机器学习 Day14 XGboost(极端梯度提升树)算法
1.算法的原理(预测函数,损失函数,优化方法)

预测函数和优化方法:从极端梯度提升树我们就会知道,XGboost也是一类提升树,所以预测函数 一般是权重为1的回归决策树(因为涉及到求梯度,要求回归)的求和,优化算法是向前分步算法,即每一步求一个最优决策树
损失函数:就是在原本的损失函数上增加一个正则化项(GBDT算法加上正则化项),以此来减小过拟合的分险,具体在XGboost算法里是加上每棵树的惩罚:

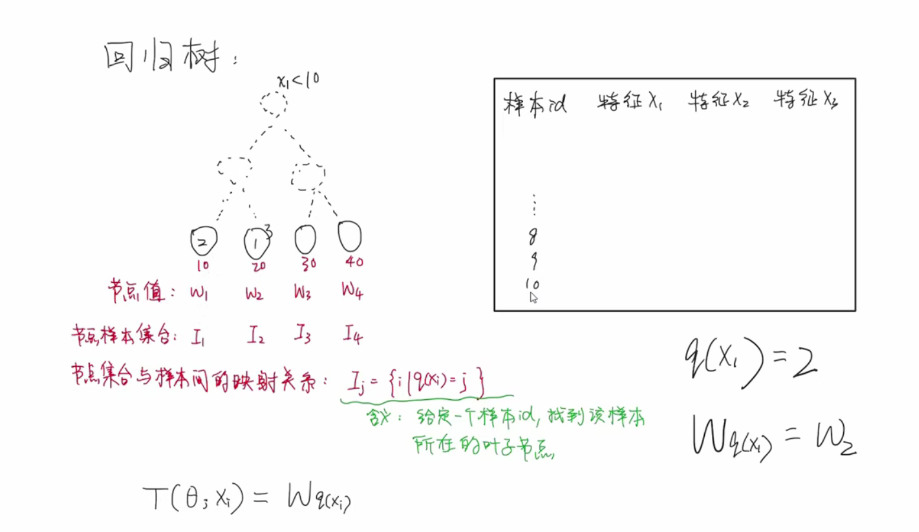
我们来看具体的一棵回归树:每个叶子结点(Ii)的值是wi,数学公式的含义q(xi)这个映射就是代表我们随便给一个xi,对应这个样本所在的叶子结点Ii,wq(xi)就是wIi就是xi这个样本对应的权值。所以可以这样表示一个树
对于正则项:其中一棵树T就表示有多少个叶子结点,因为T越大代表叶子结点越多,过拟合分险越大,所以加上T惩罚是对的,而当一棵树的权值范数求和太大,同样代表这棵树在总体中占比太大,容易发生偏差即过拟合所以要加上这个惩罚,这其实就是我们运筹里讲过的加上惩罚项的处理罢了,还有很多理论感兴趣可以看看。
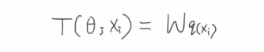
所以现在我们去优化带正则项的损失函数就行,我们接下来对它 进行化简:
2.原理推导,手写推导

说明OBJ只与当前构造树的每个叶子结点权重有关!

即,如果有棵树,则当前叶子结点权重和总损失最小是:

注意上面求最小wj的时候,我们忽略了求和号,因为
所以我们单独的求wi就行。
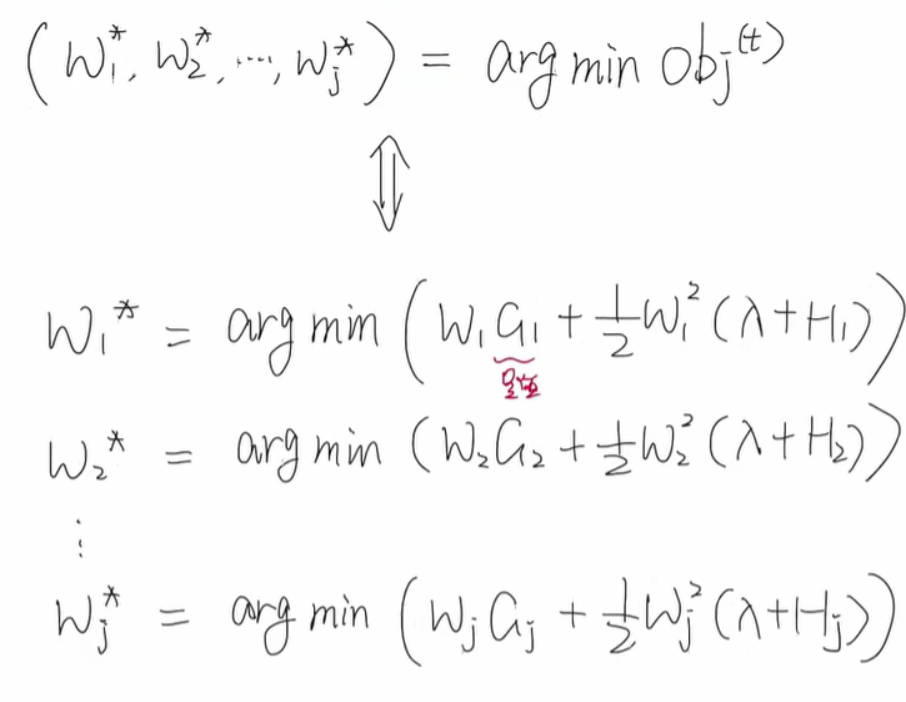
我们来理解一下gi和hi,显然每一个样本对应一个gi和hi,由上面的最优表达式我们可以得到每个叶子结点的值,来使得这个值能让这一步构造的树是一个损失最小的树,比如又边这个树,显然它的叶子结点权重按照上面最优构建即可。H是所有被包含叶子结点h的求和,G同理。
3.树的构建
上面已经知道如果有一棵树,权重该怎么样求,那如何构造一棵树呢,当然我们可以使用穷举法,然后计算每棵树的obj然后选择最小的树,但是,显然不合理,我们如何做呢?其实我们的方法类似于决策树的划分,采取贪婪+分布的策略。
其实就是我们去循环每一个特征每一个值,然后把它们二分为左右子树,分别去按上面公式计算左右子树和以前的OBJ,然后类似于信息增益去选择一个划分最优节点即可

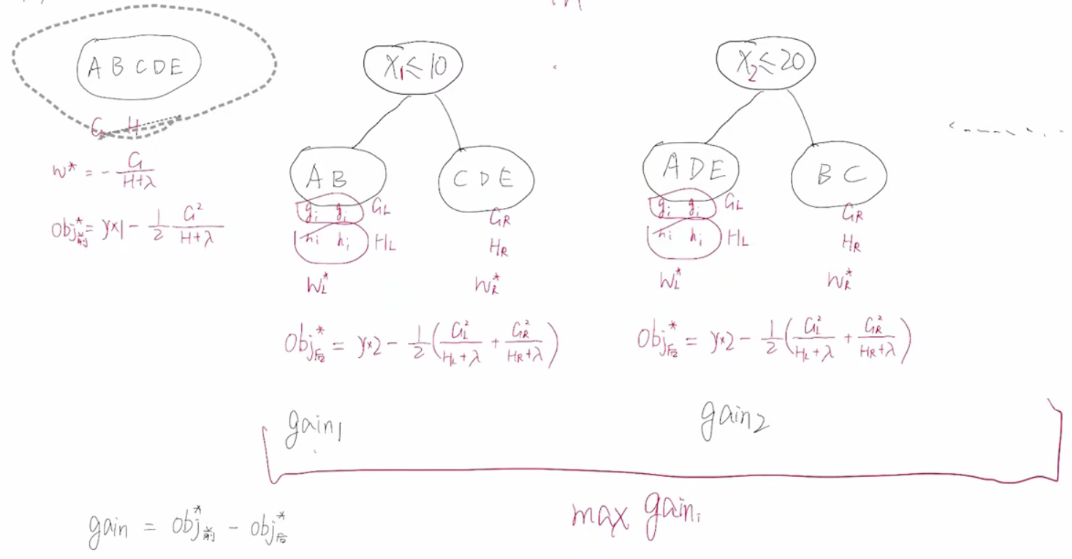
比如以下图解:
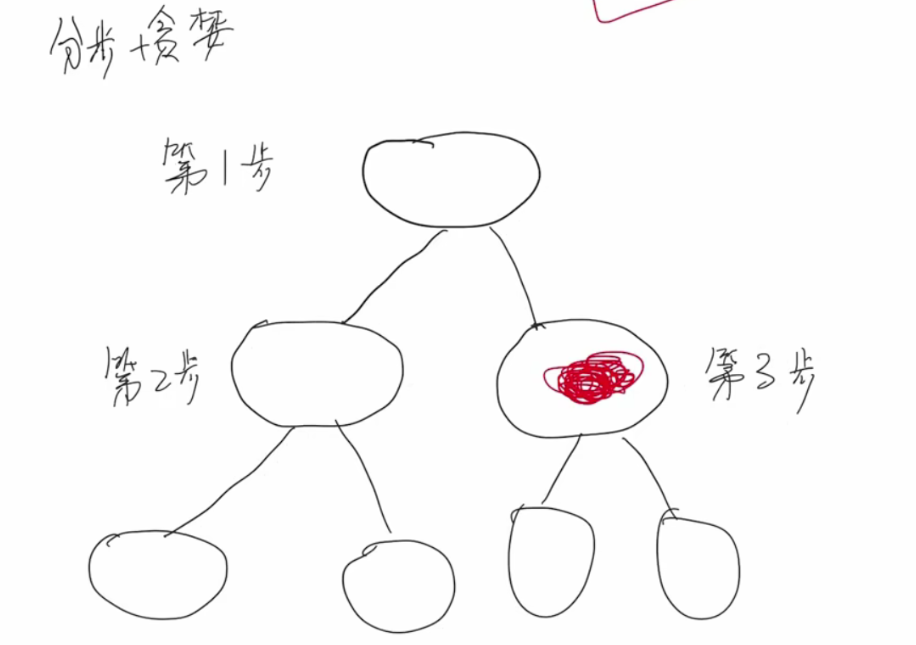 第一步时,节点ABCDE都在:
第一步时,节点ABCDE都在: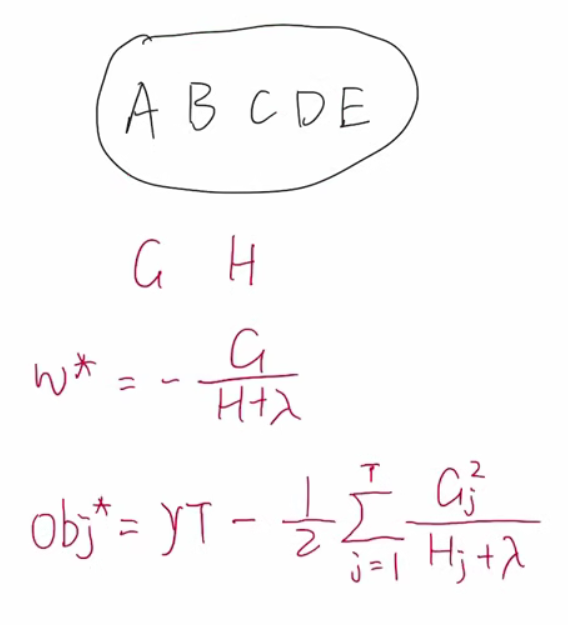
比如说用某个特征某个值划分时:计算前后OBJ:求差(L代表左子树,GL就是左子树所有样本的g求和,其他同理。)
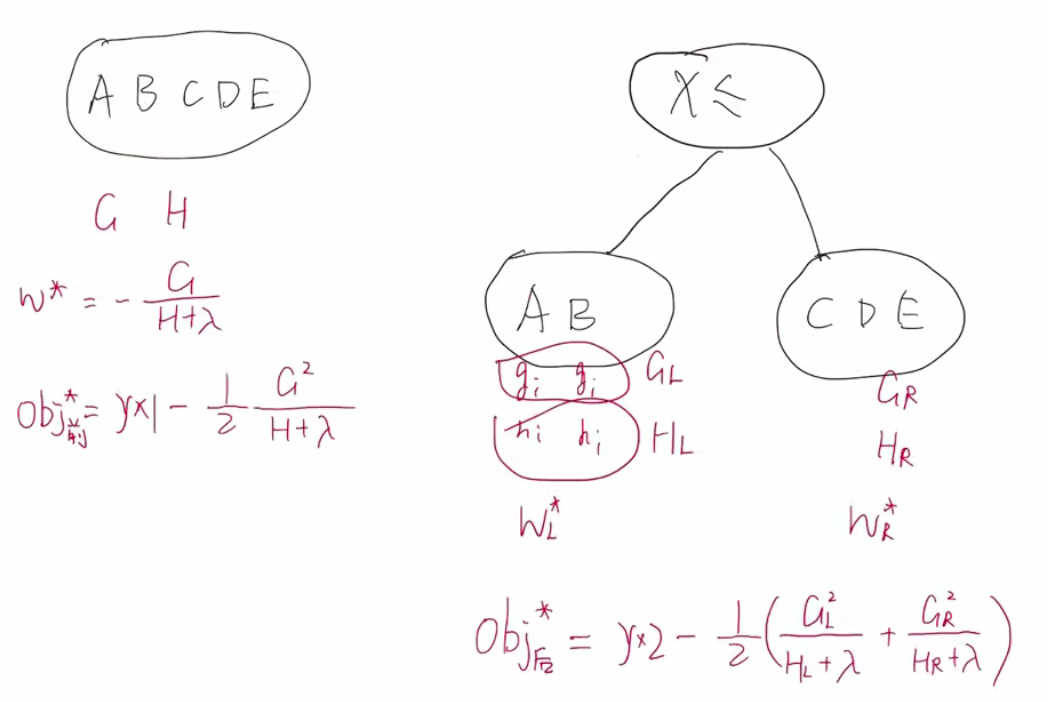
然后循环不同特征值不同值
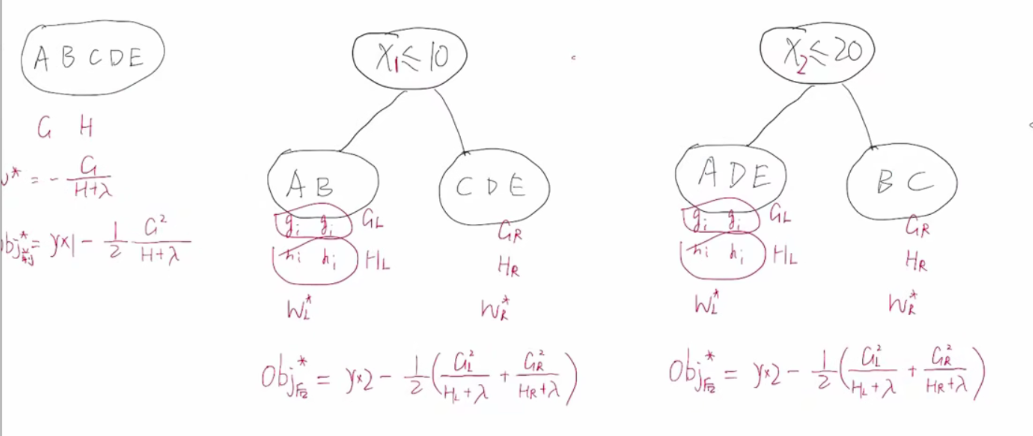
其实化简后前后gain是这样的
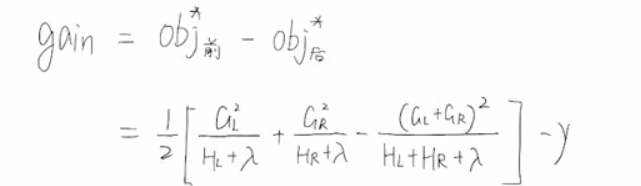
最后得到最大的gain作为划分点(类似于CART树)
我们说过XGboost构造树的时候会考虑结构化损失,即过拟合问题,那么在创建过程中它是怎么样达到目标的呢?即如何停止一颗树的深入构建。
(1)当当前节点的OBJ小于某个阈值的时候不进行划分,或者当所有划分都无法让gain减小时。
(2)叶子节点个数小于某个值或者树的深度达到某个阈值的时候。(类似于决策树的情况)
所以这样每轮的决策树都可以这样构建完成,至于如何预测一个样本,就和讲过的Adaboosting算法一样了。
总体流程是这样的:每次迭代我们都可以计算右下角的那个表格用于计算。d就是表示对特征的一个从小到大排序(用于划分左右子树),双层嵌套循环,第一层就是循环每个特征,第二层就是循环每个特征的值,注意我们要对所有特征,所有值都进行一次选择,而每个特征都得排序,这是一件很耗时的事情,我们叫这个算法为精确XGboost算法,我们为了时间,损失一部分精确度,这样的算法就是近似算法,我们采用近似算法来减少时间
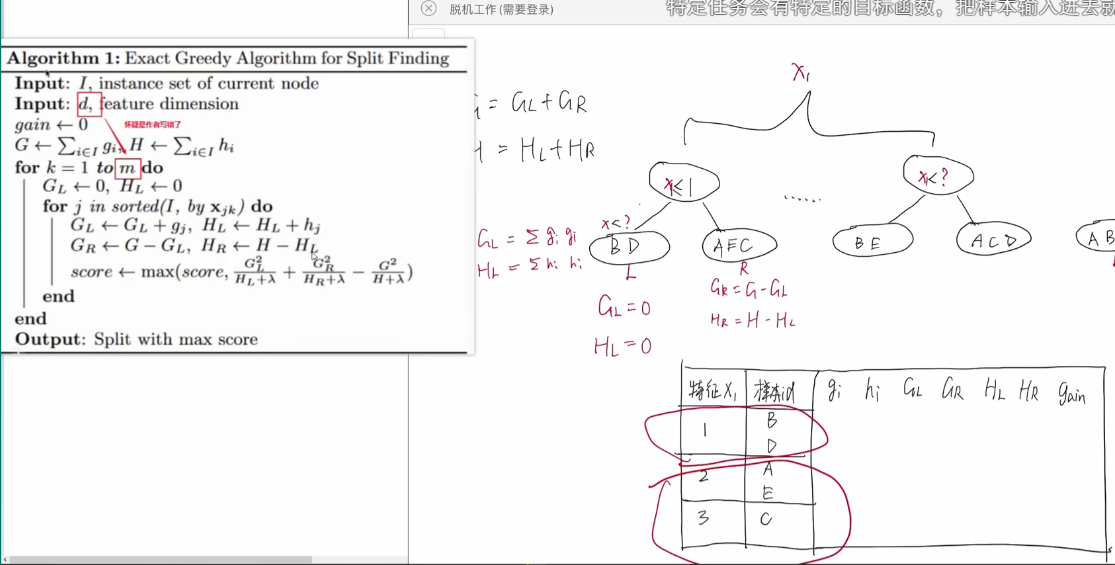
4.近似算法:我们讲到精确算法的特征和特征值太多了,所以我们可以分为两个方向:压缩特征和压缩特征值
4.1压缩特征:我们可以通过列采样来压缩特征值,就是随机选取一些特征,实际算法里可以设置占比,压缩特征可以分为按树和按层,按树的意思就是,我们随机选择一些特征,然后这棵树在分裂的时候会一直都用这些特征,按层的意思就是我们每次分裂会重新随机选取特征值
4.2.压缩特征值:分桶操作:
分桶(Binning):将连续特征值划分为若干个离散的区间(桶),用桶代替原始值进行计算。比如:
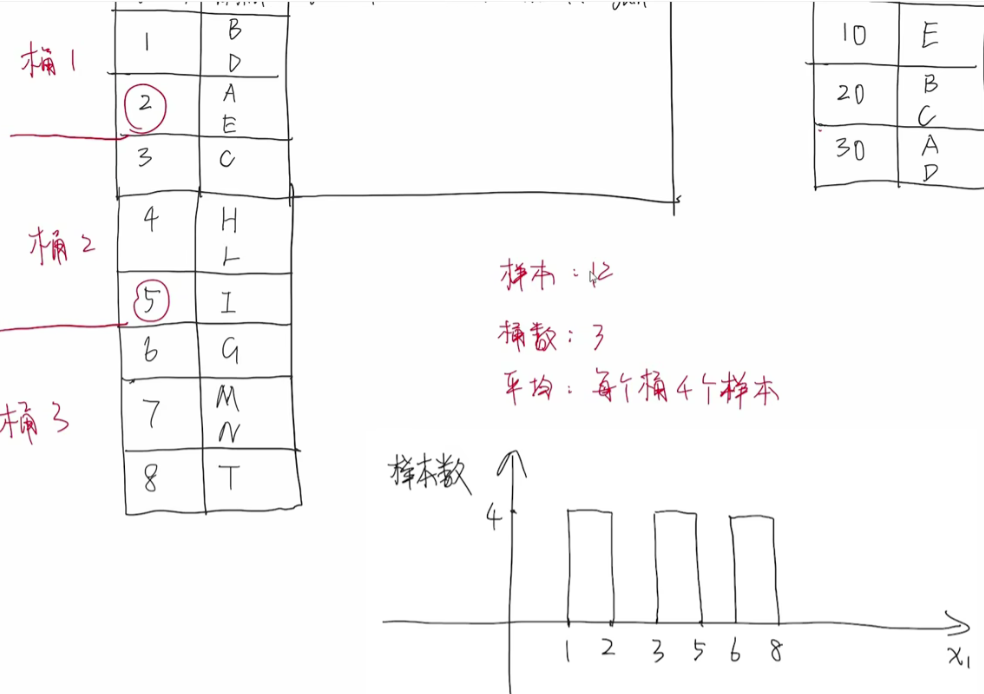
我们如果要选取3个特征值就是2,5,8 ,显然我们在分桶时将每个样本权重视为一样,这是等频分割,但是其实在实际中是不一样的,那么我们如何考察它的权重呢?
分桶方法
XGBoost中主要使用两种分桶策略:(和压缩特征一样)
-
全局分桶(Global):在建树前对所有数据进行一次分桶,所有树共享相同的分桶方案
-
局部分桶(Local):在每次分裂时重新分桶,更精确但计算量更大
分桶的具体步骤
-
排序特征值:首先对特征值进行排序
-
确定候选分割点:
-
等宽分桶:按值范围均匀划分
-
等频分桶:使每个桶包含大致相同数量的样本
-
加权分桶(Weighted Quantile Sketch):XGBoost使用的方法,考虑二阶梯度作为权重
-
注意在算法中我们可以设置一个超参数来控制每个桶的最大宽度,显然超参数越大,桶越宽,桶数越少,选取的特征值越少。
-
-
构建直方图:统计每个桶内的梯度统计量(G和H)
-
一般我们使用加权分桶
分桶的优势
-
减少计算量:只需评估桶边界作为候选分割点
-
节省内存:存储桶统计量而非原始数据
-
支持并行:不同特征的分桶可以并行计算
-
适合分布式:只需通信桶统计量而非原始数据
这种分桶操作使得XGBoost能够高效处理大规模数据,同时保持较好的模型精度。
5.对于缺失值的处理:我们当然可以枚举所有情况,但是不可能,当前也可以采用贪心+分布的思想:就是每次拿一个缺失值,分别分配左右子树,看拿个增益大,分配那个,当然这样还是计算量太大,我们是直接讲所有缺失值视为一个整体看左右那个gain大:
5.1. 基本处理原则
XGBoost不是简单地填充缺失值,而是将缺失值视为一种特殊值,让模型自动学习处理缺失值的最佳方式。
5.2 具体处理机制
5.2.1 默认方向学习
对于每个树节点中的每个特征,XGBoost会:
-
将所有非缺失值的数据按常规方式处理
-
同时计算将缺失值分配到左子树和右子树的增益
-
选择使目标函数增益更大的方向作为缺失值的默认方向
5.2.2 算法步骤
-
计算非缺失值数据的分割增益
-
计算缺失值分配到左子树的增益:
-
将缺失值样本临时归入左子集
-
计算新的统计量(G_left, H_left)和(G_right, H_right)
-
计算增益
-
-
计算缺失值分配到右子树的增益(同上)
-
选择增益更大的方向作为该特征在该节点的缺失值默认方向
注意,gi和hi只依赖于上一轮的预测值,所以即使样本有缺失,仍然不影响,有的人就要问了,那一开始的怎么样计算呀,第一轮没有预测值怎么办,第一轮的时候通常我们可以这样做:
XGboost和GBDT区别:


6.API实现:
安装xgboost库即可用于直接使用这个类,也是先实例化,再使用类方法,可以进行网格搜索和交叉验证等。