技术视界 | 数据的金字塔:从仿真到现实,机器人学习的破局之道
在人工智能的世界里,有一个共识正逐渐达成——谁掌握了数据,谁就掌握了未来。
尤其是在机器人技术迅速演进的今天,“如何让机器人理解世界、学习操作”这一问题的根源,越来越回归到数据本身。正如一座金字塔般,不同层次的数据类型,代表着不同的成本、能力与局限。理解这座“数据金字塔”,正在成为打开机器人智能时代的关键。
什么是数据金字塔?
我们可以将数据按照“成本”和“价值”的维度,分为以下三层:
1️⃣ 底层:互联网数据
- 获取门槛最低,数量庞大,类型多样;
- 包括图文、视频、开源代码、教程、百科等;
- 优势在于广覆盖与低成本,劣势是质量不均、缺乏物理语义对齐。
2️⃣ 中层:仿真数据
- 可以控制环境变量、高效生成;
- 适用于训练策略、还原极端场景;
- 但仿真与现实之间存在不可忽视的物理差异,特别在机器人领域尤为明显。
3️⃣ 顶层:真实数据
- 从真实机器人交互中采集,物理精准、任务语义完整;
- 获取成本高、标注难,但在任务泛化、精度要求上拥有无可替代的价值。
这一金字塔,也正是机器人学习进化的路线图。而在这条路上,如何选择、组合不同的数据类型,成了突破的关键。
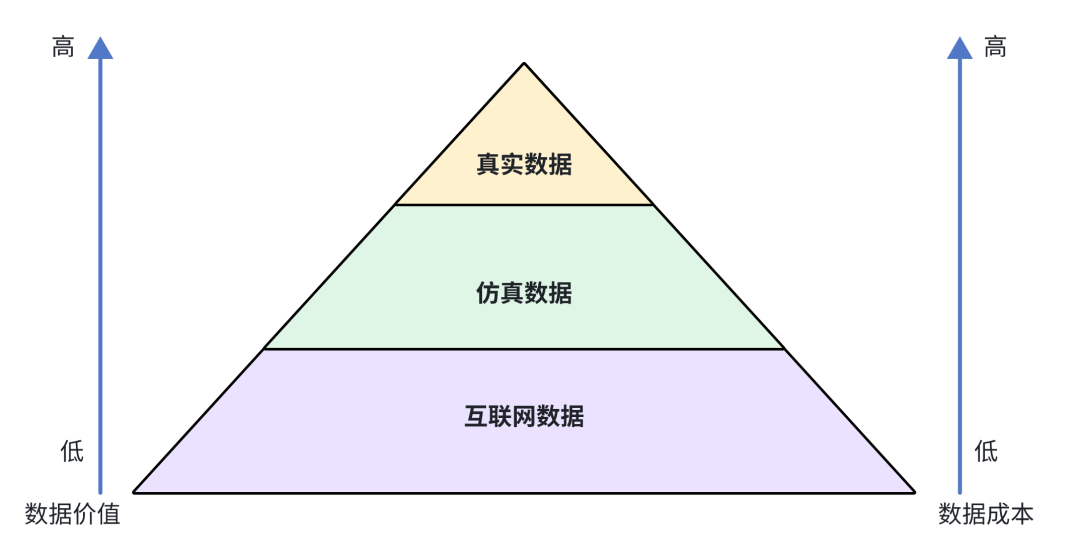
自动驾驶 vs 机器人:仿真数据的“理想与现实”
自动驾驶是一个很好的例子。想象一个场景:一只猫突然从路边窜出来——这种危险但罕见的“极端案例”(corner case),靠真实采集几乎不可能高效完成,但在仿真系统里却能轻松复现、无限重播。这正是仿真的价值所在。
但当我们把视角转向机器人,尤其是涉及复杂物理交互的操作任务时,事情就没那么简单了:
比如,机器人抓取一个柔软物体。现实中,一个物体因材质、湿度、重心分布不同,抓取时可能发生滑落;机器人需要实时感知并调整手部姿态、力量大小,才能成功抓取,而当前仿真系统尚难完整还原这类复杂的物理动态变化。
因此,尽管仿真在策略学习上具有巨大优势,但在复杂物理交互的技能迁移上,依然存在“天花板”。
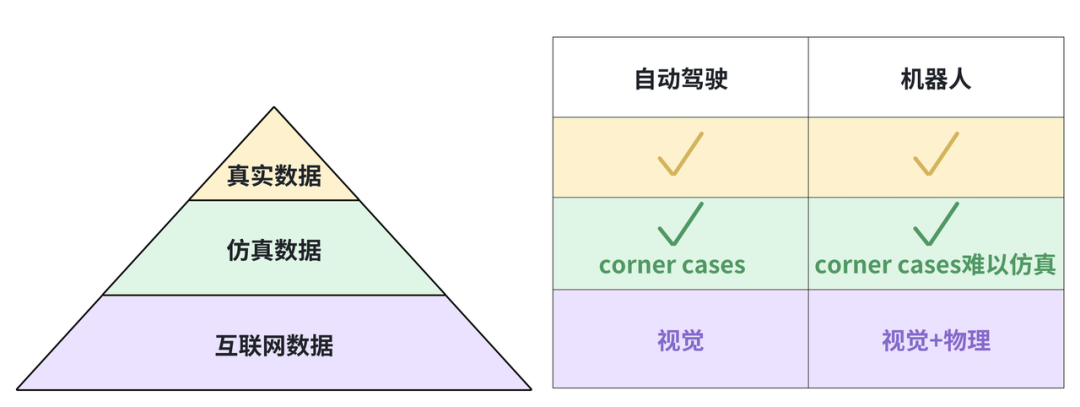
两个关键维度:Sim2Real 与技能复杂性
北京大学的董豪老师提出,在机器人技术中,有两个核心挑战维度:
Sim2Real:仿真数据能否迁移到现实?
技能复杂性:这个数据能支持多复杂的任务?
这两个维度组合后,我们可以将数据进一步划分为四类:
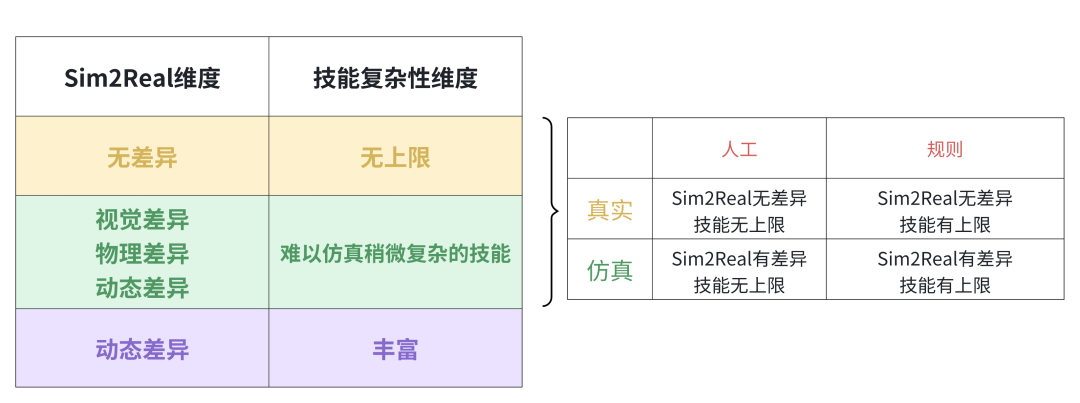
这个视角带来的启示是:单一数据形式很难支撑机器人智能的大规模跃迁,组合、对齐、策略协同是必然之路。
四种数据策略:优劣与适用场景分析
那么,面对现实,我们有哪些可行的数据策略?
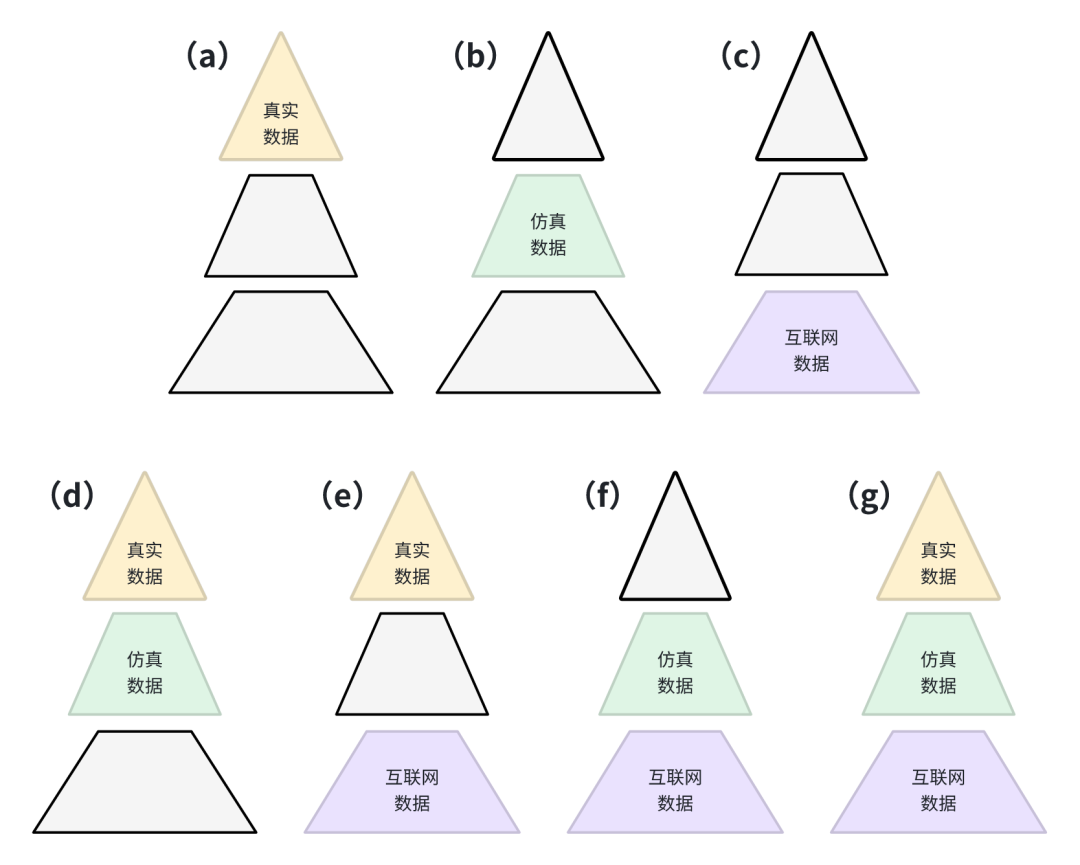
只用真实数据:成本高,通用性强
这是最稳妥的方法,也是理想路径。从第一性原理看,如果我们能低成本收集到足够多的真实数据,理论上可以完全摆脱仿真和互联网数据的依赖。这听起来像是“终极解决方案”。但真实数据的获取成本高,需要需大量人工或遥操作,还需要繁琐的标注、清洗流程。
只用仿真数据:快,但有上限
适用于初创项目、算法验证或单一场景任务,是很多RL研究中的默认选择。仿真数据生成快、结构标准、便于控制。但它不适用于高物理复杂度的场景,容易在复杂任务上“撞墙”。
只用互联网数据:覆盖广,落地难
互联网数据的丰富性是宝藏,但它与实际机器人场景的物理语义对齐度较低,与机器人的真实环境之间存在巨大语义和物理鸿沟。它可以用于预训练模型,但不适合直接用于控制或决策。
多模态融合策略:All-in-One
未来最主流的方向,或许是将三类数据按任务类型、阶段特征有机融合:
- 用互联网数据做知识迁移;
- 用仿真数据造场景和做训练;
- 用真实数据来收敛策略、精调模型。
这种分层使用的方式,不仅提升了效率,也最大化了不同数据的价值。这也是未来“多模态机器人”真正具身智能的基石。
数据不是目的,而是让机器人更聪明的“燃料”
我们常说“数据是新石油”,但对机器人来说,更贴切的比喻是——
数据是大脑得以点亮的电力,是躯体行动的神经信号。
不同的数据类型,并非互相替代,而应彼此配合,构成通向“具身智能”时代的梯子。
未来,随着远程遥操作平台、数据对齐算法、物理仿真引擎的进步,我们或许会走向一个真正的数据融合时代。到那时,机器人或许真的能像人类一样,在信息、世界和操作之间自如穿梭。
如果你也对具身智能、机器人数据栈感兴趣,欢迎关注我们,一起探索从仿真走向现实的技术之路。