SQLPandas刷题(LeetCode3451.查找无效的IP地址)
描述:LeetCode3451.查找无效的IP地址
表:
logs+-------------+---------+ | Column Name | Type | +-------------+---------+ | log_id | int | | ip | varchar | | status_code | int | +-------------+---------+ log_id 是这张表的唯一主键。 每一行包含服务器访问日志信息,包括 IP 地址和 HTTP 状态码。编写一个解决方案来查找 无效的 IP 地址。一个 IPv4 地址如果满足以下任何条件之一,则无效:
- 任何 8 位字节中包含大于 255 的数字
- 任何 8 位字节中含有 前导零(如
01.02.03.04)- 少于或多于
4个 8 位字节返回结果表分别以
invalid_count,ip降序 排序。结果格式如下所示。
示例:
输入:
logs 表:
+--------+---------------+-------------+ | log_id | ip | status_code | +--------+---------------+-------------+ | 1 | 192.168.1.1 | 200 | | 2 | 256.1.2.3 | 404 | | 3 | 192.168.001.1 | 200 | | 4 | 192.168.1.1 | 200 | | 5 | 192.168.1 | 500 | | 6 | 256.1.2.3 | 404 | | 7 | 192.168.001.1 | 200 | +--------+---------------+-------------+输出:
+---------------+--------------+ | ip | invalid_count| +---------------+--------------+ | 256.1.2.3 | 2 | | 192.168.001.1 | 2 | | 192.168.1 | 1 | +---------------+--------------+解释:
- 256.1.2.3 是无效的,因为 256 > 255
- 192.168.001.1 是无效的,因为有前导零
- 192.168.1 是非法的,因为只有 3 个 8 位字节
输出表分别以
invalid_count,ip降序排序。
数据准备
SQL
CREATE TABLE logs (log_id INT,ip VARCHAR(255),status_code INT )Truncate table logs insert into logs (log_id, ip, status_code) values ('1', '192.168.1.1', '200') insert into logs (log_id, ip, status_code) values ('2', '256.1.2.3', '404') insert into logs (log_id, ip, status_code) values ('3', '192.168.001.1', '200') insert into logs (log_id, ip, status_code) values ('4', '192.168.1.1', '200') insert into logs (log_id, ip, status_code) values ('5', '192.168.1', '500') insert into logs (log_id, ip, status_code) values ('6', '256.1.2.3', '404') insert into logs (log_id, ip, status_code) values ('7', '192.168.001.1', '200')Pandas
data = [[1, '192.168.1.1', 200], [2, '256.1.2.3', 404], [3, '192.168.001.1', 200], [4, '192.168.1.1', 200], [5, '192.168.1', 500], [6, '256.1.2.3', 404], [7, '192.168.001.1', 200]] logs = pd.DataFrame(columns=["log_id", "ip", "status_code"]).astype({"log_id": "Int64", "ip": "string", "status_code": "Int64"})
分析
①先将ip分为四段
②每一段都判断一下条件 不超过255 开头不为0
③排除掉长度缺失的
代码
法一:
with t1 as (
select ip,substring_index(substring_index(ip,'.',1),'.',-1) first,substring_index(substring_index(ip,'.',2),'.',-1) second,substring_index(substring_index(ip,'.',3),'.',-1) third,substring_index(substring_index(ip,'.',4),'.',-1) fourth
from logs)
, t2 as (
select ip,case when first > 0 and first <= 255 then 0 else 1 end r1,case when second >= 0 and second <= 255 and second not like '0%' then 0 else 1 end r2,case when third >= 0 and third <= 255 and third not like '0%' then 0 else 1 end r3,case when fourth >= 0 and fourth <= 255 and fourth not like '0%' then 0 else 1 end r4
from t1)
, t3 as (select ip,(r1 + r2 + r3 + r4) rr1,((length(ip) - length(replace(ip, '.', ''))) != 3) rr2,((r1 + r2 + r3 + r4) + ((length(ip) - length(replace(ip, '.', ''))) != 3)) rr3from t2)
select ip,count(ip)'invalid_count' from t3
where rr3 != 0
group by ip
order by invalid_count desc ,ip desc;法二: 正则
select ip,ip not regexp('^((25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9][0-9]|[0-9])\\.){3}(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9][0-9]|[0-9])$') from logs法三:pandas
import pandas as pddef find_invalid_ips(logs: pd.DataFrame) -> pd.DataFrame:logs['r1'] = logs['ip'].str.split('.')logs['result']=Nonefor i in range(len(logs['r1'])):if len(logs.loc[i,'r1']) == 4:logs.loc[i,'result'] = '1'for j in logs.loc[i,'r1']:if int(j)>255 or int(j)<0 :logs.loc[i,'result'] = '0'breakelif j.startswith('0') :logs.loc[i,'result'] = '0'breakelse:logs.loc[i,'result'] = '1'else:logs.loc[i,'result'] = '0'df1 = logs[logs['result']=='0']df2 = df1.groupby('ip')['log_id'].count().reset_index().rename(columns={'log_id':'invalid_count'})df2.sort_values(by=['invalid_count','ip'],ascending=[False,False],inplace=True)return df2总结
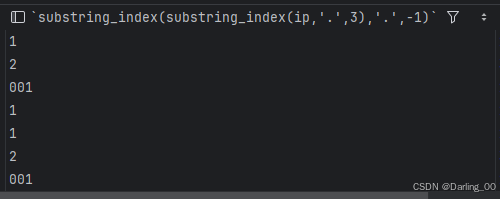
①substring_index 括号里的3 指的是符号"."分割之后的前三位
-1是指分割后从右往左数第一位
substring_index(ip,'.',3)
substring_index(substring_index(ip,'.',3),'.',-1)
②判断为八位字节ip 即分隔符为三个
(length(ip) - length(replace(ip, '.', ''))) != 3③loc和iloc区别 iloc是索引位置 loc是索引,列名
DataFrame.iloc[row_positions, column_positions]
DataFrame.loc[row_labels, column_labels]
④reset_index是重置索引
⑤正则表达式
一个0-255的数字字符串,匹配字符是这样的:
- 250-255:25[0-5]
- 200-249:2[0-4][0-9]
- 100-199:1[0-9]{2}
- 10-99(无前导零):[1-9][0-9]
- 0-9:[0-9]
- 开头 ^
- 结尾 $