VLA 论文精读(十八)π0.5: a Vision-Language-Action Model with Open-World Generalization
这篇文章是2025年发表在arxiv上的一篇VLA领域,这篇论文出来的第二天我就粗略读了一遍,但实在意犹未尽所以又写了这篇博客。这篇文章给我的震撼其实不是他们有多强泛化能力的模型,而是他们所有的机械臂构型与之前完全不一样了,Physical Intelligence 是一家打通了从硬件到算法的公司,他们与国内的银河通用、星海图等公司都有非常紧密的合作,我也是偶然才知道 Physical Intelligence 其实一直在给两家公司的本体构型提改动需求,也就是说这家公司其实摸到了正真适合VLA模型的硬件结构应该是怎样的,而其他很多模型作者只是让模型去迎合硬件。所以还是建议细读一下这篇文章,无论是从模型角度还是从本体构型出发,都可以有很大启发。
- Physical Intelligence 官网:https://www.pi.website
此外,这篇文章我认为其最大的价值在于以下几点:
- 证明了训练时与机器人无关的数据会显著影响模型的执行成功率以及泛化能力;
- 在异构训练任务上对模型进行训练,使用低级动作示例和高级语意动作进行针对性微调;
- 整个动作是分层完成的,低级动作推理高频输出动作序列,高级语意理解低频输出操作指令,但模型却是一个模型,为End-to-End提供了希望;;
之前读了很多论文其实都在想尽办法去增加机器人遥操作数据集,努力去触碰大模型的Scaling Laws,但这篇文章至少证明了在他们任务配置下那些看上去不相关的数据会对模型有很大的帮助。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLN, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:π0.5: a Vision-Language-Action Model with Open-World Generalization
- 原文链接: https://arxiv.org/abs/2504.16054
- 发表时间:2025年04月22日
- 发表平台:arxiv
- 预印版本号:[v1] Tue, 22 Apr 2025 17:31:29 UTC (14,770 KB)
- 作者团队:Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren, Lucy Xiaoyang Shi, Laura Smith, Jost Tobias Springenberg, Kyle Stachowicz, James Tanner, Quan Vuong, Homer Walke, Anna Walling, Haohuan Wang, Lili Yu, Ury Zhilinsky
- 院校机构:
- Physical Intelligence;
- 项目链接: https://pi.website/blog/pi05
- GitHub仓库: 【暂无】
Abstract
为了使机器人发挥作用,它们必须在实验室之外的现实世界中执行实际相关的任务。虽然VLA在端到端机器人控制方面已展现出令人印象深刻的效果,但此类模型在实际应用中的泛化能力仍是一个悬而未决的问题。作者在本文推出了一个基于 π0 的新模型 π0.5,它利用异构任务的协同训练来实现广泛的泛化。π0.5 使用来自多个机器人、高级语义预测、网络数据、其他来源的数据,以实现广泛泛化的现实世界机器人操作。系统结合了协同训练和混合多模态示例,这些示例结合了图像观察、语言命令、物体检测、语义子任务预测、低级动作。实验表明,这种知识迁移对于有效的泛化至关重要,并且首次证明,一个支持端到端学习的机器人系统可以在全新的家庭环境中执行长视野和灵巧的操作技能,例如清洁厨房或卧室。
1. Introduction
开放世界泛化是物理智能领域最大的开放性问题之一:机械臂、类人机器人、自动驾驶汽车等具身系统只有能够走出实验室,应对现实世界中发生的各种情况和意外事件时,才能真正发挥作用。基于学习的系统为实现广泛的泛化提供了一条途径,尤其是最近的进展,使得从自然语言处理到计算机视觉等领域的可扩展学习系统成为可能。然而,机器人在现实世界中可能遇到的情境千差万别,这不仅仅需要规模:设计能够提供广泛知识的训练方案,使机器人能够在多个抽象层次上进行泛化。例如,如果要求移动机器人清理它从未见过的厨房,如果数据中有足够的场景和物体(例如拿起刀或盘子)。其中一些行为很容易推广,而其他行为可能需要调整或修改现有模式才能以新的方式或顺序使用它们;还有一些行为可能需要基于先验知识理解场景的语义(例如,打开哪个抽屉,或者柜台上哪个物体最有可能是晾衣架)。如何为机器人学习系统构建训练方案,以实现这种灵活的推广是一个问题。
一个人可以利用一生的经验来总结每个挑战的适当解决方案。并非所有这些经验都是第一手的,也并非所有经验都来自死记硬背,例如,结合他人告知或从书中读到的事实、在不同情境中执行的其他任务中获得的启发、目标领域的直接经验。类似地假设可泛化的机器人学习系统必须能够从各种信息源迁移经验和知识。其中一些来源是与手头任务直接相关的第一手经验,一些需要从其他机器人实施例、环境或领域迁移,还有一些代表完全不同的数据类型,例如口头指令、基于网络数据的感知任务或高级语义命令的预测。虽然这些不同数据源的异质性带来了重大障碍,但幸运的是VLA的最新进展为提供了可以实现这一目标的工具包:通过将不同的模态放入相同的序列建模框架中,VLA 可以适应对机器人数据、语言数据、计算机视觉任务以及上述内容的组合进行训练。
本文利用上面的理念为 VLA 设计了一个协同训练框架,该框架可以利用异构和多样化的知识源来实现广泛的泛化。在 π 0 \pi_{0} π0 VLA 的基础上,纳入一系列不同的数据源来创建 π 0.5 \pi_{0.5} π0.5 模型(“pi oh five”),该模型可以控制移动机械手执行各种家务,即使在训练期间从未见过的家庭中也可以执行。 π 0.5 \pi_{0.5} π0.5 借鉴了多方面的经验:除了在各种真实家庭中使用移动机械手直接收集的中等规模数据集(约 400 小时)之外, π 0.5 \pi_{0.5} π0.5 还使用来自其他非移动机器人的数据、在实验室条件下收集的相关任务数据、需要根据对机器人的观察预测“高级”语义任务的训练示例、人类监督者向机器人提供的口头语言指令、从网络数据创建的各种多模态示例,如图像字幕、问答和对象定位(见Fig.1)。提供给 π 0.5 \pi_{0.5} π0.5 的绝大多数训练样本(第一阶段为 97.6%)并非来自执行家务的移动机械手,而是来自其他来源,例如其他机器人或网络数据。尽管如此 π 0.5 \pi_{0.5} π0.5 仍然能够控制训练期间未曾见过的全新房屋中的移动机械手,执行诸如挂毛巾或铺床等复杂任务,并且能够执行长达 10 到 15 分钟的长距离操控技能,仅基于高级指令就能清洁整个厨房或卧室。

π 0.5 \pi_{0.5} π0.5 的设计遵循简单的分层架构:首先在异构混合训练任务上对模型进行预训练,然后使用低级动作示例和高级“语义”动作对其进行微调以专门针对移动操作,这对应于预测子任务标签,例如“拿起砧板”或“重新摆放枕头”。运行时在推理的每个步骤中,模型首先预测语义子任务,根据任务结构和场景语义推断下一步适合执行的行为,然后根据该子任务预测低级机器人动作块。这种简单的架构既提供了推理长远多阶段任务的能力,也提供了利用两个层次的不同知识来源的能力:低级动作推理程序很容易受益于其他机器人收集的动作数据,包括其他环境中更简单的静态机器人,而高级推理程序受益于来自网络的语义示例、高级注释预测,甚至人类“监督者”向机器人提供的口头命令,这些命令引导机器人逐步完成复杂的任务,指导它(就像他们指导人的方式一样)执行适当的子任务以完成复杂的任务,例如打扫房间Fig.1。
作者的核心贡献在于构建了一个用于训练高度泛化的 VLA 模型 π 0.5 \pi_{0.5} π0.5 的系统,并提出了一个概念证明:当使用适当多样化的数据进行训练时,该模型能够实现泛化。对 π 0.5 \pi_{0.5} π0.5 的泛化能力以及不同协同训练要素的相关性进行了详细的实证评估。据作者所知这是首个端到端学习型机器人系统,该系统能够在全新住家庭环境中执行长视域和灵巧的操作技能,例如清洁厨房或卧室。实验进一步表明,这可以通过从其他机器人迁移知识、高级语义预测、来自人类监督者的口头语言指导、网络数据和其他来源来实现。
2. Related Work
Generalist robot manipulation policies
近期研究表明,将机器人操作策略的训练数据分布从狭窄的单任务数据集拓展到涵盖众多场景和任务的多样化数据集,不仅可以使生成的策略开箱即用地解决更广泛的任务,还能提升其泛化到新场景和任务的能力。训练此类泛化策略需要新的建模方法,以应对通常涵盖数百个不同任务和场景的数据集的规模和多样性。VLA 提供了一个颇具吸引力的解决方案:通过对用于机器人控制的预训练VL 模型进行微调,VLA 可以利用从网络规模预训练中获得的语义知识,并将其应用于机器人问题。当与高表达力的动作解码机制(例如流匹配、扩散或高级动作标记方案)结合使用时,VLA 可以在现实世界中执行各种复杂的操作任务。然而,尽管 VLA 拥有令人印象深刻的语言跟随能力,但其评估环境通常仍与其训练数据高度匹配。虽然一些研究表明,只需在更广泛的环境中收集机器人数据,就能将拾取物体或打开抽屉等简单技能推广到实际场景中,但将相同方法应用于更复杂、更长期的任务(如清理厨房)却极具挑战性,因为通过强行扩展机器人数据采集来广泛覆盖所有可能场景是不可行的。作者在全新场景的实验中(例如训练中未曾见过的新厨房和卧室)评估了 π 0.5 \pi_{0.5} π0.5,结果表明,VLA 不仅可以利用目标移动机械手平台上的直接第一手经验,还可以利用来自其他数据源的信息,从而推广到全新场景。这些数据源包括来自其他(非移动)机器人的数据、高级语义子任务预测以及来自网络的数据。
Non-robot data co-training
此前已有多项研究尝试利用多样化的非机器人数据来提升机器人策略的泛化能力。先前的方法包括利用计算机视觉数据集初始化视觉编码器,或利用现成的任务规划器。VLA 策略通常基于预训练的视觉语言模型进行初始化,该模型已接触过大量互联网视觉和语言数据。值得注意的是,VLA 架构灵活,支持在多模态视觉、语言和动作 token 输入输出序列之间进行映射。因此,VLA 支持在机器人动作模仿数据上协同训练单一统一的架构(允许包含一种或多种模态),从而拓宽了迁移方法的设计空间,使其超越简单的权重初始化。先前的研究已经证明,使用用于 VLM 训练的混合数据协同训练 VLA 可以提升其泛化能力,例如在与新物体或未见过的场景交互时。本文作者超越了 VLM 数据协同训练设计了一个系统,用于协同训练 VLA 和更广泛机器人相关的监督数据源,这些监督源包括来自其他机器人的数据、高级语义子任务预测和口头语言指令。虽然多任务训练和协同训练并非新概念,但作者证明了系统中特定的数据源组合,能够使移动机器人在全新环境中执行复杂且长远的行为。作者认为这种泛化水平,尤其是在考虑到任务复杂性的情况下,远远超越了先前研究的结果。
Robot reasoning and planning with language
许多先前的研究表明,用高级推理增强端到端策略可显著提升长期任务的性能,尤其是当高级子任务推理可以从大型预训练的 LLM 和 VLM 中受益时。作者的方法也使用两阶段推理程序,首先推断一个高级语义子任务(例如,“拿起盘子”),然后基于该子任务预测动作。许多先前的方法为此采用了两个独立的模型,其中一个 VLM 预测语义步骤,另一个独立的低级策略执行这些步骤。作者的方法对高级和低级推理使用完全相同的模型,其原理更类似于思路链或测试时计算方法,但与具体化的思路链方法不同,高级推理过程的运行频率仍低于低级动作推理。
Robotic learning systems with open-world generalization
虽然大多数机器人学习系统都是在与训练数据高度匹配的环境中进行评估的,但之前已有不少研究探索了更广泛的开放世界泛化能力。当机器人的任务局限于一组较为狭窄的基本原语(例如拾取物体)时,一些允许特定任务假设的方法(例如,抓取预测或结合基于模型的规划和控制)已被证明能够实现广泛的泛化,甚至扩展到全新的家庭环境。然而,此类方法并不容易推广可能需要执行的所有任务的通用机器人。最近,跨多个领域收集的大规模数据集已被证明能够将简单但端到端学习到的任务泛化到新环境。然而,这些演示中的任务仍然相对简单,通常耗时不到一分钟,而且成功率通常相对较低。作者实验证明, π 0.5 \pi_{0.5} π0.5 可以执行长时间、多阶段的任务,例如将所有碗碟放入水槽,或从新卧室的地板上捡起所有衣物,同时可以推广到全新的房屋。
3. Preliminaries
VLA 通常通过在不同机器人演示数据集 D D D 上进行模仿学习来训练,方法是在给定观察 o t o_{t} ot 和自然语言任务指令 l l l 的情况下最大化动作 a t a_{t} at (或动作块 a t : t + H a_{t:t+H} at:t+H) 的对数似然: max θ E ( a t : t + H , o t , l ) ∼ D log π θ ( a t : t + H ∣ o t , l ) \max_{\theta}E_{(a_{t:t+H},o_{t},l)\sim D}\log{\pi_{\theta}(a_{t:t+H}|o_{t},l)} maxθE(at:t+H,ot,l)∼Dlogπθ(at:t+H∣ot,l)。观察通常包含一个或多个图像 I t 1 , … , I t n I^{1}_{t},\dots,I^{n}_{t} It1,…,Itn 和本体感受状态 q t q_{t} qt,用于捕捉机器人关节的位置。VLA 架构遵循现代语言和视觉语言模型的设计,具有特定于模态的 tokenizers,可将输入和输出映射到离散(“hard”)或连续(“soft”)token表示,以及一个大型自回归 transformer 主干,该主干经过训练可从输入映射到输出标记。这些模型的权重由预训练的 VLM 初始化。通过将策略输入和输出编码为 token 表示,将上述模仿学习问题可以转化为一个简单的下一个token预测问题,针对一系列观察、指令、动作token,可以利用现代机器学习的可扩展工具来优化它。在实践中,图像和文本输入的 tokenizers 选择遵循现代视觉语言模型的选择。对于动作,先前的研究已经开发出有效的、基于压缩的 tokenization 方法,作者在本研究的预训练期间使用了这些方法。许多最近的 VLA 模型也提出通过扩散或流匹配来表示动作分布,从而为连续值动作块提供更具表现力的表示。作者在模型后训练阶段,以 π 0 \pi_{0} π0 模型的设计为基础,该模型通过流匹配来表示动作分布。在这个设计中,与动作对应的 token 接收来自上一步流匹配去噪动作作为输入,并输出流匹配矢量场。这些 token 还使用了一组不同的模型权重称之为“动作专家” 类似于MoE。该动作专家可以专注于基于流匹配的动作生成,并且其规模可以显著小于 LLM 主干网络的其他部分。
4. The π 0.5 \pi_{0.5} π0.5 Model and Training Recipe
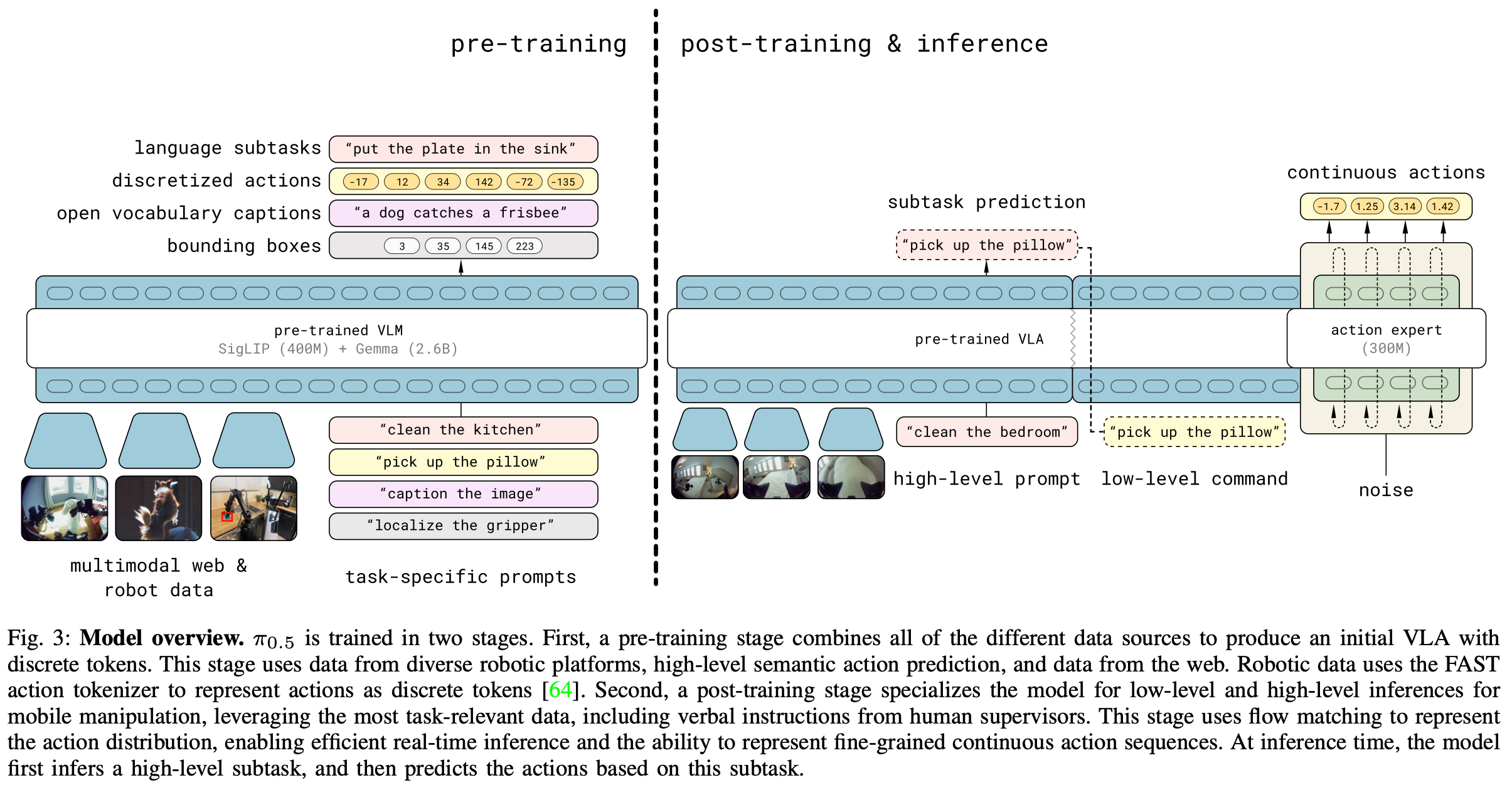
Fig.3 中概述了 π 0.5 \pi_{0.5} π0.5 模型和训练方案。模型权重由基于网络数据训练的标准 VLM 初始化,然后训练分两个阶段进行:预训练阶段旨在使模型适应不同的机器人任务;后训练阶段旨在使其专门用于移动操作并配备高效的测试时推理机制。主要有以下三个阶段:
- 预训练期间:所有任务(包括具有机器人动作的任务)都用离散的token表示,以便让训练变得简单、可扩展且高效;
- 后训练期间:像 π 0 \pi_{0} π0一样调整模型以使其也具有动作专家,以便既能以更细的粒度表示动作,又能为实时控制提供更高效的计算推理;
- 在推理时:该模型首先为机器人生成一个高级子任务,然后以此子任务为条件,通过动作专家预测低级动作;
A. The π 0.5 a r c h i t e c t r u e \pi_{0.5} architectrue π0.5architectrue
π 0.5 \pi_{0.5} π0.5 架构可以灵活地表示动作块分布和 tokenized 化文本输出,后者既可用于协同训练任务(例如问答),也可用于在分层推理过程中输出高级子任务预测。该模型捕获的分布可以表示为 π θ ( a t : t + H , h ^ ∣ o t , l ) \pi_{\theta}(a_{t:t+H},\hat{h}|o_{t},l) πθ(at:t+H,h^∣ot,l),其中 o t = [ I t 1 , … , I t n , q t ] o_{t}=[I^{1}_{t},\dots,I^{n}_{t},q_{t}] ot=[It1,…,Itn,qt] 包含所有摄像头拍摄的图像以及机器人的配置(关节角度、夹持器位姿、躯干抬升位姿、基准速度), l l l 是完整的任务提示(例如,“收拾盘子”), l ^ \hat{l} l^ 表示模型 tokenized 文本输出,可以是预测的高级子任务(例如,“拿起盘子”),也可以是网络数据中视觉语言提示的答案, a t : t : H a_{t:t:H} at:t:H 是预测的动作块。将分布分解为:
π θ ( a t : t + H , l ^ ∣ o t , l ) = π θ ( a t : t + H ∣ o t , l ^ ) π θ ( l ^ ∣ o t , l ) \pi_{\theta}(a_{t:t+H}, \hat{l}|o_{t},l)=\pi_{\theta}(a_{t:t+H}|o_{t},\hat{l})\pi_{\theta}(\hat{l}|o_{t},l) πθ(at:t+H,l^∣ot,l)=πθ(at:t+H∣ot,l^)πθ(l^∣ot,l)
动作分布仅依赖于 l ^ \hat{l} l^ 而不是 l l l,高层次的推理结果 π θ ( l ^ ∣ o t , l ) \pi_{\theta}(\hat{l}|o_{t},l) πθ(l^∣ot,l),低层次的推理结果 π θ ( a t : t + H ∣ o t , l ^ ) \pi_{\theta}(a_{t:t+H}|o_{t},\hat{l}) πθ(at:t+H∣ot,l^) 两个分布都来源于同一个模型;
该模型相当于一个transformer,接收 N N N 个模态的输入token x 1 : N x_{1:N} x1:N 包含离散和连续输入,产出一个多么台输出 y 1 : N y_{1:N} y1:N 表示为 y 1 : N = f ( x 1 : N , A ( x 1 : N ) , ρ ( x 1 : N ) ) y_{1:N}=f(x_{1:N},A(x_{1:N}),\rho(x_{1:N})) y1:N=f(x1:N,A(x1:N),ρ(x1:N))。每个输入 x i x_{i} xi 可以是一个文本token ( x i w ∈ N ) (x^{w}_{i}\in N) (xiw∈N)、一个图像path ( x i I ∈ R p × p × 3 ) (x^{I}_{i}\in R^{p\times p\times3}) (xiI∈Rp×p×3),或者降噪后的流匹配 ( x i a ∈ R d ) (x^{a}_{i}\in R^{d}) (xia∈Rd),观测值 o t o_{t} ot 和语言指令 l l l 构成了前缀部分 x 1 : N x_{1:N} x1:N。根据token类型 ρ ( x i ) \rho(x_{i}) ρ(xi),每个 token 不仅可以由不同的编码器处理,还可以由 Transformer 内的不同专家权重处理。例如,图像块通过视觉编码器输入,文本标记嵌入到嵌入矩阵中。模仿 π 0 \pi_{0} π0 将动作tokens x i a x_{i}^{a} xia线性投影到 Transformer 嵌入空间,并使用 Transformer 中单独的专家权重来处理动作标记。矩阵 A ( x 1 : H ) ∈ [ 0 , 1 ] N × N A(x_{1:H})\in [0,1]^{N\times N} A(x1:H)∈[0,1]N×N 表示一个token 是否可以 attend 到一个token上。与 LLM 中的标准因果注意相比,图像块、文本提示、连续动作token使用双向注意。
由于希望模型能够输出文本(用于回答关于场景的问题或输出接下来要完成的任务)和动作(在现实世界中采取行动),因此 f f f 的输出被拆分为文本token对数和动作输出token,表示为 ( y 1 : M l , y 1 : H a ) (y^{l}_{1:M},y^{a}_{1:H}) (y1:Ml,y1:Ha)。前 M M M 个 token 对应于可用于采样 l ^ \hat{l} l^ 的文本token对数;后 H H H 个token由单独的动作专家生成。在 π 0 \pi_{0} π0 中通过线性映射投影到用于获得 a t : t + H a_{t:t+H} at:t+H 的连续输出。上面 M + H ≤ N M + H ≤ N M+H≤N ,即并非所有输出都与损失相关。机器人本体感受状态被离散化,并作为文本token输入到模型中。有关该架构的更多详细信息,请参见Appendix. E。
B. Combining discrete & continuous action representations
与 π 0 \pi_{0} π0 类似,在模型中使用 flow-matching 来预测连续动作。给定 a t : t + H τ , ω = τ a t : t + H + ( 1 − τ ) ω , ω ∼ N ( 0 , I ) , τ ∈ [ 0 , 1 ] a^{\tau,\omega}_{t:t+H}=\tau a_{t:t+H}+(1-\tau)\omega, \omega\sim N(0, I), \tau\in[0,1] at:t+Hτ,ω=τat:t+H+(1−τ)ω,ω∼N(0,I),τ∈[0,1] 作为流匹配时间索引。然而,当动作用离散token表示时VLA 训练速度会更快,尤其是在使用能够有效压缩动作块的token化方案如 FAST的情况下。但这种离散表示不太适合实时推理,因为需要耗时的自回归解码才能进行推理。因此,理想的模型设计应该基于离散化动作进行训练,但仍允许使用流匹配在推理时生成连续动作。
因此,作者的模型通过对token进行自回归采样(使用 FAST 的tokenizer)和对流场进行迭代积分来训练以预测动作,从而结合两者的优势。使用注意力矩阵来确保不同的动作表示不会相互干扰。优化模型最小化合并损失。
E D , τ , ω [ H ( x 1 : M , f θ l ( o t , l ) ) ] + α ∥ ω − a t : t + H − f θ a ( a t : t + H τ , ω , o t , l ) ∥ E_{D,\tau,\omega}[H(x_{1:M},f^{l}_{\theta}(o_{t},l))] + \alpha \|\omega-a_{t:t+H}-f^{a}_{\theta}(a^{\tau,\omega}_{t:t+H},o_{t},l)\| ED,τ,ω[H(x1:M,fθl(ot,l))]+α∥ω−at:t+H−fθa(at:t+Hτ,ω,ot,l)∥
其中 H ( x 1 : M , y 1 : M l ) H(x_{1:M},y^{l}_{1:M}) H(x1:M,y1:Ml) 是文本token和逻辑预测的交叉熵损失,包含 FAST 编码的动作token; y 1 : H a = f θ a ( a θ τ , ω , o t , l ) y^{a}_{1:H}=f^{a}_{\theta}(a^{\tau,\omega}_{\theta},o_{t},l) y1:Ha=fθa(aθτ,ω,ot,l)是专家输出的动作; α ∈ R \alpha\in R α∈R是权重参数。此方案使模型能够首先通过将动作映射到文本token ( α = 0 \alpha = 0 α=0) 将模型预训练为标准 VLM Transformer,然后以非自回归的方式添加额外的动作专家权重,用于预测连续动作token,以便在训练后阶段进行快速推理。作者发现遵循此过程 可使 VLA 模型获得稳定的预训练效果和出色的语言跟踪能力。在推理时,对文本token l ^ \hat{l} l^ 使用标准自回归解码,然后以文本token为条件进行 10 个去噪步骤生成 a t : t + H a_{t:t+H} at:t+H处的动作。
C. Pre-training
在第一个训练阶段, π 0.5 \pi_{0.5} π0.5 使用大量的机器人和非机器人数据进行训练如 Fig.4。将其训练为标准自回归transformer,执行文本、对象位置、FAST 编码动作token的下一个标记预测。

Diverse Mobile Manipulator data (MM)
使用约 400 小时的移动机械手数据,这些机械手在约 100 个不同的家庭环境中执行家务,其中一些环境如 Fig.7 所示,使用了第 IV-E 节中的机器人。这部分训练集与评估任务直接相关,评估任务包括在未见过的家庭环境中执行类似的清洁和整理任务。
Diverse Multi-Environment non-mobile robot data (ME)
作者还采集了非移动机器人的数据,包含单臂和双臂,在各种家居环境中运行。这些机器臂固定在平台上,重量轻且易于运输,因此能够利用它们在更广泛的家庭环境中采集更多样化的数据集。然而,这些 ME 数据的来源与移动机器人不同。
Cross-Embodiment laboratory data (CE)
作者在实验室中收集了各种任务(例如,收拾桌子、折叠衬衫)的数据,这些任务的桌面环境较为简单,机器人类型也多种多样。其中一些任务与评估高度相关(例如,将碗碟放入容器中),而另一些例如,研磨咖啡豆则不认。这些数据涵盖了单臂和双臂、静态和移动基座。作者还纳入了开源 OXE 数据集。该数据集是\pi_{0}所用数据集的扩展版本。
High-Level subtask prediction (HL)
将“打扫卧室”等高级任务命令分解为“调整毯子”和“拿起枕头”等较短的子任务,类似于语言模型的思路链提示,可以帮助训练好的策略推理当前场景并更好地确定下一步动作。对于 MM、ME 和 CE 中的机器人数据,如果任务涉及多个子任务,则手动标注子任务的语义描述,并训练 π 0.5 \pi_{0.5} π0.5 以根据当前观察和高级命令联合预测子任务标签(以文本形式)和动作(以子任务标签为条件)。生成的模型既可以充当高级策略(输出子任务),也可以充当执行这些子任务动作的低级策略。作者还标记了当前观察中显示的相关边界框,并在预测子任务之前训练 π 0 \pi_{0} π0 来预测它们。
Multi-modal Web Data (WD)
最后,在预训练中引入了一系列丰富的网络数据,涉及图像字幕制作(CapsFusion、COCO )、问答系统(Cambrian-7M 、PixMo、VQAv2)以及物体定位。对于物体定位,作者进一步扩展了标准数据集,添加了带有边界框标注的室内场景和家居物品的网络数据。
对于所有动作数据,训练模型来预测目标关节和末端执行器的姿态。为了进行区分,在文本提示中添加了“<control_mode> joint/end effector<control_model>”作为提示词。所有动作数据均使用单个数据集中每个动作维度的1%和99%分位数归一化为[-1, 1]。将动作 a a a 的维数设置为固定值,以适应所有数据集中最大的动作空间。对于低维配置和动作空间的机器人,对动作向量进行零填充。
D. Post-training
在使用离散token对模型进行 28 万个梯度步长的预训练后,进行第二阶段的训练。此阶段的目的是使模型针对case(家庭中的移动设备操作)进行专业化,并添加一个能够通过流匹配生成连续动作块的动作专家。此阶段与下一个token预测联合训练,以保留文本预测能力,并为动作专家进行流匹配(在后训练开始时使用随机权重初始化)。优化了公式 (1) 中的目标函数令 α = 10.0 \alpha = 10.0 α=10.0,并额外训练了 8 万个梯度步长。后训练动作数据集包含 MM 和 ME 机器人数据,筛选出长度低于固定阈值的成功片段。加入网络数据 (WD) 以保留模型的语义和视觉能力,以及与多环境数据集对应的 HL 数据切片。为了提升模型预测合适高级子任务的能力,作者采集了口头指令演示 (verbal instruction, VI),这些演示由专家用户构建提供“语言演示”,选择合适的子任务命令,逐步指挥机器人执行移动操作任务。这些示例是通过实时遥操作机器人并使用语言执行已学习的低级策略来采集的,本质上是为已训练策略提供良好的高级子任务输出演示。
E. Robot system details
Fig.5 展示了在移动操作实验中使用的机器人构型。这里使用两种的移动操作器完成了所有实验。两个平台都配备了两个 6 DoF 臂、带有平行钳口夹持器、腕式单目 RGB 摄像头、一个轮式完整基座、一个躯干升降机构。基座的状态和动作空间对应于线性(2D)和角(1D)速度,躯干升降机构是 1D(上/下)或 2D(上/下和前后)。除了两个腕式摄像头之外,机器人还在手臂之间安装了前后摄像头。将所有四个摄像头用于高级推理,将腕式摄像头和前置摄像头用于低级推理过程。状态和动作空间的总维数为 18 或 19,具体取决于平台。

控制系统非常简单: π 0 \pi_{0} π0 模型直接控制手臂、夹持器、躯干升降的目标姿态,以及 50 Hz(带动作分块)的目标基准速度。这些目标通过简单的 PD 控制器进行跟踪,无需任何额外的轨迹规划或碰撞检测,所有操作和导航控制均为端到端。
5. Experimental Evaluation
π 0.5 \pi_{0.5} π0.5 模型旨在广泛推广到新环境。虽然在与训练数据in-domain的环境中评估 VLA 很常见,但作者所有实验均在训练中未曾见过的新环境中进行。为了进行定量比较,使用一组仿真家庭环境来提供可控且可重复的配置,而真机评估则在三个不属于训练集的真实家庭中进行(见Fig.6)。实验重点关注以下问题:
- π 0.5 \pi_{0.5} π0.5 能否有效地推广到全新住宅中的复杂多阶段任务;
- π 0.5 \pi_{0.5} π0.5 的泛化如何随着训练数据中不同环境的数量而变化;
- π 0.5 \pi_{0.5} π0.5 训练混合物中的各个共同训练成分对其最终表现有何贡献;
- π 0.5 \pi_{0.5} π0.5 与 π 0 \pi_{0} π0 VLA 相比如何;
- π 0.5 \pi_{0.5} π0.5 的高级推理分量有多重要,它与低级推理以及 oracle 高级基线相比如何?

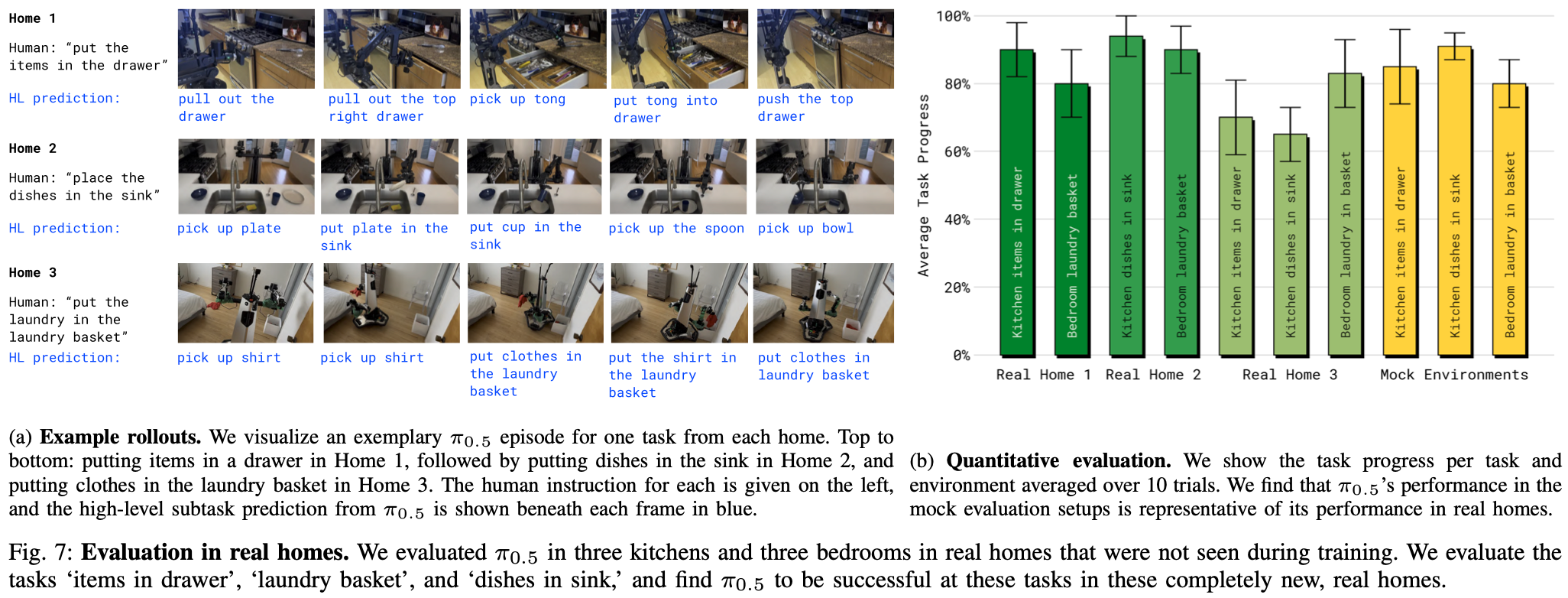
A. Can π 0.5 \pi_{0.5} π0.5 generalize to real homes?
为了回答问题 (1),作者在三个训练集中未包含的真实家庭中,使用两种类型的机器人对 π 0.5 \pi_{0.5} π0.5 进行了评估。在每个家庭中,机器人都被指示执行卧室和厨房的清洁任务。每个任务的评估标准在Appendix. B 中提供,大致对应于每个任务中成功完成的步骤百分比(例如,将一半的盘子放入水槽中相当于 50% 左右)。Fig.7 中的结果表明, π 0.5 \pi_{0.5} π0.5 能够在每个家庭中持续成功完成各种任务(模型能够执行比定量评估中使用的更多任务)。许多任务涉及多个阶段(例如,移动多个物体)持续约 2 至 5 分钟。对于这些试验,为模型提供了一个简单的高级命令(例如,“将盘子放入水槽”),高级推理过程自主确定适当的步骤(例如,“拿起杯子”)。这种泛化水平大大超出了先前的VLA所展示的结果,无论是在模型必须处理的新颖程度方面,还是在任务持续时间和复杂性方面。
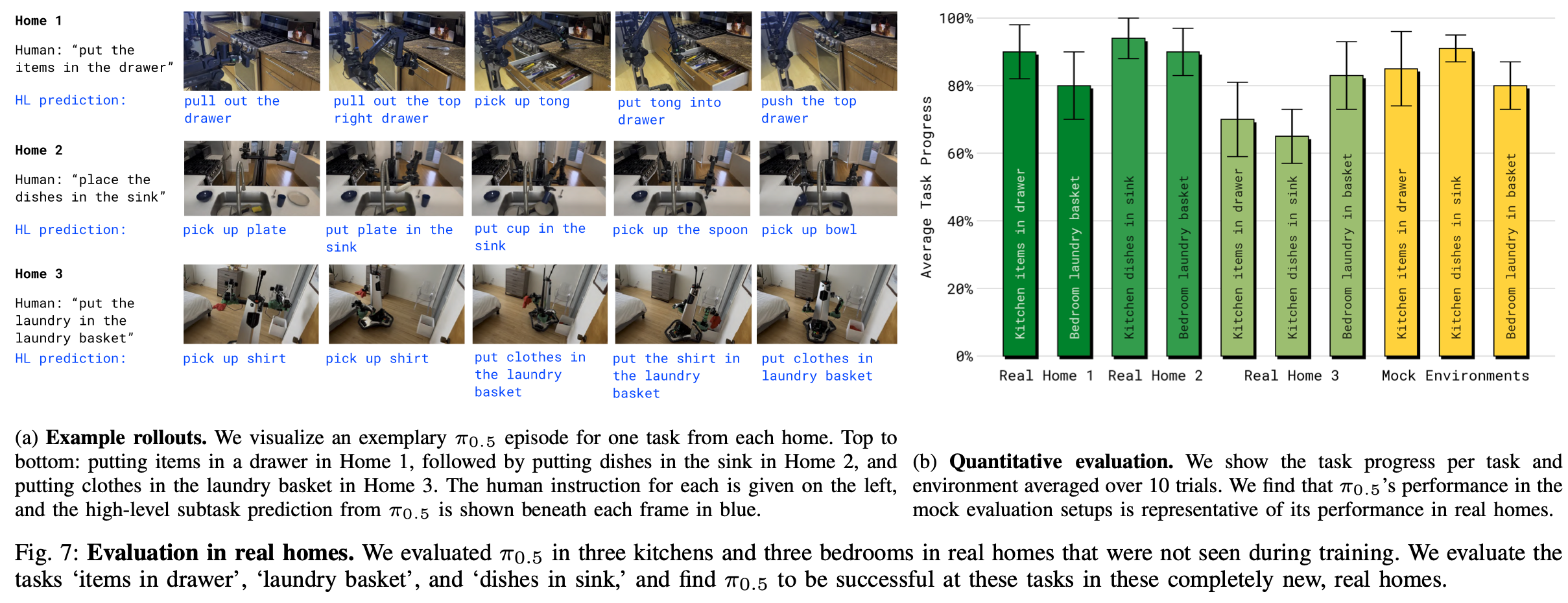
B. How does generalization scale with the number of scenes?
下一组实验旨在测量泛化能力如何随着训练数据中环境数量的变化而变化。改变移动设备操作数据中的环境数量,并通过使用 3、12、22、53、82、104 个位置数据进行训练来测量其对泛化能力的影响。由于将整个训练前后方案应用于每个数据集会占用过多的计算资源,因此对于这些实验,会在不包含移动设备操作数据的混合机器人动作预测数据上进行预训练,然后与在包含来自不同数量环境的移动设备操作数据的数据集上进行后训练的模型进行比较。虽然按位置划分的数据集在大小上有所不同,但训练步数(40k)使得每个模型都能看到相同数量的唯一数据样本,使得能够在训练后实验中改变使用的位置数量时控制数据集大小。
每个模型都在Fig.6 所示的仿真环境中进行评估,这些环境在训练中是未见过的。首先,为了评估多阶段任务的整体表现,使用Appendix. B 中的标准评分标准和仿真房屋来评估每个模型在将碗碟放入水槽、将物品装入抽屉、收拾好衣物、铺床方面的端到端性能。其次,对每个模型遵循语言指令和与新物体交互的能力进行更细粒度的评估,机器人必须根据语言命令从厨房台面上拿起特定的物体。实验既使用了与训练数据中相似类别的分布内对象(但这些对象是新实例),也使用了来自未知类别的分布外对象。后者需要广泛的语义泛化能力。

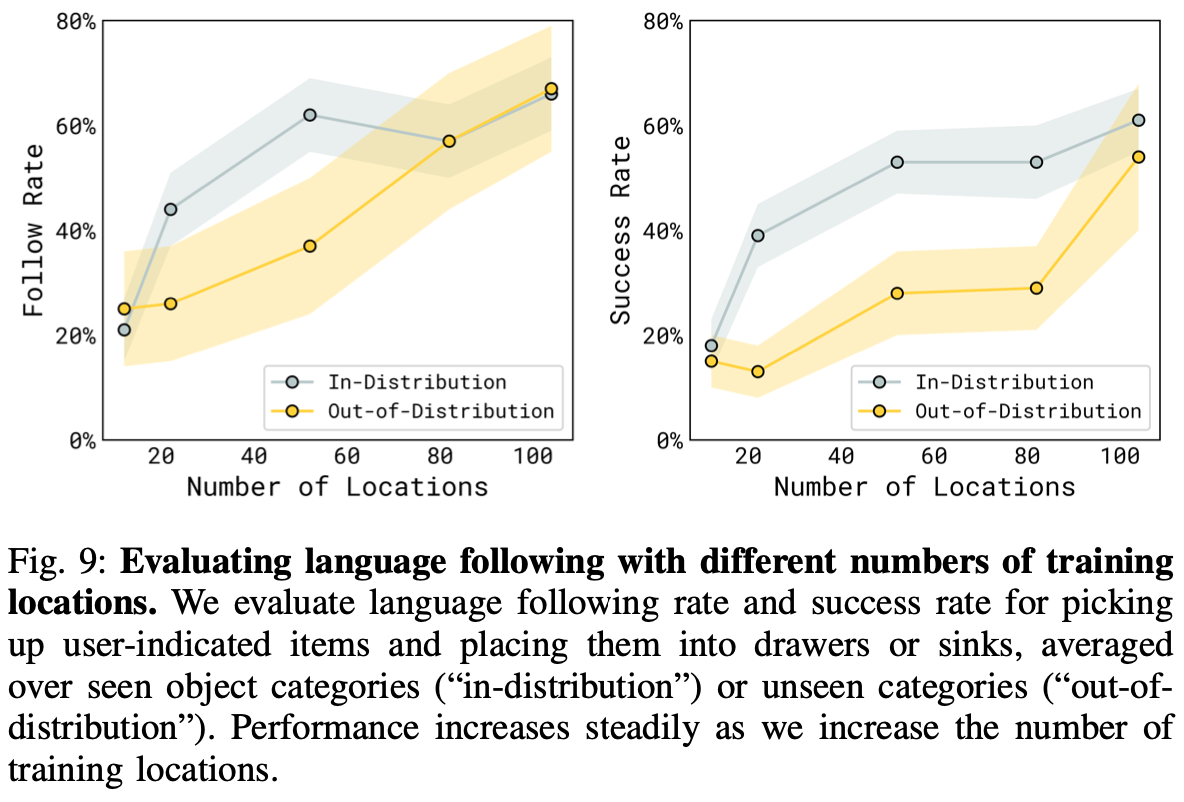
第一个实验的结果如Fig.8所示。训练位置越多各项任务的平均性能通常就越高。为了量化最终模型(包含 104 个位置)在多大程度上弥补了泛化方面的差距,作者添加了一个对照模型(显示为绿色),该模型直接使用来自测试家庭的数据进行训练。对照模型达到了与最终的 104 个位置模型相似的性能,这表明协同训练方案有效地实现了泛化,达到了与在测试环境中训练的模型相似的性能。为了确认这种泛化性能需要完整的协同训练方案,作者另外添加了两个baseline,在预训练阶段不使用任何其他协同训练任务,而是直接使用来自测试环境的数据(浅绿色)或来自 104 个训练位置的移动设备操作数据(浅黄色)进行训练。这两个baseline的性能都明显较差,表明即使策略已经使用了来自测试家庭的机器人数据,完整训练方案所利用的其他数据源对于良好的泛化也至关重要。当不使用来自测试家庭的数据时,使用作者的配置进行预训练尤为重要,如Fig.8中绿色条和浅黄色条之间的较大间隙所示。
第二个实验(语言跟踪)的结果如Fig.9 所示,它衡量机器人选择语言命令中指示的物体的频率,以及成功率,它衡量机器人成功将物体放置在正确位置(抽屉内或水槽内,取决于测试场景)的频率。分别测量在训练见过相同类型但新的物体实例、未见过的物体类别性能。该实验的细节在Appendix. C中展示和讨论。Fig.9 显示随着训练数据中位置数量的增加,语言跟踪性能和成功率都会提高。分布内物体的性能比分布外物体的性能提高得更快。随着每个新环境引入新的家居用品,该模型通常会变得更加健壮,并开始推广到训练数据中不存在的任务类别。
C. How important is each part of our co-training recipe?
为了研究问题 (3),将完整的 π 0.5 \pi_{0.5} π0.5模型与其他训练混合模型进行比较,以研究每个混合成分的重要性,同样使用仿真家庭中的端到端任务表现、第 V-B 节中描述的语言跟踪评估。完整方案使用来自多环境中的移动机械手 (MM)、多环境中的静态机械手 (ME) 的数据、在实验室环境中采集的各种跨体现数据 (CE)、高级语言命令对应子命令 (HL) 预测数据、有字幕的VQA以及对象定位任务 (WD) 的网络数据。训练后使用口头指示数据 (VI)进行测试。在这些实验中消融了混合物的不同部分:
- 无 WD:此消融不包括网络数据;
- 无 ME:此消融不包括多环境非移动数据;
- 无 CE:此消融排除了实验室跨实施例数据;
- 无 ME 或 CE:此消融排除了来自其他机器人的两个数据源,因此该模型仅基于来自目标移动机械手平台的数据以及网络数据进行训练;
完整仿真家庭任务的结果如Fig.10 所示(每项任务的详细表现细分见Appendix. D)。从结果中看到,排除两个跨具身数据源(ME 和 CE)中的任何一个都会显著降低表现,这表明 π 0 \pi_{0} π0 从跨具身迁移中获益良多,无论是来自其他环境(ME)还是其他任务(CE),排除这两个来源对表现的损害更大。在本实验中,没有 WD 消融的情况下的表现差异在统计学上并不显著,稍后会表明网络数据对语言跟随(下文)和高级子任务推理(第 V-E 节)有很大影响。
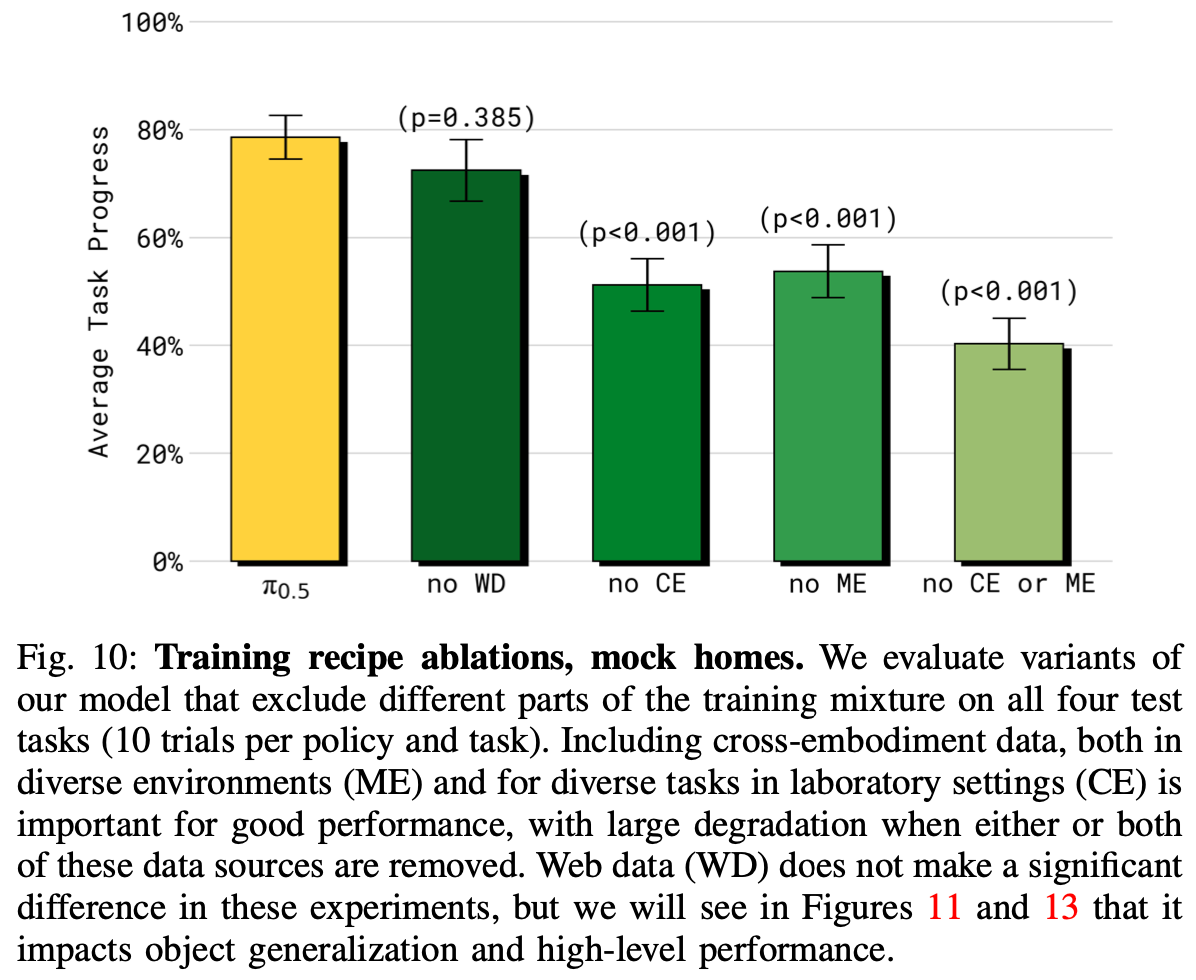
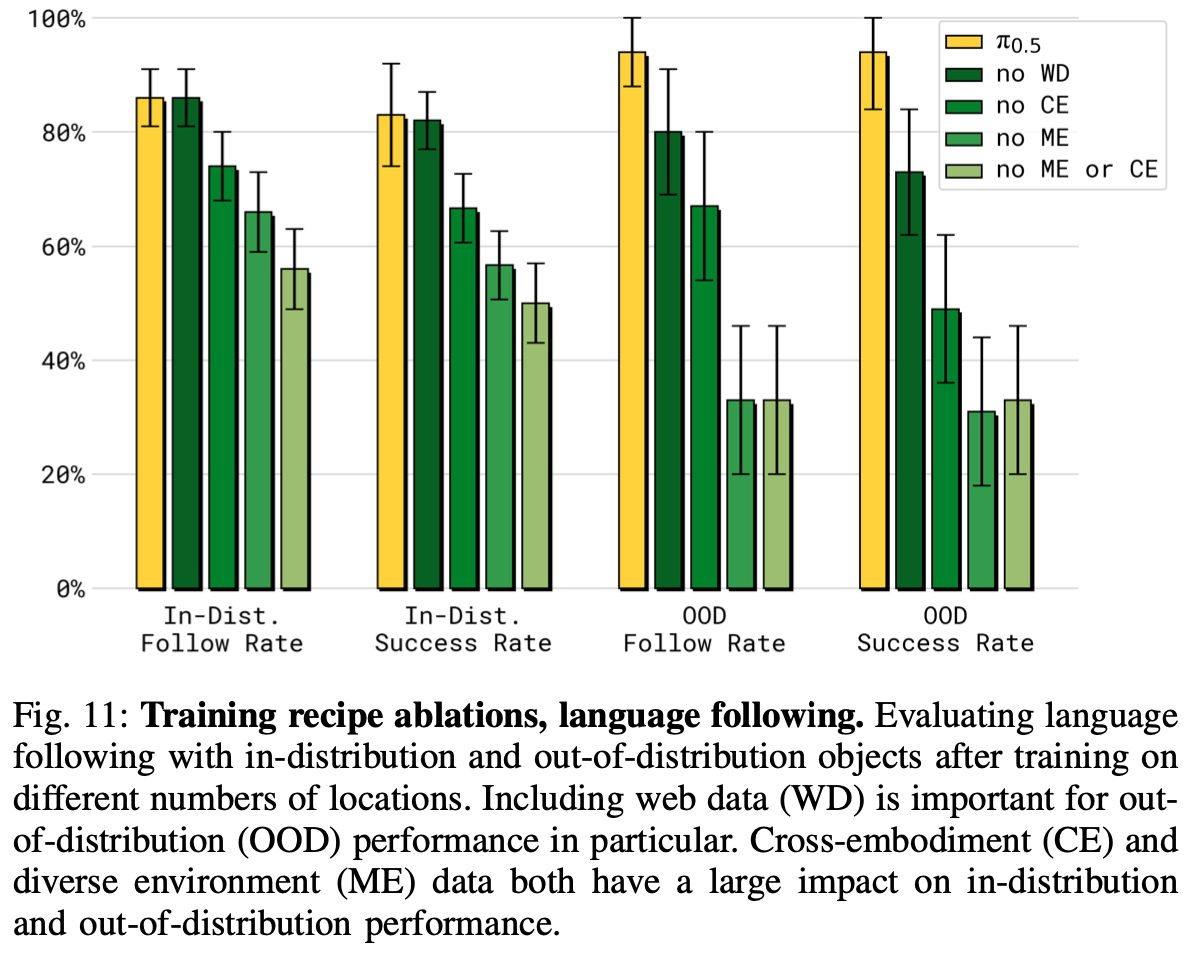
Fig.11 所示的语言跟踪实验结果与Fig.10呈现出类似的趋势:排除 ME 或/和 CE 数据会导致性能显著下降。不同之处在于删除网页数据(无 WD)会导致分布外 (OOD) 对象的性能显著下降。作者推测,使用包含非常广泛的物理对象知识的网页数据进行训练,可以让模型理解并遵循涉及未知对象类别的语言命令。
D. How does π 0.5 \pi_{0.5} π0.5 compare to other VLAs?
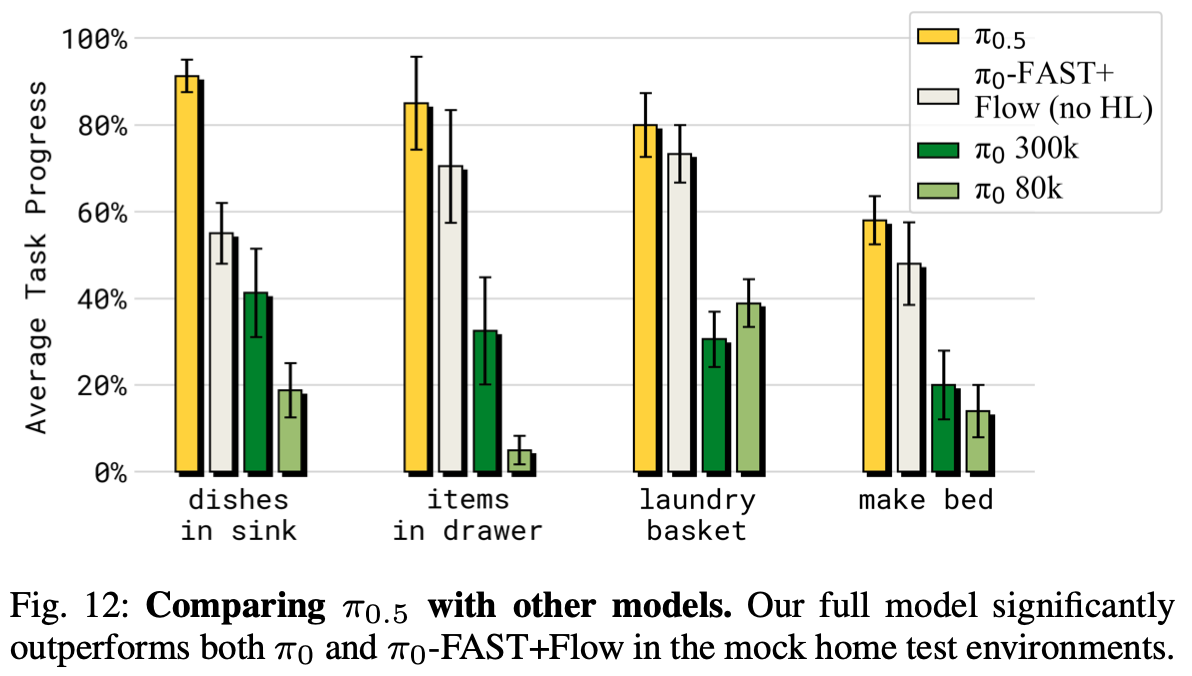
将 π 0.5 \pi_{0.5} π0.5 与原始 π 0 \pi_{0} π0 VLA 以及 π 0 \pi_{0} π0 的改进版本 π 0 -FAST+Flow \pi_{0}\text{-FAST+Flow} π0-FAST+Flow 进行比较。此版本通过Equation. 1 中的联合扩散和 FAST 动作预测公式进行训练,但仅使用动作数据,没有 HL 或 WD 数据集。这些模型提供了强有力的对比依据,因为 π 0 \pi_{0} π0 已被证明在复杂和灵巧的移动操作任务上表现强劲,并且 π 0 -FAST+Flow \pi_{0}\text{-FAST+Flow} π0-FAST+Flow 的增强使其尽可能接近 π 0.5 \pi_{0.5} π0.5。 π 0.5 \pi_{0.5} π0.5 在这些模型的基础上结合了共同训练任务。为了进行公平的比较,所有模型都接受相同的跨实施例机器人训练集,并进行相当数量的步数的训练。区别在于:
- π 0.5 \pi_{0.5} π0.5 还使用 HL 和 WD 数据;
- π 0.5 \pi_{0.5} π0.5 采用混合训练程序,在训练前阶段使用离散 tokenizer 训练,在训练后阶段仅使用流匹配动作专家进行训练,而 π 0 \pi_{0} π0 始终使用动作专家。
- π 0 -FAST+Flow \pi_{0}\text{-FAST+Flow} π0-FAST+Flow 遵循混合训练方案,但仅使用包含机器人动作的数据进行训练,因此无法执行高级推理。
Fig.12 中的结果表明, π 0.5 \pi_{0.5} π0.5 明显优于 π 0 \pi_{0} π0 和我们的增强版。即使我们允许对 π 0 \pi_{0} π0 进行长达 300k 个训练步的更长时间训练,这个结果仍然成立,这证实了与 Pertsch 等人一样,使用 FAST token进行训练在计算方面比纯基于扩散的训练更有效。
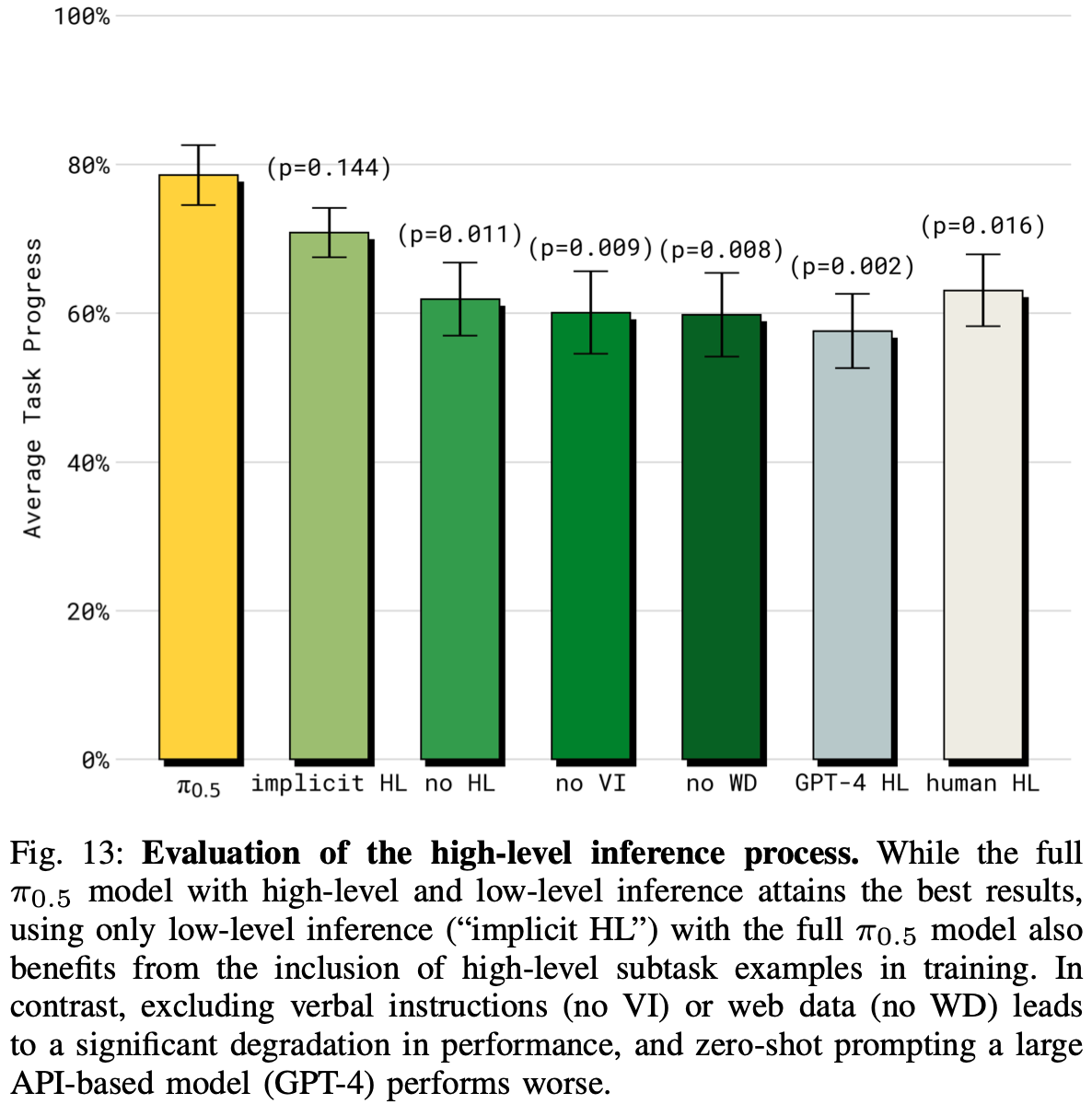
E. How important is high-level inference?
最后评估了高级推理的重要性,并比较了几种替代高级推理方法的性能。 π 0.5 \pi_{0.5} π0.5 中的高级推理机制接收高级命令(例如“打扫卧室”),并输出需要完成的子任务(例如“捡起枕头”),然后将其用作推断低级动作的上下文,类似于CoT。虽然 π 0.5 \pi_{0.5} π0.5 采用统一的架构,同一模型同时执行高级和低级推理,但也可以用于构建基线方法,这些方法要么放弃高级推理过程,将任务提示直接输入低级系统;要么使用另一个模型进行高级推理,以消除不同数据集组件对高级策略的影响的重要性。按照以下方法和消融,它们均使用具有不同高级策略的完整 π 0.5 \pi_{0.5} π0.5 低级推理过程:
- π 0.5 \pi_{0.5} π0.5 模型用于高级和低级推理;
- 无 WD: π 0.5 \pi_{0.5} π0.5 排除网络数据;
- 无 VI: π 0.5 \pi_{0.5} π0.5 排除口头指令 (VI) 数据;
- 隐式 HL:运行时没有高级推理,但在训练中包含高级数据,这可以隐式地向模型传授有关子任务的知识;
- 没有 HL:没有高级推理,并且根本没有训练中的高级数据;
- GPT-4:使用 GPT-4 作为高级策略,评估在机器人数据上训练高级策略的重要性。为了使模型与任务领域保持一致,作者向 GPT-4 提供了任务描述以及一个最常用的标签列表以供选择(prompt工程);
- 人类 HL:使用人类专家作为高级策略,为性能提供上限;
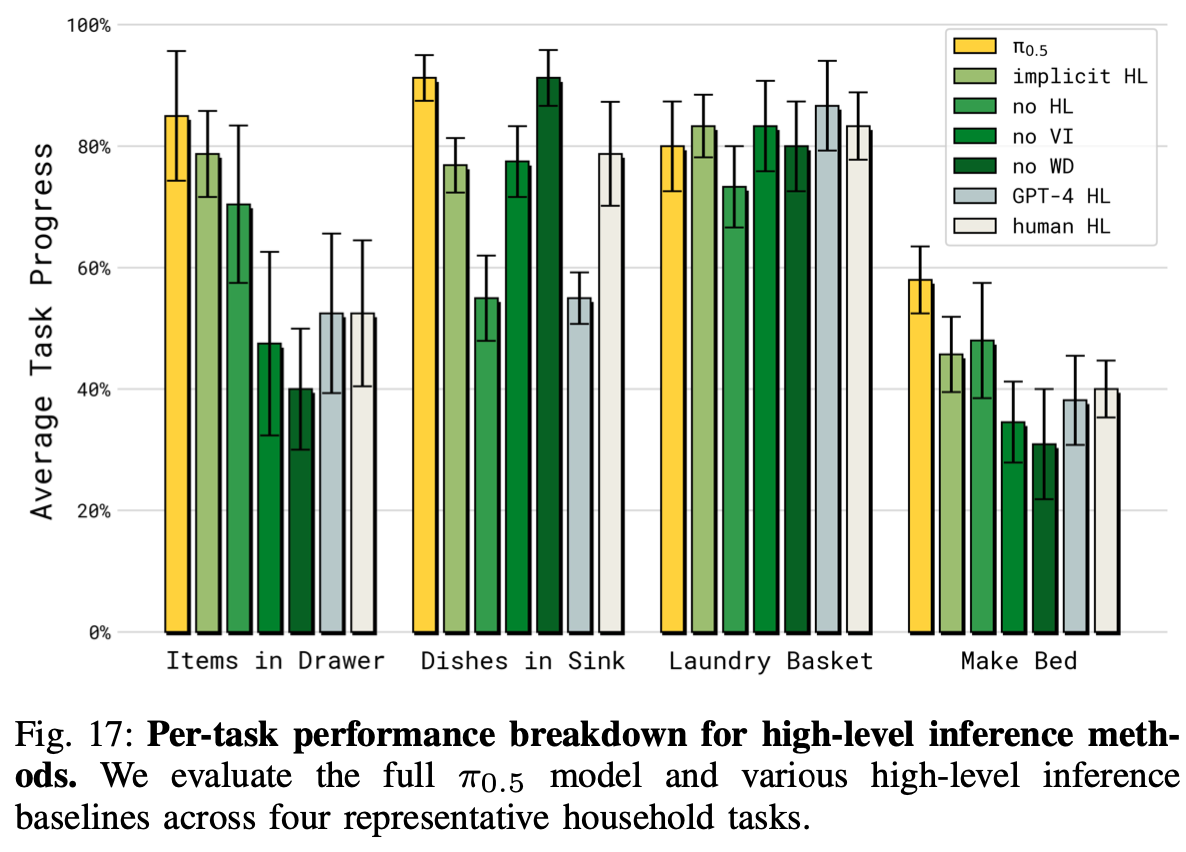
这些实验的结果如Fig.13 所示。完整的 π 0.5 \pi_{0.5} π0.5 模型表现最佳,甚至优于人类 HL“oracle”基线。意外的是,第二好的模型是隐式 HL 消融,不执行任何高级推理,但在训练中包含完整的数据混合(即子任务预测),这证明了作者模型使用的协同训练方法的重要性:虽然显式推断高级子任务是有好处的,但只需在训练数据中混入包含子任务预测数据,就能让模型获得能力;无 HL 消融,即使在训练中也不包括 HL 任务表现也明显较差。结果还表明,相对较小的口头指令数据集(仅占高级移动操作示例的 11% 左右)对于强劲的表现至关重要,因为无 VI 消融明显表现较差;无 WD 消融的效果也明显更差,这表明网络数据的信息用在了调教高层策略。最后,zero-shot 的 GPT-4 消融的性能最差,这表明使用机器人数据调整 VLM 的重要性。Appendix. D 和 Fig.17 中提供了每项任务的详细性能细分。
| Fig.13 | Fig.17 |
|---|---|
 |  |
6. Discussion And Future Work
作者推出了 π 0.5 \pi_{0.5} π0.5,一个基于 π 0.5 \pi_{0.5} π0.5 VLA 的协同训练模型,它整合了各种数据源并能够推广到新环境。 π 0.5 \pi_{0.5} π0.5 VLA 可以控制移动机械手执行训练数据中从未见过的家庭任务,例如清洁厨房和卧室、铺床、挂毛巾以及执行其他多阶段和灵巧的行为。 π 0.5 \pi_{0.5} π0.5 基于大约 400 小时的移动操作数据进行训练,但包含来自其他机器人的大量数据,包括不同环境中的非移动机械手和在实验室条件下采集的数据。它还与来自网络的数据以及基于机器人观察输出语言命令的高级预测数据进行联合训练。 π 0.5 \pi_{0.5} π0.5 的泛化能力表明,这种协同训练方法有助于有效的迁移,仅使用中等规模的移动操作数据集即可实现对移动机械手的高度泛化控制。但 π 0.5 \pi_{0.5} π0.5 并非没有局限性:
- 虽然已经表现出广泛的泛化能力但它仍然会犯错。某些环境会任务失败(例如,不熟悉的抽屉把手,或者机器人难以打开的橱柜),某些行为会给部分可观测性带来挑战(例如,机械臂遮挡了应该擦拭的溢出物),在某些情况下,高级子任务推理很容易分散注意力(例如,在收拾物品时多次关闭和打开抽屉);
- 更好的协同训练、迁移、更大的数据集来应对这些挑战是未来工作的一个有希望的方向,他人的可以解决当前的技术限制;
- 虽然 π 0.5 \pi_{0.5} π0.5 可以执行各种行为来清洁厨房和卧室,但它处理的提示相对简单。模型所能容纳的提示复杂度取决于训练数据,未来可以通过人工标注或人工合成的方式生成更复杂、更多样化的注释,从而融入更复杂的用户偏好和指令;
- 该模型使用的语境相对有限,融入更丰富的语境和记忆可以使模型在可观测性更强的场景下表现更佳,例如需要在不同房间之间导航或记住物品存放位置的任务。更广泛地说, π 0.5 \pi_{0.5} π0.5 探索的是异构数据源的特定组合,但具体的数据源可以进行更深入的探索,例如系统能够从口头指令中学习,这提供了一种强大的新型监督模式,未来的研究可以探索这种模式以及人类为机器人提供额外语境知识的其他方式;