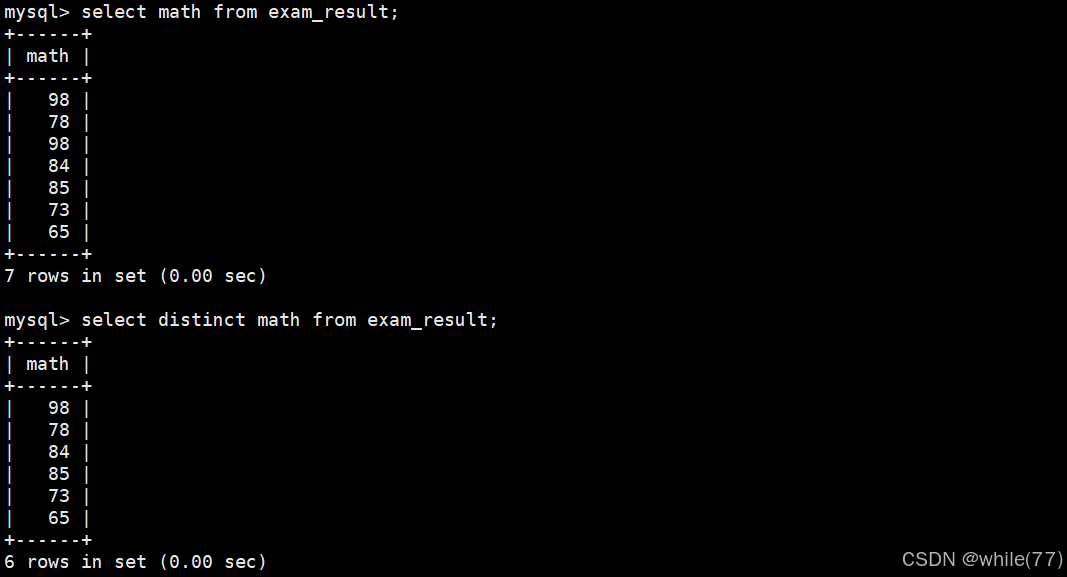
结果去重
可以在select的后面加上一个distinct进行结果去重
where子句
where子句是用来进行条件筛选的。刚刚是对表整体的信息进行筛选,是筛选出要显示的列,而where子句是筛选出要显示的行。where子句一般需要配合运算符进行使用。
比较运算符:

逻辑运算符:

解释一下上面的NULL不安全。在MySQL中,0、'\0'是不等于NULL的,=是不能用于判断一个值是否等于NULL的。

不等于的两个都是NULL不安全的。更喜欢使用is null或者is not null来判断一个值是否是空
我们使用一些案例来看一下where子句如何写
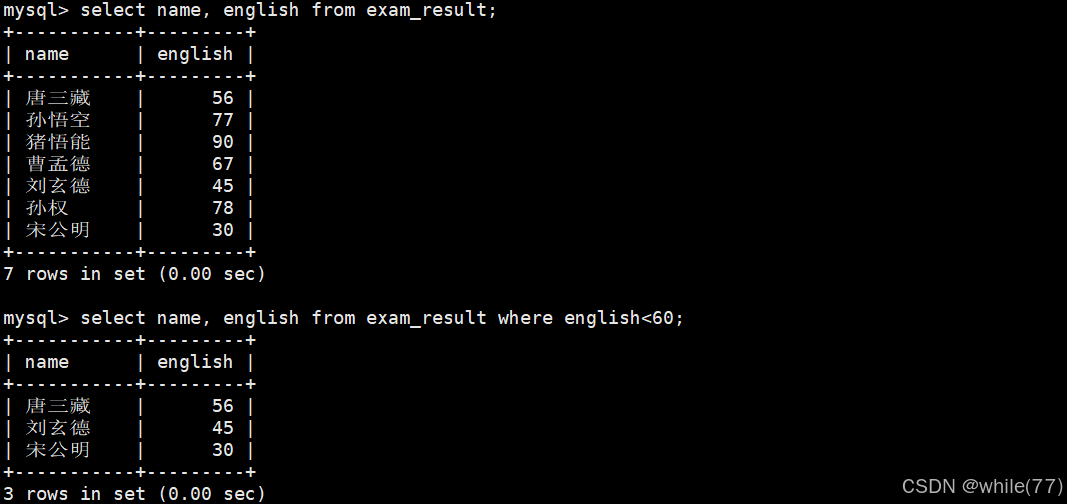
英语不及格的同学及其英语成绩
语文成绩在[80, 90]分的同学及语文成绩
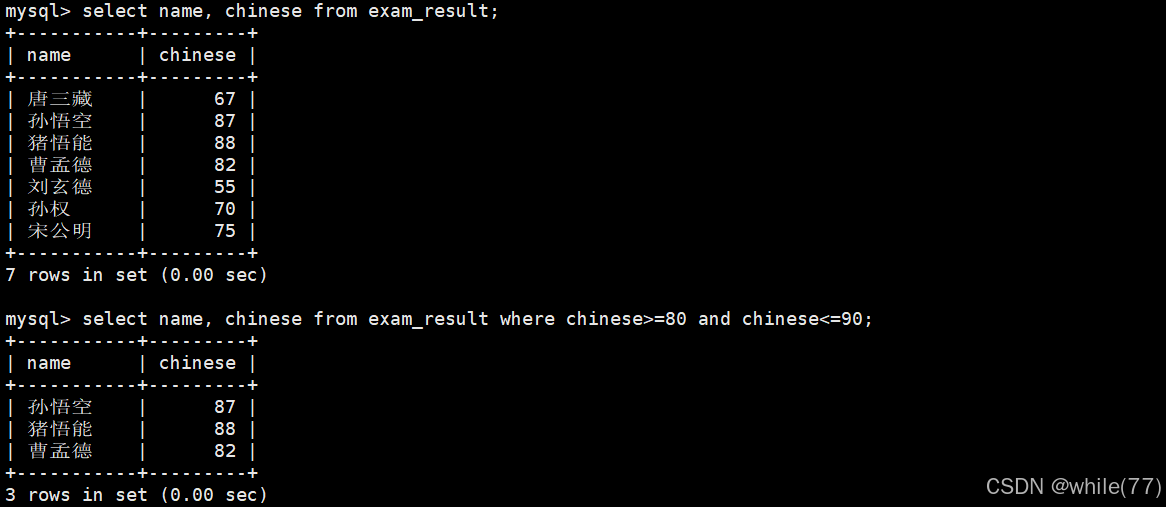
也可以使用between

数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩

也可以使用in,in是满足任意一个就为真

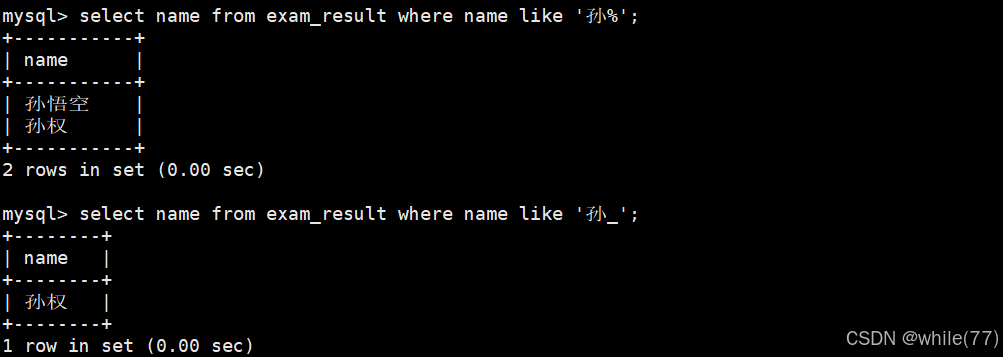
姓孙的同学及孙某同学
刚刚的都是比较是否相等、范围比较、判断是否在集合当中,有时候匹配时并不能确定非常细节的字段含义,可能只给了一个很模糊的搜索字段关键字,此时就可以使用like。%表示匹配任意多个字符(包括0个),_表示匹配任意一个字符。
语文成绩好于英语成绩的同学
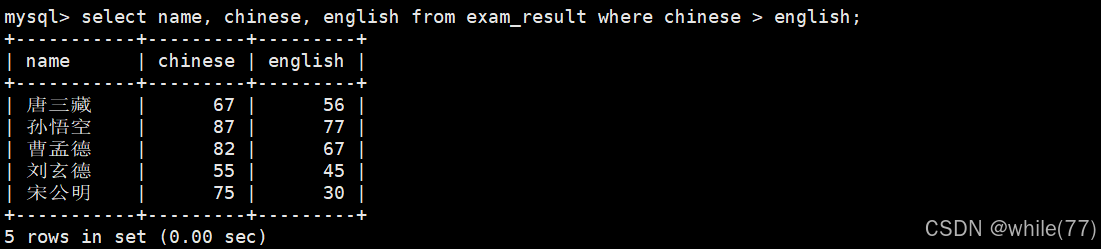
所以,可以一个列与数字比较、一个列与字符串比较、模糊匹配,也可以列与列之间比较
总分在200分以下的同学
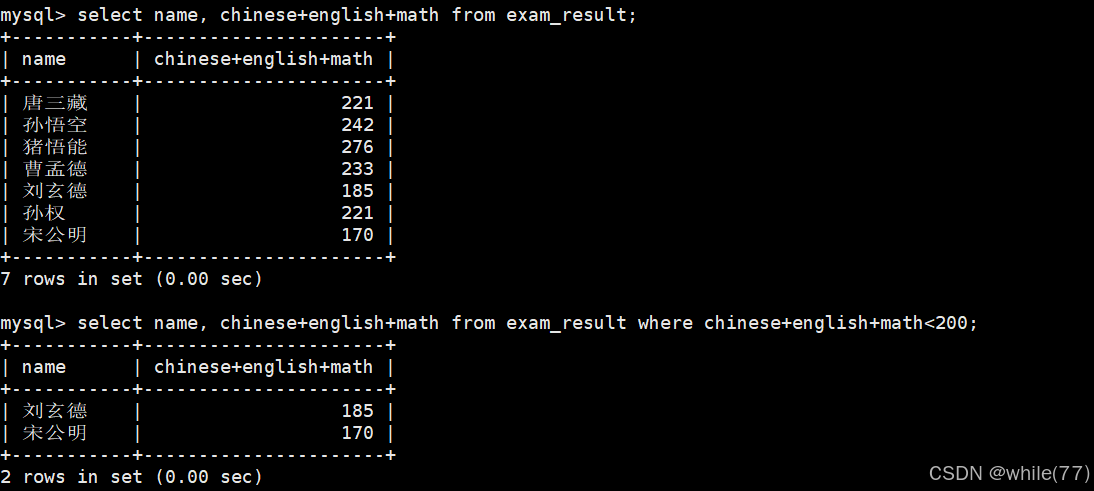
所以,where子句后面是可以跟表达式的。上面的太长了,我们试试给它们取别名。
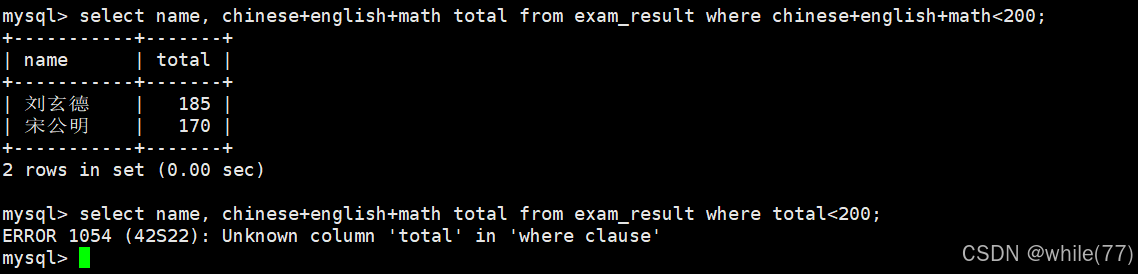
为什么第一句可以,第二句就不行呢?这就需要考虑在select语句中的执行顺序了。

数字代表执行顺序。所以,在执行到where时还没有执行到重命名,自然不认识重命名后的值。总结:不能在筛选时进行重命名,因为这属于是显示的范畴了。重命名应该是在筛选完了,最后显示时才弄。
语文成绩大于80,并且不姓孙的同学
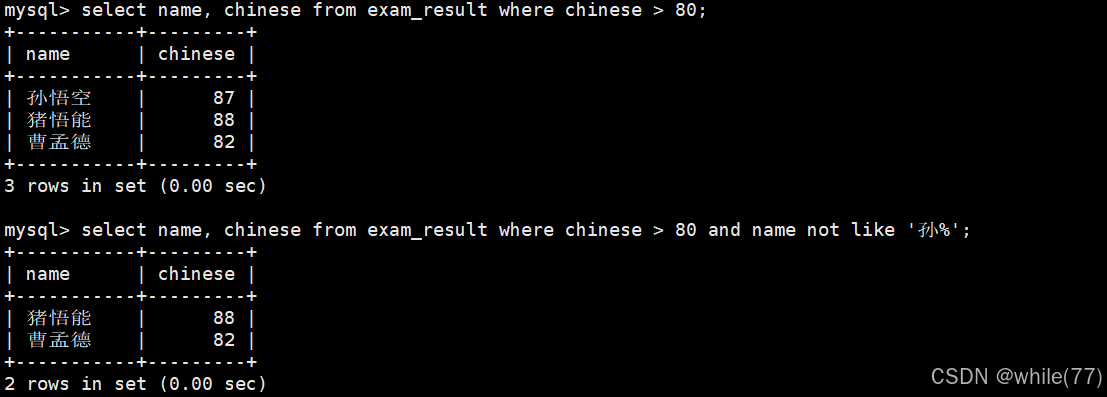
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80

MySQL支持将条件使用一个括号括起来,表示一个条件

NULL的查询
我们创建一张表,并向其中插入一些包含NULL的值


id为5的name是插入了一个空串
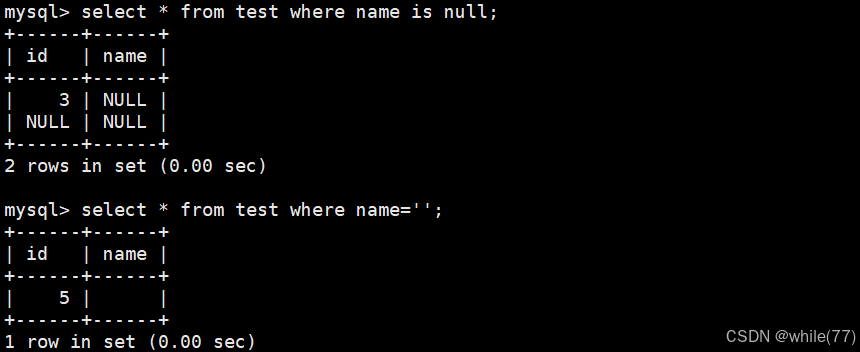
可以看到,空串和null是不同的
结果排序
可以使用order by子句来对查询出的结果进行排序。asc是升序,desc是降序,默认情况下是升序。注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。没有使用order by子句时,是根据表中的原始数据进行罗列的,永远不要依赖这个顺序,即使这个顺序本身就是有序的。
同样使用几个案例来熟悉一下order by子句
同学及数学成绩,按数学成绩升序显示
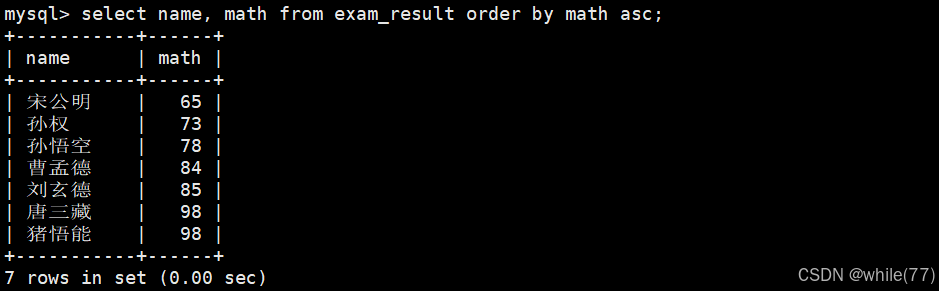
同学的姓名,排序显示
我们找一个包含NULL的列的表,看看NULL在排序中的数值大小
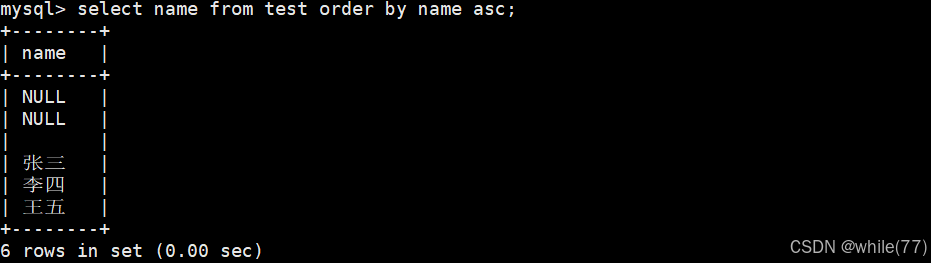
NULL视为比任何值都小
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
这里的意思是,当数学成绩相同时,按英语升序排序,当英语成绩也相同时,按语文升序排序
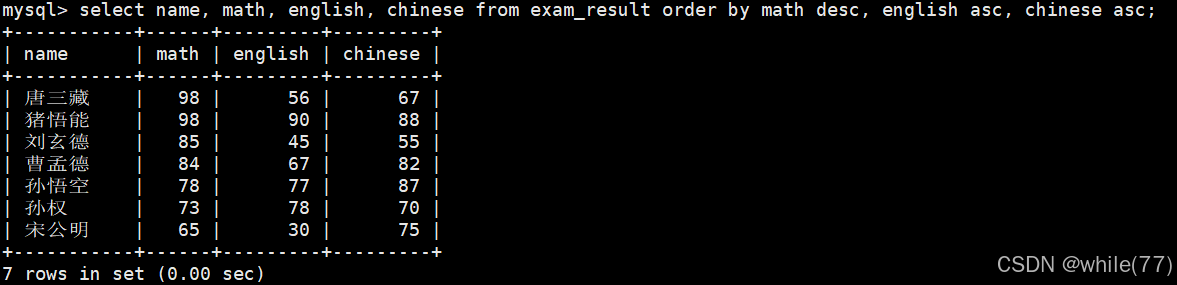
因为默认情况下是升序的,所以可以将一些升序去掉
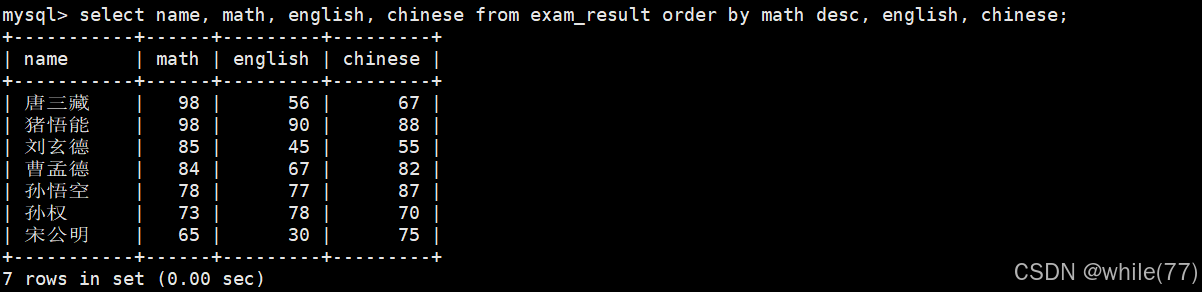
查询同学及总分,由高到低
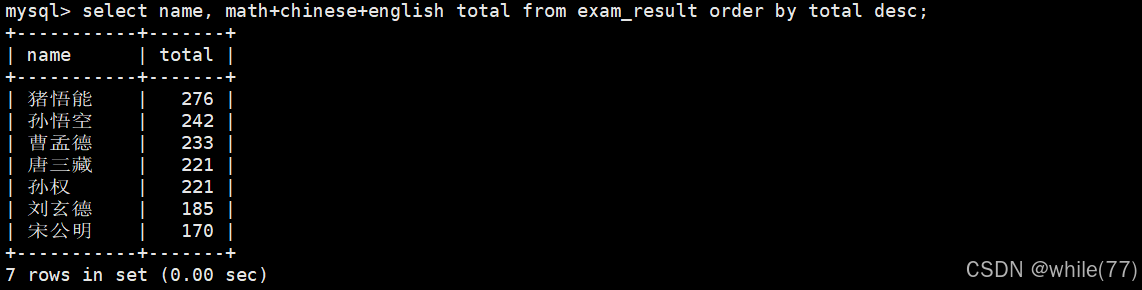
可以看到,使用order by进行结果排序时是可以使用别名的。只有当数据筛选好了之后,才可以进行排序

查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示

筛选分页结果
MySQL中limit子句用于限制select语句返回的结果数量
- 起始下标为0,也就是说select的结果的第一行下标为0
- 从0开始,筛选n条结果
select ... from table_name [where ...] [order by ...] limit n; - 从s开始,筛选n条结果,s是下标,n是步长
select ... from table_name [where ...] [order by ...] limit s, n;
所以,limit 3等同于limit 0, 3 - 从s开始,筛选n条结果,s是下标,n是步长,比第二种用法更明确,建议使用
select ... from table_name [where ...] [order by ...] limit n offset s;
建议:对未知的表进行查询时,最好加一条LIMT1,辟免因为表中数据过大查询全表数据导致数据库卡死
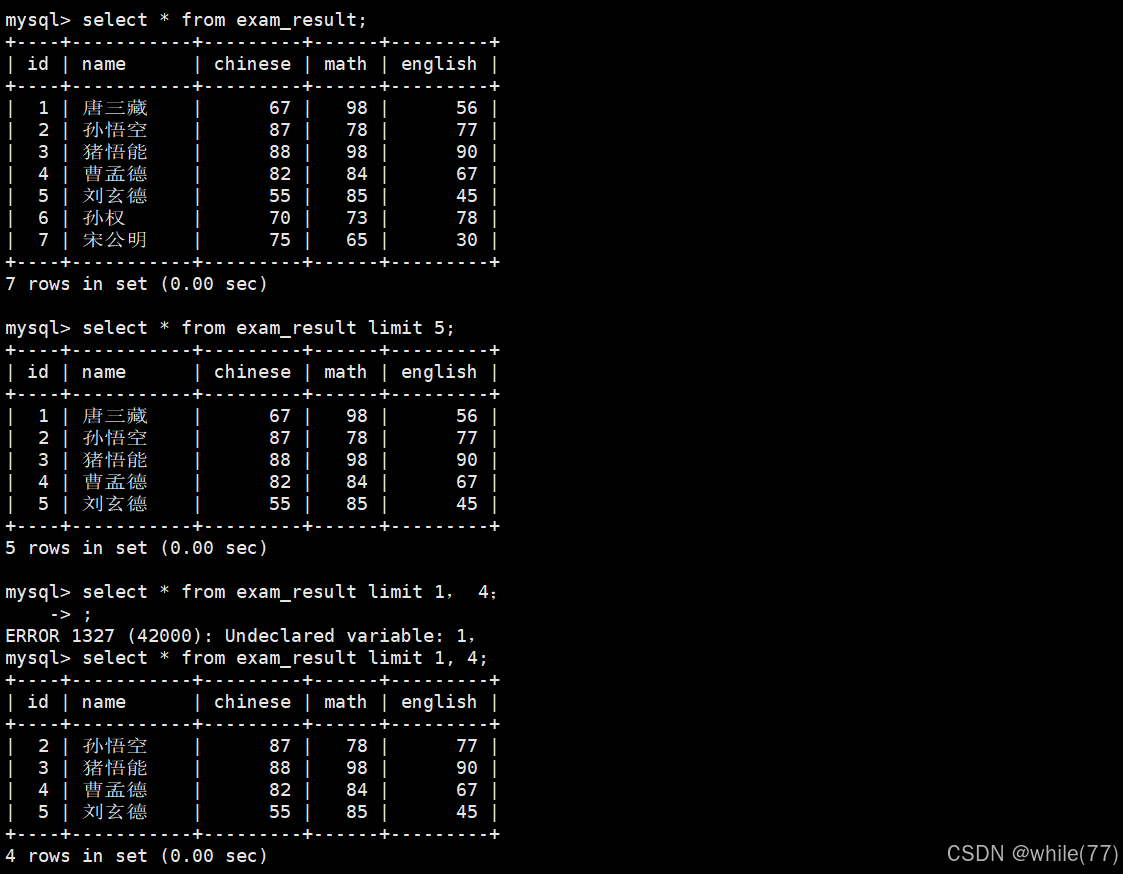
limit可实现简单的分页功能
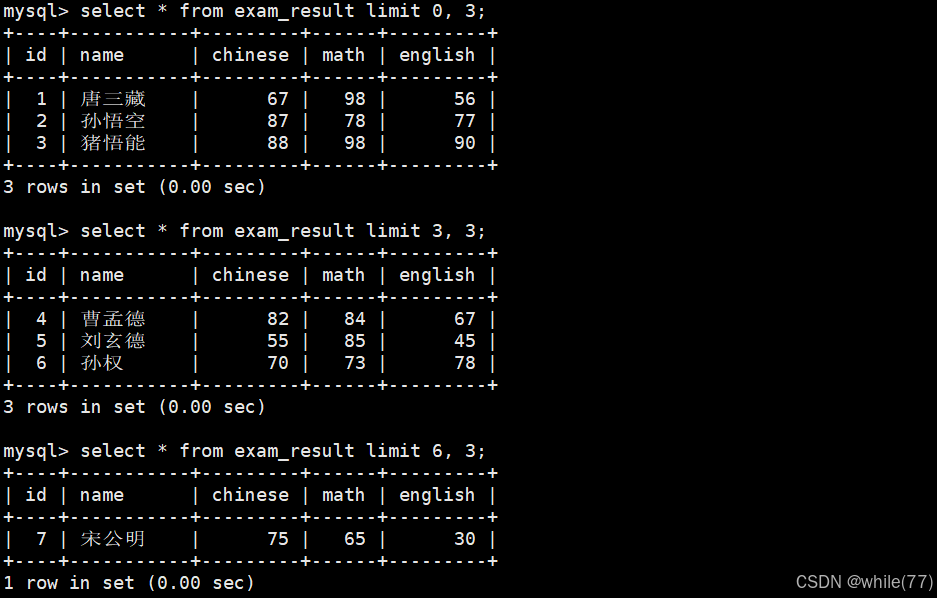
获取班级总分第一
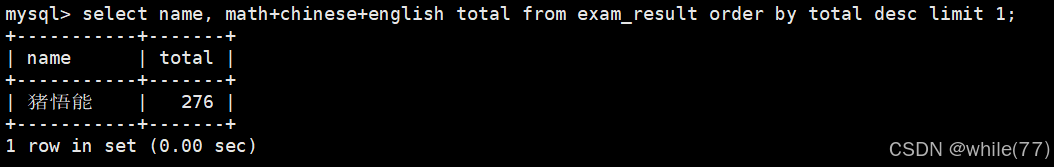
将班级总分大于200分的同学分成3个等级,每个等级最多两个同学
只有当数据准备好了,才要进行显示,limit的本质就是对显示的限制

修改(更新)
语法
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
将指定列的值修改成什么,左侧是列名,右侧是表达式。一般需要通过where来限定行,否则会将这个表中所有的这一列都修改成这个值
对查询到的结果进行列值更新
将孙悟空同学的数学成绩变更为 80 分
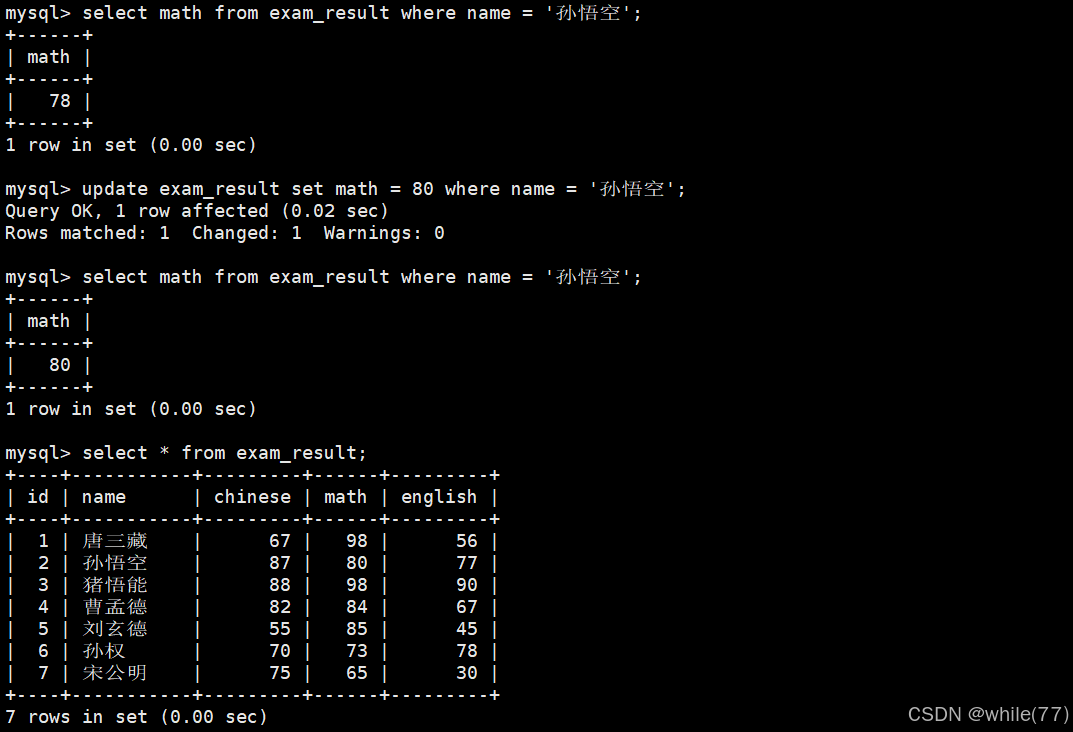
可以看到,此时只有孙悟空的数学变成了80,若没有where会将这个表中math这一列所有的值都修改成80
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
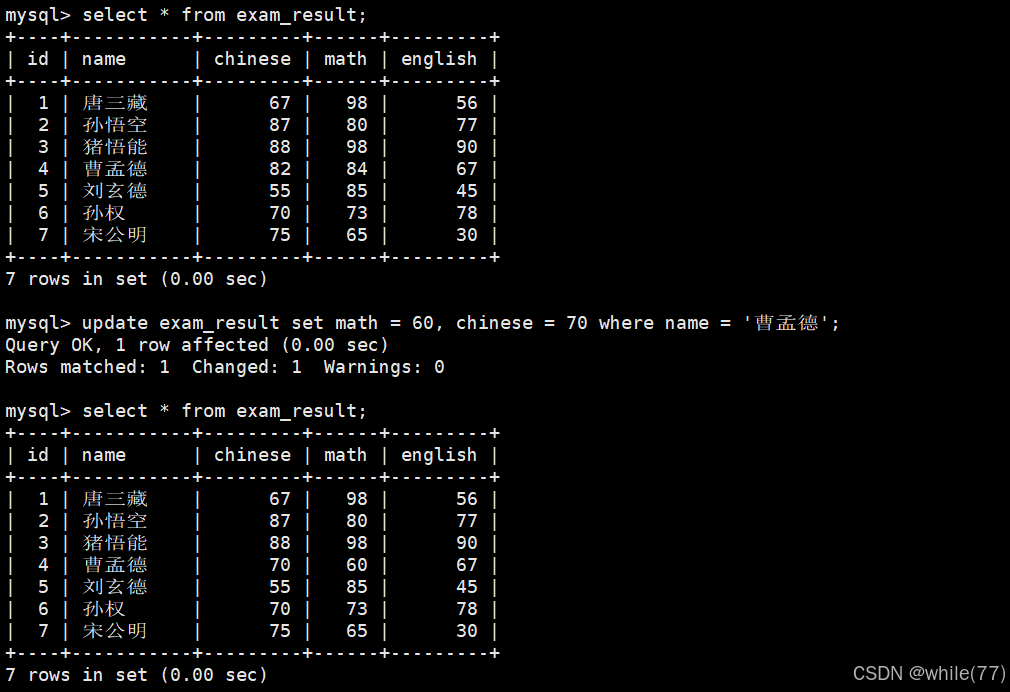
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
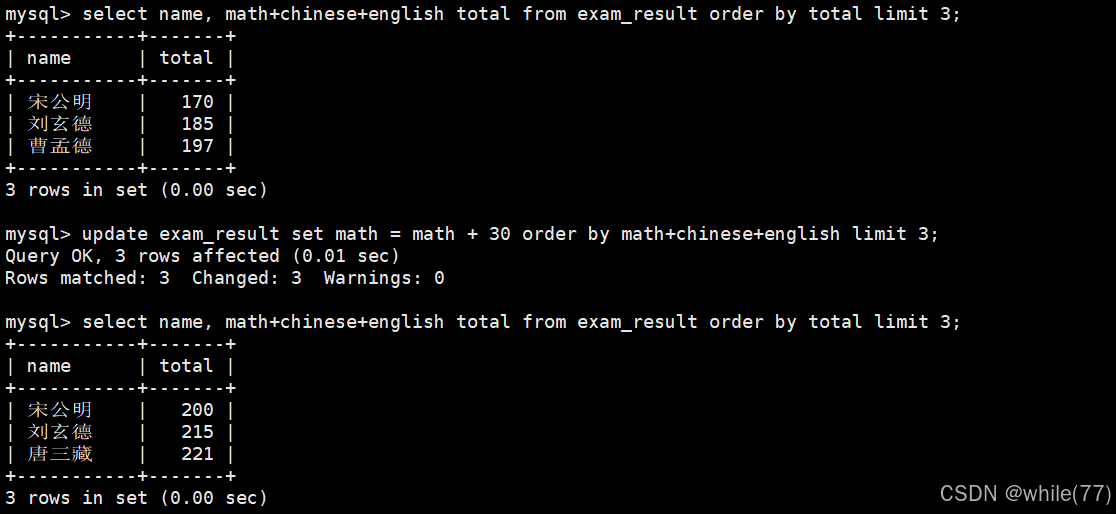
MySQL是不支持+=的
将所有同学的语文成绩更新为原来的 2 倍
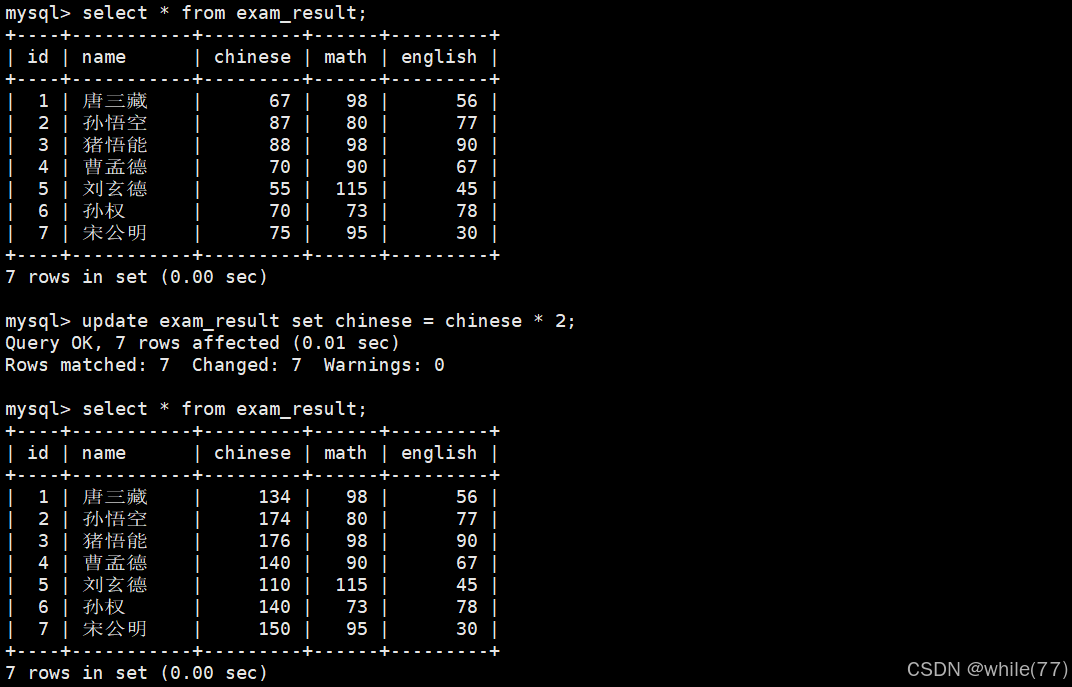
注意:更新全表的语句慎用
删除
普通删除
语法
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
delete from table_name,这样是删除整张表的数据,表的结构不变。若想要将表删除,需要使用drop
删除孙悟空同学的考试成绩
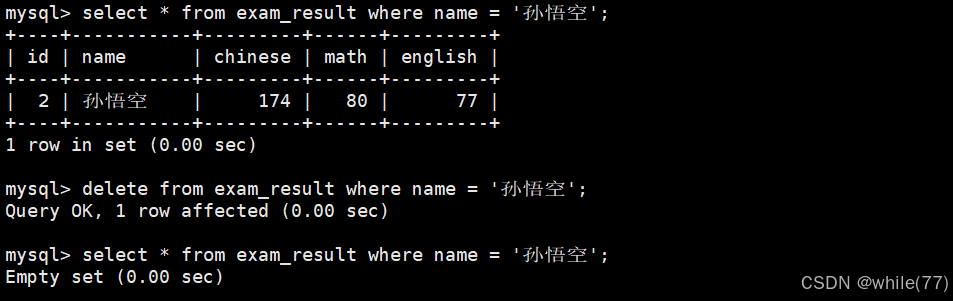
删除成绩倒数第一的同学
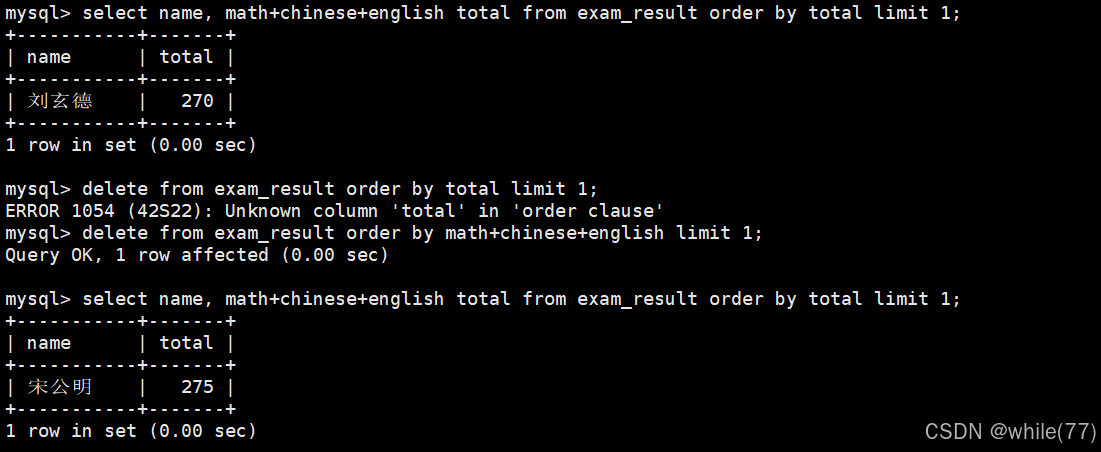
删除整张表的数据
注意:删除整张表的数据要慎用
我们先创建一个测试表

并向其中插入一些数据
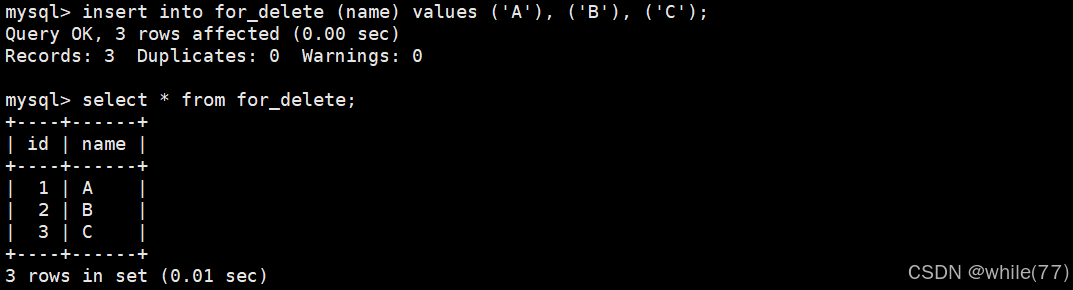

id会自增是因为维护了计数器
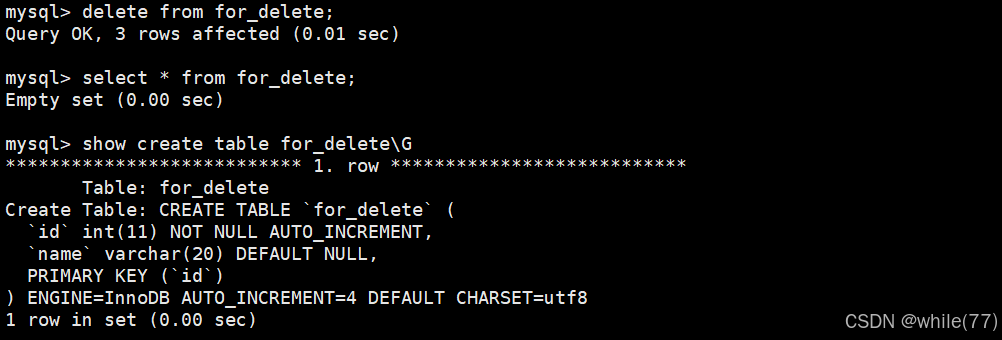
会发现使用这种方式将表内的数据清除后,计数器并没有变化
截断表
这是另外一种将表内容清空的方式
TRUNCATE [TABLE] table_name
注意:这个操作一定要慎用
先准备一个测试表

并向其中插入一些数据
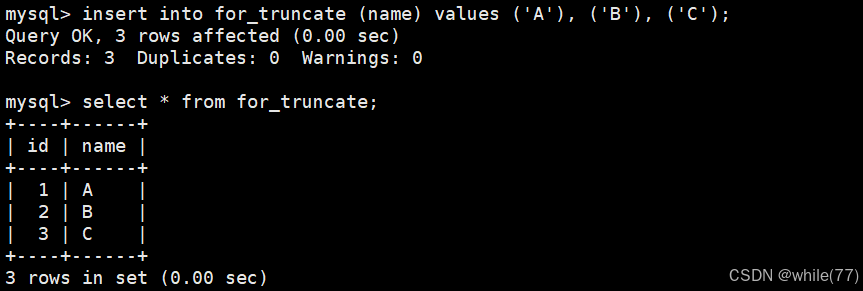
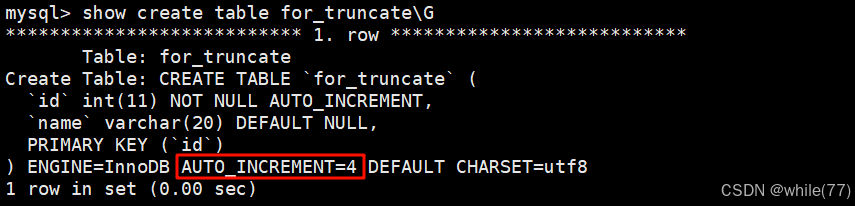
现在使用truncate将表清空
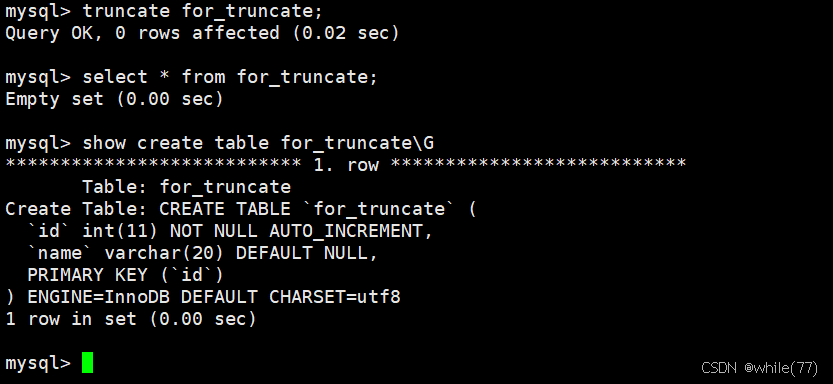
这种清空表的方式,同样不会改变表的结构,但是会将计数器重新置位
truncate与delete的区别
- truncate只能对整表操作,不像delete一样针对部分数据操作
- truncate会重置auto_increment项
- truncate不走事物,直接将表的内容清空,delete会先变成事物,再将表的内容清空,所以,truncate更快
插入查询结果
INSERT INTO table_name [(column [, column ...])] SELECT ...
将从其他表中查询到的结果插入到insert后面的表中。属于是SQL语句的组合使用
删除表中的重复数据
我们先创建一个测试表,并向这个表中插入一些数据
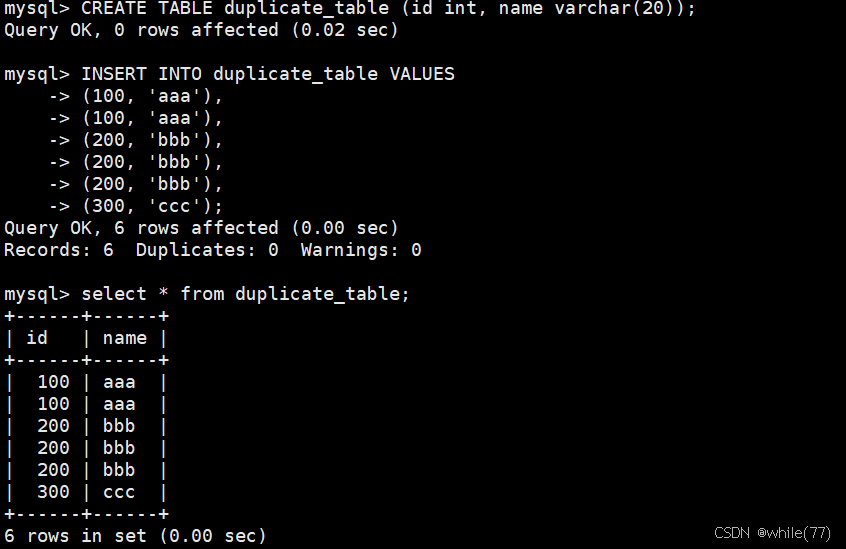
此时可能会想到
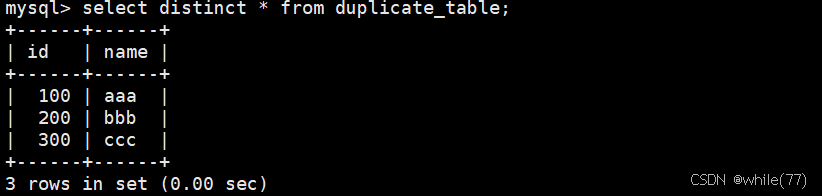
这样明显是不行的,因为这样只是查询时去重,表内的数据是没有去重的
我们此时想去重,可以再创建一张新表,将现在这张表查询去重后的结果插入到新表中。再将原来的表重命名,并将新表的名字改成原来表的名字
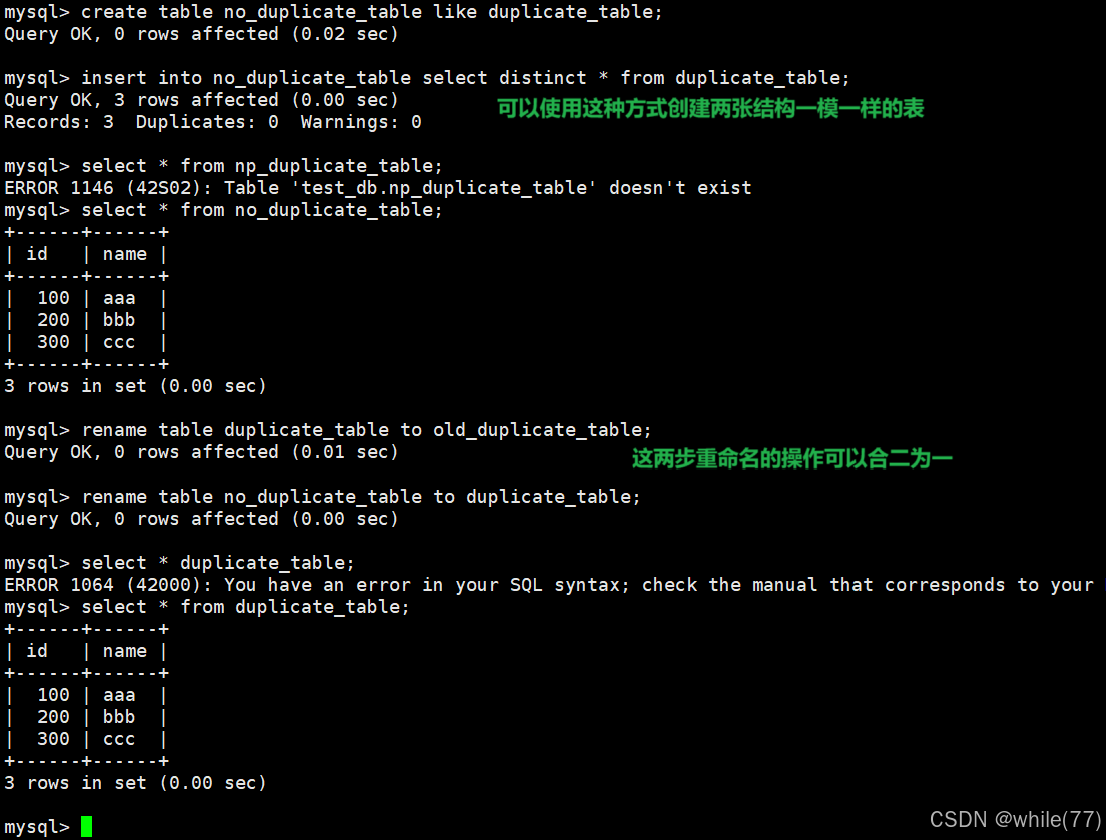
为什么最后要使用rename的方式进行,而不是直接修改目标表呢?
MySQL建一个数据库就是建一个文件夹,创建一个表就是创建一个文件(在C/C++中就是open/fopen),就是学指令时的touch。重命名调用的就是rename这样的系统调用,mv也一样。现在想将一个文件以原子的方式上传Linux的某目录下,这个文件可能比较大,不会一下上传完成,若直接上传到这个目录下不一定是原子的。一般会将这个为文件上传到一个临时目录下,全部上传完成后,再将这个文件move到指定的目录下面,因为move是原子的。就是单纯地相等一切都就绪了,然后统一放入、更新、生效等。
聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
聚合是有条件的,一定要保证列的数据类型是可以被聚合的
计算班级共有多少同学
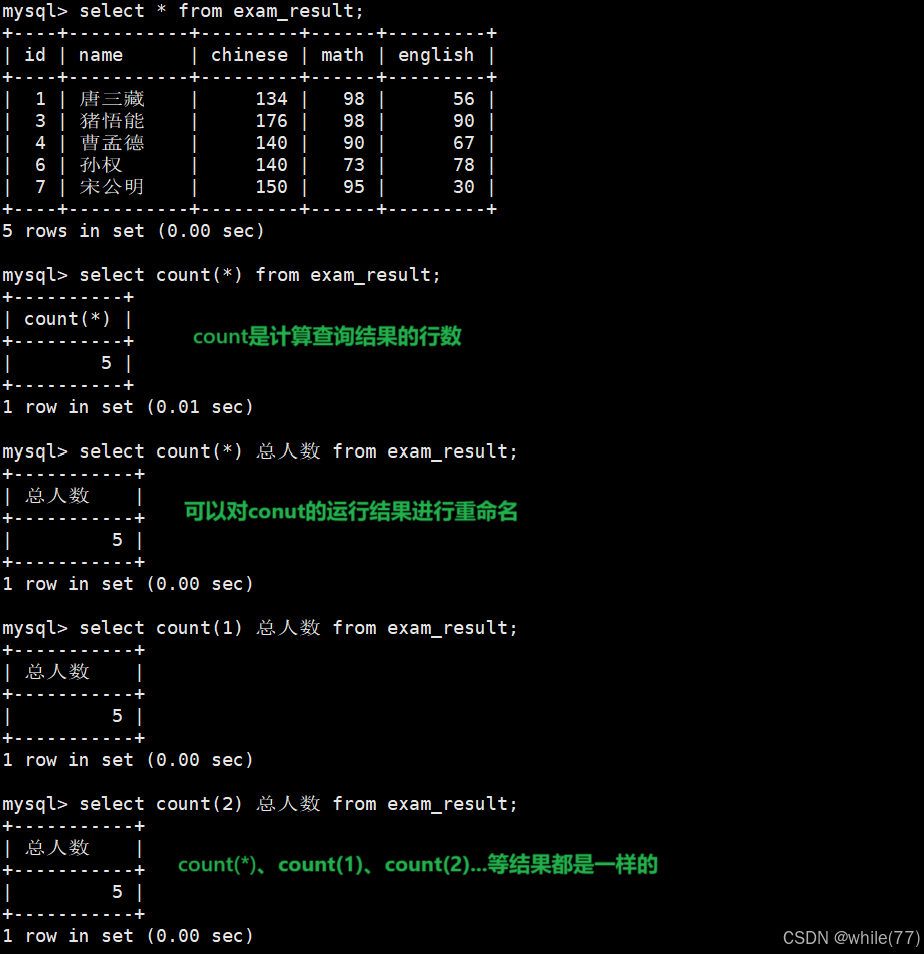
统计本次考试的数学成绩个数
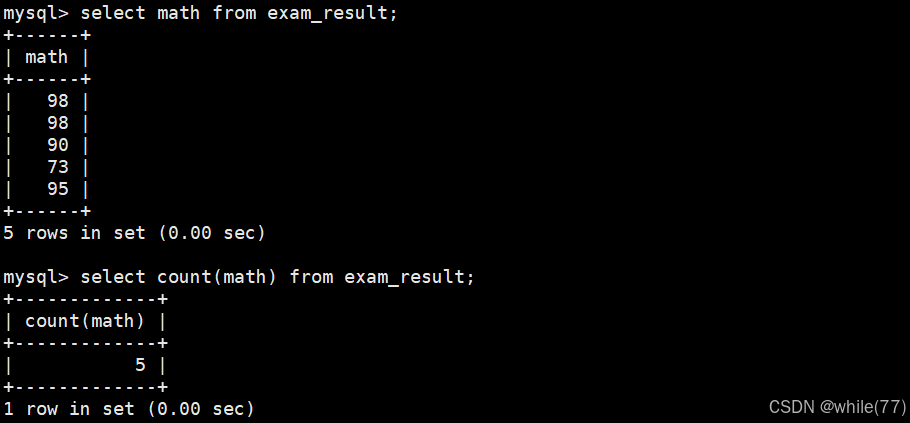
因为数学成绩中有重分的,所以直接统计肯定是不行的,需要去重

这样是对聚合后的结果进行了去重,聚合后的结果就是一个数字,没有必要去重
我们应该是对math去重,去重后再让其聚合

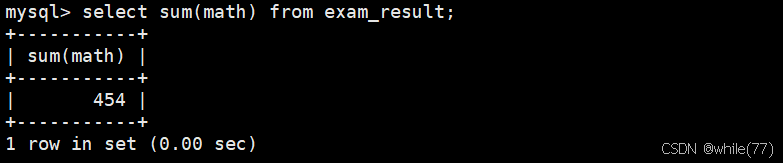
统计数学成绩总分
统计英语成绩不及格的人数

统计数学成绩的平均分
方法一

方法二

获取英语的最高分

如果我们向要同时获取英语最高峰和这个最高分的名字

像这样是会报错的。聚合是需要先将数据筛选出来,并且保证数据能够被聚合才能使用的,name的数据类型不允许被聚合,此时需要先分组再聚合。若想知道英语最高分是谁,应该orderby+limit
分组查询
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
分组的目的是为了分组之后,方便进行聚合统计。是先将数据拿到,然后分组,分组完成后进行聚合统计。如我们想统计一下班级中男生、女生的数学最高分是多少,此时就可以将男生、女生分成不同组,再进行聚合统计
我们可以将分组,理解成"分表"。也就是说,将根据某一条件分组后的每一个结果,都看成是一个表。并且我们前面查询后的结果等,虽然只是表内的一部分数据,我们也可以看成是一张完整的表
我们先导入我们要进行实验的数据库

传输完成后就能看到当前目录下就有了.sql文件
![]()
再使用这个语句就可以将这个.sql里面的SQL在MySQL中执行一遍
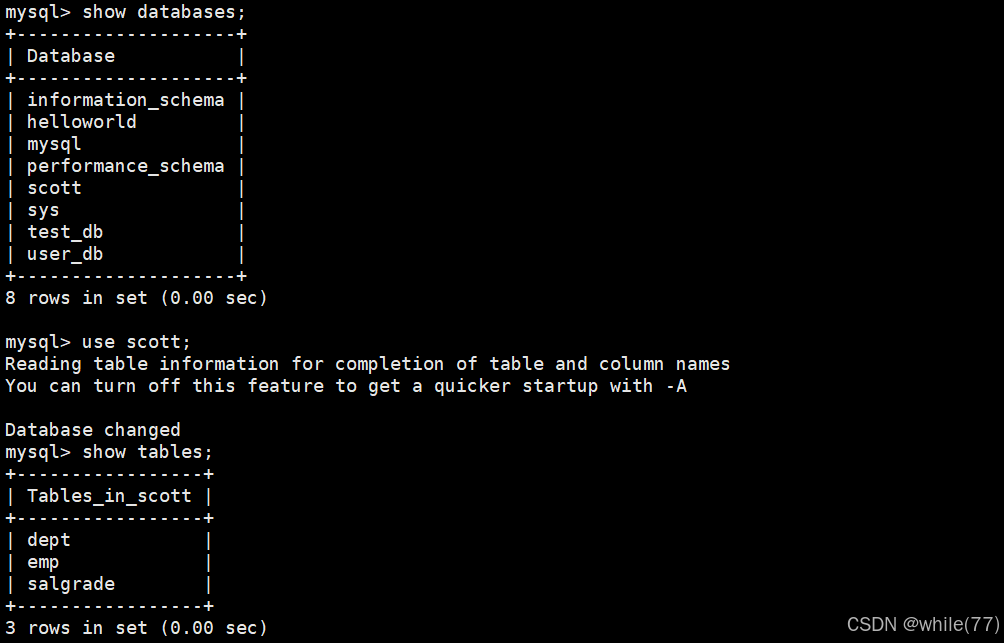
此时就多了一个数据库。这个数据库中有3个表。dept是部门信息表,emp是员工信息表,salgrade是员工薪资等级表
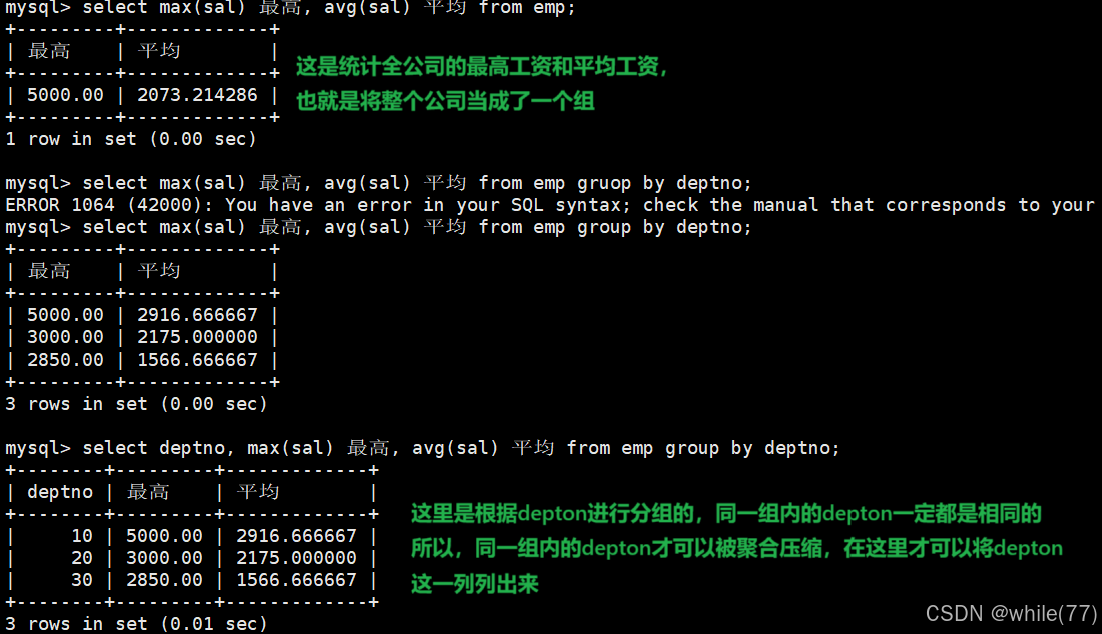
显示每个部门的平均工资和最高工资
我们需要根据部门将表划分成多个部分,然后针对每一个部分进行统计
显示每个部门的每种岗位的平均工资和最低工资
我们需要先根据部门进行分组,再针对每个部门的不同岗位进行分组,然后再统计
group by后面是可以跟多个列名称的,表示根据多个条件进行分组
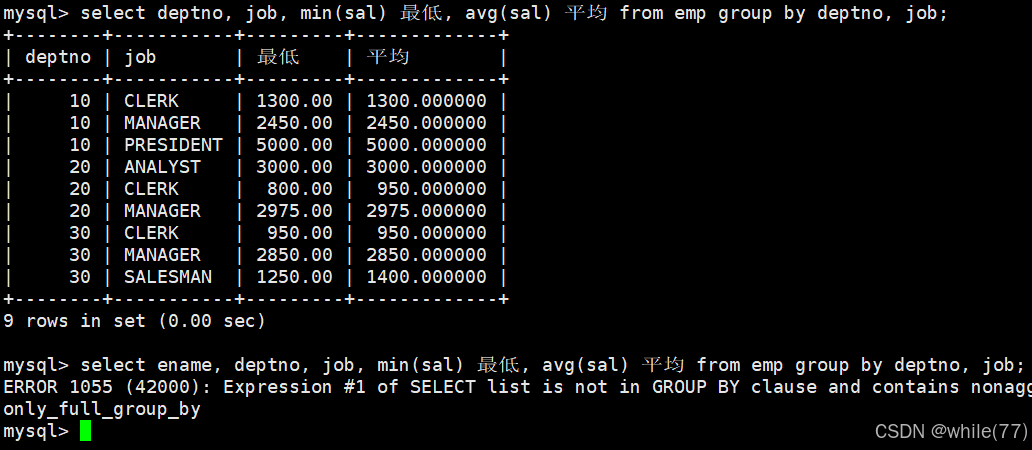
会发现加上员工的名称就会报错,因为分到最下面,部门、岗位是相同的,这两个可以进行聚合压缩,但是组内每个人的姓名是不同的,不能进行聚合压缩。当我们涉及到聚合压缩时,只有出现在group by后面的列名称和聚合函数可以放在select后面。
显示平均工资低于2000的部门和他的平均工资
第一:需要先聚合统计出每个部门的平均工资
第二:对聚合统计的结果进行判断
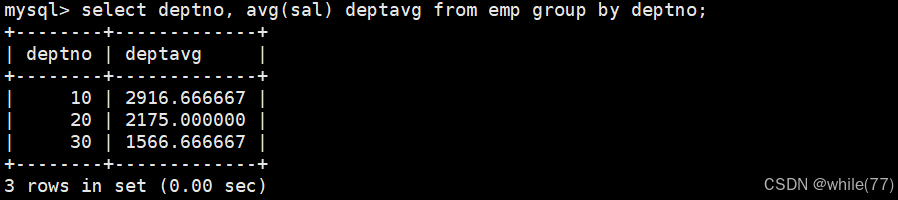
这是聚合出来的结果,接下来需要对聚合的结果进行判断。对聚合的结果进行判断就需要使用having。前面的先执行,然后再执行having,所以是可以使用别名的
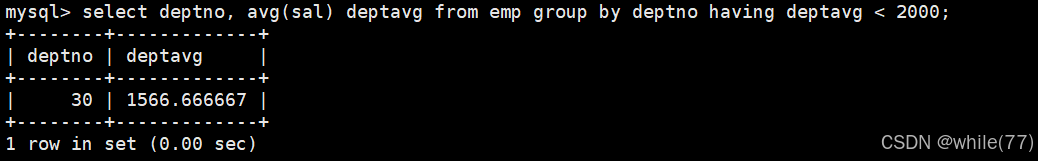
having是对聚合统计后的数据进行条件筛选的
having vs where
having和where都可以进行条件筛选,但是两者是完全不同的条件筛选

我们将上面SQL语句的having改成where会发现就不行了

会发现having完全是可以充当where的功能的。因为我们前面说了,我们将分组后的结果当成一张表,而emp本身就是一张表
假设我们现在要:显示平均工资低于2000的部门和他的平均工资,且员工SMITH不参与


所以,having和where都是进行条件筛选,但是条件筛选的阶段是不同的
最后再强调一遍:不要单纯的认为,只有磁盘上表结构导入到mysql,真实存在的表,才叫做表;中间筛选出来的,包括最终结果,在我看来,全部都是逻辑上的表!