Wan2.1和HunyuanVideo文生视频模型算法解析与功能体验丨前沿多模态模型开发与应用实战第六期
多模态生成大模型是一类能够同时创造和合成多种数据形式的人工智能系统。这类模型基于前沿的生成式深度学习架构,不仅能理解跨模态信息,还能实现多形式内容的高质量生成与融合。近些年来,文生视频多模态大模型展现出强大的表现力,通过跨模态对齐与协同创作,可生成更丰富、连贯且符合场景逻辑的视频内容,极大拓展了创造性AI的应用边界。通过大规模Transformer架构与扩散式生成机制,这类模型实现了对视频生成质量,动态性,一致性的全面提升,广泛应用于虚拟场景合成,跨模态艺术设计、个性化内容生成等场景,为创意产业和智能化工具的发展注入全新动能。
上一期介绍了文生图的多模态扩散模型 FLUX,本期将介绍Wan2.1模型和HunyuanVideo模型,涵盖文生视频,图片生视频等方面。内容包括模型细节、训练流程、模型能力的展示,并以PaddleMIX中Wan2.1和HunyuanVideo的实现为例,对代码进行逐步解读。
wan2.1生成效果展示
HunyuanVideo生成效果展示
一、引言
自OpenAI推出Sora以来,视频生成技术引起了业界和学术界的广泛关注,推动了该领域的快速发展。能够生成与专业制作内容相媲美的视频的模型的出现,大大提高了内容创作的效率,同时降低了视频制作的成本。
HunyuanVideo是一个13B参数量的视频生成模型,模型进行了一系列针对性的设计,保证了高质量的视觉效果,运动动力学,文本-视频对齐和更好的拍摄技术。论文提出了一套完整的数据过滤,数据筛选处理的流程,生成了大量高质量的视频数据用于模型训练。评测结果显示,HunyuanVideo超越了之前最先进的模型,包括Runway Gen-3, Luma 1.6等。
Wan2.1的核心设计灵感来源于扩散变换器(DiT)与流匹配相结合的成功框架,该框架已在文本到图像(T2I)和文本到视频(T2V)任务中证明了通过扩展可实现显著的性能提升。在这一架构范式中,采用交叉注意力来嵌入文本条件,同时精心优化模型设计以确保计算效率和精确的文本可控性。为了进一步增强模型捕捉复杂动态的能力,还融入了完整的时空注意力机制。Wan2.1提供了两个功能强大的模型,即1.3B和14B参数模型,分别用于提高效率和效果。它还涵盖了多个下游应用,包括图像到视频、指令引导的视频编辑和个人视频生成,涵盖多达八个任务。同时,Wan2.1是首个能够生成中英文视觉文本的模型,显著提升了其实用价值。
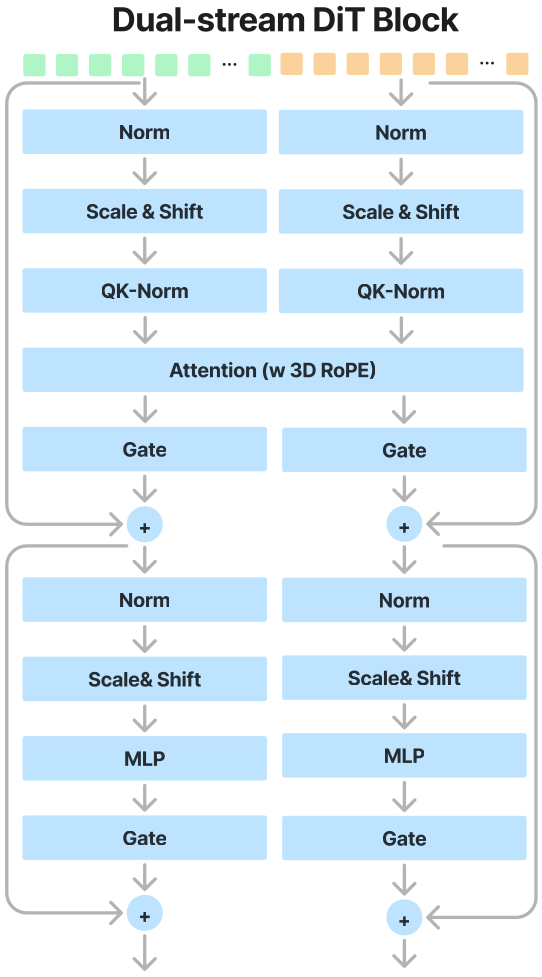
数据方面,Wan2.1和HunyuanVideo都提出了一套完整的数据筛选,过滤,处理的流程,得到了大量高质量视频数据,为模型效果提供了保障。模型方面,Wan2.1和HunyuanVideo都由Causal 3D VAE,diffusion backbone和Text Encoder共3部分组成,都对VAE部分进行了重新训练,diffusion backbone部分都使用DiT架构构建时间和空间上的注意力机制,其中HunyuanVideo的diffusion backbone部分使用了Dual-stream to Single-stream模型架构。
二、Hunyuanvideo模型介绍
2.1 Hunyuanvideo方法介绍
2.1.1 模型架构
HunyuanVideo网络架构由3部分组成如下图所示,Causal 3D VAE,Large Language Models以及diffusion backbone
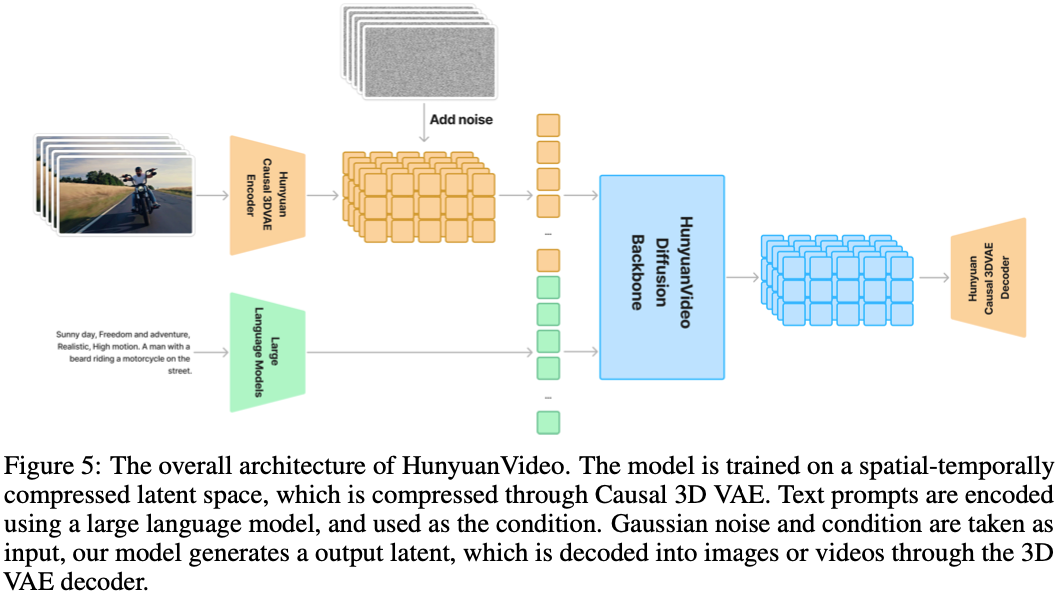
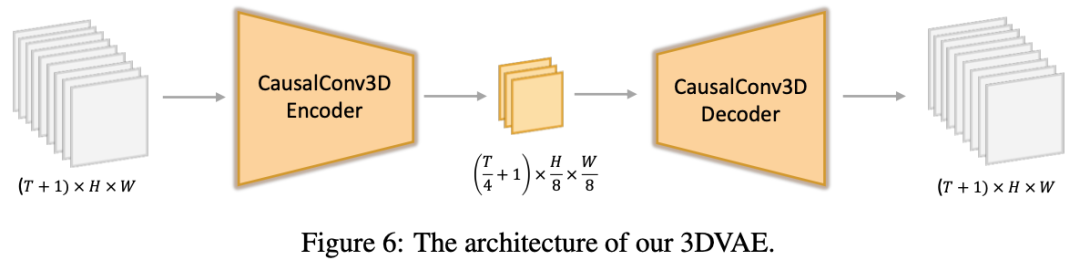
Causal 3D VAE。首先Causal 3D VAE encoder将视频和图像从pixel空间压缩到latents空间。具体来说,使用CausalConv3D将形状为 的视频数据压缩为 的latents,其中。经过VAE压缩后的视频latents形状为 ,使用卷积核为 3D convolution对视频latents进行处理,随后展平为1D向量,就得到了长度为的1维tokens。
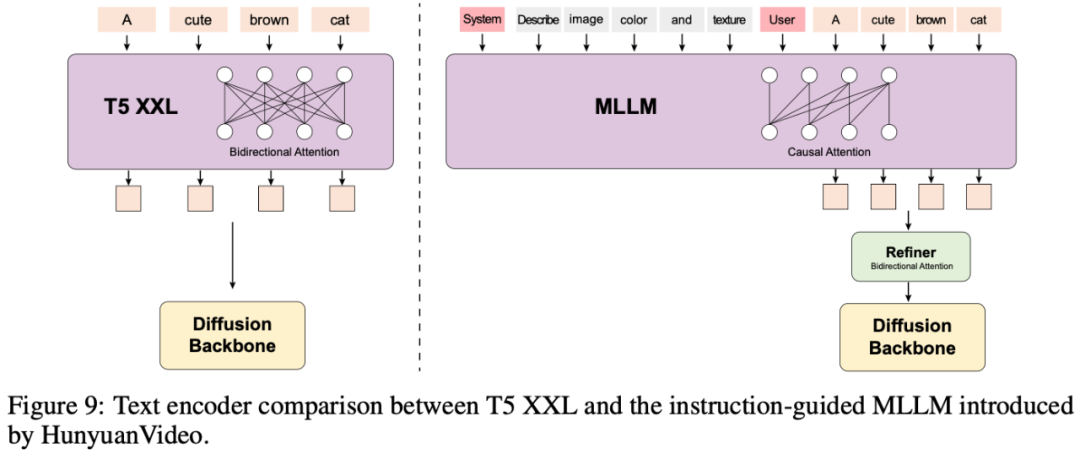
Large Language Models。prompt输入text encoder得到prompt embeddings。HunyuanVideo使用了一个预训练好的多模态大语言模型(MLLM) Llama作为text encoder,这种设计具有如下优势:(1)与T5相比,MLLM经过visual instruction finetuning后其特征空间中的图像-文本对齐更好,(2)与CLIP相比,MLLM具有更好的图像细节描述和复杂推理能力,(3)MLLM可以作为一个zero-shot learner,通过跟随用户提供的prompt,帮助文本特征更多地关注关键信息。T5-XXL使用的是bidirectional attention,MLLM使用的是causal attention,后者可以为扩散模型提供更好的文本引导。为此,HunyuanVideo引入了一个额外的bidirectional token refiner来增强文本特征。同时使用CLIP模型提取包含全局信息的pooled prompt embeddings,随后加到timestep embedding中输入到网络中。
Diffusion Backbone。为了更加高效地整合文本和图像信息,HunyuanVideo使用了Dual-stream to Single-stream模型架构。在dual-stream阶段,视频token和文本token独立地使用多个transformer blocks进行处理,更好地学习各自模态的信息。在single-stream阶段,将视频token和文本token拼接起来共同输入到transformer blocks中高效地进行多模态信息融合。为了适应不同分辨率,不同比例,不同时长的视频生成,HunyuanVideo在每个transformer block中使用Rotary Position Embedding (RoPE)。RoPE使用一个rotary frequency matrix对相对位置和绝对位置进行编码。HunyuanVideo将RoPE扩展到了3个维度,分别为时间T,高度H,宽度W,在3个维度分别计算一个rotary frequency matrix,然后将query和key的特征维度划分为3个区间,每个区间的特征乘以对应的rotary frequency matrix然后再拼接起来,这样就得到了position-aware的key和value特征。
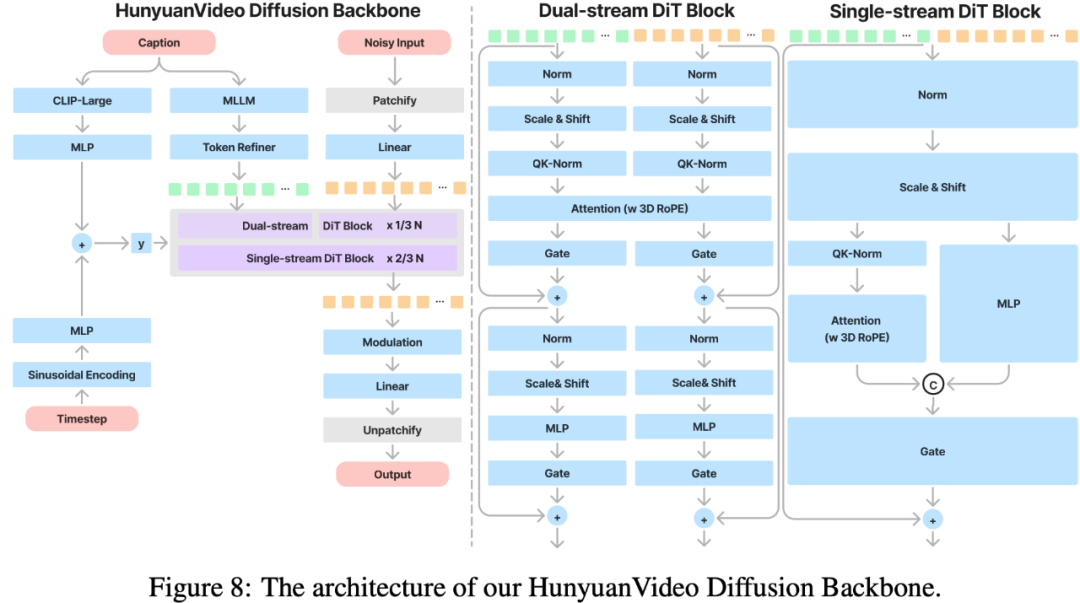
HunyuanVideo中使用了Full Attention机制,具有如下的优势:
- 相比分离的spatio-temporal attention,具有更好的效果
- 支持同时生成图像和视频,简化了模型训练过程,提升了模型的可扩展性
- 能够更加高效地使用目前LLM相关的加速技术,提升了训练和推理的效率
2.1.2 数据处理
该部分主要介绍训练数据的处理流程。
数据筛选。使用PySceneDetect将原始视频切分为视频片段,使用VideoCLIP模型计算这些视频片段的embeddings,根据embeddings过滤掉相似度高的视频片段和重采样。定义了一系列过滤器用于过滤数据,包括:美学过滤器,光流过滤器,OCR过滤器,运动过滤器等,用于筛选出美学质量高,高动态性,清晰,不包括文本和字幕的视频片段。数据过滤pipeline如下所示,总共产生了5个数据集,对应着5个训练阶段,同时视频分辨率也在逐步增加。为了在最后一个阶段提升模型性能,论文构建了一个包括1M高质量视频片段的数据集,用于微调模型。
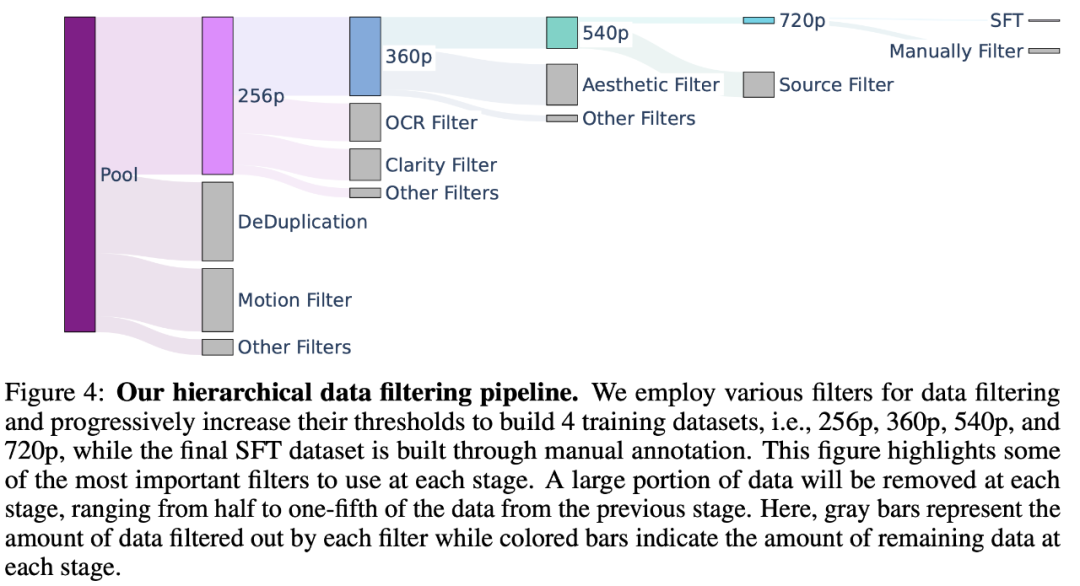
数据标注。开发了一个Vision Language Model(VLM)用于生成结构化的注释,包括:简短的描述、详细的描述、背景、风格、拍摄风格、光照、氛围。训练了一个相机运动分类器,能够预测14种不同的相机运动类型,有助于实现生成模型的摄像机移动控制能力。
2.1.3模型训练
- 图像预训练:
- 第一阶段:使用低分辨率256px图像进行预训练,同时采用多比例训练multi-aspect training,能够有助于模型生成各种比例的图像,同时可以避免在图像预处理阶段裁剪操作导致的文本-图像不对齐的问题
- 第二阶段:使用更高分辨率512px图像进行训练,为了保证低分辨率图像的生成效果,采用混合尺度训练,也即同时将256px和512px图像混合后进行训练
- 视频-图像联合训练:
- 经过处理后的视频数据有不同的比例和长度,为了更加高效地使用这些数据,根据视频长度和比例将数据划分到不同的buckets中。由于每个bucket中token的数量都不一样,为此为每个bucket分配了一个最大的批次大小,以防止训练时超出显存的问题。训练之前,所有数据都会根据视频长度和比例被分配到最近的bucket中,训练时,每个rank都会随机从一个bucket中获取一个批次的数据。这种随机选择机制可以保证模型训练的每一步都是用不同的尺寸的数据,从而提升模型的泛化能力。
- 为了生成更高质量的长视频,加快模型收敛,huyuanvideo提出了一种课程学习策略curriculum learning strategy,使用T2I模型权重进行初始化,随后逐步增加视频长度和分辨率,主要分为以下3个阶段:
·低分辨率,短视频阶段:该阶段模型能够建立文本和视觉信息之间的基本映射关系,在较短的视频中可以保证一致性和连贯性
·低分辨率,长视频阶段:该阶段模型学习更加复杂的时间动态和场景变换,能够在较长的视频中保证时间和空间的一致性
·高分辨率,长视频阶段:该阶段模型主要增强视频分辨率和细节质量 - 同时,在每个阶段会按照不同的比例将图像数据加入进来,使用图像和视频的混合数据进行训练,从而解决高质量数据数据缺失的问题,进一步提升模型生成效果
- 提示词重写:用户提供的提示词的长度和风格往往差异较大,为此论文使用Hunyuan-Large模型作为提示词重写模型,将用户提供的prompt转换为model-preferred prompt。该方法可以在无需重新训练模型的前提下,利用详细的提示词和上下文学习样例来提升生成效果,主要功能如下:
- 多语言输入适配:该模块将通过各种语言处理和理解用户的prompt,确保保留prompt的含义和上下文信息
- 提示词结构标准化:将prompt重新组织为标准的格式,类似于训练数据的captions
- 复杂术语的简化:在保留用户原始含义的前提下,将用户复杂的用词简化为更简单直接的表达
- 高性能微调:在预训练阶段使用了大量的数据进行训练,虽然这些数据足够丰富但是质量参差不齐,为此论文从这些数据中精心挑选了4个特定的子集数据,并使用这些数据对模型进行微调,从而使模型可以生成更高质量,动态性的视频结果。在该阶段会随机开启或者关闭tiling策略,保证训练阶段和推理阶段结果的一致性。
2.1.4 模型加速
推理步数减少:之前的一些工作表明,去噪过程中前期的时间步尤为重要,为此hunyuanvideo会在使用较少推理步数时使用time-step shifting,具体来说,当给定一个时间步 t 之后,会将其映射为 ,其中s表示偏移系数。当偏移系数s>1时,模型会更加依赖前期的时间步,同时论文发现越少的推理步数需要越大的偏移系数s,例如50步时s设置为7,当推理步数减少到20步时s需要增大到17.
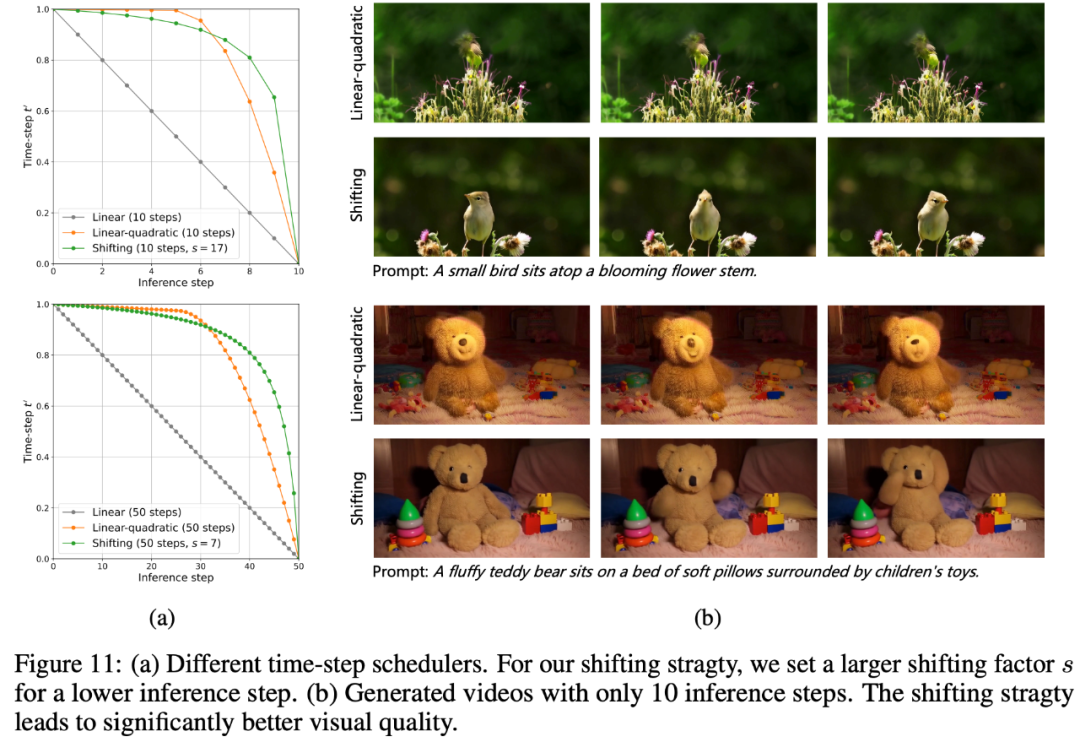
CFG蒸馏:Classifier-free guidance (CFG) 显著提升了文本引导生成模型的生成质量,但由于需要同时输入有条件输入和无条件输入,所以需要耗费更多的计算资源。为此hunyuanvideo使用了CFG蒸馏技术,具体来说,将CFG训练得到的模型视为教师模型,然后定义一个学生模型,该学生模型网络结构和初始化参数和教师模型一致,学生模型接收guidance scale作为输入参数,直接输出教师模型的CFG的结果。实验表明,CFG蒸馏后的学生模型不需要同时输入有条件输入和无条件输入,可以实现1.9倍的推理加速。
2.2 Hunyuanvideo 代码解读
2.2.1 HunyuanVideoTransformerBlock
-
类名: HunyuanVideoTransformerBlock
-
主要功能: 分两个stream对图像模态特征和文本模态特征进行计算
-
初始化参数 (init):
- num_attention_heads: attention时的head个数
- attention_head_dim: attention时特征的维度
- mlp_ratio: FFN中inner_dim扩大的比例
- qk_norm: query和key的norm方式
- 前向传播参数 (forward):
- hidden_states: paddle.Tensor 类型的输入张量,表示image embeddings
- encoder_hidden_states:paddle.Tensor 类型的输入张量,表示prompt embeddings
- temb:paddle.Tensor 类型的输入张量,表示timestep embeddings
- attention_mask:可选参数,paddle.Tensor 类型的注意力掩码,用于屏蔽不需要关注的位置。
- freqs_cis:可选参数,由paddle.Tensor组成的Tuple类型,表示图像rotary embeddings
- 前向传播 (forward):
- hidden_states输入AdaLayerNormZero,对hidden_states进行norm,shift,scale计算,并计算后续的gate,shift,scale参数
- encoder_hidden_states输入AdaLayerNormZero,对encoder_hidden_states进行norm,shift,scale计算,并计算后续的gate,shift,scale参数
- 将hidden_states和encoder_hidden_states输入Attention模块
- 对不同模态的特征分别进行gate和残差计算
- 对不同模态的特征分别进行norm,scale,shift,MLP映射,gate,残差计算
class HunyuanVideoTransformerBlock(paddle.nn.Layer):def __init__(self,num_attention_heads: int,attention_head_dim: int,mlp_ratio: float,qk_norm: str = "rms_norm",) -> None:super().__init__()hidden_size = num_attention_heads * attention_head_dimself.norm1 = AdaLayerNormZero(hidden_size)self.norm1_context = AdaLayerNormZero(hidden_size)self.attn = Attention(query_dim=hidden_size,cross_attention_dim=None,added_kv_proj_dim=hidden_size,dim_head=attention_head_dim,heads=num_attention_heads,out_dim=hidden_size,context_pre_only=False,bias=True,processor=HunyuanVideoAttnProcessor2_0(),qk_norm=qk_norm,eps=1e-06,)self.norm2 = paddle.nn.LayerNorm(normalized_shape=hidden_size,weight_attr=False,bias_attr=False,epsilon=1e-06,)self.ff = FeedForward(hidden_size, mult=mlp_ratio, activation_fn="gelu-approximate")self.norm2_context = paddle.nn.LayerNorm(normalized_shape=hidden_size,weight_attr=False,bias_attr=False,epsilon=1e-06,)self.ff_context = FeedForward(hidden_size, mult=mlp_ratio, activation_fn="gelu-approximate")def forward(self,hidden_states: paddle.Tensor,encoder_hidden_states: paddle.Tensor,temb: paddle.Tensor,attention_mask: Optional[paddle.Tensor] = None,freqs_cis: Optional[Tuple[paddle.Tensor, paddle.Tensor]] = None,) -> Tuple[paddle.Tensor, paddle.Tensor]:norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb)norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(encoder_hidden_states, emb=temb)# 2. Joint attentionattn_output, context_attn_output = self.attn(hidden_states=norm_hidden_states,encoder_hidden_states=norm_encoder_hidden_states,attention_mask=attention_mask,image_rotary_emb=freqs_cis,)# 3. Modulation and residual connectionhidden_states = hidden_states + attn_output * gate_msa.unsqueeze(axis=1)encoder_hidden_states = (encoder_hidden_states + context_attn_output * c_gate_msa.unsqueeze(axis=1))norm_hidden_states = self.norm2(hidden_states)norm_encoder_hidden_states = self.norm2_context(encoder_hidden_states)norm_hidden_states = (norm_hidden_states * (1 + scale_mlp[:, (None)]) + shift_mlp[:, (None)])norm_encoder_hidden_states = (norm_encoder_hidden_states * (1 + c_scale_mlp[:, (None)]) + c_shift_mlp[:, (None)])# 4. Feed-forwardff_output = self.ff(norm_hidden_states)context_ff_output = self.ff_context(norm_encoder_hidden_states)hidden_states = hidden_states + gate_mlp.unsqueeze(axis=1) * ff_outputencoder_hidden_states = (encoder_hidden_states + c_gate_mlp.unsqueeze(axis=1) * context_ff_output)return hidden_states, encoder_hidden_states
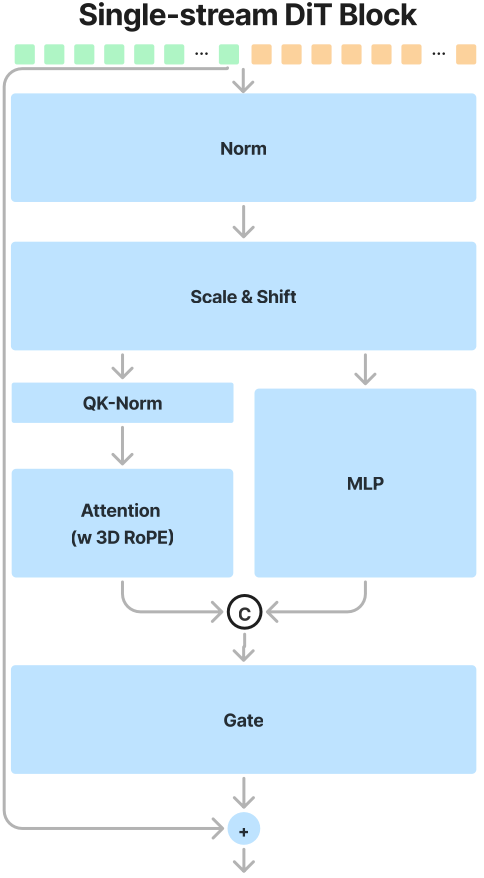
2.2.2 HunyuanVideoSingleTransformerBlock
-
类名: HunyuanVideoSingleTransformerBlock
-
主要功能: 深度融合图像和文本两种模态特征的信息
-
初始化参数 (init):
- num_attention_heads: attention时的head个数
- attention_head_dim: attention时特征的维度
- mlp_ratio: FFN中inner_dim扩大的比例
- qk_norm: query和key的norm方式
- 前向传播参数 (forward):
- hidden_states: paddle.Tensor 类型的输入张量,表示image embeddings
- encoder_hidden_states:paddle.Tensor 类型的输入张量,表示prompt embeddings
- temb:paddle.Tensor 类型的输入张量,表示timestep embeddings
- attention_mask:可选参数,paddle.Tensor 类型的注意力掩码,用于屏蔽不需要关注的位置。
- image_rotary_emb:可选参数,由paddle.Tensor组成的Tuple类型,表示图像rotary embeddings
- 前向传播 (forward):
- 将hidden_states和encoder_hidden_states,也即两种模态的特征,进行拼接,得到新的特征hidden_states
- hidden_states输入AdaLayerNormZeroSingle,对hidden_states进行norm,scale,shift计算,并计算后续的gate参数
- 将hidden_states分别输入Attention模块和MLP
- 将Attention模块输出和MLP映射后特征拼接,再进行gate,残差计算
class HunyuanVideoSingleTransformerBlock(paddle.nn.Layer):def __init__(self,num_attention_heads: int,attention_head_dim: int,mlp_ratio: float = 4.0,qk_norm: str = "rms_norm",) -> None:super().__init__()hidden_size = num_attention_heads * attention_head_dimmlp_dim = int(hidden_size * mlp_ratio)self.attn = Attention(query_dim=hidden_size,cross_attention_dim=None,dim_head=attention_head_dim,heads=num_attention_heads,out_dim=hidden_size,bias=True,processor=HunyuanVideoAttnProcessor2_0(),qk_norm=qk_norm,eps=1e-06,pre_only=True,)self.norm = AdaLayerNormZeroSingle(hidden_size, norm_type="layer_norm")self.proj_mlp = paddle.nn.Linear(in_features=hidden_size, out_features=mlp_dim)self.act_mlp = paddle.nn.GELU(approximate=True)self.proj_out = paddle.nn.Linear(in_features=hidden_size + mlp_dim, out_features=hidden_size)def forward(self,hidden_states: paddle.Tensor,encoder_hidden_states: paddle.Tensor,temb: paddle.Tensor,attention_mask: Optional[paddle.Tensor] = None,image_rotary_emb: Optional[Tuple[paddle.Tensor, paddle.Tensor]] = None,) -> paddle.Tensor:text_seq_length = tuple(encoder_hidden_states.shape)[1]hidden_states = paddle.concat(x=[hidden_states, encoder_hidden_states], axis=1)residual = hidden_states# 1. Input normalizationnorm_hidden_states, gate = self.norm(hidden_states, emb=temb)mlp_hidden_states = self.act_mlp(self.proj_mlp(norm_hidden_states))norm_hidden_states, norm_encoder_hidden_states = (norm_hidden_states[:, :-text_seq_length, :],norm_hidden_states[:, -text_seq_length:, :],)# 2. Attentionattn_output, context_attn_output = self.attn(hidden_states=norm_hidden_states,encoder_hidden_states=norm_encoder_hidden_states,attention_mask=attention_mask,image_rotary_emb=image_rotary_emb,)attn_output = paddle.concat(x=[attn_output, context_attn_output], axis=1)# 3. Modulation and residual connectionhidden_states = paddle.concat(x=[attn_output, mlp_hidden_states], axis=2)hidden_states = gate.unsqueeze(axis=1) * self.proj_out(hidden_states)hidden_states = hidden_states + residualhidden_states, encoder_hidden_states = (hidden_states[:, :-text_seq_length, :],hidden_states[:, -text_seq_length:, :],)return hidden_states, encoder_hidden_states
2.2.3 HunyuanVideoRotaryPosEmbed
-
类名: HunyuanVideoRotaryPosEmbed
-
主要功能: 生成时间、高度、宽度共3个方向的rotary position embeddings
-
初始化参数 (init):
- patch_size:int数据类型,高度和宽度方向上patch的尺寸
- patch_size_t:int数据类型,时间维度上patch的尺寸
- rope_dim:int数据类型组成的List,每个维度的位置编码的通道数
- theta:float数据类型
- 前向传播参数 (forward):
- hidden_states: paddle.Tensor 类型的输入张量,表示image embeddings
- 前向传播 (forward):
- 根据hidden_states的帧数,宽度和高度确定3个维度的位置编码尺寸
- 调用meshgrid方法生成3个维度的栅格grid
- 调用get_1d_rotary_pos_embed,输入3个维度的栅格grid,生成对应的rotary position embeddings
- 将rotary position embeddings的cos形式和sin形式矩阵分别取出,在attention时使用
class HunyuanVideoRotaryPosEmbed(paddle.nn.Layer):def __init__(self, patch_size: int, patch_size_t: int, rope_dim: List[int], theta: float = 256.0) -> None:super().__init__()self.patch_size = patch_sizeself.patch_size_t = patch_size_tself.rope_dim = rope_dimself.theta = thetadef forward(self, hidden_states: paddle.Tensor) -> paddle.Tensor:batch_size, num_channels, num_frames, height, width = tuple(hidden_states.shape)rope_sizes = [num_frames // self.patch_size_t, height // self.patch_size, width // self.patch_size]axes_grids = []for i in range(3):# Note: The following line diverges from original behaviour. We create the grid on the device, whereas# original implementation creates it on CPU and then moves it to device. This results in numerical# differences in layerwise debugging outputs, but visually it is the same.grid = paddle.arange(start=0, end=rope_sizes[i], dtype="float32")axes_grids.append(grid)grid = paddle.meshgrid(*axes_grids)grid = paddle.stack(x=grid, axis=0)freqs = []for i in range(3):freq = get_1d_rotary_pos_embed(self.rope_dim[i], grid[i].reshape([-1]), self.theta, use_real=True)freqs.append(freq)freqs_cos = paddle.concat(x=[f[0] for f in freqs], axis=1) # (W * H * T, D / 2)freqs_sin = paddle.concat(x=[f[1] for f in freqs], axis=1) # (W * H * T, D / 2)return freqs_cos, freqs_sin
2.2.4 HunyuanVideoTokenRefiner
-
类名: HunyuanVideoTokenRefiner
-
主要功能:
-
初始化参数 (init):
- in_channels:int数据类型,输入通道数
- num_attention_heads:int数据类型,attention的head数量
- attention_head_dim:int数据类型,attention的head的通道数
- num_layers:int数据类型,token_refiner的数量
- mlp_ratio:float数据类型,mlp层的通道压缩比例
- mlp_drop_rate:float数据类型,mlp中dropout的比例
- attention_bias:bool数据类型,是否开启attention bias
- 前向传播参数 (forward):
- hidden_states:paddle.Tensor数据类型,表示prompt embeddings特征
- timestep:paddle.Tensor数据类型,时间步
- attention_mask:可选参数,paddle.Tensor数据类型,attention操作的掩码
- 前向传播 (forward):
- 使用attention_mask对hidden_states信息进行压缩,得到pooled_projections
- 调用CombinedTimestepTextProjEmbeddings,将pooled_projections和timestep信息进行融合,得到temb
- 使用Linear层对hidden_states进行映射
- 对hidden_states进行self-attention操作,进一步细化hidden_states的特征
class HunyuanVideoTokenRefiner(paddle.nn.Layer):def __init__(self,in_channels: int,num_attention_heads: int,attention_head_dim: int,num_layers: int,mlp_ratio: float = 4.0,mlp_drop_rate: float = 0.0,attention_bias: bool = True,) -> None:super().__init__()hidden_size = num_attention_heads * attention_head_dimself.time_text_embed = CombinedTimestepTextProjEmbeddings(embedding_dim=hidden_size, pooled_projection_dim=in_channels)self.proj_in = paddle.nn.Linear(in_features=in_channels, out_features=hidden_size, bias_attr=True)self.token_refiner = HunyuanVideoIndividualTokenRefiner(num_attention_heads=num_attention_heads,attention_head_dim=attention_head_dim,num_layers=num_layers,mlp_width_ratio=mlp_ratio,mlp_drop_rate=mlp_drop_rate,attention_bias=attention_bias,)def forward(self,hidden_states: paddle.Tensor,timestep: paddle.Tensor,attention_mask: Optional[paddle.Tensor] = None,) -> paddle.Tensor:if attention_mask is None:pooled_projections = hidden_states.mean(axis=1)else:original_dtype = hidden_states.dtypemask_float = attention_mask.astype(dtype="float32").unsqueeze(axis=-1)pooled_projections = (hidden_states * mask_float).sum(axis=1) / mask_float.sum(axis=1)pooled_projections = pooled_projections.to(original_dtype)temb = self.time_text_embed(timestep, pooled_projections)hidden_states = self.proj_in(hidden_states)hidden_states = self.token_refiner(hidden_states, temb, attention_mask)return hidden_states
三、Wan2.1模型介绍
3.1 方法介绍
3.1.1 数据处理
高质量数据对于训练大型生成式模型至关重要,而自动化的数据构建流程能够显著提升训练过程的效率。在开发数据集时,优先考虑了三个核心原则:高质量、高多样性和大规模。遵循这些原则,策划了一个包含数十亿视频和图像的数据集。
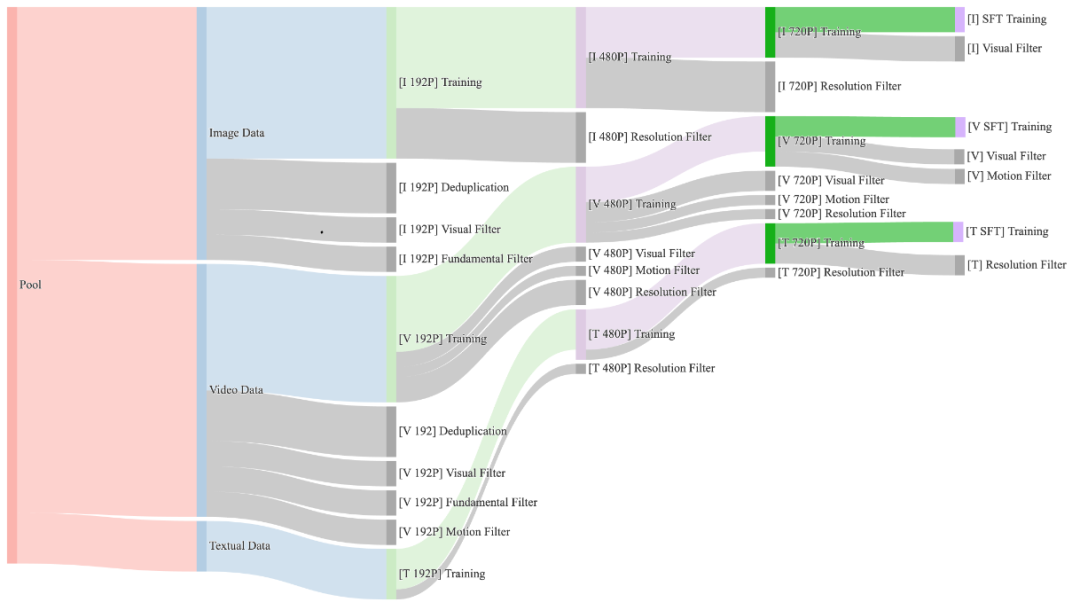
图1:不同训练阶段的数据配置。对于每个阶段,都会根据数据吞吐量动态调整与运动、质量和类别相关的数据比例。
- PRE-TRAINING DATA
从内部版权来源和可公开访问的数据中策划并整理了一份候选数据集。在预训练阶段,目标是从这个庞大而嘈杂的数据集中选择高质量和多样化的数据,以促进有效的训练。在整个数据挖掘过程中,设计了一个四步数据清洗过程,重点关注基本维度、视觉质量和运动质量。
- POST-TRAINING DATA
后训练的核心目标是通过高质量数据提高生成视频的视觉保真度和运动动态。本阶段数据处理流程对静态数据和动态数据采用不同的策略:图像数据经过优化以提高视觉质量,而视频数据则经过特殊处理以提高运动质量。
- DENSE VIDEO CAPTION
虽然数据集包含许多图像和视频的原始网页文本描述,但它们往往过于简单,无法传达详细的视觉内容。DALL-E 3已经证明,通过在高度描述性的生成视觉描述上进行训练,可以显著增强视觉生成模型遵循提示的能力。因此,开发了一个内部视频描述模型,为数据集中的每个图像和视频生成密集描述。为了训练这个模型,结合了开源视觉语言数据集和内部收集的其他数据。
- MODEL DESIGN
- Architecture.
字幕模型采用LLaVA风格的架构。使用ViT编码器提取图像和视频帧的视觉嵌入。这些嵌入通过两层感知进行投影,然后输入到Qwen LLM中。
对于图像输入,采用与LLaVA相同的动态高分辨率。图像最多可分为七个区块。对于每个区块,将视觉嵌入自适应池化为12x12网格表示,以减少计算量。
对于视频,每秒采样3帧,上限为129帧。为了进一步减少计算量,采用慢速-快速编码策略:每四帧保持原始分辨率,并对剩余帧的嵌入进行全局平均池化。对长视频基准的测试表明,慢速-快速机制可以在有限数量的视觉标记下增强理解上将性能从67.6%提高到69.1%),且无需字幕。
- Training.
遵循最新的先进技术方法,训练过程分为三个阶段。
- 在第一阶段,冻结了ViT和LLM,并且只训练多层感知器来使视觉嵌入与LLM输入空间对齐,学习率设置为1e-3。
- 在第二阶段,所有参数均可训练。
- 在最后阶段,对一组包含高质量数据的小型数据集进行端到端训练。
对于最后两个阶段,LLM和MLP的学习率设置为1e-5,ViT的学习率设置为1e-6。
3.1.2 Wan-VAE
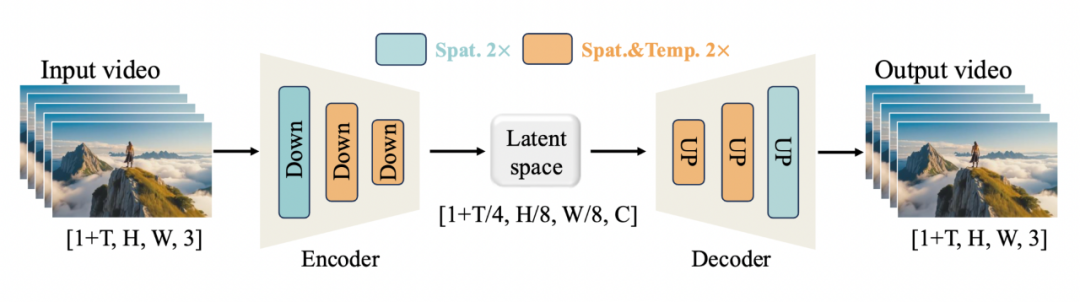
图2:Wan-VAE框架。Wan-VAE可以将视频的时空维度压缩4 × 8 × 8倍。橙色矩形代表2倍的时空压缩,绿色矩形代表2倍的空间压缩。
为实现高维 pixel space 与低维 latent space 的双向映射,Wan2.1设计了如图1所示的3D causal VAE。给定输入视频 V∈R (1+T)×H×W×3,Wan-VAE将其时空维度压缩至 [1+T/4,H/8,W/8] ,同时将channel数 C 扩展至16。具体地,首帧仅进行空间压缩(遵循MagViT-v2方法),以更好地处理图像数据。在架构层面,将所有GroupNorm层替换为RMSNorm层以保持时间因果关系。这一修改支持特征缓存机制,显著提升了推理效率。此外,在空间上采样层中将输入feature channel减半,使推理阶段内存消耗降低33%。 通过进一步仔细调整基础通道的数量,Wan-VAE实现了仅包含1.27亿个参数的紧凑模型尺寸。这一优化减少了编码时间和内存使用量,从而有利于后续扩散变换器模型的训练。
3.1.3 训练Wan-VAE
采用三阶段方法训练Wan-VAE:
-
第一阶段:构建结构与2D图像VAE相同的模型,并在图像数据上预训练。
-
第二阶段:将训练好的2D图像VAE扩展为3D因果Wan-VAE,提供初始空间压缩先验(相比从零训练视频VAE,此方法大幅提升训练速度)。此阶段使用低分辨率(128×128)、少帧数(5帧)的视频训练,以加速收敛。训练损失包括L1重建损失、KL损失和LPIPS感知损失,权重系数分别为3、3e-6和3。
-
第三阶段:在高质量视频(不同分辨率和帧数)上微调模型,并引入基于3D判别器的GAN损失。
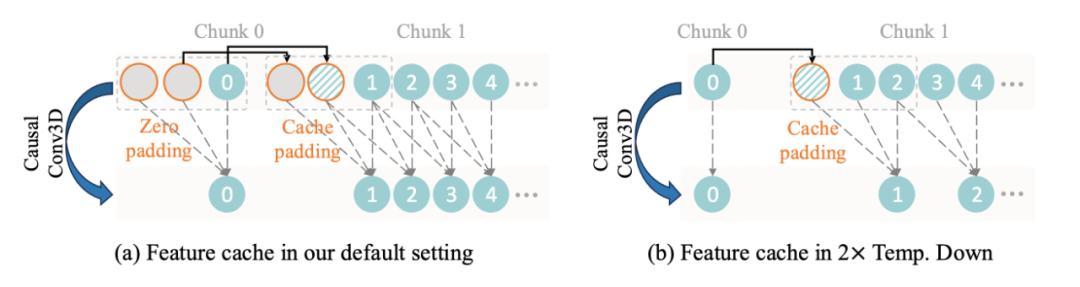
图3: 特征缓存机制。(a)和(b)分别显示了如何在常规因果卷积和时间下采样中使用此机制
为实现对任意长度视频的高效编码与解码,在Wan-VAE的因果卷积模块中实现了特征缓存机制(feature cache mechanism)。具体而言:
1. 输入格式与分块策略:视频序列的帧数遵循 1 + T 的输入格式(首帧 + 后续T帧),因此将视频划分为 1 + T/4 个块(chunk),与潜在特征(latent features)的数量一致。编码/解码时,每个操作仅处理与单个潜在特征对应的视频块。根据时间压缩比例,每个处理块最多包含4帧,有效避免内存溢出。
2. 时间连续性保障:
- 默认设置(无下采样)(图3a):
- 因果卷积不改变帧数,需缓存历史块的最后2帧特征(卷积核大小为3)。
- 初始块用2个虚拟帧(zero padding)初始化缓存;后续块复用前一块的最后2帧作为缓存,丢弃过时数据。
- 2倍时间下采样(图3b):
- 仅在非初始块使用单帧缓存填充,确保输出序列长度严格符合下采样比例,同时维持块间因果性。
3. 机制优势:
- 内存利用率优化:分块处理限制单次计算量,避免长视频导致的显存爆炸。
- 跨块特征一致性:缓存历史特征实现块间平滑过渡,支持无限长视频的稳定推理。
3.1.4 模型架构
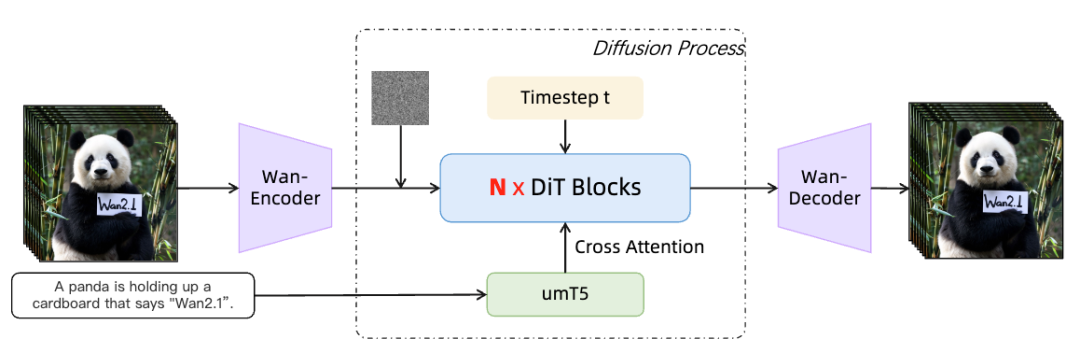
图4:Wan模型架构
Wan模型基于当前主流的DiT(Diffusion Transformer)架构设计,主要由三个核心组件构成:
1. Wan-VAE:将输入视频 V∈R (1+T)×H×W×3从像素空间编码至潜在空间 x∈R 1+T/4×H/8×W/8。
2. Diffusion Transformer:接收潜在表示 x ,通过去噪过程生成目标视频的潜在特征。
3. Text Encoder:将输入文本转换为语义嵌入,指导视频生成内容。
Diffusion transformer. 主要由三个组件构成:一个 patchifying 模块 , transformer blocks 和一个 unpatchifying 模块 。在每个块中专注于有效地建模时空上下文关系,并将文本条件与时间步长一起嵌入。实验验证该设计减少约25%参数量,并在相同参数量级下显著提升性能。
1. Patchifying Module
- 使用核大小为 (1, 2, 2) 的3D卷积,并通过展平操作将输入x转换为形状为(B,L,D)的特征序列。
- B:批大小(Batch Size)
- L=(1+T/4)×H/16×W/16:序列长度(时间压缩后帧数 × 空间分块数)
- D:潜在维度(Latent Dimension)
2. Transformer Blocks
- 核心任务:建模时空上下文关系,并嵌入文本条件与时间步信息。
- 文本条件嵌入:采用交叉注意力机制,确保模型在长上下文建模中仍能遵循文本指令。
- 时间步调制:
- 使用共享MLP(含Linear层和SiLU激活层)处理时间嵌入,独立预测6个调制参数。
- 每个变换器块学习独特的偏置(Bias),增强表达能力。
3. Unpatchifying Module:将变换后的序列特征还原至原始潜在空间维度。
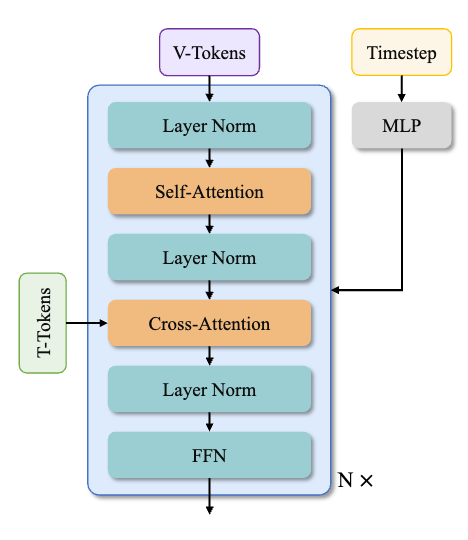
图 5: Transformer block of Wan.
- Text encoder. Wan的架构采用umT5对输入文本进行编码。通过大量实验,发现umT5具有多个优势:
- 它拥有强大的多语言编码能力,能有效理解中文和英文,以及输入的视觉文本;
- 在相同条件下,发现umT5在组合方面优于其他单向注意力机制的LLM;
- 它表现出优异的收敛性,在相同参数规模下,umT5实现更快收敛。
基于这些发现,最终选择umT5作为文本嵌入器。
3.1.5 模型训练
利用流匹配框架为图像和视频领域建模了一个统一的去噪扩散过程。首先对低分辨率图像进行预训练,然后对图像和视频进行多阶段联合优化。在整个阶段中,图像视频联合训练通过使用逐步扩大的数据分辨率和延长的时间段来进行。
1. Image pre-training. 实验分析揭示了在高分辨率图像与长时长视频序列联合直接训练中的两个关键挑战:
- 扩展的序列长度(通常 1280×720 视频对应 81 帧)会显著降低训练吞吐量。在固定 GPU-hour 预算下,这导致数据吞吐不足,从而阻碍模型收敛速度。
- 过高的 GPU 内存消耗迫使使用次优 batch size,引发由梯度方差突增导致的训练不稳定。
为缓解这些问题,通过低分辨率( 256px )text-to-image 预训练来初始化 14B 模型的训练,在逐步引入高分辨率视频模态前,强制建立跨模态的 semantic-textual alignment 和 geometric structure fidelity。
2. Pre-training configurations. 采用bf16混合精度的高效训练,并结合使用AdamW优化器,权重衰减系数为 1e −3。初始学习率设置为 1e −4,并根据 FID 和 CLIP Score 指标的平稳状态动态降低。
3. Post-training configurations. 在后训练阶段,保持与预训练阶段相同的模型架构和优化器配置,并使用预训练的检查点初始化网络。使用后训练视频数据集,以480像素和720像素的分辨率进行联合训练。
4. Workload Analysis. 在训练过程中,只有DiT模型得到优化,而文本编码器和VAE编码器保持冻结状态。因此,GPU内存使用主要集中在DiT的训练上。DiT的GPU内存使用可以表示为 γLbsh ,其中 γ 取决于DiT层的实现, L 表示DiT层的数量。由于模型输入包括视频令牌、输入提示和时间步长,因此 γ 的值通常大于普通LLM模型。例如,虽然标准LLM的 γ 可能为34,但DiT模型的 γ 可能超过60。因此,当序列长度达到100万个令牌且微批量大小为1时,14B DiT模型中激活的总GPU内存使用量可能超过8TB。
5. DiT parallel strategy. 鉴于DiT模型的大小适中,并考虑到优化重叠计算和通信以及最大化数据并行(DP)的规模,选择FSDP作为参数分片策略。
6. Distributed strategy switching for different modules. 在训练过程中,不同模块利用相同的资源。具体而言,将数据并行(DP)应用于变分自编码器(VAE)和文本编码器,而DiT模块则结合使用数据并行(DP)和检查点并行(CP)。因此,当VAE和文本编码器的输出在训练过程中被馈送到DiT模块时,有必要切换分布式策略以避免资源浪费。具体而言,检查点并行(CP)要求CP组内的设备读取相同批次的数据。然而,如果VAE和文本编码器部分中的设备也读取相同的数据,则会导致冗余计算。为了消除这种冗余,CP组内的设备最初读取不同的数据。然后,在执行CP之前,执行一个大小等于CP大小的循环遍历,依次广播CP组内不同设备读取的数据,以确保CP内的输入相同。通过这种方式,单个模型迭代中VAE和文本编码器的时间比例减少到1/CP,从而提高了整体性能。
3.2 Wan2.1代码解读
下面以PaddleMIX中Wan2.1的实现为例,对Wan2.1中关键创新点的代码实现进行讲解。
3.2.1 CausalConv3d
核心算子。
- 无限视频支持原理:通过 cache_x 缓存前一时间块的最后 CACHE_T 帧(代码中定义为2帧),在卷积时与当前块拼接,模拟完整时序上下文。
- 内存优势:显存占用仅与块大小相关(如处理 1080P 视频时每块 4 帧),而非全长视频,实现 O(1) 内存复杂度。
class WanCausalConv3d(nn.Conv3D):r"""A custom 3D causal convolution layer with feature caching support.This layer extends the standard Conv3D layer by ensuring causality in the time dimension and handling featurecaching for efficient inference.Args:in_channels (int): Number of channels in the input imageout_channels (int): Number of channels produced by the convolutionkernel_size (int or tuple): Size of the convolving kernelstride (int or tuple, optional): Stride of the convolution. Default: 1padding (int or tuple, optional): Zero-padding added to all three sides of the input. Default: 0"""def __init__(self,in_channels: int,out_channels: int,kernel_size: Union[int, Tuple[int, int, int]],stride: Union[int, Tuple[int, int, int]] = 1,padding: Union[int, Tuple[int, int, int]] = 0,) -> None:super().__init__(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,)# Set up causal paddingself.padding = self._updated_paddingself._padding = (self.padding[2], self.padding[2], self.padding[1], self.padding[1], 2 * self.padding[0], 0)self.padding = (0, 0, 0)self._updated_padding = (0, 0, 0)def forward(self, x, cache_x=None):padding = list(self._padding)if cache_x is not None and self._padding[4] > 0:cache_x = cache_xx = paddle.concat([cache_x, x], axis=2)padding[4] -= cache_x.shape[2]x = F.pad(x, padding)return super().forward(x)
3.2.2 时-空解耦的渐进式下采样
以Downsample3d为例。
- 时空分离压缩:对时间维度(time_conv)和空间维度(resample)分别进行下采样,时间压缩率通过temperal_downsample控制(如[True, True, False]表示前两阶段进行时间下采样)。
- 信息保留:缓存每一时间块的最后1帧(feat_cache[idx] = x[:, :, -1:, :, :]),作为下一块的初始状态,避免时序断裂。
class WanResample(nn.Layer): def forward(self, x, feat_cache=None, feat_idx=[0]): if self.mode == "downsample3d":if feat_cache is not None:idx = feat_idx[0]if feat_cache[idx] is None:feat_cache[idx] = x.clone()feat_idx[0] += 1else:cache_x = x[:, :, -1:, :, :].clone()x = self.time_conv(paddle.concat([feat_cache[idx][:, :, -1:, :, :], x], 2))feat_cache[idx] = cache_xfeat_idx[0] += 1return x
3.2.3 残差块中的跨块特征传递
层级缓存:每个残差块独立维护特征缓存,在卷积层间传递跨块信息。保证在长视频序列中前序信息的有效引入。
class WanResidualBlock(nn.Layer):def forward(self, x, feat_cache=None, feat_idx=[0]):# Apply shortcut connectionh = self.conv_shortcut(x)# First normalization and activationx = self.norm1(x)x = self.nonlinearity(x)if feat_cache is not None:idx = feat_idx[0]cache_x = x[:, :, -CACHE_T:, :, :].clone() # 提取当前块尾部帧if cache_x.shape[2] < 2 and feat_cache[idx] is not None:cache_x = paddle.concat([feat_cache[idx][:, :, -1, :, :].unsqueeze(2), cache_x], axis=2)x = self.conv1(x, feat_cache[idx]) # 注入历史特征feat_cache[idx] = cache_x #更新缓存feat_idx[0] += 1else:x = self.conv1(x)
3.2.4 Transformer block of Wan
上述代码与图4结构一一对应,可以参照图5进行对照理解。
class WanTransformerBlock(nn.Layer):def __init__(self,dim: int,ffn_dim: int,num_heads: int,qk_norm: str = "rms_norm_across_heads",cross_attn_norm: bool = False,eps: float = 1e-6,added_kv_proj_dim: Optional[int] = None,):super().__init__()# 1. Self-attentionself.norm1 = FP32LayerNorm(dim, eps, weight_attr=False, bias_attr=False)self.attn1 = Attention(query_dim=dim,heads=num_heads,kv_heads=num_heads,dim_head=dim // num_heads,qk_norm=qk_norm,eps=eps,bias=True,cross_attention_dim=None,out_bias=True,processor=WanAttnProcessor2_0(),)# 2. Cross-attentionself.attn2 = Attention(query_dim=dim,heads=num_heads,kv_heads=num_heads,dim_head=dim // num_heads,qk_norm=qk_norm,eps=eps,bias=True,cross_attention_dim=None,out_bias=True,added_kv_proj_dim=added_kv_proj_dim,added_proj_bias=True,processor=WanAttnProcessor2_0(),)self.norm2 = FP32LayerNorm(dim, eps) if cross_attn_norm else nn.Identity()# 3. Feed-forwardself.ffn = FeedForward(dim, inner_dim=ffn_dim, activation_fn="gelu-approximate")self.norm3 = FP32LayerNorm(dim, eps, weight_attr=False, bias_attr=False)self.scale_shift_table = nn.Parameter(paddle.randn([1, 6, dim]) / dim**0.5)def forward(self,hidden_states: paddle.Tensor,encoder_hidden_states: paddle.Tensor,temb: paddle.Tensor,rotary_emb: paddle.Tensor,) -> paddle.Tensor:shift_msa, scale_msa, gate_msa, c_shift_msa, c_scale_msa, c_gate_msa = (self.scale_shift_table + temb.astype(paddle.float32)).chunk(6, axis=1)# 1. Self-attentionnorm_hidden_states = (self.norm1(hidden_states.astype(paddle.float32)) * (1 + scale_msa) + shift_msa).cast(hidden_states.dtype)attn_output = self.attn1(hidden_states=norm_hidden_states, rotary_emb=rotary_emb)hidden_states = (hidden_states.astype(paddle.float32) + attn_output * gate_msa).cast(hidden_states.dtype)# 2. Cross-attentionnorm_hidden_states = self.norm2(hidden_states.astype(paddle.float32)).cast(hidden_states.dtype)attn_output = self.attn2(hidden_states=norm_hidden_states, encoder_hidden_states=encoder_hidden_states)hidden_states = hidden_states + attn_output# 3. Feed-forwardnorm_hidden_states = (self.norm3(hidden_states.astype(paddle.float32)) * (1 + c_scale_msa) + c_shift_msa).cast(hidden_states.dtype)ff_output = self.ffn(norm_hidden_states)hidden_states = (hidden_states.astype(paddle.float32) + ff_output.astype(paddle.float32) * c_gate_msa).cast(hidden_states.dtype)return hidden_states
3.2.5 归一化层
归一化操作使用了RMS-norm
class WanRMS_norm(nn.Layer):r"""A custom RMS normalization layer.Args:dim (int): The number of dimensions to normalize over.channel_first (bool, optional): Whether the input tensor has channels as the first dimension.Default is True.images (bool, optional): Whether the input represents image data. Default is True.bias (bool, optional): Whether to include a learnable bias term. Default is False."""def __init__(self, dim: int, channel_first: bool = True, images: bool = True, bias: bool = False) -> None:super().__init__()broadcastable_dims = (1, 1, 1) if not images else (1, 1)shape = (dim, *broadcastable_dims) if channel_first else (dim,)self.channel_first = channel_firstself.scale = dim**0.5self.gamma = nn.Parameter(paddle.ones(shape))self.bias = nn.Parameter(paddle.zeros(shape)) if bias else 0.0def forward(self, x):return F.normalize(x, axis=(1 if self.channel_first else -1)) * self.scale * self.gamma + self.bias
四、上手教程
4.1 环境配置
若曾使用PaddlePaddle主页build_paddle_env.sh脚本安装PaddlePaddle,请根据本身cuda版本手动更新版本Installation(下方链接)。
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
安装ppdiffusers:ppdiffusers在目录下运行以下命令:
python install -e .
硬件要求:
- wan2.1模型:1.3B模型请保证有30G以上显存,14B模型请保证有80G显存
- hunyuanvideo模型:最少需要50G以上显存
4.2 Wan2.1 文本到视频
cd Wan2.1
python text2video.py
可以通过text2video.py文件中的model_id参数选择模型,支持以下模型:
model_id 当前支持:Wan-AI/Wan2.1-T2V-14B-Diffusers,Wan-AI/Wan2.1-T2V-1.3B-Diffusers
对应Wan2.1-T2V的14B版本与1.3B版本。
输出结果: 在同一目录下,输出output.mp4文件,若没有修改prompt,视频长度为5s,视频内容为:一只猫和一只狗在厨房里一起烤蛋糕。猫在仔细地测量面粉,狗则在用木勺搅拌面糊。厨房里很舒适,阳光透过窗户洒进来。
Wan2.1 文本到视频
4.3 Wan2.1 图像到视频
python image2video.py
可以通过image2video.py文件中的model_id参数选择模型,支持以下模型:
model_id 当前支持:Wan-AI/Wan2.1-I2V-14B-480P-Diffusers,Wan-AI/Wan2.1-I2V-14B-720P-Diffusers
对应Wan2.1-I2V 14B的480P版本与720P版本。
输出结果: 在同一目录下,输出output.mp4文件,若没有修改prompt,将会生成一个由图5为基础,符合文件内容描述:“一名宇航员在月球表面从一枚蛋中孵化,”,“背景实现了太空的黑暗和深度。高质量、超逼真的细节和令人屏息的电影镜头”。的一段5s视频。
Wan2.1 图像到视频
4.4 Hunyuanvideo文本到视频
python ppdiffusers/examples/inference/text_to_video_generation-hunyuan_video.py
使用如下prompt “the ultra-wide-angle lens follows closely from the hood, with raindrops continuously splattering against the lens. A sports car speeds around a corner. There are colorful streaks on the car’s surface. The camera swiftly shifts to the side of the car, gradually zooms out.”,视频生成结果如下所示
Hunyuanvideo文本到视频
五、总结
在文生视频领域,Wan2.1和Huyuanvideo凭借强大的网络架构和高质量数据,可以生成更丰富、高质量的视频。 百度飞桨团队推出的PaddleMIX套件已支持模型的推理全流程,通过深入解析其代码实现,研究人员和开发者能够更透彻地理解模型的核心技术细节与创新。
论文链接:
Wan2.1 Technical Report
https://arxiv.org/abs/2503.20314
HunyuanVideo: A Systematic Framework For Large Video Generative Models
https://arxiv.org/abs/2412.03603
项目地址:
Wan2.1
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/ppdiffusers/examples/Wan2.1
HunyuanVideo
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/ppdiffusers/examples/HunyuanVideo
为了帮助您通过解析代码深入理解模型实现细节与技术创新,基于PaddleMIX框架实操多模态文生视频模型Wan2.1和HunyuanVideo,我们将开展“多模态大模型PaddleMIX产业实战精品课”,带您实战操作多模态生成任务处理。4月28日正式开营,报名即可免费获得项目消耗算力(限时一周),名额有限,立即点击链接报名:https://www.wjx.top/vm/Q1ewEYG.aspx?udsid=781380
