PyTorch 实现食物图像分类实战:从数据处理到模型训练
一、简介
在计算机视觉领域,图像分类是一项基础且重要的任务,广泛应用于智能安防、医疗诊断、电商推荐等场景。本文将以食物图像分类为例,基于 PyTorch 框架,详细介绍从数据准备、模型构建到训练测试的全流程,帮助读者深入理解深度学习图像分类的实践过程。
二、原理
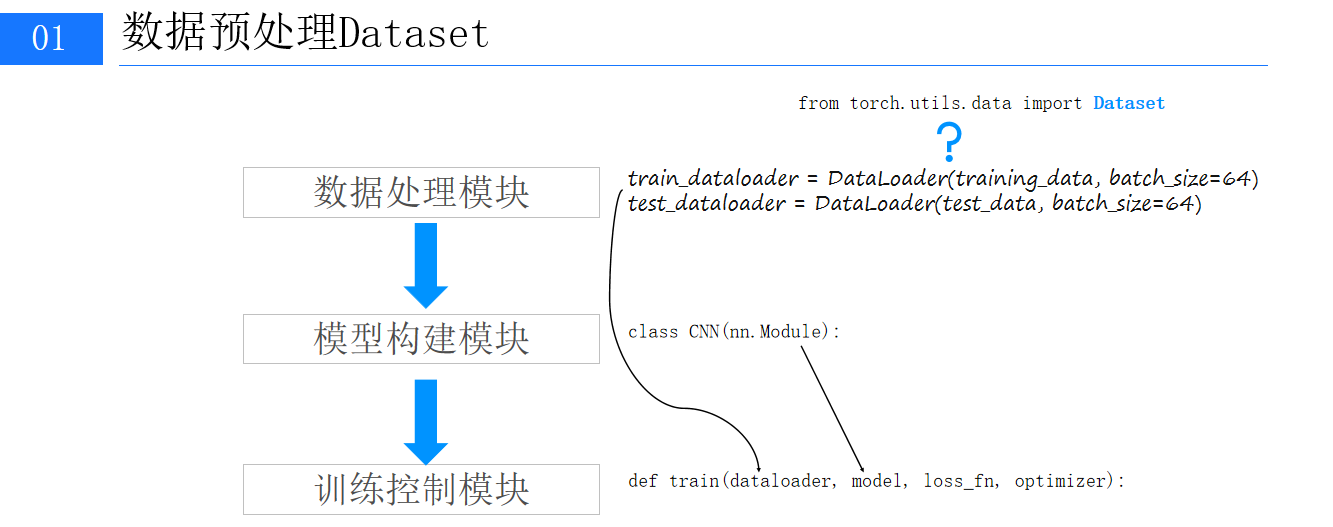
三、代码示例
1、数据文件路径准备
在实际项目中,原始图像数据通常按类别存储在不同文件夹下。代码中的train_test_file函数用于遍历数据文件夹,将图像文件路径及其对应的类别标签写入文本文件,方便后续数据加载:
import os
def train_test_file(root, dir):file_txt = open(dir+'.txt','w')path = os.path.join(root, dir)for roots, directories, files in os.walk(path):#os.walk(path)代表开始去遍历path路径下的文件if len(directories) != 0:dirs = directorieselse:now_dir = roots.split('\\')for file in files:path_1 = os.path.join(roots,file)print(path_1)file_txt.write(path_1+' '+str(dirs.index(now_dir[-1]))+'\n')file_txt.close()
root = r'.\食物分类\food_dataset2'
train_dir = 'train'
test_dir = 'test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)
该函数通过os.walk递归遍历文件夹,将每个图像文件的绝对路径与对应的类别索引(通过文件夹名称顺序确定)写入.txt文件,格式为图像路径 标签。
2、自定义数据集类
import torch
import numpy as np
from PIL import Image
from torch.utils.data import Dataset,DataLoader #用于处理数据集
from torchvision import transforms
data_transforms = {#字典'train':transforms.Compose([#对图片做预处理的,组合transforms.Resize([256,256]),#数据进行改变大小transforms.ToTensor(),#数据转换为tensor,默认把通道维度放在前面]),'valid':transforms.Compose([transforms.Resize([256, 256]),transforms.ToTensor(),]),
}#数组增强class food_dataset(Dataset):def __init__(self, file_path, transform=None):self.file_path = file_path#为了将外部空间的路径传递给共享空间,以便于后期可以使用self.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f:samples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path)#图像的路径self.labels.append(label)#标签,还不是tensordef __len__(self):return len(self.imgs)def __getitem__(self, idx):image = Image.open(self.imgs[idx])#读取到图片数据,还不是tensor,BGRif self.transform:#将pil图像数据转换为tensorimage = self.transform(image)label = self.labels[idx]#label还不是tensorlabel = torch.from_numpy(np.array(label, dtype = np.int64))#label也转换为tensorreturn image, labelfood_dataset类实现了__len__和__getitem__两个关键方法:
__len__返回数据集的样本总数;
__getitem__根据索引读取图像文件,应用数据变换(如调整大小、转换为张量),并将标签转换为torch.Tensor格式后返回。
3、数据加载器配置
#training_data包含了本次训练需要的全部数据集
training_data = food_dataset(file_path = './train.txt',transform = data_transforms['train'])
test_data = food_dataset(file_path = './test.txt',transform = data_transforms['valid'])
#training_data需要具备索引的功能,还要确保数据是tensor
train_dataloader = DataLoader(training_data, batch_size=64,shuffle = True)#64个图片为一个包,shuffle = True用于将数据进行打乱
test_dataloader = DataLoader(test_data, batch_size = 64,shuffle = True)DataLoader的batch_size参数指定每个批次包含的样本数量,shuffle=True表示在每个 epoch 训练前打乱数据顺序,有助于提高模型的泛化能力
4、搭建卷积神经网路模型
'''定义神经网络'''
from torch import nn #导入神经网络模块class CNN(nn.Module):def __init__(self): #python基础关于类,self类自已本身super(CNN,self).__init__() #继承的父类初始化self.conv1=nn.Sequential( #将多个层组合成一起。创建了一个容器,将多个网络合在一起nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据in_channels=3, #、图像通道个数,1表示灰度图(确定了卷积核 组中的个数)out_channels=16, # 要得到几多少个特征图,卷积核的个数kernel_size=5, # 卷积核大小,5*5stride=1, # 步长padding=2, #一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何), # 输出的特征图为(16,28,28)nn.ReLU(), # relu层,不会改变特征图的大小nn.MaxPool2d(kernel_size=2), #进行池化操作(2x2 区域),输出结果为:(16,128,128))self.conv2=nn.Sequential( #输入nn.Conv2d(16,32,5,1,2), # 输出(32 128 128)nn.ReLU(),nn.Conv2d(32,32,5,1,2), # 输出(32 128 128)nn.ReLU(),nn.MaxPool2d(2), #输出(32,64,64))self.conv3=nn.Sequential( #输入(32 64 64)nn.Conv2d(32,128,5,1,2), #(128 64 64)nn.ReLU(),)self.out=nn.Linear(128*64*64,20) #全连接层得到的结果def forward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)output=self.out(x)return outputmodel = CNN().to(device)
print(model)5、训练与测试函数实现
def train(dataloader,model,loss_fn,optimizer):model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()batch_size_num=1for X,y in dataloader: #其中batch为每一个数据的编号,X是打包好的每一个数据包X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPUpred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化w权值loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络w参数loss_value=loss.item() #从tensor数据中提取数据出来,tensor获取损失值if batch_size_num %1 ==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader) #打包的数量model.eval() #测试,w就不能再更新。test_loss,correct=0,0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item() #test_loss是会自动累加每一个批次的损失值correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值b=(pred.argmax(1)==y).type(torch.float)test_loss /=num_batchescorrect /= sizeprint(f'Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}')6、模型训练与评估
loss_fn=nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为食物的类别是20
optimizer=torch.optim.Adam(model.parameters(),lr=0.001) #创建一个优化器,SGD为随机梯度下降算法
# #params:要训练的参数,一般我们传入的都是model.parameters()#
# lr:learning_rate学习率,也就是步长#loss表示模型训练后的输出结果与,样本标签的差距。如果差距越小,就表示模型训练越好,越逼近干真实的模型。# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)epochs=1
for t in range(epochs):print(f"Epoch {t+1}\n---------------------------")train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader,model,loss_fn) 7、运行结果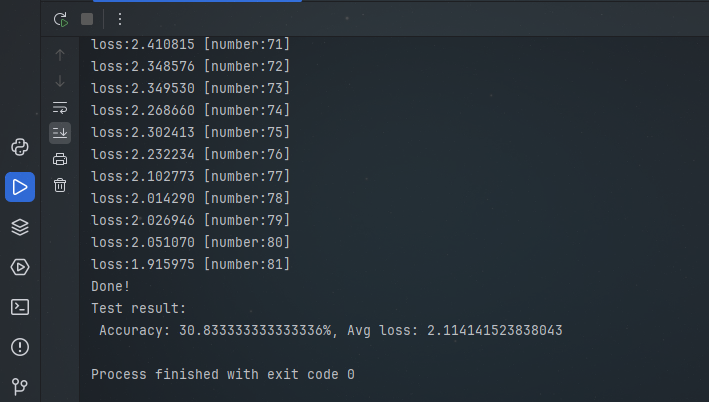
四、总结与优化方向
本文完整展示了基于PyTorch的食物图像分类项目流程,涵盖数据处理、模型构建和训练测试等核心环节。然而,当前模型仍有优化空间:
- 数据增强:增加更多数据增强策略(如随机裁剪、颜色抖动)以扩充数据集;
- 模型优化:尝试更复杂的预训练模型(如ResNet、VGG)或调整超参数(学习率、batch size);
- 正则化:添加Dropout或L2正则化防止过拟合。
通过不断改进和实践,图像分类模型的准确率和泛化能力将得到进一步提升。希望本文能为读者在深度学习图像分类领域的学习和实践提供有益参考。