「图文互搜+情感分析」聚客AI前沿技术拆解:用Hugging Face玩转多模态AI大模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。
1. 多模态机器学习与典型任务
1.1 什么是多模态机器学习?
多模态机器学习(Multimodal Machine Learning)通过融合文本、图像、音频、视频等不同模态的数据,使模型具备更全面的感知和推理能力。其核心目标是解决模态异构性(不同数据类型的差异)和信息互补性(多模态联合建模提升性能)。
典型任务分类:
视觉-语言任务
-
图像描述生成(Image Captioning):输入一张图片,生成自然语言描述。
-
视觉问答(VQA):根据图片内容回答问题,例如:“图中天空是什么颜色?”
-
跨模态检索:以文搜图或以图搜文,如CLIP模型。
-
音频-语言任务
-
语音情感识别:通过语音的音调、语速等特征判断情绪(如愤怒、喜悦)。
-
语音翻译:将中文语音实时转换为英文文本。
-
多模态生成任务
-
文本到图像生成:如Stable Diffusion根据文本生成高质量图片。
-
视频合成:结合剧本生成带场景、动作和配音的视频片段。
代码示例:图像描述生成(基于Hugging Face)
from transformers import pipeline
# 加载预训练模型
image_to_text = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning")
caption = image_to_text("cat.jpg")[0]['generated_text']
print(f"图片描述: {caption}") # 输出示例:A cat is sitting on a sofa.2. 跨模态预训练
2.1 核心思想与关键技术
跨模态预训练通过自监督学习(Self-supervised Learning)从大规模数据中学习模态间的关联性,典型方法包括:
-
对比学习(Contrastive Learning):如CLIP模型,将匹配的图文对拉近,不匹配的推远。
-
掩码建模(Masked Modeling):如BERT的MLM任务,随机掩盖部分输入,让模型预测缺失内容。
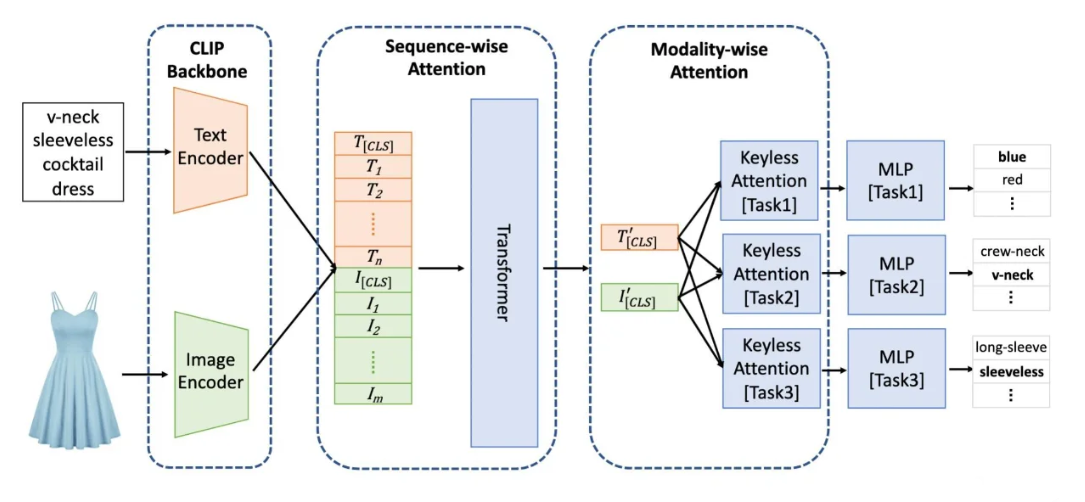
模型架构:
-
双塔结构:文本和图像分别编码后计算相似度(如CLIP)。
-
单塔结构:多模态输入共享同一编码器(如UNITER)。
-
代码示例:图文检索(基于CLIP)
import torch
from PIL import Image
from transformers import CLIPProcessor, CLIPModel
# 加载模型
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 输入处理
image = Image.open("beach.jpg")
texts = ["a photo of a beach", "a photo of a mountain"]
# 计算相似度
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
probs = outputs.logits_per_image.softmax(dim=1)
print(f"匹配概率: {probs}") # 输出示例:tensor([[0.92, 0.08]])3. 跨模态交互:Language-Audio/Vision-Audio/Vision-Language
3.1 Vision-Language-Action(VLA)
应用场景:自动驾驶、机器人控制。模型输入视觉和语言指令,输出动作序列。
-
核心技术:
-
思维链(Chain-of-Thought):分步推理,例如“检测红灯→刹车→等待”。
-
时空建模:处理视频流中的连续动作。
-
代码示例:VLA动作生成(简化版)
import torch
import torch.nn as nn
class VLA(nn.Module):def __init__(self, vision_dim=512, text_dim=512, action_dim=4):super().__init__()self.vision_proj = nn.Linear(vision_dim, 256)self.text_proj = nn.Linear(text_dim, 256)self.fusion = nn.Transformer(d_model=256, nhead=8)self.action_head = nn.Linear(256, action_dim)def forward(self, vision_feat, text_feat):vision_emb = self.vision_proj(vision_feat)text_emb = self.text_proj(text_feat)fused = self.fusion(torch.cat([vision_emb, text_emb], dim=1))action = self.action_head(fused.mean(dim=1))return action
# 示例输入
vision_feat = torch.randn(1, 512) # 图像特征
text_feat = torch.randn(1, 512) # 文本特征
model = VLA()
action = model(vision_feat, text_feat)
print(f"动作向量: {action.shape}") # 输出:torch.Size([1, 4])3.2 Vision-Audio融合
应用场景:视频内容理解、语音增强。
-
关键技术:
-
时频分析:将音频信号转换为频谱图,使用CNN处理。
-
多模态对齐:如IMTFF-Networks通过时间同步对齐视觉和音频特征。
-
代码示例:音频分类(基于Librosa)
import librosa
import torch
from torch import nn
# 提取MFCC特征
audio, sr = librosa.load("speech.wav", sr=16000)
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=40)
mfcc_tensor = torch.tensor(mfcc).unsqueeze(0) # 输入维度:(1, 40, 时间步)
# 简单分类模型
class AudioClassifier(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv1d(40, 64, kernel_size=3)self.fc = nn.Linear(64, 5) # 5类情感def forward(self, x):x = torch.relu(self.conv(x))x = x.mean(dim=2) # 全局平均池化return self.fc(x)
model = AudioClassifier()
output = model(mfcc_tensor)
print(f"分类结果: {torch.softmax(output, dim=1)}")4. 定位相关任务
4.1 视觉定位(Visual Grounding)
任务定义:根据文本描述在图像中定位目标物体。例如:“左侧穿红色衣服的人”。
技术方法:
区域特征提取:使用Faster R-CNN提取候选框特征。
跨模态匹配:计算文本特征与候选框特征的相似度。
代码示例:视觉定位(基于Faster R-CNN)
import torchvision
from torchvision.models.detection import fasterrcnn_resnet50_fpn
# 加载预训练模型
model = fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
# 输入处理
image = torch.rand(3, 800, 1200) # 模拟输入图像
predictions = model([image])
print(f"检测框: {predictions[0]['boxes']}") # 输出边界框坐标4.2 时空定位(视频动作检测)
应用场景:在长视频中定位特定动作的时间段。
技术方案:
-
TSN(Temporal Segment Networks):将视频分段处理,融合时序特征。
-
3D CNN:直接处理视频的时空维度。
-
5. 情感计算(Affect Computing)
5.1 多模态情感分析
技术流程:
特征提取:
-
文本:BERT提取情感关键词。
-
语音:MFCC、音高、语速。
-
视觉:OpenCV提取面部表情(如嘴角弧度、眉毛动作)。
-
融合与分类:拼接多模态特征后输入分类器。
代码示例:情感分类(融合文本与语音)
from transformers import BertModel, BertTokenizer
import torch
# 文本特征提取
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text_model = BertModel.from_pretrained("bert-base-uncased")
text_input = tokenizer("I feel happy today", return_tensors="pt")
text_feat = text_model(**text_input).last_hidden_state.mean(dim=1)
# 假设已有语音特征audio_feat
multimodal_feat = torch.cat([text_feat, audio_feat], dim=1)
classifier = nn.Linear(768 + 128, 3) # 3类情感
output = classifier(multimodal_feat)
print(f"情感概率: {torch.softmax(output, dim=1)}")注:本文代码均为简化示例,完整实现需结合具体数据和调参优化。