初识Redis · 主从复制(上)
目录
前言:
主从模式
模拟主从模式
连接信息
slaveof命令
nagle算法
Nagle算法的工作原理:
具体实现:
优点:
缺点:
使用场景:
拓扑结构
前言:
主从复制这里算得上是一个大头了,主要是因为主从复制它解决的问题,就是比较契合于我们当代网民的一个核心点,即人多了数据读写不过来怎么办?我们在Redis的第一篇中写到分布式系统架构的由来是从单机架构,然后引入多台机器,每台机器还可以细分工作内容,这样的一个流程引出了分布式系统,甚至到了微服务部分。
那么主从复制这里解决的问题就是:单点问题,如果只有一台机器,那么就意味着两个点,第一,某个服务的性能和并发量是较为有限的,因为不管是应用层服务还是数据库服务都要从这一台机器来完成,第二,这个服务的可用性不是很强,因为如果一旦机器挂了,服务也就中断了,没有其他机器来提供对应的服务了。
所以,为了解决以上的单点问题,往往在部署Redis服务的时候,希望部署多个Redis服务器,构成一个集群,如果某一个机器挂了,也是可以让其他机器提供相应的服务,这样对应服务的可用性就大大提高了。
那么在分布式系统中,一般会有三种部署Redis服务的方式,分别是:主从复制,主从复制+哨兵,集群模式。
那么我们将通过三篇文章,分别介绍三种不同的模式是如何解决单点问题的。
主从模式
所谓主从模式,我们从字面意思上来看,就是分为了主节点和从节点,假设我们分别有三个Redis服务器,为A,B,C。其中A节点为主节点,B和C为从节点。
既然是主从关系,那么也就意味着A是老大,BC是小弟,小弟得听老大的吧?所以在数据方面,BC的数据都是从A上面同步过来的。既然是同步过来的,同步我们也是有不同的机制的,这里后文介绍。
那么问题来了,作为从节点,是否具有权限修改对应的数据?
显然是不可以的,因为对于从节点来说,数据都是从主节点来的,私自篡改了可就一点不像从节点了,对于主从模式来说,数据要保持一致性,既然是一致性,从节点单独修改了数据之后同步给主节点看起来好像也可以,但是如果在主从模式中我们规定:只有主节点能同步数据给从节点,从节点不能同步数据给主节点。
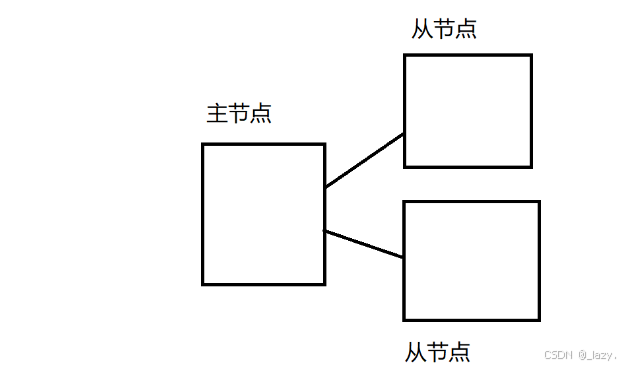
当我们有了三个节点之后,对于上面的单点问题我们就有了一定多个解决能力,并且,单点问题的核心就是怕服务器挂了,现在我们有三个服务器,即便挂了一个,也不会影响其他两个节点正常工作。
那么什么是正常工作呢?对于Redis来说,操作我们就分为读写好了,通过前面文章的理解,我们就知道了对于数据库服务来说,一般都是读的压力远远大于写的压力的,所以从节点一般会多分担一点读的压力,对于主节点来说,它不仅要分担读的工作量,写的操作都是它全权来完成的。
正常工作的时候多和谐,可是一旦挂了节点,比如B节点挂了,影响也不是那么大,毕竟还有两个服务器顶着呢,而多台服务器同时挂的可能性也是非常非常小的,这点我们不用担心。那么问题来了,假设我们有机器挂了,如果是从节点还好,如果是主节点呢?
主节点一挂,就完了,也不是能真完了,只是主节点一挂,那么读方面的请求还是能够处理的,不过写方面的请求就没有办法了,有人说咱们再引入一个主节点,这可是万万不行的,一山可容不得二虎,所以如果主节点一挂,咱们要么就人工干预另起一个主节点,要么就引入哨兵机制。这个点我们在第二篇文章会讲的。对于人工干预的话,操作相当繁琐,所以这里并不打算展开来讲。
那么从上面的介绍,我们能得出来两个简短的结论:主从模式能有效的分配读写请求,最大的安全隐患是主节点是否能正常运行。
模拟主从模式
这里针对的是使用云服务器的同学,咱们只有一台服务器,那么如何启动多个Redis-server进程呢?一般来说,分布式系统代表的是多个redis-server进程启动在不同的主机上。这里我们是有办法启动多个server进程的。
首先,配置文件肯定要来多份,因为redis-server服务器启动的时候会自动加载配置文件,其次,我们需要修改对应的端口号,因为redis服务器默认启动的6379端口号,所以我们需要修改一下,比如6380,6381等。
当然了,其实模仿主从模式有多种方式,上面的这种方式是修改的配置文件,使得主从模式永久生效,我们也可以通过命令行的方式使主从模式生效,比如redis-cli --slaveof{masterhost}{masterport},但是这种方式都不是永久性的,我们为了方便学习,还是推荐使用修改配置文件的方式。


分别复制配置文件之后,然后修改端口号为6380和6381,并且我们可以关注一下daemonize是否开启,这个的作用使让Redis以守护进程的方式在后台运行的。
另一个同理:
然后我们通过指定配置文件的方式,使得新启动的两个服务器的端口号正确,并且指定了我们希望的主节点的主机名和端口号,这样我们的连接就算完成了。
这里127.0.0.1:6379 127.0.0.1:39155/38147代表的意思就是进行tcp连接的时候,OS会为redis分配一个临时端口用于网络连接,而现在已经连接成功了。
我们发现它使用的是tcp连接,也就意味着主节点和从节点之间的通信是通过tcp进行的,换句话说,这个时候我们可以把主节点认为是服务器,从节点认为是客户端。
此时我们的连接就成功了,在正式验证主从复制之前,我们先来简单理解一下对服务器使用kill的现象,其实在我们刚才kill掉6379的服务器的时候,我们发现它自己重启了,并且也为自己分配了一个全新的pid。这是因为服务器要的是稳定性和高可用性,但是不免有挂的时候,这个时候就要求服务器立即重启,这样就能避免产生严重的后果。所以,我们看到的现象是kill掉之后立即重启了。
连接信息
目前我们已经是连接成功了,那么我们可以先启动一下redis-cli 6379的服务器,并且使用命令info replication查看相关的信息: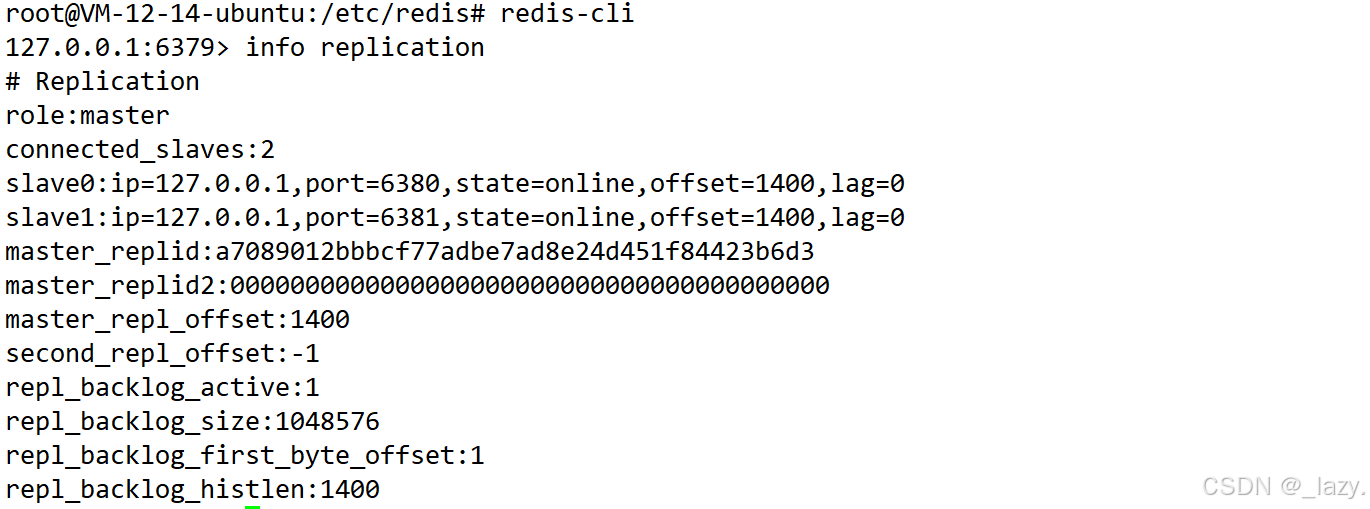
从上到下,我们依次阅读,可以发现role:master,代表这个节点它是主节点,connected_slaves代表的是连接的从节点有两个,slave0和slave1后面的字符串蕴含的信息有从节点的ip地址,port,state在线状态,以及offset偏移量和lag延迟,然后是master_replid,有两个,后面介绍。对于master_repl_offset和second_repl_offset代表的是主节点复制偏移量和第二复制偏移量,后面的四个字段代表的都是积压缓冲区的值。
我们发现相关的连接信息还是比较多的,那么我们可以根据连接信息,展开一系列的学习。
slaveof命令
首先就是既然我们能够让节点跟随某个节点,如何取消呢?
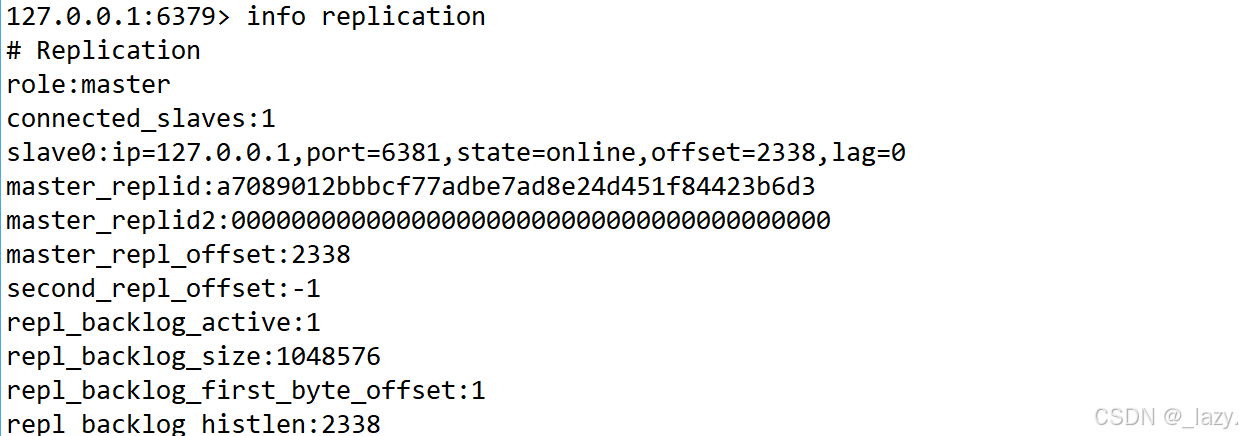
使用命令slaveof no one,我们就能够取消主从关系了,同时我们在主节点那里使用info replication,我们发现对应的连接信息也发生了修改。
当然了,我们也可以通过slaveof重新连接。

有了这个命令,我们是否可以完成以上的结构呢?当然是可以的~
此时结构发生更改,然后我们可以通过Info replication查看一下6380的信息。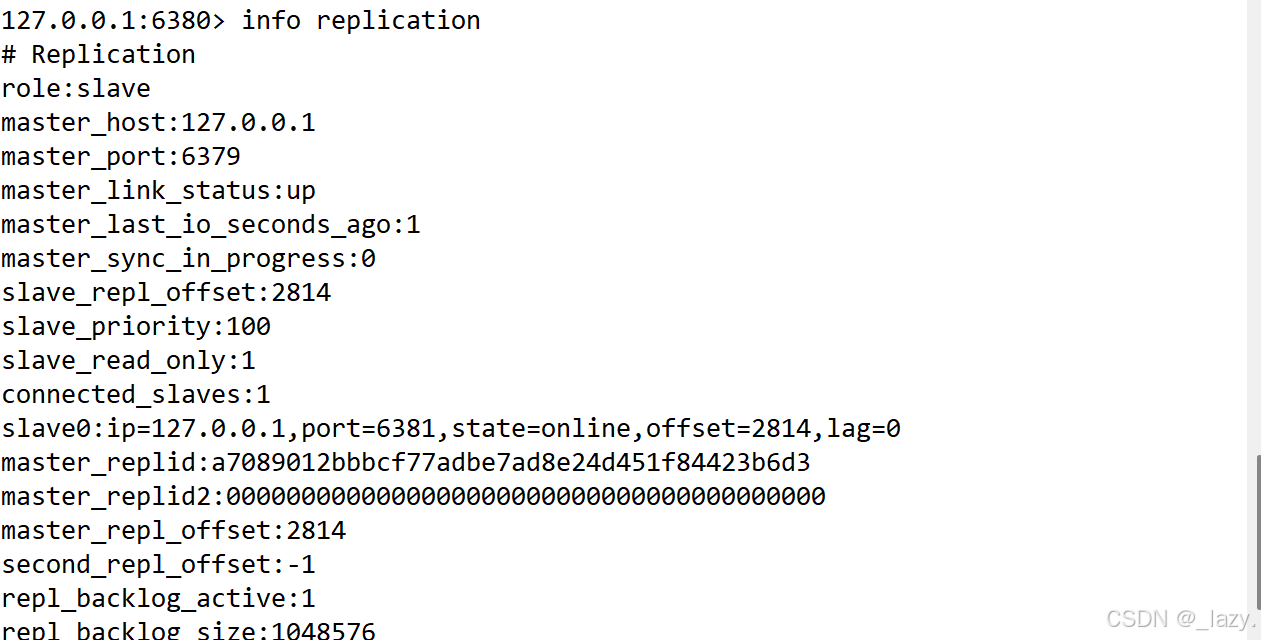
我们可以看到它仍然是一个slave节点,不过看起来它好像是6381的主主节点,实际上它没有实权,还是只能完成读的操作,写的操作仍然不被允许。
nagle算法

我们刚才通过netstat命令发现主节点和从节点之间是通过tcp连接的,既然是通过tcp连接,那么我们可能就得好好思考即时性的问题了。一般在游戏开发中,对于即时性的要求非常高,比如fps游戏等。
而nagle算法一旦开启,就会增加tcp的传输延迟,但是好处是能够节省网络带宽,这对于资源节省来说还是不错的,那么反过来,关闭了nagle算法,就能提高传输效率,但是对于网络带宽的消耗就大了,至于如何平衡,我们就要看实际的应用场景了。
以下工作原理来源于AI:
Nagle算法的工作原理:
Nagle算法的核心思想是:如果当前没有足够的数据来填充一个完整的TCP包,那么就等一等,把多个小的数据合并成一个较大的包进行发送。这样做的目的是减少网络中小数据包的数量,从而降低协议头的开销,提升整体吞吐量。
具体实现:
如果有数据要发送,但当前发送的数据量不足以填满一个TCP包(即小于MSS,最大分段大小),那么发送的数据将被缓存。
这时,发送方会等到缓存中的数据量足够填满一个完整的包,或者等到先前发送的数据被确认(收到确认报文,ACK)后,再发送新的数据。
这样,发送的数据会合并成更大的数据包来提高传输效率。
优点:
减少小数据包的数量:通过合并多个小的数据包,减少了每个数据包的头部开销,从而提高了网络带宽的利用率。
提高吞吐量:尤其是在网络延迟较高的情况下,减少了发送的小包数量,能有效提高吞吐量。
缺点:
延迟增大:由于发送方可能会等待缓存中数据的积累或者等待确认,这可能会导致某些小数据包的延迟增大,尤其是对于需要实时交互的应用(例如在线游戏、视频流)来说,这可能不利。
实时性差:在对实时性要求较高的应用中,Nagle算法可能引入不必要的延迟,导致响应时间变慢。
使用场景:
适合数据传输量较大,且不太关心实时性要求的场合,如文件传输、邮件发送等。
不适合实时性要求高的应用,如在线游戏、即时通讯等,因为 Nagle算法会引入延迟。
拓扑结构
我们刚才更改了三个节点之间的结构:
这种结构我们称之为拓扑结构,即不同的排列结构,而不同的排列结构会导致效率的高低,比如
这种结构来讲的话,主节点收到修改的命令之后,那么就要通过tcp网络服务把其他四个机器上的数据进行更改,随着节点个数的增多,每个节点都连接了主节点的话,那么主节点对于一条数据就是重复传输多次,这势必会减少效率。
所以我们引入了扁平化结构: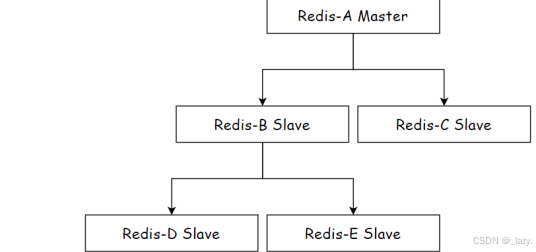
即从节点带着从节点,这样主节点就不用一条数据进行多次传输,而是将这个任务给到了自己的从节点。
那么如何从节点如何从主节点那里get到数据的呢?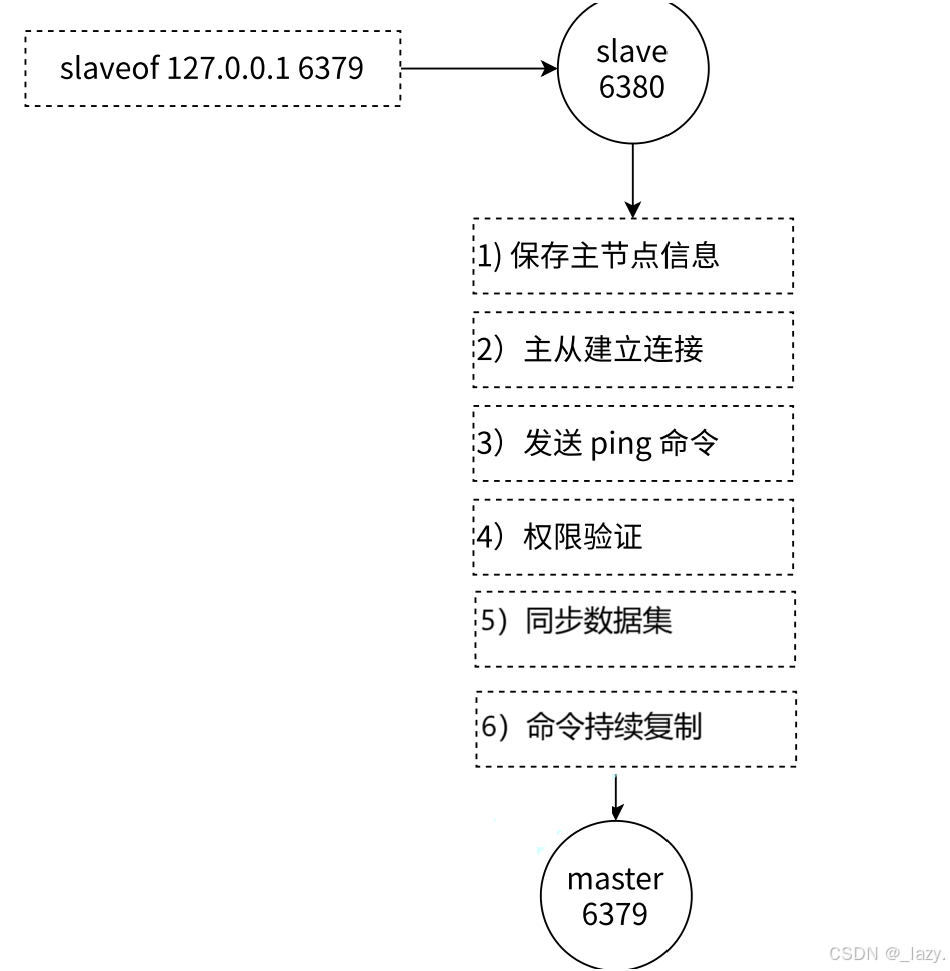
首先是保存主节点的信息,比如ip port等,然后通过tcp建议连接,这个过程会有tcp的三次握手,在网络层面上判断tcp连接是否成功,成功了之后,再使用ping命令,判断主节点和从节点是否都能正常工作,然后是权限验证,不可能让你啥也不验证就连接了是吧。
最后就是同步数据了,同步数据分为了全量复制和增量复制以及实时复制,复制的这个话题我们就单开一篇文章介绍了,毕竟这是主从复制的核心机制了。
我们也可以简单验证一下主从复制了: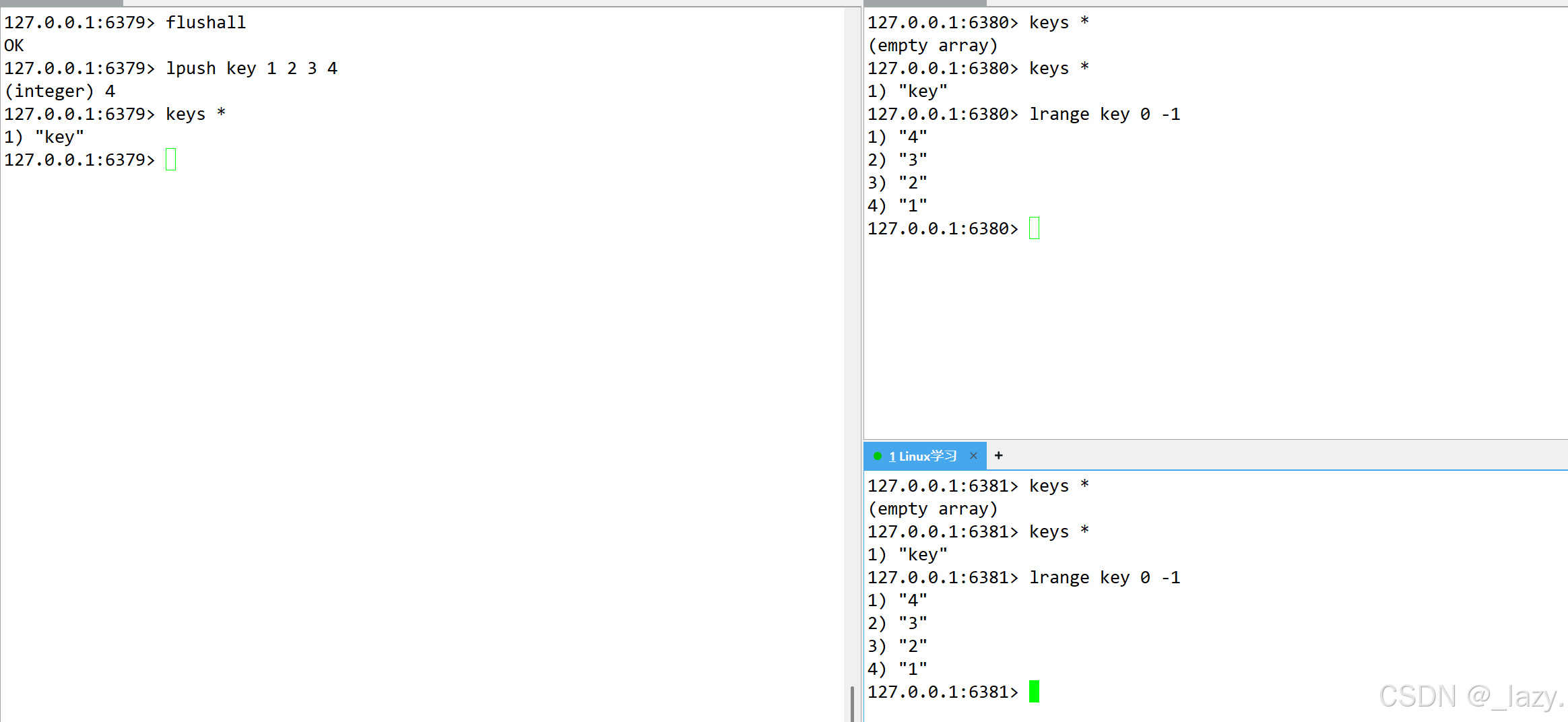
关于主从复制的同步数据机制请移步下一篇文章~
感谢阅读!