目标检测篇---faster R-CNN
目标检测系列文章
第一章 R-CNN
第二篇 Fast R-CNN
目录
- 目标检测系列文章
- 📄 论文标题
- 🧠 论文逻辑梳理
- 1. 引言部分梳理 (动机与思想)
- 📝 三句话总结
- 🔍 方法逻辑梳理
- 🚀 关键创新点
- 🔗 方法流程图
- 关键疑问解答
- Q1、 Anchor 的来源、生成与训练中的作用?
- Q2 Anchor 尺寸大于感受野如何工作?
📄 论文标题
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick(fast R-CNN作者), and Jian Sun
团队:Microsoft Research
🧠 论文逻辑梳理
1. 引言部分梳理 (动机与思想)
| Aspect | Description (Motivation / Core Idea) |
|---|---|
| 问题背景 (Problem) | Fast R-CNN 已经很快了,但是它依赖的外部区域提议算法(如 Selective Search)运行在 CPU 上,速度很慢,成为了整个目标检测系统的性能瓶颈。而且,区域提议的计算与下游的检测网络是分离的,没有共享计算。 |
| 目标 (Goal) | 创建一个完全基于深度学习的、端到端的目标检测系统。具体来说,要设计一个内部的区域提议网络,使其能够与检测网络共享卷积特征,从而消除外部区域提议的瓶颈,实现高速且统一的检测框架。 |
| 核心思想 (Core Idea) | Faster R-CNN: 提出 区域提议网络 (Region Proposal Network, RPN)。RPN 是一个小型全卷积网络,它直接作用于主干网络(如 VGG/ResNet)输出的共享卷积特征图上,利用 Anchors 高效地预测出物体边界框提议及其“物体性”得分。这些提议随后被送入 Fast R-CNN 检测网络(使用同一份共享特征图)进行精确分类和位置修正。 |
| 核心假设 (Hypothesis) | 通过让 RPN 与检测网络共享底层的卷积计算,并将区域提议也用神经网络实现,可以构建一个统一、高效的框架,显著提升目标检测的速度(达到近实时),同时保持甚至提高检测精度。 |
📝 三句话总结
| 方面 | 内容 |
|---|---|
| ❓发现的问题 |
|
| 💡提出的方法 (R-CNN) |
|
| ⚡该方案的局限性/可改进的点 |
|
🔍 方法逻辑梳理
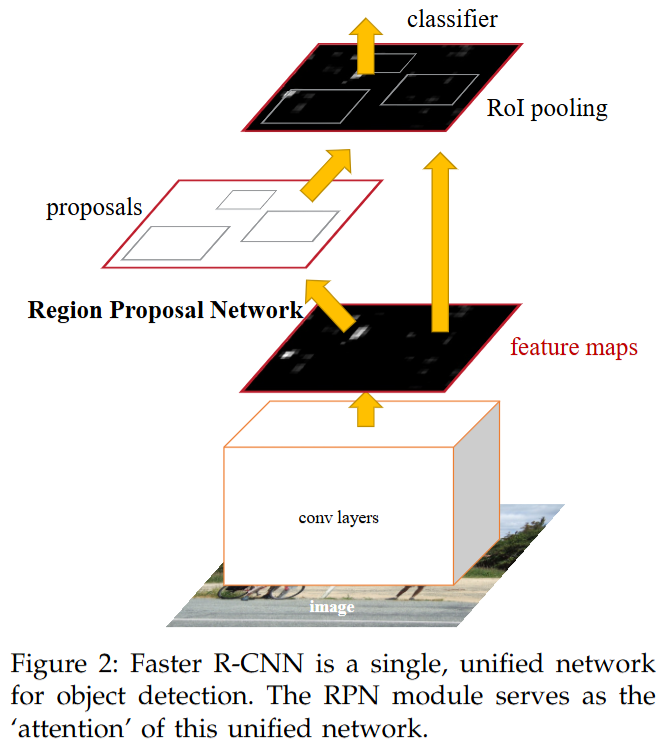
Faster R-CNN 是一个高度整合的统一网络。
-
模型输入:
- 一张
RGB图像。(不再需要外部 RoIs)
- 一张
-
处理流程 (Unified Network):
- 共享主干网络 (Shared Conv Backbone - Encoder 角色):
- 输入: 整张图像。
- 处理: 图像通过一系列卷积和池化层(如
VGG,ResNet的conv部分)。 - 输出: 整张图像的共享卷积特征图 (Shared Feature Map)。
- 区域提议网络 (Region Proposal Network - RPN - 特殊模块):
- 输入: 来自步骤 1 的共享特征图。
- 处理:
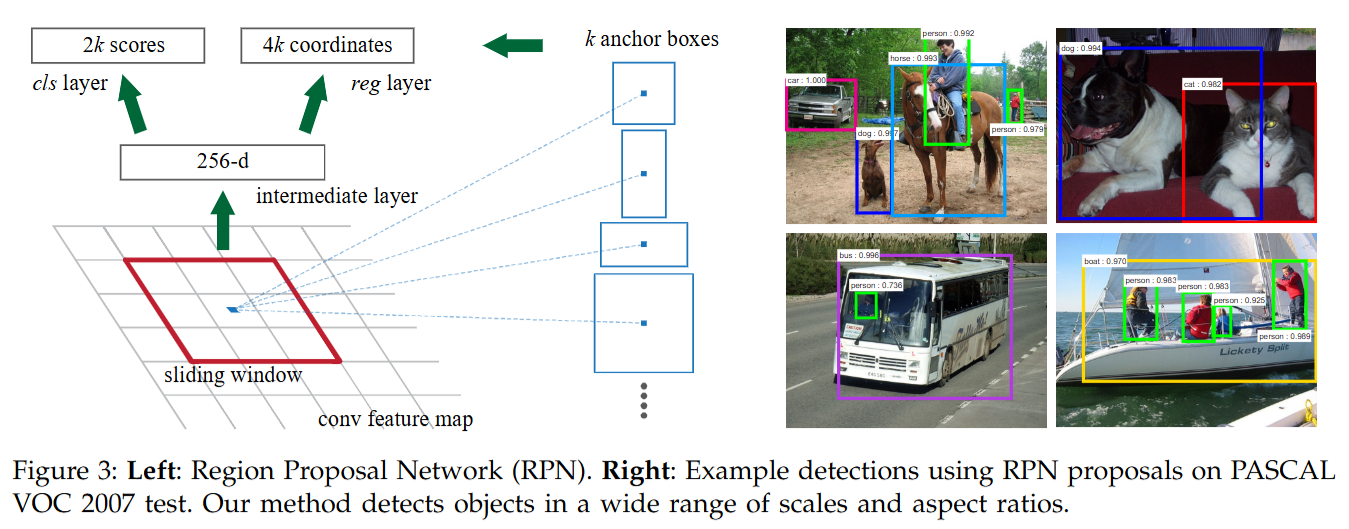
- 在特征图上滑动一个小型的卷积网络(如 3x3 卷积)。
- 在滑窗的每个位置,考虑 k 个预定义的 Anchors (不同尺度面积(128²、256²、512²)、长宽比(0.5、1、2))。
- 通过两个并行的 1x1 卷积(分类头和回归头)对每个 Anchor 进行预测:
- 预测 2k 个物体性得分 (Objectness Scores:
objectvs.background)。 - 预测 4k 个边界框回归偏移量 (relative to anchor)。
- 预测 2k 个物体性得分 (Objectness Scores:
- 基于物体性得分筛选
Anchors,应用回归偏移量修正坐标,得到初步的 Proposals。 - 对 Proposals 应用 NMS (非极大值抑制) 以减少冗余。【第一次使用NMS剔除多余的Anchors】
- 输出: 一组候选区域 RoIs (例如 ~300 或 ~2000 个,坐标是相对于原始图像的)。
- RoI Pooling / RoI Align 层 (特殊模块):
- 输入: 共享特征图 (来自步骤 1) + RPN 生成的 RoIs (来自步骤 2)。
- 处理: 对每个 RoI,从共享特征图中提取一个固定大小 (e.g., 7x7xC) 的特征图块。(
RoI Align效果通常更好) - 输出: 为每个 RoI 输出一个固定大小的特征图块。
- 检测头 (Detection Head - Fast R-CNN 部分 - Decoder/Prediction 角色):
- 输入: 来自
RoI Pooling/Align的固定大小特征图块。 - 处理:
- 通过全连接层 (
FClayers) 或卷积层进一步处理特征。 - 送入两个并行的输出层:
- Softmax 分类器 (输出 K+1 类概率 p p p)。
- 边界框回归器 (输出 K 类对应的 4 K 4K 4K 个回归偏移量 t k t^k tk)。
- 通过全连接层 (
- 输出: 对每个输入的 RoI,输出其最终的类别概率 p p p 和类别相关的回归偏移量 t k t^k tk。
- 输入: 来自
- 后处理 (Post-processing - NMS):
- 使用最终的类别分数和应用了回归偏移量后的边界框,再次进行
NMS(通常按类别进行)。 - 输出: 最终检测结果列表。
- 使用最终的类别分数和应用了回归偏移量后的边界框,再次进行
- 共享主干网络 (Shared Conv Backbone - Encoder 角色):
-
模型输出:
- 图像中检测到的物体列表,每个物体包含:类别标签、置信度分数、精修后的边界框坐标。
-
训练过程:
- 目标: 训练 RPN 网络学会生成高质量的 Proposals,同时训练检测头学会对这些 Proposals 进行精确分类和定位。
- 损失函数: 联合优化 RPN 的损失 ( L c l s R P N + λ 1 L r e g R P N L_{cls}^{RPN} + \lambda_1 L_{reg}^{RPN} LclsRPN+λ1LregRPN) 和 Fast R-CNN 检测头的损失 ( L c l s F a s t + λ 2 [ u > 0 ] L r e g F a s t L_{cls}^{Fast} + \lambda_2 [u>0] L_{reg}^{Fast} LclsFast+λ2[u>0]LregFast) 。总损失是这两部分损失的和(可能有权重因子)。
- 训练策略:
- 4步交替训练 (Alternating Training - 原始论文提出): 比较复杂,步骤间有权重固定和微调。
- 训练 RPN (用
ImageNet预训练模型初始化)。 - 训练 Fast R-CNN 检测网络 (用
ImageNet预训练模型初始化,使用第1步 RPN 生成的 proposals)。此时 ConvNet 独立训练。 - 固定共享的 ConvNet 层,只微调 RPN 的独有层。
- 固定共享的 ConvNet 层,只微调 Fast R-CNN 的独有层 (
FCs等)。
- 训练 RPN (用
- 近似联合训练 (Approximate Joint Training - 更常用): 在一次前向传播中计算 RPN 和 Fast R-CNN 的 proposals 和损失,然后将它们的损失加起来一起反向传播更新所有权重(包括共享卷积层)。实现上有一些细节处理 RPN proposal 对后续 loss 的影响。
- 端到端联合训练 (End-to-End Joint Training): 一些现代框架支持更彻底的端到端训练。
- 4步交替训练 (Alternating Training - 原始论文提出): 比较复杂,步骤间有权重固定和微调。
🚀 关键创新点
-
创新点 1: 区域提议网络 (Region Proposal Network - RPN)
- 为什么要这样做? 为了摆脱对外部、缓慢、与网络分离的区域提议算法(如
Selective Search)的依赖。 - 不用它会怎样? 目标检测系统的速度会被区域提议步骤严重拖慢,无法实现高速检测,且提议过程无法从深度特征学习中受益。RPN 是实现速度和整合的关键。
- 为什么要这样做? 为了摆脱对外部、缓慢、与网络分离的区域提议算法(如
-
创新点 2: 卷积特征共享 (Shared Convolutional Features)
- 为什么要这样做? 区域提议和物体检测都需要对图像进行特征提取,分开做是巨大的计算浪费。这两项任务可以基于相同的底层视觉特征。
- 不用它会怎样? 计算成本会高得多(如 R-CNN 或即使是将 SS 搬上 GPU 但仍独立计算的方案)。特征共享是 Faster R-CNN 实现效率飞跃的核心原因。
-
创新点 3: Anchor 机制
- 为什么要这样做? 需要一种方法让 RPN(一个相对简单的全卷积网络)能够高效地在特征图上直接预测出不同尺度、不同长宽比的物体提议。
- 不用它会怎样? RPN 可能难以直接预测如此多样化的边界框。Anchor 提供了一组有效的、多样的参考基准,极大地简化了 RPN 的预测任务,使其可以在单一尺度的特征图上工作,避免了图像金字塔或滤波器金字塔的复杂性。
-
创新点 4: 统一网络与端到端训练趋势
- 为什么要这样做? 将整个目标检测流程(除了
NMS等后处理)尽可能地统一到一个深度网络中,可以简化系统、提高效率,并可能通过联合优化提升性能。 - 不用它会怎样? 系统会保持多阶段、多模块的状态,训练和部署更复杂,速度也受限。Faster R-CNN 代表了向更整合、更端到端的检测系统迈出的决定性一步。
- 为什么要这样做? 将整个目标检测流程(除了
总结来说,Faster R-CNN 通过革命性的 RPN 和 Anchor 机制,并将 RPN 与 Fast R-CNN 检测器基于共享的卷积特征进行整合,最终构建了一个高效、准确且相对统一的目标检测框架,成为了后续许多现代检测器的基础。
🔗 方法流程图
关键疑问解答
Q1、 Anchor 的来源、生成与训练中的作用?
- 来源:
Anchors是预先定义好的超参数 (不同的尺度Scales和长宽比Aspect Ratios),不是根据当前数据集实时生成的。其设定基于经验或常见物体特性。 - 生成:
Anchors概念上是在 CNN 输出的最后一个特征图的每一个空间位置上生成的。每个位置都有一整套 (k 个) 不同规格的Anchors,它们的中心对应于特征图位置映射回原图的位置。这个生成发生在每次前向传播时。 - 训练作用:
Anchors作为参考基准。训练RPN的目标是:
1、分类: 判断每个 Anchor 是否覆盖了一个物体 (Objectness Score),通过与 Ground Truth Boxes 计算IoU来标记Anchor (正/负/忽略样本),并计算分类损失。
2、回归: 对于被标记为正样本的 Anchor,学习预测出将其精确调整到对应Ground Truth Box所需的4 个偏移量 (dx, dy, dw, dh),并计算回归损失 (通常用 Smooth L1 Loss)。网络学习的是预测“修正量”,而不是修改 Anchor 本身。
Q2 Anchor 尺寸大于感受野如何工作?
Anchor 是预测的参考框架,RPN 的预测是基于其感受野内的特征进行的。
网络学习的是将感受野内的局部特征与“应该使用哪种规格的 Anchor”以及“应该如何对该 Anchor 进行相对调整”这两者关联起来。
即使感受野小于 Anchor,内部特征也可能足够指示一个大物体的存在及大致的调整方向。对于大物体,多个相邻位置的预测会共同作用。【管中窥豹,可知豹外貌】