【数据可视化-25】时尚零售销售数据集的机器学习可视化分析
🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【数据可视化-25】时尚零售销售数据集的机器学习可视化分析
- 一、引言
- 二、数据集概述
- 2.1 数据加载与预览
- 2.2 数据清洗与预处理
- 2.3 异常值处理
- 三、数据可视化分析
- 3.1 销售总额分析
- 3.2 按日期分组的销售情况
- 3.3 年度销售分布
- 3.4 支付方式分析
- 3.5 平均单笔消费最高的用户分析
- 3.6 热门商品分析
- 3.7 评论评分分布
- 3.8 不同交付方式的销售总额分析
- 四、结论
一、引言
在时尚零售行业中,对销售数据进行深入分析可以帮助企业了解客户购买行为、产品受欢迎程度和支付偏好等关键信息。本文将通过一个包含3400条时尚零售记录的数据集,进行详细的可视化分析,并提供完整的Python代码,以帮助读者更好地理解数据并从中提取有价值的信息。
二、数据集概述
数据集包含以下列:
- Customer Reference ID:整数类型,每个客户的唯一标识符。
- Item Purchased:字符串类型,购买的时尚商品的名称。
- Purchase Amount (USD):浮点数类型,商品的购买价格(以美元为单位),存在650个缺失值。
- Date Purchase:字符串类型,购买日期(格式:DD-MM-YYYY)。
- Review Rating:浮点数类型,买家评论评分(1到5分)。
- Payment Method:字符串类型,使用的付款方式(如信用卡、现金等)。
2.1 数据加载与预览
首先,加载数据集并进行初步的预览和探索。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据集
df = pd.read_csv("/kaggle/input/fashion-retail-dataset/fashion_retail.csv")# 显示前几行数据
print(df.head())
2.2 数据清洗与预处理
在进行深入分析之前,我们需要对数据进行清洗和预处理。
# 将Date Purchase转换为日期类型
df['Date Purchase'] = pd.to_datetime(df['Date Purchase'], format='%d-%m-%Y')
# 缺失值处理
df['Purchase Amount (USD)'] = df['Purchase Amount (USD)'].fillna(df['Purchase Amount (USD)'].mean())
df['Review Rating'] = df['Review Rating'].fillna(df['Review Rating'].mode()[0])
2.3 异常值处理
通过箱线图查看数据异常情况。
sns.boxplot(data=df)
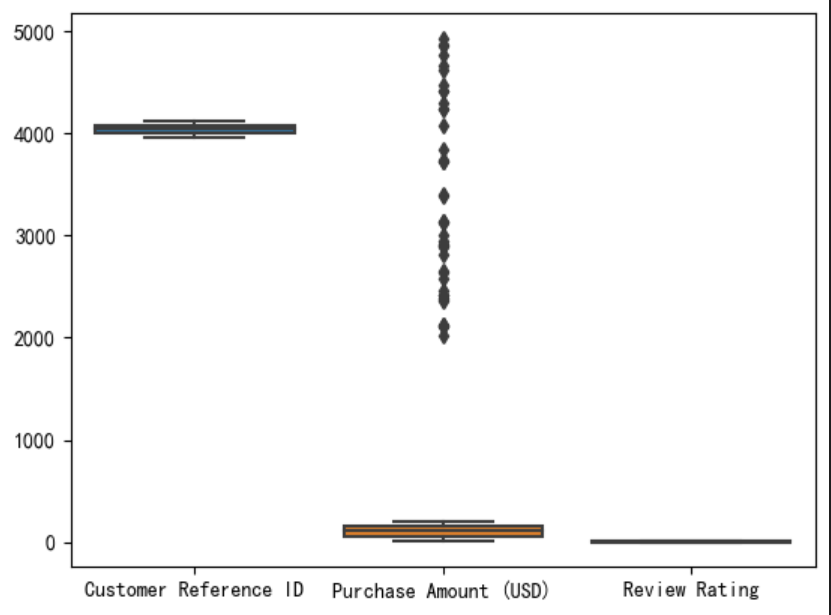
从图中我们可以发现,'Purchase Amount (USD)'列中存在比较多的异常值,将异常值进行替换。
# 计算均值和标准差
mean = df['Purchase Amount (USD)'].mean()
std = df['Purchase Amount (USD)'].std()# 计算上下限
lower_bound = mean - 3 * std
upper_bound = mean + 3 * std# 将异常值替换为均值
df['Purchase Amount (USD)'] = np.where((df['Purchase Amount (USD)'] < lower_bound) | (df['Purchase Amount (USD)'] > upper_bound), mean, df['Purchase Amount (USD)'])sns.boxplot(data=df)
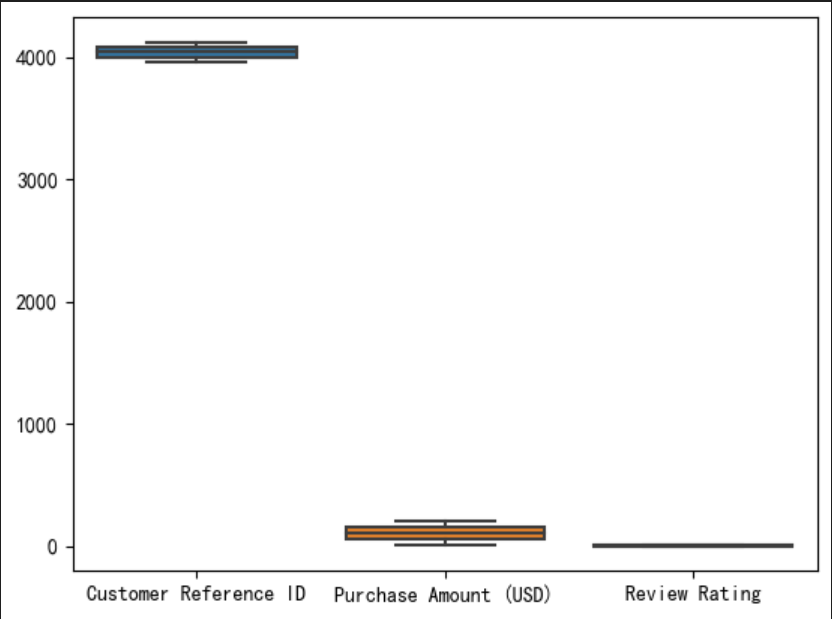
三、数据可视化分析
3.1 销售总额分析
sns.kdeplot(data=df,x='Purchase Amount (USD)')
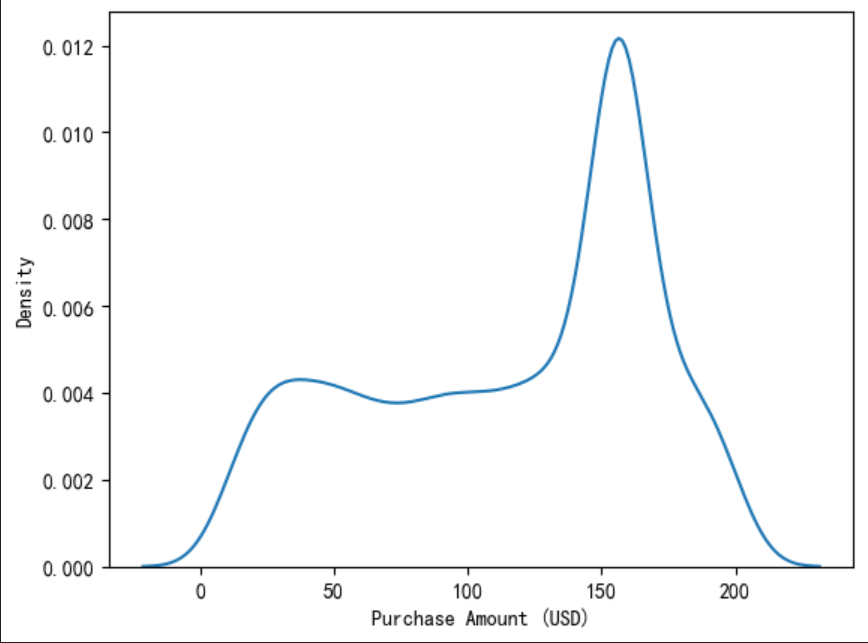
3.2 按日期分组的销售情况
# 按日期分组并计算每日销售总额
daily_purchase_df = ready_df.groupby('Date Purchase')['Purchase Amount (USD)'].sum().reset_index()plt.figure(figsize=(25, 8))
plt.plot(daily_purchase_df['Date Purchase'], daily_purchase_df['Purchase Amount (USD)'], color='purple')
plt.xlabel('Date')
plt.ylabel('Sales Amount (USD)')
plt.title('Amount Of Sales By Date')
plt.show()
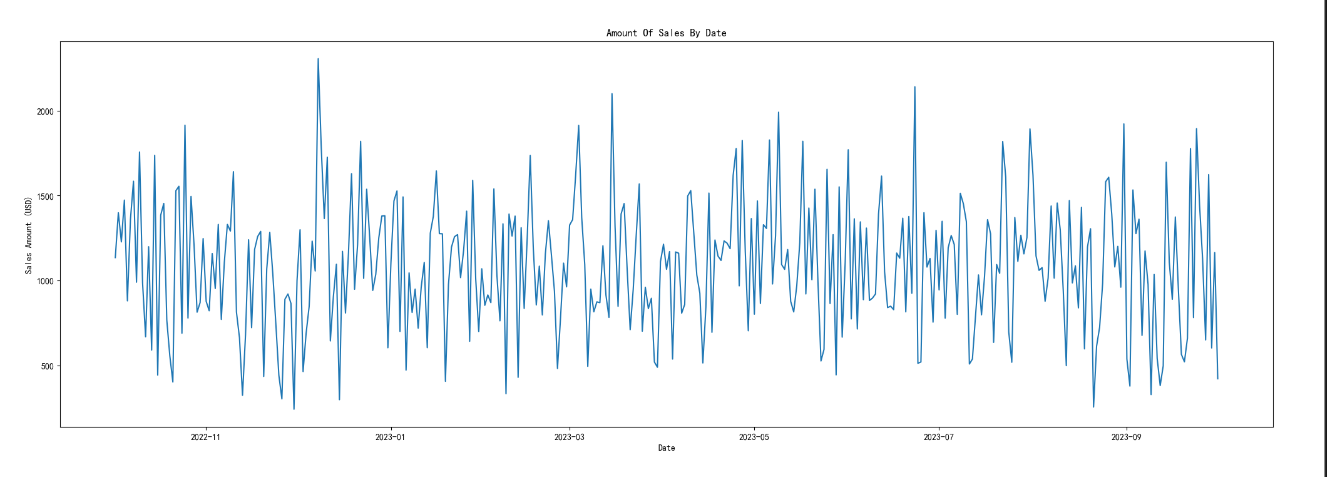
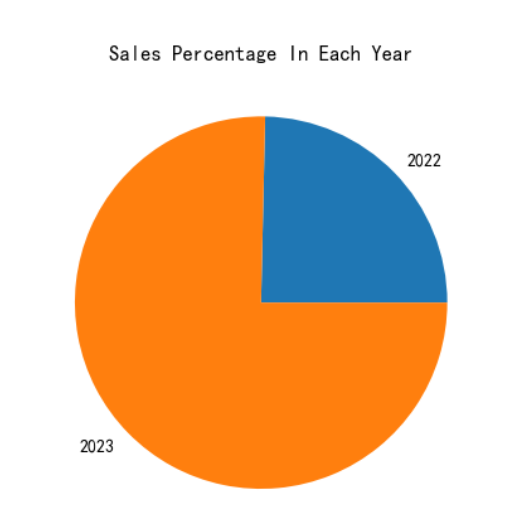
3.3 年度销售分布
df['Year'] = df['Date Purchase'].dt.year
yearly_sales = df.groupby('Year')['Purchase Amount (USD)'].sum()
plt.pie(yearly_sales, labels=yearly_sales.index)
plt.title('Sales Percentage In Each Year')
plt.show()
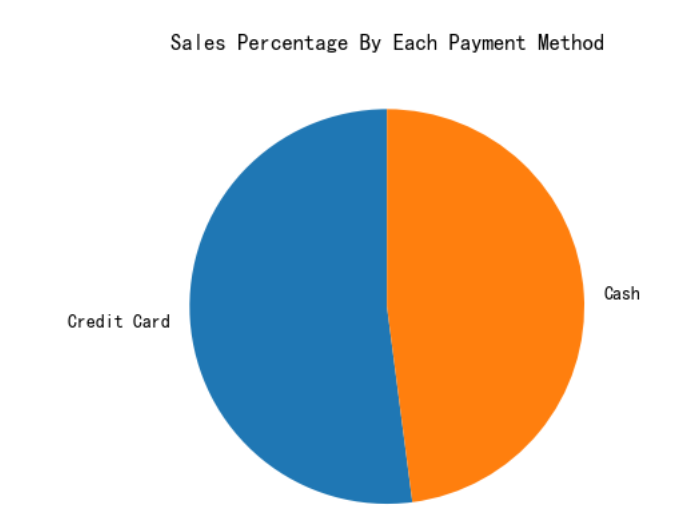
3.4 支付方式分析
plt.pie(df['Payment Method'].value_counts().values, labels=df['Payment Method'].unique(),startangle=90)
plt.title('Sales Percentage By Each Payment Method')
plt.show()
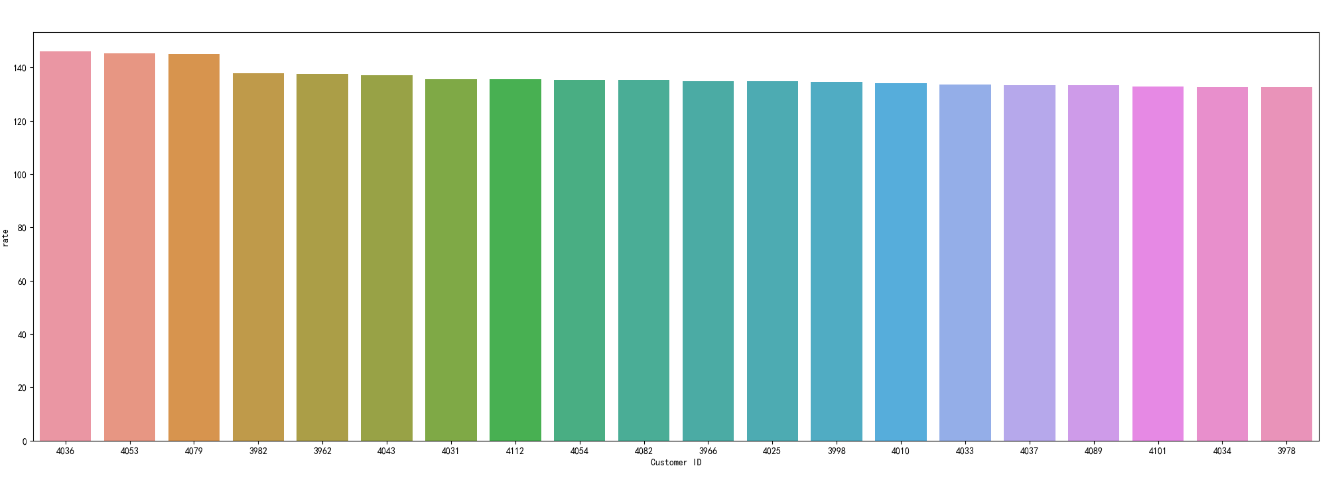
3.5 平均单笔消费最高的用户分析
samples = []
for customer in df['Customer Reference ID'].unique():temp_df = df[df['Customer Reference ID'] == customer]samples.append((customer, temp_df['Purchase Amount (USD)'].sum(), len(temp_df)))samples = pd.DataFrame(samples, columns=['Customer ID', 'Overall amount of purchases (USD)', 'Number of purchases'])
samples = samples.sort_values(by='Overall amount of purchases (USD)', ascending=False).reset_index(drop=True)
samples['rate'] = samples['Overall amount of purchases (USD)'] / samples['Number of purchases']
samples = samples.sort_values(by='rate',ascending=False).reset_index(drop=True)
samples['Customer ID'] = samples['Customer ID'].map(str)plt.figure(figsize=(25, 8))
sns.barplot(data=samples[:20],x='Customer ID',y='rate')
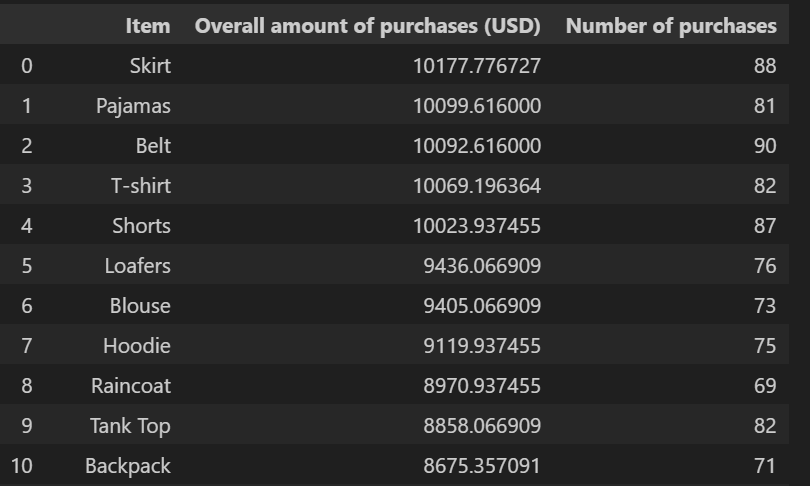
3.6 热门商品分析
Pur_df = []
for item in df['Item Purchased'].unique():temp_df = df[df['Item Purchased'] == item]Pur_df.append((item, temp_df['Purchase Amount (USD)'].sum(), len(temp_df)))Pur_df = pd.DataFrame(Pur_df, columns=['Item', 'Overall amount of purchases (USD)', 'Number of purchases'])
Pur_df = Pur_df.sort_values(by='Overall amount of purchases (USD)', ascending=False).reset_index(drop=True)
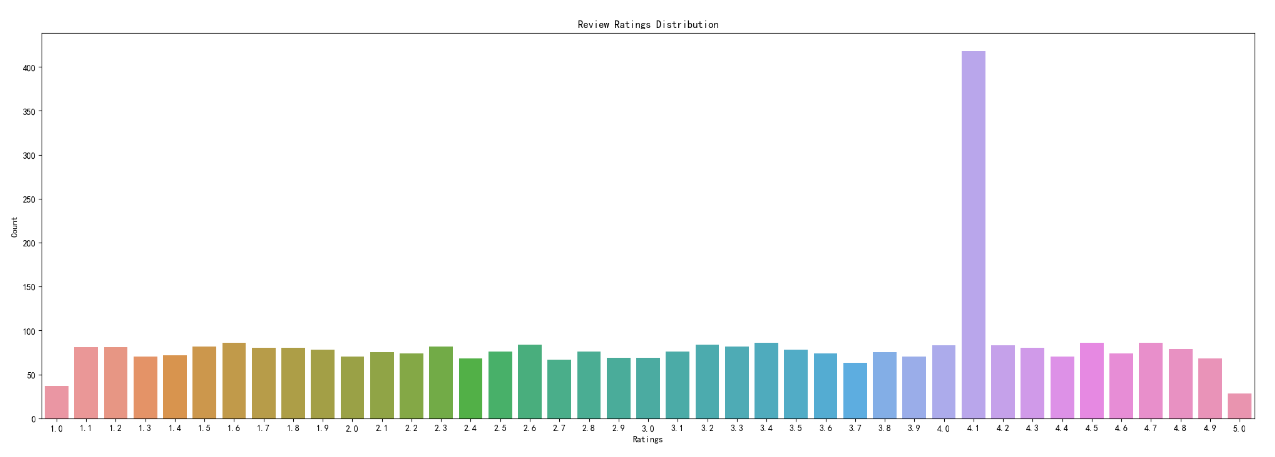
3.7 评论评分分布
rating_counts = df.groupby('Review Rating').count().reset_index()
rating_counts = rating_counts[['Review Rating','Year']]
plt.figure(figsize=(25, 8))
sns.barplot(data=rating_counts,x='Review Rating',y='Year')
plt.xlabel('Ratings')
plt.ylabel('Count')
plt.title('Review Ratings Distribution')
plt.show()
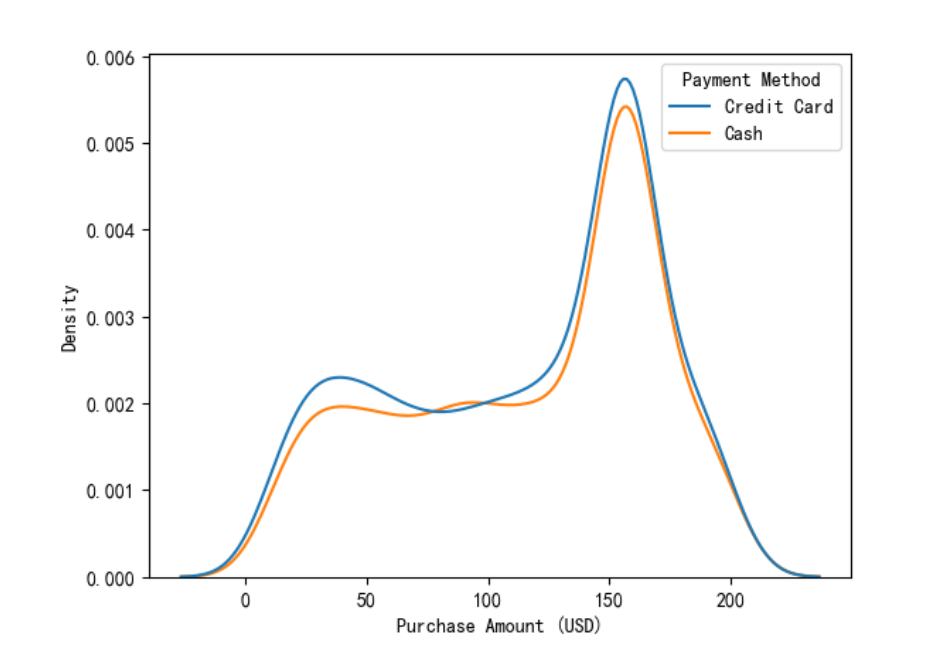
3.8 不同交付方式的销售总额分析
sns.kdeplot(data=df,x='Purchase Amount (USD)',hue='Payment Method')
四、结论
通过以上的可视化分析,我们可以得出以下结论:
- 销售总额与平均销售额:了解整体销售额和平均销售额有助于评估业务表现。
- 时间序列销售趋势:每日销售趋势可以帮助识别销售高峰和低谷。
- 年度销售分布:不同年度的销售占比揭示了业务的季节性和年度变化。
- 支付方式偏好:客户对不同支付方式的偏好影响支付策略。
- 顶级客户与热门商品:识别高价值客户和热门商品有助于制定营销策略。
- 评论评分分布:了解客户满意度和产品评价有助于改进产品质量和服务。
通过这些分析,时尚零售企业可以更好地理解市场趋势、客户行为和产品表现,从而制定更有效的商业策略,提升销售业绩和客户满意度。