使用PyTorch如何配置一个简单的GTP
目录
一、什么是GPT
1. Transformer Block 的核心结构
2. 关键组件解析
(1) 掩码多头自注意力(Masked Multi-Head Self-Attention)
(2) 前馈神经网络(FFN)
(3) 层归一化(LayerNorm)
(4) 残差连接(Residual Connection)
3.代码
1. 为什么需要位置编码?
2. 位置编码的数学形式
关键特性
3.代码
(1) 初始化部分
(2) 前向传播
四、Encoder(Transofermer编码器)模块
1. Transformer 编码器的作用
2. 核心设计思想
(1) 多层堆叠(n_layers)
(2) 残差连接与层归一化
(3) 自注意力机制(Self-Attention)
(4) 前馈神经网络(FFN)
(1) 初始化部分
(2) 前向传播
五、GPT模型
1. GPT 的核心思想
关键特性
2. 模型架构解析
(1) 输入表示
(2) Transformer 编码器堆叠(encoder)
(3) 输出层(generator)
(4) 掩码机制(generate_square_subsequent_mask)
3. 关键设计细节
(1) 权重初始化(_init_weights)
(2) 输入输出流程
4.代码
六、AdamWarmupCosineDecay 优化器模块
1. 优化器的核心目标
2. 关键设计解析
(1) AdamW 基础
(2) 学习率调度策略
① 线性预热(Warmup)
② 余弦衰减(Cosine Decay)
(3) 参数分组与权重衰减
3.代码
七、create_optimizer 函数
1.代码
2. 核心设计目标
3. 关键设计解析
(1) 参数分组策略
① 识别需衰减的参数
② 分组实现
(2) 理论依据
为什么不对所有参数衰减?
AdamW 的权重衰减解耦
(3) 学习率调度集成
3. 代码执行流程
如果不了解Transformer的可以先去看看:
一口气看完从零到一构建transformer架构代码一:多头注意力机制_transformer 多头注意力机制代码-CSDN博客
一口气看完从零到一构建transformer架构代码二:位置编码模块-CSDN博客
一口气看完从零到一构建transformer架构代码三:编码器和解码器-CSDN博客
一、什么是GPT
GPT(Generative Pre-trained Transformer) 是一种基于 Transformer 架构 的大规模预训练语言模型,由 OpenAI 开发。它的核心思想是通过海量文本数据的预训练,学习语言的通用规律,再通过微调(Fine-tuning)适应具体任务(如问答、写作、翻译等)。
二、Transformer Block模块
1. Transformer Block 的核心结构
该模块遵循 "Pre-LN"(LayerNorm在前) 的架构(与原始 Transformer 的 "Post-LN" 不同),包含两个核心子层:
- 掩码多头自注意力(Masked Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Network, FFN)
每个子层均包含 残差连接(Residual Connection) 和 层归一化(Layer Normalization)。
2. 关键组件解析
(1) 掩码多头自注意力(Masked Multi-Head Self-Attention)
- 作用:让模型动态关注输入序列中不同位置的信息,并避免未来信息泄露(自回归特性)。
- 实现:
- 使用
nn.MultiheadAttention实现多头注意力。 - 通过
attn_mask参数传入上三角掩码(-inf),确保解码时只能看到当前位置及之前的信息。
- 使用
- 数学形式:
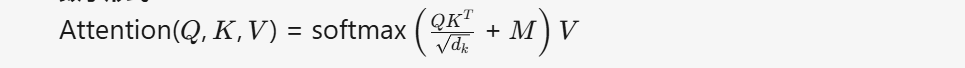
- M 是掩码矩阵(上三角为
-inf,其余为0)。 - dk 是注意力头的维度(
d_model // n_head)。
- M 是掩码矩阵(上三角为
(2) 前馈神经网络(FFN)
- 作用:对注意力输出进行非线性变换,增强模型表达能力。
- 实现:
- 两层线性层 + GELU 激活:
d_model → d_ff → d_model。 - 典型扩展比:
d_ff = 4 * d_model(例如d_model=768,d_ff=3072)。
- 两层线性层 + GELU 激活:
- 为什么用 GELU?
GELU(Gaussian Error Linear Unit)比 ReLU 更平滑,接近大脑神经元的激活特性,被 GPT 系列广泛采用。
(3) 层归一化(LayerNorm)
- 作用:稳定训练过程,缓解梯度消失/爆炸。
- 位置:
- Pre-LN:在子层(注意力/FFN)之前 进行归一化(现代架构主流,如 GPT-3)。
- (对比原始 Transformer 的 Post-LN:在子层之后归一化,容易梯度不稳定)
- 公式:

- μ,σ 沿特征维度计算,γ,β 是可学习参数。
(4) 残差连接(Residual Connection)
- 作用:缓解深层网络梯度消失,保留原始信息。
- 实现:
output = x + dropout(sublayer(x))- 先对子层输出应用 Dropout,再与输入相加。
- Dropout 在训练时随机关闭部分神经元,防止过拟合。
3.代码
class TransformerBlock(nn.Module):"""单个Transformer块包含掩码多头注意力和前馈网络"""def __init__(self, d_model: int, n_head: int, d_ff: int, dropout: float = 0.1):super().__init__()# 层归一化self.ln1 = nn.LayerNorm(d_model) # 第一个层归一化(注意力前)self.ln2 = nn.LayerNorm(d_model) # 第二个层归一化(前馈网络前)# 多头注意力机制self.attn = nn.MultiheadAttention(d_model, n_head, dropout=dropout)# 前馈网络(包含GELU激活)self.ffn = nn.Sequential(nn.Linear(d_model, d_ff), # 扩展维度nn.GELU(), # GELU激活函数nn.Linear(d_ff, d_model), # 降回原维度nn.Dropout(dropout) # 随机失活)self.dropout = nn.Dropout(dropout) # 残差连接的dropoutdef forward(self, x: torch.Tensor, mask: torch.Tensor = None) -> torch.Tensor:# 自注意力部分(带残差连接和层归一化)attn_output, _ = self.attn(x, x, x, attn_mask=mask) # 自注意力计算x = x + self.dropout(attn_output) # 残差连接x = self.ln1(x) # 层归一化# 前馈网络部分(带残差连接和层归一化)ffn_output = self.ffn(x) # 前馈网络计算x = x + self.dropout(ffn_output) # 残差连接x = self.ln2(x) # 层归一化return x三、PositionalEncoding(位置编码)模块
这段代码实现了 Transformer 模型中的位置编码(Positional Encoding),用于向输入序列注入位置信息,弥补 Transformer 自注意力机制本身不具备的 时序感知能力。以下是其背后的 核心理论 和 设计原理:
1. 为什么需要位置编码?
Transformer 的 Self-Attention 机制 是 置换不变(Permutation Invariant) 的,即它对输入序列的顺序不敏感。例如:
- 输入序列
[A, B, C]和[B, A, C]在 Self-Attention 中的计算结果可能相同(如果不考虑位置信息)。 - 但自然语言、时间序列等数据 严重依赖顺序(如 "猫吃鱼" ≠ "鱼吃猫")。
位置编码的作用:显式地告诉模型每个词的位置,使其能区分 "I love NLP" 和 "NLP love I"。
2. 位置编码的数学形式
代码中的位置编码采用 正弦(Sine)和余弦(Cosine) 函数的组合,其公式为:
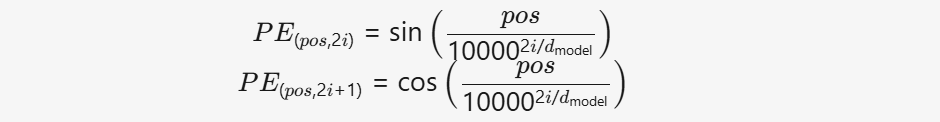
其中:
- pos:词在序列中的位置(0, 1, 2, ..., seq_len-1)。
- i:维度索引(0 ≤ i < dmodel/2)。
- dmodel:词向量的维度(如 512、768 等)。
关键特性
- 不同频率的正弦/余弦函数:
- 高频(i 较大):捕捉局部位置关系(如相邻词)。
- 低频(i 较小):捕捉全局位置关系(如段落/句子级顺序)。
- 相对位置可学习:
- 通过三角函数的线性组合,模型可以学习到相对位置关系(如
pos + k的位置编码可以表示为PE(pos)的线性函数)。
- 通过三角函数的线性组合,模型可以学习到相对位置关系(如
- 值范围固定:
- 正弦/余弦函数的输出在
[-1, 1]之间,不会因序列长度增长而数值爆炸。
- 正弦/余弦函数的输出在
3.代码
class PositionalEncoding(nn.Module):"""位置编码模块通过正弦和余弦函数为输入嵌入添加位置信息"""def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):super().__init__()self.dropout = nn.Dropout(p=dropout) # 随机失活层# 计算位置编码position = torch.arange(max_len).unsqueeze(1) # 位置序列 [max_len, 1]div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) # 除数项pe = torch.zeros(max_len, 1, d_model) # 初始化位置编码矩阵pe[:, 0, 0::2] = torch.sin(position * div_term) # 偶数位置使用正弦函数pe[:, 0, 1::2] = torch.cos(position * div_term) # 奇数位置使用余弦函数self.register_buffer('pe', pe) # 注册为缓冲区,不参与梯度更新def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播参数:x: 输入张量,形状 [seq_len, batch_size, embedding_dim]"""x = x + self.pe[:x.size(0)] # 添加位置编码return self.dropout(x) # 应用dropout(1) 初始化部分
position = torch.arange(max_len).unsqueeze(1) # 位置序列 [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term) # 偶数维度:sin
pe[:, 0, 1::2] = torch.cos(position * div_term) # 奇数维度:cos
self.register_buffer('pe', pe) # 不参与梯度更新- **
div_term的计算**:- 等价于 1/(10000**(2i/dmodel)),用于控制不同维度的频率。
- 使用
torch.exp和log避免数值不稳定。
- **
pe的填充**:- 偶数维度(
0::2)填充sin,奇数维度(1::2)填充cos。
- 偶数维度(
- **
register_buffer**:- 将
pe注册为模型的 缓冲区(不参与梯度更新),因为它是一个固定的编码表。
- 将
(2) 前向传播
x = x + self.pe[:x.size(0)] # 添加位置编码
return self.dropout(x) # 添加Dropout- 加法操作:
- 直接将位置编码加到输入词嵌入上(
x的形状为[seq_len, batch_size, d_model])。
- 直接将位置编码加到输入词嵌入上(
- Dropout:
- 对位置编码后的结果进行随机失活,增强鲁棒性(原始论文中未使用,但现代实现常用)。
四、Encoder(Transofermer编码器)模块
这段代码实现了一个标准的 Transformer 编码器(Encoder),它由多个 TransformerBlock(Transformer 块)堆叠而成,是 GPT、BERT 等现代 Transformer 架构的核心组件。
1. Transformer 编码器的作用
- 输入:经过词嵌入(Word Embedding)和位置编码(Positional Encoding)的序列。
- 输出:每个位置的 上下文感知表示(Contextualized Representation),即每个词的向量不仅包含自身信息,还融合了全局序列信息。
- 典型应用:
- 自回归模型(如 GPT):用于生成任务(每次预测下一个词)。
- 双向模型(如 BERT):用于理解任务(同时利用左右上下文)。
2. 核心设计思想
(1) 多层堆叠(n_layers)
- 每个
TransformerBlock包含:- 自注意力机制(Self-Attention):捕捉序列内词与词的关系。
- 前馈神经网络(FFN):增强非线性表达能力。
- 深层堆叠的意义:
- 低层:学习局部语法和短语级特征(如词性、短语句法)。
- 高层:学习全局语义和篇章级特征(如指代消解、逻辑关系)。
- 实验结论:
- 模型性能通常随层数增加而提升(但需权衡计算成本)。
- 例如:
- GPT-3:96 层。
- BERT-base:12 层。
(2) 残差连接与层归一化
- 残差连接(Residual Connection):
- 每层的输出 = 输入 + 子层输出(如
x + self.attn(x))。 - 作用:缓解梯度消失,使深层网络可训练。
- 每层的输出 = 输入 + 子层输出(如
- 层归一化(LayerNorm):
- 对每个样本的特征维度进行归一化(区别于 BatchNorm)。
- 作用:稳定训练过程,加速收敛。
(3) 自注意力机制(Self-Attention)
- 核心公式:

- Q,K,V 分别由输入线性变换得到。
- dk 用于缩放点积,防止梯度爆炸。
- 多头注意力(Multi-Head):
- 并行运行多组注意力头,捕捉不同模式的关系(如语法、语义、指代等)。
- 最终拼接所有头的输出并通过线性层融合。
(4) 前馈神经网络(FFN)
- 结构:两层全连接层 + 激活函数(如 GELU)。
- 扩展维度:
d_model → d_ff(通常d_ff = 4 * d_model)。 - 收缩维度:
d_ff → d_model。
- 扩展维度:
- 作用:
- 引入非线性变换,增强模型容量。
- 独立处理每个位置的信息(与注意力机制的交互互补)。
class Encoder(nn.Module):"""Transformer编码器由多个Transformer块堆叠而成"""def __init__(self, n_layers: int, d_model: int, n_head: int, d_ff: int, dropout: float = 0.1):super().__init__()# 创建多个Transformer块self.layers = nn.ModuleList([TransformerBlock(d_model, n_head, d_ff, dropout)for _ in range(n_layers)])def forward(self, x: torch.Tensor, mask: torch.Tensor = None) -> torch.Tensor:# 逐层处理输入for layer in self.layers:x = layer(x, mask)return x(1) 初始化部分
self.layers = nn.ModuleList([TransformerBlock(d_model, n_head, d_ff, dropout)for _ in range(n_layers)
])- **
nn.ModuleList**:- 用于存储多个
TransformerBlock,确保 PyTorch 能正确注册子模块的参数。
- 用于存储多个
- 参数传递:
d_model:隐藏层维度(如 768)。n_head:注意力头数(如 12)。d_ff:FFN 中间层维度(如 3072)。dropout:随机失活率(如 0.1)。
(2) 前向传播
for layer in self.layers:x = layer(x, mask)
return x- 逐层处理:
- 输入
x依次通过所有TransformerBlock。 - 每层的输出是下一层的输入(类似于 ResNet)。
- 输入
- 掩码(
mask):- 在自回归模型(如 GPT)中,使用上三角掩码防止未来信息泄露。
- 在双向模型(如 BERT)中,可忽略或用于 padding 掩码。
五、GPT模型
这段代码实现了一个 GPT(Generative Pre-trained Transformer) 模型的核心架构,属于 Decoder-only Transformer 类型,是现代大语言模型(如 ChatGPT、GPT-3/4)的基础。以下是其背后的 核心理论 和 设计原理:
1. GPT 的核心思想
GPT 是一个 自回归(Autoregressive) 语言模型,其核心任务是:
给定前文的词序列,预测下一个词的概率分布。
例如:
输入 "The cat sat on the" → 预测下一个词可能是 "mat"。
关键特性
- 单向注意力:只能看到当前词及之前的词(通过掩码实现)。
- 生成式预训练:在大规模文本上预训练,学习语言的通用模式。
- 微调适配:可通过微调适应具体任务(如问答、摘要)。
2. 模型架构解析
(1) 输入表示
- 词嵌入(
token_embed):- 将词索引映射为稠密向量(维度
d_model)。 - 例如:
"cat"→[0.2, -0.5, ..., 0.7](d_model维)。
- 将词索引映射为稠密向量(维度
- 位置编码(
pos_embed):- 通过正弦/余弦函数注入位置信息,解决 Transformer 的置换不变性问题。
- 公式:

(2) Transformer 编码器堆叠(encoder)
- 由多个
TransformerBlock组成(层数n_layers)。 - 每个
TransformerBlock包含:- 掩码多头自注意力:计算当前词与前文词的关系(掩码防止未来信息泄露)。
- 前馈网络(FFN):两层全连接层 + GELU 激活。
- 残差连接 + LayerNorm:稳定训练过程。
- 输入输出形状:
- 输入:
[seq_len, batch_size, d_model](需转置以适应 PyTorch 的MultiheadAttention)。 - 输出:每个位置的上下文表示。
- 输入:
(3) 输出层(generator)
- 线性投影:将
d_model维向量映射到词表大小n_tokens。 - 输出:
[batch_size, seq_len, n_tokens],表示每个位置对词表的预测概率。 - 通过
softmax转换为概率分布(代码中未显式写出,通常在损失函数中处理)。
(4) 掩码机制(generate_square_subsequent_mask)
- 作用:确保自回归性质,模型只能看到当前词及之前的词。
- 实现:
- 生成上三角矩阵(
-inf),下三角和对角线为0。 - 例如,序列长度为 3 的掩码:000−∞00−∞−∞0
- 生成上三角矩阵(
- 数学意义:在注意力计算中,
-inf会使对应位置的权重趋近于 0。
3. 关键设计细节
(1) 权重初始化(_init_weights)
- 线性层/嵌入层:权重初始化为
N(0, 0.02),偏置初始化为0。 - 目的:
- 避免梯度爆炸或消失。
- 与原始 GPT 论文保持一致。
(2) 输入输出流程
- 输入序列:
[batch_size, seq_len](词索引)。 - 词嵌入:
[batch_size, seq_len, d_model]。 - 位置编码:与词嵌入相加。
- 转置:
[seq_len, batch_size, d_model](适应 PyTorch 的注意力机制)。 - Transformer 编码器:逐层处理。
- 转置恢复:
[batch_size, seq_len, d_model]。 - 输出投影:
[batch_size, seq_len, n_tokens]。
4.代码
class GPT(nn.Module):"""GPT模型(解码器-only架构)包含:1. 词嵌入 + 位置编码2. Transformer编码器堆叠3. 输出线性层"""def __init__(self, n_tokens: int, d_model: int, n_layers: int, n_head: int, d_ff: int, dropout: float = 0.1):super().__init__()# 词嵌入层self.token_embed = nn.Embedding(n_tokens, d_model)# 位置编码层self.pos_embed = PositionalEncoding(d_model, dropout)# Transformer编码器self.encoder = Encoder(n_layers, d_model, n_head, d_ff, dropout)# 输出线性层(词表大小)self.generator = nn.Linear(d_model, n_tokens)# 初始化权重self.apply(self._init_weights)# 掩码将在前向传播时创建self.mask = Nonedef _init_weights(self, module):"""权重初始化(GPT风格)"""if isinstance(module, (nn.Linear, nn.Embedding)):# 线性层和嵌入层权重初始化为N(0, 0.02)module.weight.data.normal_(mean=0.0, std=0.02)# 如果有偏置项,初始化为0if isinstance(module, nn.Linear) and module.bias is not None:module.bias.data.zero_()def forward(self, x: torch.Tensor) -> torch.Tensor:# 创建后续掩码(如果不存在或尺寸不匹配)if self.mask is None or self.mask.size(0) != x.size(1):self.mask = self.generate_square_subsequent_mask(x.size(1)).to(x.device)# 获取词嵌入并添加位置编码x = self.token_embed(x) # [batch_size, seq_len, d_model]x = x.transpose(0, 1) # [seq_len, batch_size, d_model](Transformer要求的输入格式)x = self.pos_embed(x) # 添加位置编码# 通过Transformer编码器x = self.encoder(x, self.mask)# 生成输出概率x = x.transpose(0, 1) # 恢复为[batch_size, seq_len, d_model]x = self.generator(x) # 线性投影到词表空间return x@staticmethoddef generate_square_subsequent_mask(sz: int) -> torch.Tensor:"""生成上三角掩码(防止看到未来信息)"""return torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1)六、AdamWarmupCosineDecay 优化器模块
这段代码实现了一个 结合预热(Warmup)和余弦衰减(Cosine Decay)的 AdamW 优化器,是训练 GPT 等大型 Transformer 模型的核心组件之一。以下是其背后的 设计原理 和 理论依据:
1. 优化器的核心目标
在训练深度学习模型(尤其是大语言模型)时,学习率调度 对模型性能至关重要。该优化器通过以下策略平衡训练稳定性和收敛速度:
- 预热阶段:从小学习率逐步增大,避免早期训练不稳定。
- 余弦衰减阶段:平滑降低学习率,帮助模型精细调参。
2. 关键设计解析
(1) AdamW 基础
- AdamW 是 Adam 的改进版,解耦权重衰减(Weight Decay) 和梯度更新:
- 传统 Adam:权重衰减与梯度混合计算。
- AdamW:将权重衰减单独处理,更接近原始 SGD 的 L2 正则化。
- 参数:
betas=(0.9, 0.95):一阶/二阶矩估计的指数衰减率。eps=1e-8:数值稳定项。weight_decay=0.01:权重衰减系数。
(2) 学习率调度策略
① 线性预热(Warmup)
- 作用:
模型参数初始随机时,大学习率易导致梯度爆炸或不稳定。预热阶段从小学习率逐步增大,让参数先探索合理的初始方向。 - 公式:

warmup_steps:预热总步数(如 2000 步或总步数的 10%)。- 例如:
base_lr=6e-4,当前步 1000 →lr = 6e-4 * 1000/2000 = 3e-4。
② 余弦衰减(Cosine Decay)
- 作用:
预热后,学习率按余弦曲线平滑下降,避免突变导致的训练震荡。 - 公式:
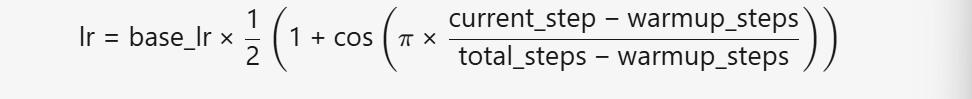
- 从
base_lr缓慢衰减到接近0。 - 曲线平滑,利于模型收敛到更优解。
- 从
(3) 参数分组与权重衰减
- 权重衰减的应用:
- 仅对 线性层的权重 应用衰减(如
nn.Linear.weight)。 - 忽略 偏置项 和 层归一化参数(通过
create_optimizer实现分组)。
- 仅对 线性层的权重 应用衰减(如
- 目的:
避免对不应正则化的参数施加约束,提升模型泛化性。
3.代码
class AdamWarmupCosineDecay(torch.optim.AdamW):"""带预热和余弦衰减的AdamW优化器GPT训练常用配置:- 初始学习率6e-4- 权重衰减0.1(仅应用于特定参数)- 预热步骤2000"""def __init__(self, params, lr=6e-4, betas=(0.9, 0.95), eps=1e-8,weight_decay=0.01, warmup=0.1, total_steps=10000):super().__init__(params, lr=0.0, betas=betas, eps=eps, weight_decay=weight_decay)self.warmup = warmup # 预热步数比例self.total_steps = total_steps # 总训练步数self.base_lr = lr # 基础学习率self.current_step = 0 # 当前步数def get_lr(self):"""计算当前学习率"""if self.current_step < self.warmup:# 线性预热阶段return self.base_lr * (self.current_step / self.warmup)# 余弦衰减阶段progress = (self.current_step - self.warmup) / (self.total_steps - self.warmup)return self.base_lr * (0.5 * (1.0 + math.cos(math.pi * progress)))def step(self, closure=None):"""优化器步进"""self.current_step += 1# 更新所有参数组的学习率for group in self.param_groups:group['lr'] = self.get_lr()super().step(closure)七、create_optimizer 函数
这段代码实现了一个为 GPT 类模型 量身定制的优化器创建函数,核心是 参数分组策略 和 学习率调度 的结合。以下是其背后的 设计原理 和 理论依据:
1.代码
def create_optimizer(model: nn.Module, weight_decay: float = 0.1,lr: float = 6e-4, warmup: int = 2000, total_steps: int = 100000):"""创建优化器(GPT风格)特点:- 权重衰减仅应用于线性层的权重- 其他参数(如层归一化参数)不应用权重衰减"""# 收集需要应用权重衰减的参数名decay = set()for mn, m in model.named_modules():for pn, p in m.named_parameters():fpn = f'{mn}.{pn}' if mn else pn # 完整参数名# 如果是线性层的weight参数,加入衰减集合if fpn.endswith('weight') and isinstance(m, nn.Linear):decay.add(fpn)# 参数分组param_dict = {pn: p for pn, p in model.named_parameters()}no_decay = set(param_dict.keys()) - decay # 不需要衰减的参数# 创建参数组opt_groups = [{'params': [param_dict[pn] for pn in sorted(list(decay))], 'weight_decay': weight_decay},{'params': [param_dict[pn] for pn in sorted(list(no_decay))], 'weight_decay': 0.0}]# 返回配置好的优化器return AdamWarmupCosineDecay(opt_groups, lr=lr, warmup=warmup, total_steps=total_steps)
2. 核心设计目标
在训练大型 Transformer 模型(如 GPT)时,不同参数需要差异化的优化策略:
- 线性层权重:需要权重衰减(L2 正则化)防止过拟合。
- 其他参数(如 LayerNorm 参数、偏置项):不应施加权重衰减,避免损害模型性能。
该函数通过 参数分组 实现这一目标,并集成 预热+余弦衰减 的学习率调度。
3. 关键设计解析
(1) 参数分组策略
① 识别需衰减的参数
if fpn.endswith('weight') and isinstance(m, nn.Linear):decay.add(fpn)- 目标参数:所有
nn.Linear层的weight(不包括bias)。 - 排除项:
- 层归一化(
LayerNorm)的参数。 - 所有偏置项(
bias)。 - 嵌入层(
Embedding)的参数(尽管是weight,但通常不衰减)。
- 层归一化(
② 分组实现
opt_groups = [{'params': [param_dict[pn] for pn in sorted(list(decay))], 'weight_decay': weight_decay},{'params': [param_dict[pn] for pn in sorted(list(no_decay))], 'weight_decay': 0.0}
]- 第 1 组:线性层权重,应用
weight_decay(如0.1)。 - 第 2 组:其他参数,
weight_decay=0。
(2) 理论依据
为什么不对所有参数衰减?
- LayerNorm 和偏置项:
- 这些参数通常量级较小,衰减会导致 过度约束,损害模型表达能力。
- 例如:LayerNorm 的
gain参数若被衰减,会破坏归一化效果。
- 嵌入层:
- 词嵌入矩阵的稀疏性高,衰减可能破坏语义表示(但某些实现会对其衰减)。
AdamW 的权重衰减解耦
- 传统 Adam:权重衰减与梯度更新混合,实际效果类似 L2 正则化。
- AdamW:将权重衰减独立计算,更接近 SGD + L2 的行为,数学上更合理。
(3) 学习率调度集成
- 预热(Warmup):
初始阶段线性增加学习率,避免早期梯度不稳定(尤其对深层 Transformer 重要)。 - 余弦衰减(Cosine Decay):
平滑降低学习率,帮助模型收敛到更优解。
3. 代码执行流程
- 遍历模型参数:
- 通过
named_modules()和named_parameters()递归扫描所有参数。 - 记录所有
nn.Linear.weight的完整名称(如"layers.0.attn.weight")。
- 通过
- 参数分组:
- 将参数分为
decay和no_decay两组。
- 将参数分为
- 创建优化器:
- 将分组传入
AdamWarmupCosineDecay,配置不同的weight_decay。
- 将分组传入
八、完整代码和测试用例
import torch
import torch.nn as nn
import math
from torch.nn import functional as Fclass PositionalEncoding(nn.Module):"""位置编码模块通过正弦和余弦函数为输入嵌入添加位置信息"""def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):super().__init__()self.dropout = nn.Dropout(p=dropout) # 随机失活层# 计算位置编码position = torch.arange(max_len).unsqueeze(1) # 位置序列 [max_len, 1]div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) # 除数项pe = torch.zeros(max_len, 1, d_model) # 初始化位置编码矩阵pe[:, 0, 0::2] = torch.sin(position * div_term) # 偶数位置使用正弦函数pe[:, 0, 1::2] = torch.cos(position * div_term) # 奇数位置使用余弦函数self.register_buffer('pe', pe) # 注册为缓冲区,不参与梯度更新def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播参数:x: 输入张量,形状 [seq_len, batch_size, embedding_dim]"""x = x + self.pe[:x.size(0)] # 添加位置编码return self.dropout(x) # 应用dropoutclass TransformerBlock(nn.Module):"""单个Transformer块包含掩码多头注意力和前馈网络"""def __init__(self, d_model: int, n_head: int, d_ff: int, dropout: float = 0.1):super().__init__()# 层归一化self.ln1 = nn.LayerNorm(d_model) # 第一个层归一化(注意力前)self.ln2 = nn.LayerNorm(d_model) # 第二个层归一化(前馈网络前)# 多头注意力机制self.attn = nn.MultiheadAttention(d_model, n_head, dropout=dropout)# 前馈网络(包含GELU激活)self.ffn = nn.Sequential(nn.Linear(d_model, d_ff), # 扩展维度nn.GELU(), # GELU激活函数nn.Linear(d_ff, d_model), # 降回原维度nn.Dropout(dropout) # 随机失活)self.dropout = nn.Dropout(dropout) # 残差连接的dropoutdef forward(self, x: torch.Tensor, mask: torch.Tensor = None) -> torch.Tensor:# 自注意力部分(带残差连接和层归一化)attn_output, _ = self.attn(x, x, x, attn_mask=mask) # 自注意力计算x = x + self.dropout(attn_output) # 残差连接x = self.ln1(x) # 层归一化# 前馈网络部分(带残差连接和层归一化)ffn_output = self.ffn(x) # 前馈网络计算x = x + self.dropout(ffn_output) # 残差连接x = self.ln2(x) # 层归一化return xclass Encoder(nn.Module):"""Transformer编码器由多个Transformer块堆叠而成"""def __init__(self, n_layers: int, d_model: int, n_head: int, d_ff: int, dropout: float = 0.1):super().__init__()# 创建多个Transformer块self.layers = nn.ModuleList([TransformerBlock(d_model, n_head, d_ff, dropout)for _ in range(n_layers)])def forward(self, x: torch.Tensor, mask: torch.Tensor = None) -> torch.Tensor:# 逐层处理输入for layer in self.layers:x = layer(x, mask)return xclass GPT(nn.Module):"""GPT模型(解码器-only架构)包含:1. 词嵌入 + 位置编码2. Transformer编码器堆叠3. 输出线性层"""def __init__(self, n_tokens: int, d_model: int, n_layers: int, n_head: int, d_ff: int, dropout: float = 0.1):super().__init__()# 词嵌入层self.token_embed = nn.Embedding(n_tokens, d_model)# 位置编码层self.pos_embed = PositionalEncoding(d_model, dropout)# Transformer编码器self.encoder = Encoder(n_layers, d_model, n_head, d_ff, dropout)# 输出线性层(词表大小)self.generator = nn.Linear(d_model, n_tokens)# 初始化权重self.apply(self._init_weights)# 掩码将在前向传播时创建self.mask = Nonedef _init_weights(self, module):"""权重初始化(GPT风格)"""if isinstance(module, (nn.Linear, nn.Embedding)):# 线性层和嵌入层权重初始化为N(0, 0.02)module.weight.data.normal_(mean=0.0, std=0.02)# 如果有偏置项,初始化为0if isinstance(module, nn.Linear) and module.bias is not None:module.bias.data.zero_()def forward(self, x: torch.Tensor) -> torch.Tensor:# 创建后续掩码(如果不存在或尺寸不匹配)if self.mask is None or self.mask.size(0) != x.size(1):self.mask = self.generate_square_subsequent_mask(x.size(1)).to(x.device)# 获取词嵌入并添加位置编码x = self.token_embed(x) # [batch_size, seq_len, d_model]x = x.transpose(0, 1) # [seq_len, batch_size, d_model](Transformer要求的输入格式)x = self.pos_embed(x) # 添加位置编码# 通过Transformer编码器x = self.encoder(x, self.mask)# 生成输出概率x = x.transpose(0, 1) # 恢复为[batch_size, seq_len, d_model]x = self.generator(x) # 线性投影到词表空间return x@staticmethoddef generate_square_subsequent_mask(sz: int) -> torch.Tensor:"""生成上三角掩码(防止看到未来信息)"""return torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1)class AdamWarmupCosineDecay(torch.optim.AdamW):"""带预热和余弦衰减的AdamW优化器GPT训练常用配置:- 初始学习率6e-4- 权重衰减0.1(仅应用于特定参数)- 预热步骤2000"""def __init__(self, params, lr=6e-4, betas=(0.9, 0.95), eps=1e-8,weight_decay=0.01, warmup=0.1, total_steps=10000):super().__init__(params, lr=0.0, betas=betas, eps=eps, weight_decay=weight_decay)self.warmup = warmup # 预热步数比例self.total_steps = total_steps # 总训练步数self.base_lr = lr # 基础学习率self.current_step = 0 # 当前步数def get_lr(self):"""计算当前学习率"""if self.current_step < self.warmup:# 线性预热阶段return self.base_lr * (self.current_step / self.warmup)# 余弦衰减阶段progress = (self.current_step - self.warmup) / (self.total_steps - self.warmup)return self.base_lr * (0.5 * (1.0 + math.cos(math.pi * progress)))def step(self, closure=None):"""优化器步进"""self.current_step += 1# 更新所有参数组的学习率for group in self.param_groups:group['lr'] = self.get_lr()super().step(closure)def create_optimizer(model: nn.Module, weight_decay: float = 0.1,lr: float = 6e-4, warmup: int = 2000, total_steps: int = 100000):"""创建优化器(GPT风格)特点:- 权重衰减仅应用于线性层的权重- 其他参数(如层归一化参数)不应用权重衰减"""# 收集需要应用权重衰减的参数名decay = set()for mn, m in model.named_modules():for pn, p in m.named_parameters():fpn = f'{mn}.{pn}' if mn else pn # 完整参数名# 如果是线性层的weight参数,加入衰减集合if fpn.endswith('weight') and isinstance(m, nn.Linear):decay.add(fpn)# 参数分组param_dict = {pn: p for pn, p in model.named_parameters()}no_decay = set(param_dict.keys()) - decay # 不需要衰减的参数# 创建参数组opt_groups = [{'params': [param_dict[pn] for pn in sorted(list(decay))], 'weight_decay': weight_decay},{'params': [param_dict[pn] for pn in sorted(list(no_decay))], 'weight_decay': 0.0}]# 返回配置好的优化器return AdamWarmupCosineDecay(opt_groups, lr=lr, warmup=warmup, total_steps=total_steps)# 示例用法
if __name__ == "__main__":# 超参数配置(GPT-small规模)n_tokens = 10000 # 词表大小d_model = 768 # 嵌入维度n_layers = 12 # Transformer层数n_head = 12 # 注意力头数d_ff = 3072 # 前馈网络隐藏层维度dropout = 0.1 # dropout率# 创建模型实例model = GPT(n_tokens, d_model, n_layers, n_head, d_ff, dropout)# 创建优化器(GPT训练配置)optimizer = create_optimizer(model)# 模拟输入数据(batch_size=4, seq_len=32)batch_size = 4seq_len = 32x = torch.randint(0, n_tokens, (batch_size, seq_len))# 前向传播output = model(x)print(f"输出形状: {output.shape}") # 应为 [batch_size, seq_len, n_tokens]