YOLOv12的注意力机制革新与实时检测性能分析——基于架构优化与历史版本对比
 目录
目录
一、摘要
二、引言
三、YOLO架构的技术演变
四、YOLOv12的架构设计
主干网特征提取
头部特征融合和目标检测
五、YOLOv12的架构创新
区域注意力模块
残差高效层聚合网络(R-ELAN)
其他改进和效率提升
六、YOLOv12 的基准评估
延迟与精度
FLOPs vs精度
速度比较和硬件利用率
七、YOLO12支持的关键计算机视觉任务
实时物体检测
物体定位
多尺度物体检测
优化特征提取
实例分割
八、讨论
模型效率和部署
结构创新和计算效率
性能提升和硬件适应性
更广泛的意义和影响
九、挑战与未来研究方向
硬件限制和在边缘设备上的部署
训练复杂性和数据集依赖性
物体检测之外的扩展
结论
一、摘要
YOLO系列一直是实时目标检测领域的领先框架,不断提高速度和准确性之间的平衡。然而,将注意力机制整合到YOLO中一直具有挑战性,因为它们的计算开销很高。YOLOv12引入了一种新方法,在保持实时性能的同时,成功地集成了基于注意力的增强功能。本文全面回顾了YOLOv12在架构上的创新,包括用于提高计算效率的区域注意(Area Attention)、用于改进特征聚合的剩余高效层聚合网络(Residual Efficient Layer Aggregation Networks)和用于优化内存访问的闪存注意(FlashAttention)。此外,我们还将YOLOv12与之前的YOLO版本和竞争对象检测器进行了比较,分析了其在准确性、推理速度和计算效率方面的改进。通过分析,我们展示了YOLOv12如何通过改进延迟与准确性的权衡和优化计算资源来推进实时对象检测。

论文题目:
A REVIEW OF YOLOV12: ATTENTION-BASED ENHANCEMENTS VS. PREVIOUS VERSIONS
论文链接:
https://arxiv.org/pdf/2504.11995
二、引言
实时目标检测是现代计算机视觉的基石,在自动驾驶、机器人和视频监控等应用中发挥着关键作用。这些领域不仅要求高精度,还要求低延迟性能,以确保实时决策。在各种目标检测框架中,YOLO系列已成为主流解决方案,通过不断完善卷积神经网络(CNN)架构,在速度和精度之间取得了平衡。然而,基于卷积神经网络的检测器面临的一个基本挑战在于其捕捉长程依赖关系的能力有限,而这对于理解复杂场景中的空间关系至关重要。这一局限性促使人们加大了对注意力机制的研究,特别是对擅长全局特征建模的视觉变换器(ViTs)的研究。尽管ViTs有很多优点,但其计算复杂度为二次方,内存访问效率低,因此不适合实时部署。
为了解决这些局限性,YOLOv12引入了一种以注意力为中心的方法,该方法整合了关键的创新技术,在保持实时性能的同时提高了效率。通过在YOLO框架中嵌入注意力机制,它成功地缩小了基于 CNN 的检测器与基于变压器的检测器之间的差距,同时又不影响速度。这是通过优化计算效率、改进特征聚合和完善注意力机制的几项架构改进实现的:
-
区域注意 (A2):这是一种新颖的机制,可分割空间区域以降低自我注意的复杂性,在提高计算效率的同时保留较大的感受野。这使得基于注意力的模型能在速度上与CNN竞争。
-
剩余高效层聚合网络(R-ELAN):它是对传统ELAN的增强,旨在通过引入残差捷径和修订的特征聚合策略来稳定大规模模型的训练,从而确保更好的梯度流和优化。
-
结构精简:对结构进行了多项改进,包括集成FlashAttention以提高内存访问效率,取消位置编码以简化计算,以及优化MLP比例以平衡性能和推理速度。
三、YOLO架构的技术演变
通过不断的架构创新和性能优化,“YOU ONLY LOOK ONCE”(YOLO)系列彻底改变了实时目标检测技术。YOLO 的发展可追溯到不同的版本,每个版本都有显著的进步。
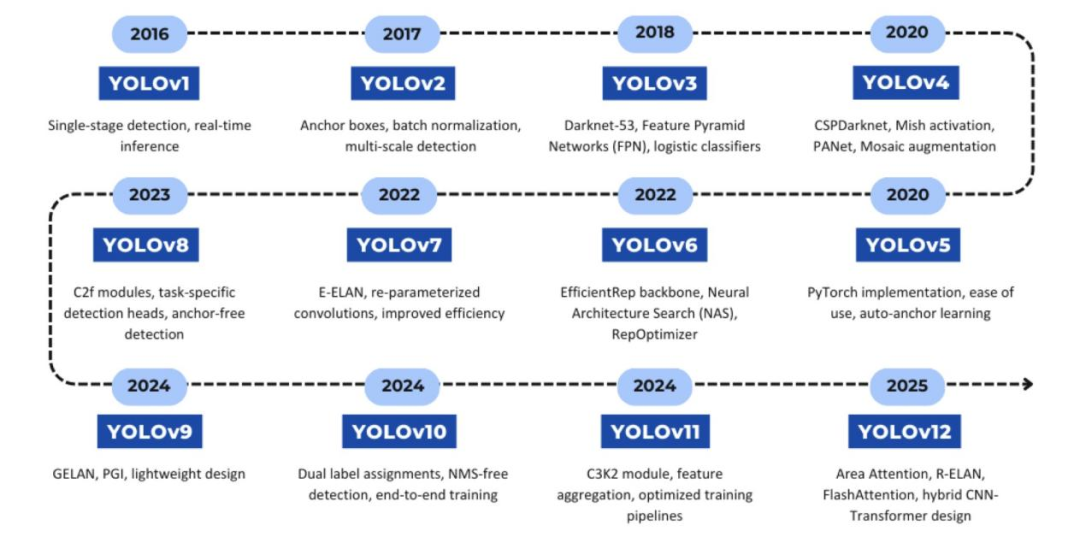
-
约瑟夫-雷德蒙等人开发的 YOLOv1(2015 年)引入了单阶段目标检测的概念,优先考虑速度而非准确性。它将图像划分为网格,并直接从每个网格单元预测边界框和类概率,从而实现实时推理。与两阶段检测器相比,这种方法大大降低了计算开销,尽管在定位精度上有一些折衷。
-
YOLOv2(2016)也是约瑟夫-雷德蒙(Joseph Redmon)的作品,通过引入锚箱、批量归一化和多尺度训练,增强了检测能力。锚点框允许模型预测各种形状和大小的边界框,从而提高了检测不同物体的能力。批量归一化稳定了训练并提高了收敛性,而多尺度训练使模型对不同的输入分辨率更加稳健。
-
约瑟夫-雷德蒙(Joseph Redmon)再次提出的 YOLOv3(2018)[13]利用Darknet-53骨干网、特征金字塔网络(FPN)和逻辑分类器进一步提高了准确性Darknet-53提供了更深入、更强大的特征提取器,而 FPN 则使模型能够利用多尺度特征来改进对小物体的检测。逻辑分类器取代了用于类别预测的softmax,实现了多标签分类。
-
Alexey Bochkovskiy等人开发的YOLOv4(2020)结合了CSPDarknet、Mish激活、PANet和Mosaic增强。CSPDarknet在保持性能的同时降低了计算成本,Mish激活改善了梯度流,PANet增强了特征融合,Mosaic增强增加了数据多样性。
-
由Ultralytics开发的YOLOv5(2020 年)引入了PyTorch实现,标志着一个关键的转变。这大大简化了培训和部署,使更多人可以使用YOLO。它还具有自动锚点学习功能,可在训练过程中动态调整锚点框的大小,并在数据增强方面取得了进步。从Darknet到PyTorch的过渡是一个重大变化,极大地促进了模型的普及。
-
由美团开发的YOLOv6(2022 年)通过EfficientRep主干网、神经架构搜索(NAS)和RepOptimizer提高了效率。EfficientRep优化了模型的架构以提高速度和准确性,NAS自动搜索最优超参数,RepOptimizer则通过结构重参数化缩短推理时间。
-
Wang等人开发的 YOLOv7(2022 年)通过扩展高效层聚合网络(E-ELAN)和重新参数化卷积进一步提高了效率。E-ELAN增强了特征整合和学习能力,而重新参数化的卷积减少了计算开销。
-
同样由Ultralytics开发的YOLOv8(2023 年)引入了C2f模块、特定任务检测头和无锚检测。C2f 模块增强了特征融合和梯度流,特定任务检测头允许执行更专业的检测任务,无锚检测消除了对预定义锚框的需求,简化了检测过程。
-
由Chien-Yao Wang等人开发的YOLOv9(2024 年)引入了通用高效层聚合网络(GELAN)和可编程梯度信息(PGI)。GELAN提高了模型学习不同特征的能力,而PGI则有助于避免深度网络训练过程中的信息丢失。
-
YOLOv10(2024)由多位研究人员共同开发,强调双标签分配、无NMS 检测和端到端训练。双标签分配增强了模型处理模糊对象实例的能力,无NMS检测减少了计算开销,而端到端训练则简化了训练过程。之所以说 “各种研究贡献者”,是因为目前还没有一个像以前的版本一样得到普遍认可和一致认可的开发者或组织。
-
由Glenn Jocher和Jing Qiu开发的YOLOv11(2024)侧重于C3K2模块、特征聚合和优化的训练管道。C3K2模块增强了特征提取能力,特征聚合提高了模型整合多尺度特征的能力,而优化的训练管道则缩短了训练时间。与YOLOv10 类似,开发人员信息的整合程度较低,协作性较强。
最新迭代版本YOLOv12(2025 年)在保持实时效率的同时整合了关注机制。它引入了A2、残差高效层聚合网络(R-ELAN)和FlashAttention,以及混合CNN-Transformer框架。这些创新改进了计算效率,优化了延迟与准确性之间的权衡,超越了基于CNN和Transformer的目标检测器。
YOLO模型的发展突显了从基于暗网的架构到PyTorch实现,以及最近向混合CNN变换器架构[27]的转变。每一代产品都兼顾了速度和精度,并在特征提取、梯度优化和数据效率方面取得了进步。图1展示了YOLO架构的发展过程,强调了各个版本的关键创新。
随着YOLOv12架构的完善,注意力机制现已嵌入YOLO框架,从而优化了计算效率和高速推理。下一节将详细分析这些改进,并对YOLOv12在多个检测任务中的性能进行基准测试。
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
具体操作步骤可参考:YOLO11全解析:从原理到实战,全流程体验下一代目标检测
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
四、YOLOv12的架构设计
YOLO框架引入了一个统一的神经网络,在一次前向传递中同时执行边界框回归和对象分类,从而彻底改变了对象检测方法。与传统的两阶段检测方法不同,YOLO采用的是端到端方法,因此在实时应用中效率很高。其完全可微分的设计实现了无缝优化,从而提高了目标检测任务的速度和准确性。
YOLOv12架构的核心由两个主要部分组成:主干和头部。主干作为特征提取器,通过一系列卷积层处理输入图像,生成不同尺度的分层特征图。这些特征能捕捉到目标检测所需的基本空间和上下文信息。头部负责完善这些特征,并通过执行多尺度特征融合和定位来生成最终预测结果。通过上采样、连接和卷积操作的组合,头部增强了特征表示,确保了对小型、中型和大型物体的稳健检测。YOLOv12 的主干和头部架构如算法1所示。
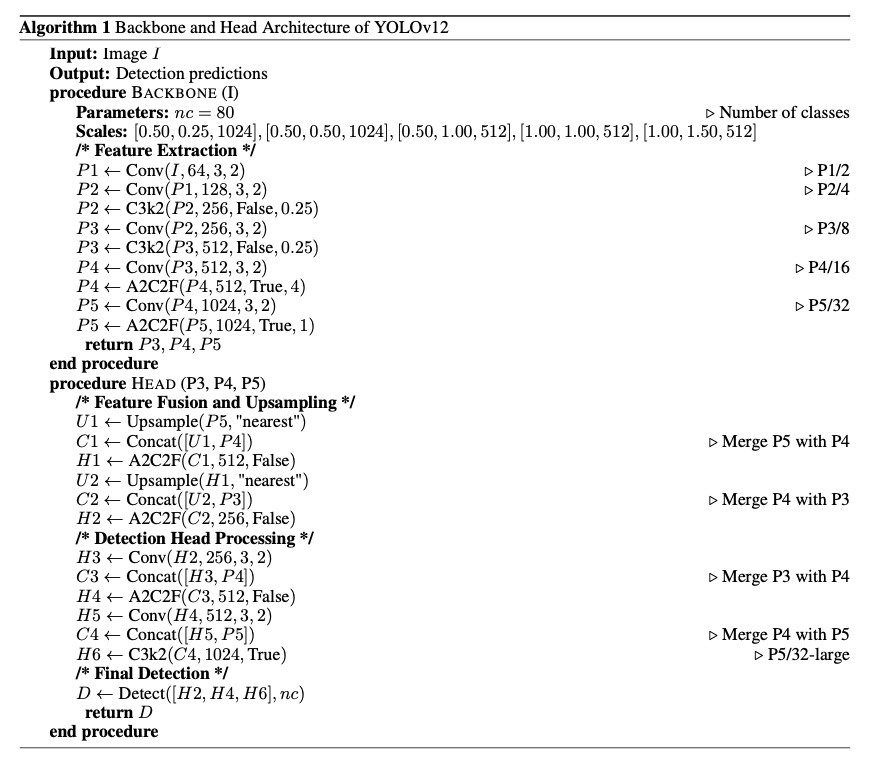
-
主干网特征提取
YOLOv12的骨干层通过一系列卷积层处理输入图像,在增加特征图深度的同时逐步缩小空间维度。处理过程从提取低层次特征的初始卷积层开始,然后是执行下采样以捕捉层次信息的附加卷积层。第一阶段应用步长为2的3×3卷积,生成初始特征图。随后是另一个卷积层,进一步降低空间分辨率,同时增加特征深度。
当图像在骨干层中移动时,会使用C3k2和A2C2F等专门模块进行多尺度特征学习。C3k2模块在保持计算效率的同时增强了特征表示,而 A2C2F 模块则改进了特征融合,以实现更好的空间和上下文理解。骨干网继续这一过程,直到生成三个关键特征图:P3、P4和P5,分别代表不同规模的特征提取。然后,这些特征图被传送到检测头进行进一步处理。
-
头部特征融合和目标检测
YOLOv12 的头部负责合并多尺度特征并生成最终的目标检测预测。它采用一种特征融合策略,将来自骨干网不同层次的信息结合起来,以提高对小型、中型和大型物体的检测精度。这是通过一系列上采样和串联操作实现的。首先,使用最近邻插值法对分辨率最高的特征图(P5)进行上采样。然后将其与相应的低分辨率特征图(P4)进行连接,以创建精细的特征表示。使用A2C2F模块对融合后的特征进行进一步处理,以增强其表现力。
对下一个尺度重复类似的过程,即对改进后的特征图进行上采样,并与较低尺度的特征图进行连接(P3)。这种分级融合确保了低级和高级特征都有助于最终检测,从而提高了模型检测不同尺度物体的能力。
特征融合后,网络将进行最终处理,为检测做好准备。细化后的特征会再次降低采样率,并在不同层次上进行合并,以加强物体表征。C3k2模块应用于最大尺度(P5/32-large),以确保在降低计算成本的同时保留高分辨率特征。然后,这些经过处理的特征图将通过最终的检测层,在不同的物体类别中应用分类和定位预测。算法1中正式描述了其主干和头部架构的详细分解。
五、YOLOv12的架构创新
YOLOv12引入了一种以注意力为中心的实时物体检测新方法,缩小了传统 CNN与基于注意力的架构之间的性能差距。以前的YOLO版本主要依靠CNN来提高效率,与之不同的是,YOLOv12在不牺牲速度的情况下集成了注意力机制。这是通过三个关键的架构改进实现的:A2模块、R-ELAN和整体模型结构的增强,包括FlashAttention和多层感知器 (MLP) 中计算开销的减少。下文将详细介绍其中的每个部分:
-
区域注意力模块
注意力机制的效率历来受制于其高昂的计算成本,尤其是与自我注意力操作相关的二次复杂性。缓解这一问题的常见策略是线性注意,它通过更有效的变换来近似注意互动,从而降低复杂性。不过,线性注意虽然提高了速度,但也存在全局依赖性下降、训练期间不稳定以及对输入分布变化敏感等问题。此外,由于其低秩表示约束,它很难在高分辨率图像中保留细粒度细节,从而限制了其在物体检测中的有效性。
为了解决这些局限性,YOLOv12引入了A2模块,它既保留了自我注意的优点,又大大减少了计算开销。与计算整个图像交互的传统全局注意力机制不同,区域注意力将特征图划分为大小相等的非重叠片段,可以是水平片段,也可以是垂直片段。具体来说,尺寸为(H,W)的特征图被划分为大小为(H/L,W)或(H,W/L)的L个片段,省去了其他注意力模型中的显式窗口划分方法,如移位窗口、十字注意力或轴向注意力。这些方法通常会带来额外的复杂性并降低计算效率,而A2则通过简单的重塑操作实现分割,在保持较大感受野的同时显著提高处理速度。这种方法如图2所示。

虽然A2将感受野缩小到原始大小的14,但其覆盖范围和效率仍超过了传统的局部注意方法。此外,它的计算成本几乎减半,从2n2hd(传统自我注意复杂度)降至n2hd。这种效率的提高使YOLOv12能够更有效地处理大规模图像,同时保持稳健的检测精度。
-
残差高效层聚合网络(R-ELAN)
在深度学习架构中,特征聚合在改善信息流方面起着至关重要的作用。以前的YOLO模型采用了高效层聚合网络(ELAN),通过将1×1卷积层的输出分成多个并行处理流,然后再将它们合并在一起,从而优化了特征融合。然而,这种方法有两大缺陷:梯度阻塞和优化困难。这些问题在较深的模型中尤为明显,因为输入和输出之间缺乏直接的残差连接,阻碍了有效的梯度传播,导致收敛缓慢或不稳定。
为了应对这些挑战,YOLOv12引入了R-ELAN,这是一种新颖的增强技术,旨在提高训练的稳定性和收敛性。与ELAN不同,R-ELAN集成了残差快捷方式,通过缩放因子(默认设置为0.01)将输入直接连接到输出。这确保了梯度流更加平滑,同时保持了计算效率。这些残差连接的灵感来源于Vision Transformers中的层缩放技术,但它们专门适用于卷积架构,以避免延迟开销,而延迟开销往往会影响注意力密集型模型。
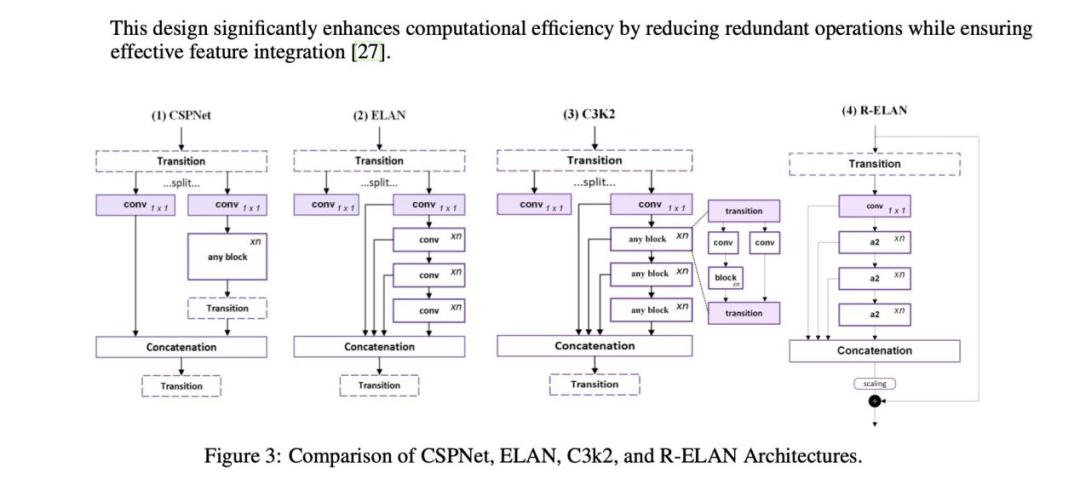
图3展示了不同架构的比较概览,包括 CSPNet、ELAN、C3k2和R-ELAN,突出了它们在结构上的区别。
-
CSPNet(跨阶段部分网络):CSPNet将特征图分成两部分,通过一系列卷积处理其中一部分,同时保持另一部分不变,然后将它们合并,从而改善梯度流并减少冗余计算。这种部分连接方法提高了效率,同时保留了表征能力。
-
ELAN(高效层聚合网络):ELAN通过引入更深入的特征聚合来扩展CSPNet。它在初始1×1卷积后利用多个并行卷积路径,将其连接起来以丰富特征表示。然而,由于没有直接的残差连接,梯度流受到限制,使得更深层次的网络更难训练。
-
C3k2作为ELAN的改进版本,C3k2在特征整合过程中加入了额外的变换,但仍继承了 ELAN 的梯度阻塞问题。虽然它提高了结构效率,但并不能完全解决深度网络所面临的优化难题。
-
R-ELAN:与ELAN和C3k2不同,R-ELAN通过纳入残差连接来重组特征聚合。R-ELAN并非首先分割特征图并对各部分进行独立处理,而是预先调整通道维度,在通过瓶颈层之前生成统一的特征图。
在 YOLOv12中引入R-ELAN有几个好处,包括收敛速度更快、梯度稳定性更好、优化难度更低,尤其是对于更大的模型(L和X)。以前的版本在使用Adam 和AdamW等标准优化器时经常会收敛失败,但R-ELAN有效地缓解了这些问题,使 YOLOv12在深度学习应用中更加稳健。
-
其他改进和效率提升
除了引入A2和R-ELAN,YOLOv12还在架构上做了一些改进,以提高整体性能:
-
采用更少堆叠块的精简骨干网:先前版本的YOLO在骨干网的最后阶段加入了多个堆叠关注层和卷积层。YOLOv12对此进行了优化,只保留了单个 R-ELAN块,从而加快了收敛速度,提高了优化稳定性,并提高了推理效率,尤其是在大型模型中。
-
高效卷积设计:为了提高计算效率,YOLOv12有策略地保留了具有优势的卷积层。它没有使用层归一化(LN)的全连接层,而是采用了与批归一化(BN)相结合的卷积操作,这更适合实时应用。这使得该模型既能保持类似CNN的效率,又能结合注意力机制。
-
去除位置编码:与传统的基于注意力的架构不同,YOLOv12摒弃了明确的位置编码,而是在注意力模块中采用大核可分离卷积(7×7),即位置感知器。这样既能确保空间感知,又不会增加不必要的复杂性,从而提高了效率和推理速度。
-
优化的MLP比率:传统的视觉转换器通常使用4的MLP扩展比,这导致在实时环境中部署时计算效率低下。YOLOv12 将 MLP 比率降低到 1.2 ,确保前馈网络不会主导整体运行时间。这一改进有助于平衡效率和性能,避免不必要的计算开销。
-
FlashAttention集成:基于注意力的模型的关键瓶颈之一是内存效率低下。YOLOv12采用了FlashAttention这种优化技术,通过重组计算以更好地利用GPU 高速内存(SRAM)来减少内存访问开销。这使得YOLOv12能够在速度上与CNN相媲美,同时利用注意力机制的卓越建模能力。
六、YOLOv12 的基准评估
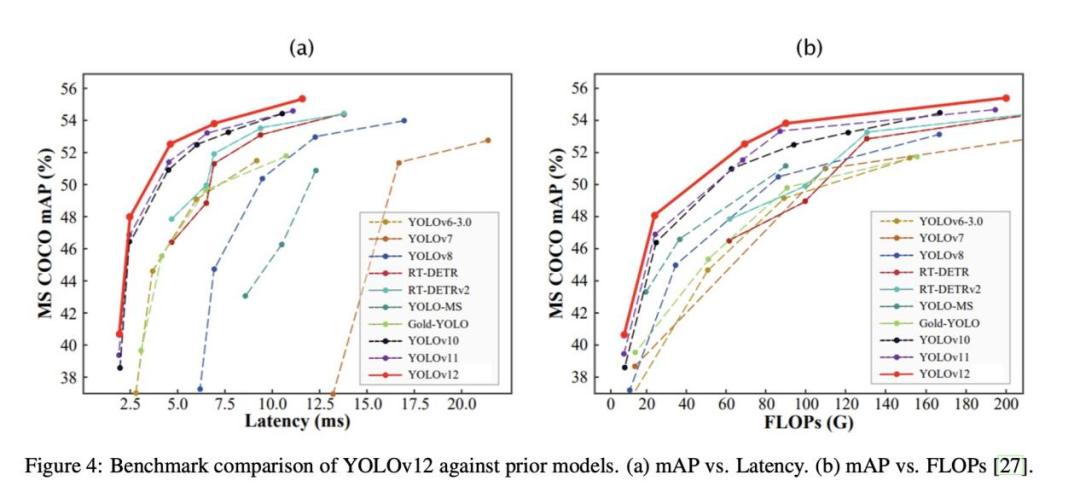
评估物体检测模型的性能需要对准确性和计算效率进行综合分析。YOLOv12 在MS COCO 2017物体检测基准上进行了评估,这是一个用于评估物体检测模型的标准数据集。其性能与之前的YOLO版本和最先进的检测模型(包括RT-DETR 和RT-DETRv2)进行了比较。评估考虑了平均精度(mAP)、推理延迟和FLOPs 等关键指标,有助于深入了解YOLOv12在实际应用中的有效性。图4展示了评估结果,下文将详细介绍YOLOv12在精度、速度和计算效率方面的进步。
-
延迟与精度
在实时物体检测应用中,推理速度是一个关键因素,因为在这种应用中,响应速度是最重要的。图4 (a) 中的结果表明,YOLOv12比以前的YOLO模型实现了更高的mAP,同时保持了有竞争力或更优越的延迟。例如,最小的变体 YOLOv12-N实现了40.6% 的 mAP,超过了YOLOv10-N(38.5%)和YOLOv11-N(39.4%),在T4 GPU上的推理时间为1.64 ms。更大的YOLOv12-X模型实现了 55.2%的mAP,比其前身YOLOv11-X高出0.6%,证明了模型改进在准确性和计算效率方面的有效性。在不同规模的模型中都能取得一致的改进,这突出表明了 YOLOv12 的架构和优化策略的有效性。
值得注意的是,YOLOv12与RT-DETR模型相比始终保持优势,尤其是在推理速度方面。YOLOv12- S的运行速度比RT-DETR-R18/RT-DETRv2-R18快42%,而计算量和参数分别只用了36%和45%。具体来说,YOLOv12-S的延迟时间为2.61毫秒,而RT-DETR- R18/RT-DETRv2-R18为4.58毫秒,速度优势显著。这些改进凸显了YOLOv12在保持或提高检测精度的同时降低延迟的效率,使其非常适合自动驾驶、监控和机器人等对时间敏感的应用,在这些应用中,快速处理至关重要。
-
FLOPs vs精度
图4 (b) 展示 mAP与FLOPs(每秒浮点运算次数)之间的关系,详细介绍了YOLOv12的计算效率。结果表明,与竞争架构相比,YOLOv12能以相当或更低的FLOPs实现更高的精度。代表YOLOv12的红色曲线始终高于竞争模型,这表明YOLOv12有效利用了计算资源,最大限度地提高了精确度。这种高效利用对于在计算能力有限的设备上部署模型至关重要。
一个重要的观察结果是,YOLOv12可以在不同规模的模型中有效扩展。虽然增加 FLOPs 通常会带来更高的精确度,但YOLOv12在FLOPs相同或更少的情况下始终优于之前的模型,从而加强了其架构优化的优势。例如,YOLOv12-L以88.9 GFLOPs实现了53.7%的mAP,超过了YOLOv11-L,后者以86.9 GFLOPs 实现了53.3%的mAP。这一趋势表明,YOLOv12即使在计算受限的情况下也能保持高效率,因此适合部署在边缘设备和移动平台等资源受限的硬件上,因为在这些硬件上,能效是首要考虑因素。
-
速度比较和硬件利用率
YOLOv12在效率方面的改进体现在其卓越的推理速度和各种平台的硬件利用率上。表2提供了RTX 3080、RTX A5000和RTX A6000 GPU在FP32和FP16 精度下的推理延迟对比分析,将YOLOv12与YOLOv9、YOLOv10和YOLOv11进行了比较。为了保持一致性,所有实验都在相同的硬件上进行。此外,还使用 Ultralytics代码库对YOLOv9和YOLOv10进行了评估。
结果表明,YOLOv12的推理速度明显优于YOLOv9,同时效率与YOLOv10和YOLOv11相当。值得注意的是,在RTX 3080 GPU上,YOLOv12-N的推理时间分别为1.7毫秒(FP32)和1.1毫秒(FP16),比YOLOv9的2.4毫秒(FP32)和 1.5 毫秒(FP16)有所改进。此外,在英伟达T4 GPU上,YOLOv12-S的推理延迟为2.61毫秒,巩固了其作为同类产品中最快实时物体检测模型之一的地位。这一效率水平确保了YOLOv12在对延迟敏感的应用中的可行性。
除了GPU基准测试之外,图5还提供了更多关于准确度、模型参数和CPU延迟之间权衡的比较信息。图5(a) 显示了精度参数权衡,其中YOLOv12确定了一个主导边界,超越了以前的YOLO版本,包括架构更紧凑的YOLOv10。图5(b) 展示了在CPU上的准确度-延迟性能,其中YOLOv12实现了卓越的效率,在英特尔酷睿i7-10700K 3.80GHz处理器上进行评估时,YOLOv12超越了之前的版本。
FlashAttention优化了GPU内存访问(SRAM利用率)并减少了内存开销,从而提高了吞吐量并降低了内存消耗,进一步促进了这些改进。通过解决内存访问中的瓶颈问题,YOLOv12可以进行更大规模的批量处理,并高效处理高分辨率视频流,因此特别适合需要即时反馈的实时应用,如增强现实、交互式机器人和自主系统。
七、YOLO12支持的关键计算机视觉任务
-
实时物体检测
YOLO系列始终将实时对象检测放在首位,每次迭代都在速度和准确性之间取得了更好的平衡。YOLOv1引入了单次检测的基本概念,允许模型在单次评估中直接从完整图像预测边界框和类概率。虽然在速度上具有突破性,但其准确性却受到定位误差的影响。YOLOv2在此基础上进行了改进,引入了批量归一化、锚框和多尺度训练,显著提高了精确度和召回率。
后来的版本,如YOLOv3和YOLOv4,引入了锚框和特征金字塔网络,以增强检测能力。包括YOLOv5和YOLOv6在内的后续模型在保持卷积架构基础的同时,还进行了优化以提高效率。值得注意的是,YOLOv6引入了BiC和 SimCSPSPPF模块,进一步提高了速度和准确性。YOLOv7和YOLOv8通过整合E-ELAN和C2f模块进一步完善了框架,从而增强了特征提取功能。
YOLOv9引入了用于架构优化的GELAN和用于改进训练的PGI,从而实现了更好的梯度流,并提高了对小物体检测的鲁棒性。YOLOv10和YOLOv11转向减少延迟和提高检测效率,其中YOLOv11引入了C3K2块和轻量级深度可分离卷积来加速检测。
在此基础上,YOLOv12通过整合注意力机制,在实时性能上赶上甚至超过了前代产品,而注意力机制以前被认为在此类应用中速度太慢。FlashAttention 的加入解决了内存瓶颈问题,使注意力处理过程与传统卷积方法一样迅速,同时提高了检测精度。值得注意的是,YOLOv12-N的mAP为40.6%,推理延迟为 1.64 毫秒,在精度和速度上都优于YOLOv10-N和YOLOv11-N。
-
物体定位
对象定位一直是YOLO模型的基石,每个版本都在完善其边界框回归功能。YOLOv1 最初将物体检测表述为一个回归问题,直接从图像中预测边界框,而不依赖于区域建议。然而,它缺乏基于锚点的机制,导致定位精度不一致。YOLOv2引入了锚点框和高分辨率分类器,提高了定位精度。
YOLOv3和YOLOv4采用了基于锚点的检测,虽然有效,但由于预定义的锚点大小,偶尔会导致不准确的边界框。在YOLOv5和YOLOv6中,转向无锚方法和双层特征融合提高了定位精度。YOLOv7和YOLOv8中的进一步优化,如动态标签分配和增强的损失函数,延续了这一趋势。YOLOv9 通过改进特征聚合策略和采用更先进的分配策略来减少错位,从而增强了定位功能。
YOLOv10和YOLOv11利用C3K2模块和非最大无抑制(NMS-free)训练改进了检测头,完善了边界框预测。YOLOv12 通过引入A2增强了物体定位功能A2可捕捉到更广阔的感受野,从而实现更精确的定位。FlashAttentio的使用减少了内存开销,进一步提高了边界框回归精度,从而在保持快速推理速度的同时,在定位精度上超越了之前的版本。
-
多尺度物体检测
在同一幅图像中检测不同大小物体的能力一直是YOLO系列的重点。YOLOv1和YOLOv2由于多尺度特征提取能力有限,在小物体检测方面举步维艰。YOLOv4采用了FPN,以促进多尺度检测。YOLOv5和YOLOv6的增强功能,如 CSPNe和 SimCSPSPPF,优化了不同尺度的性能。YOLOv7和YOLOv8引入了用于改进特征提取的C2f块,增强了多尺度检测能力。
YOLOv9引入了GELAN,通过优化不同分辨率的空间特征,进一步提高了多尺度检测能力。YOLOv10和YOLOv11专注于加速特征聚合和采用轻量级检测头,从而提高了性能,尤其是对小型物体的性能。
YOLOv12通过结合 A2[27]推进了多尺度物体检测,它无需复杂的窗口分割就能保持较大的感受野,从而保持了速度。性能指标表明,YOLOv12-N在检测小型物体时的mAP为20.2%,在检测中型物体时为45.2%,在检测大型物体时为 58.4%,在所有尺度上都优于之前的模型。
-
优化特征提取
有效的特征提取是物体检测的基础,YOLO的每一次迭代都力求加强这一过程。YOLOv1依赖于全连接层,这限制了它对未见物体尺度的泛化能力。YOLOv2用更深的卷积层和批量归一化取代了这些层,提高了效率。YOLOv3和YOLOv4采用了基于暗网的骨干网,虽然功能强大,但计算密集。
YOLOv5和YOLOv6引入了CSPNet和SimCSPSPPF,以优化特征学习并减少冗余。YOLOv7和YOLOv8中E-ELAN和C2f块的实施提高了特征提取的效率。YOLOv9引入了GELAN,进一步优化了梯度流,并能更好地利用特征图。
YOLOv10和YOLOv11引入了C3K2模块和轻量级卷积,进一步改进了特征流。YOLOv12引入了R-ELAN,加强了梯度流和特征整合。FlashAttention的采用解决了内存不足的问题,使特征提取更快、更有效。这些创新最终实现了速度和准确性的完美平衡,使YOLOv12成为实时检测性能的佼佼者。
-
实例分割
YOLO系列中实例分割功能的发展反映了在保持实时性的同时,从简单的基于网格的检测向高质量、像素级对象划分的转变。
早期的模型YOLOv1、YOLOv2和YOLOv3专门用于边界框检测,缺乏分割功能。YOLOv5是一个重大进步,它通过整合轻量级的全卷积 ProtoNet 引入了实例分割功能。这使得原型掩码的生成与检测输出相结合,从而产生像素精确的分割掩码,同时保持了高速性能。
YOLOv6重点改进了RepVG和CSPStackRep块等架构,在不直接添加分割分支的情况下增强了特征提取功能。YOLOv7引入了专门的分割变体(YOLOv7-Seg),在生成高质量掩码的同时保持了实时效率。YOLOv8利用无锚分割头和改进的主干进一步完善了分割,实现了更高的精度和稳健的分割掩码。YOLOv10引入了自适应掩码分辨率、用于减少掩码盒错位的特征对齐模块,以及用于捕捉远距离依赖关系的选择性变压器元素。这些改进大大提高了分割质量,同时保持了计算效率。YOLOv11利用跨阶段部分空间注意力(C2PSA)模块进一步优化了分割,提高了在杂乱环境中对相关区域的关注度。
虽然YOLOv12没有引入专门的实例分割框架,但某些架构增强功能(如改进的注意力机制和通过R-ELAN进行的特征聚合)可能有助于更有效地区分物体边界。FlashAttention通过减少内存开销,也可能有助于更精细地感知物体。不过,由于没有关于YOLOv12分段性能的具体基准或明确文档,它在这方面的优势仍有待探索,而不是得到证实的改进。
八、讨论
YOLOv12是物体检测领域的一项重大进步,它建立在YOLOv11的坚实基础之上,同时还融入了最前沿的架构改进。该模型在准确性、速度和计算效率之间取得了很好的平衡,是跨领域实时计算机视觉应用的最佳解决方案。
-
模型效率和部署
YOLOv12引入了一系列模型尺寸,从12n到12x,允许在各种硬件平台上部署。这种可扩展性确保YOLOv12可以在资源有限的边缘设备和高性能GPU上高效运行,在优化推理速度的同时保持高精度。纳米级和小型变体在保持检测精度的同时显著降低了延迟,是自主导航、机器人和智能监控等实时应用的理想选择。
-
结构创新和计算效率
YOLOv12引入了几项关键的架构改进,提高了特征提取和处理效率。R-ELAN优化了特征融合和梯度传播,使网络结构更深入、更高效。此外,7×7 可分离卷积的引入减少了参数数量,同时保持了空间一致性,从而以最小的计算开销改进了特征提取。
YOLOv12中最突出的优化之一是由FlashAttention驱动的基于区域的注意力机制,它在提高检测准确性的同时减少了内存开销。这使得YOLOv12能够更精确地定位对象,尤其是在杂乱或动态环境中,而不会影响推理速度。这些架构上的改进共同带来了更高的mAP,同时保持了实时处理效率,使得该模型在需要低延迟物体检测的应用中非常有效。
-
性能提升和硬件适应性
基准评估证实,YOLOv12在准确性和效率方面都优于之前的YOLO版本。YOLOv12m变体实现了与YOLOv11x相当或更高的mAP,同时使用的参数减少了25%,显示了计算效率的显著提高。此外,YOLOv12s等较小的变体可减少推理延迟,因此适合边缘计算和嵌入式视觉应用。
从硬件部署的角度来看,YOLOv12 具有很强的可扩展性,可与高性能 GPU 和低功耗人工智能加速器兼容。其优化的模型变体可在自动驾驶汽车、工业自动化、安全监控和其他实时应用中灵活部署。该模型具有高效的内存利用率和较低的计算占用空间,是资源严格受限环境下的实用选择。
-
更广泛的意义和影响
YOLOv12中引入的创新对多个行业具有广泛影响。它能够以较低的计算开销实现高精度的目标检测,这使其在自主导航、安全和实时监控系统中尤为重要。此外,该模型在小物体检测方面的改进提高了其在医疗成像和农业监测方面的可用性,在这些领域,检测细粒度的视觉细节至关重要。
此外,YOLOv12的高效处理管道可确保在云端、边缘和嵌入式人工智能系统中实现无缝部署,从而巩固其作为领先实时检测框架的地位。随着对高速、高精度视觉模型的需求不断增加,YOLOv12为可扩展的高效物体检测技术树立了新的标杆。
九、挑战与未来研究方向
尽管YOLOv12在架构和效率方面取得了进步,但仍存在一些需要进一步研究的挑战。解决这些限制对于优化实际应用中的部署以及将 YOLOv12 的功能扩展到标准对象检测之外至关重要。
-
硬件限制和在边缘设备上的部署
虽然YOLOv12集成了注意力机制和FlashAttention以提高准确性,但这些增强功能也增加了计算需求。虽然该模型在高端GPU上实现了实时性能,但在移动处理器、嵌入式系统和物联网设备等低功耗边缘设备上部署该模型仍是一个挑战[54]。
一个关键的限制因素是内存瓶颈。由于需要大量的特征图和矩阵乘法,基于注意力的架构需要更高的VRAM使用率。这使得YOLOv12难以在英伟达Jetson Nano、Raspberry Pi和基于ARM的微控制器等资源受限的设备上高效运行。通过低秩分解和权重剪枝等模型压缩技术优化内存占用,有助于缓解这一问题。
另一个挑战是推理延迟。虽然YOLOv12与完整的视觉转换器相比减少了注意力开销,但在边缘硬件上仍落后于基于纯CNN的YOLO版本。结构化剪枝、知识提炼和量化(如int8)等策略可以提高嵌入式人工智能加速器的实时性能。
此外,未来的研究还可以探索针对硬件的优化,以提高YOLOv12在不同平台上的效率。张量级优化、高效卷积核和FPGA/DSP实现等技术可以使模型更适合低功耗设备。
-
训练复杂性和数据集依赖性
YOLOv12精度的提高是以训练复杂度和数据集依赖性的增加为代价的。与早期针对轻量级训练进行优化的YOLO模型不同,YOLOv12引入了注意力机制和更深入的特征聚合,这导致了更高的计算要求。
其中一个主要挑战是训练成本。基于注意力的模块需要更多的FLOPs和内存带宽,因此训练成本很高,对于GPU资源有限的研究人员来说尤其如此。注意力权重的低阶因式分解、梯度检查点和高效损失函数等技术有助于降低计算开销。
另一个问题是数据效率。YOLOv12的超高准确率主要归功于在MS COCO和OpenImages等大型数据集上的训练。然而,在医学成像和工业缺陷检测等许多实际应用中,数据集往往较小或不平衡。探索自监督学习、半监督训练和域适应技术可以提高YOLOv12在低数据量环境中的性能。
此外,超参数敏感性仍然是一个挑战。YOLOv12需要对学习率、注意力头和锚框大小等参数进行大量调整,这可能会耗费大量计算资源。未来的研究可以利用NAS等技术研究自动超参数调整,以提高可用性和效率。
-
物体检测之外的扩展
虽然 YOLOv12已针对二维物体检测进行了优化,但许多新兴应用需要更高级的场景理解,而不仅仅是简单的边界框。将YOLOv12扩展到三维物体检测、实例分割和全景分割可以带来新的研究机会。
对于三维物体检测,自动驾驶和机器人等应用需要能够预测深度感知三维边界框的模型。目前基于变换器的模型,如DETR3D和BEVFormer,利用了多视角输入和激光雷达融合技术。扩展YOLOv12以处理立体图像或LiDAR数据可使其适用于3D感知任务。
例如,YOLOv12缺乏专用的分割头。现有的解决方案(如YOLACT和SOLOv2)通过集成轻量级遮罩分支来实现实时实例分割。YOLO的未来迭代可以集成并行分割分支,以改进像素级对象划分。
此外,结合实例分割和语义分割的全视角分割已成为计算机视觉中一个不断发展的领域。虽然当前的YOLO模型不支持这一任务,但在保持YOLO效率的同时,集成基于变换器的分割头,可以实现统一的物体检测和分割框架。
结论
在本综述中,我们对YOLOv12进行了深入分析,它是YOLO系列实时物体检测器的最新发展。通过集成A2模块、R-ELAN和FlashAttention等创新技术,YOLOv12有效地平衡了准确性和推理速度之间的权衡。这些改进不仅解决了早期YOLO版本和传统卷积方法固有的局限性,而且还突破了实时目标检测的极限。
我们追溯了YOLO架构的技术演进,并详细介绍了YOLOv12的结构改进,包括其优化的主干和检测头。全面的基准评估表明,YOLOv12在延迟、准确性和计算效率等多个指标上都取得了卓越的性能,非常适合高性能GPU和资源有限的设备。
虽然YOLOv12标志着一项重大进步,但我们的审查也发现了仍然存在的一些挑战,例如边缘部署的硬件限制和训练复杂性。总体而言,YOLOv12结合了卷积方法和注意力方法的优势,在实时物体检测方面迈出了一大步。其可扩展的设计和更高的效率不仅满足了广泛的应用需求,还为计算机视觉领域的进一步创新铺平了道路。
